







【学习笔记】【Pytorch】四、torchvision.datasets模块的使用`
学习地址
主要内容
一、torchvision模块说明
介绍:主要处理图像数据,包含一些常用的数据集、模型、转换函数等。
二、datasets模块介绍
介绍:一些加载数据的函数及常用的数据集接口。
三、datasets.CIFAR10类的使用
作用:CIFAR-10数据集的加载和数据处理。
一、torchvision模块说明
tochvision主要处理图像数据,包含一些常用的数据集、模型、转换函数等。torchvision独立于PyTorch,需要专门安装。
torchvision主要包含以下四部分:
- torchvision.models: 提供深度学习中各种经典的网络结构、预训练好的模型,如:Alex-Net、VGG、ResNet、Inception等。
- torchvision.datasets:提供常用的数据集,设计上继承 torch.utils.data.Dataset,主要包括:MNIST、CIFAR10/100、ImageNet、COCO等。
- torchvision.transforms:提供常用的数据预处理操作,主要包括对Tensor及PIL Image对象的操作。
- torchvision.utils:工具类,如保存张量作为图像到磁盘,给一个小批量创建一个图像网格。
二、datasets模块介绍
Pytorch官网:torchvision.datasets介绍
介绍:一些加载数据的函数及常用的数据集接口。
from torchvision import datasets
datasets文件夹:

三、datasets.CIFAR10类的使用
CIFAR-10官网:CIFAR-10数据集介绍
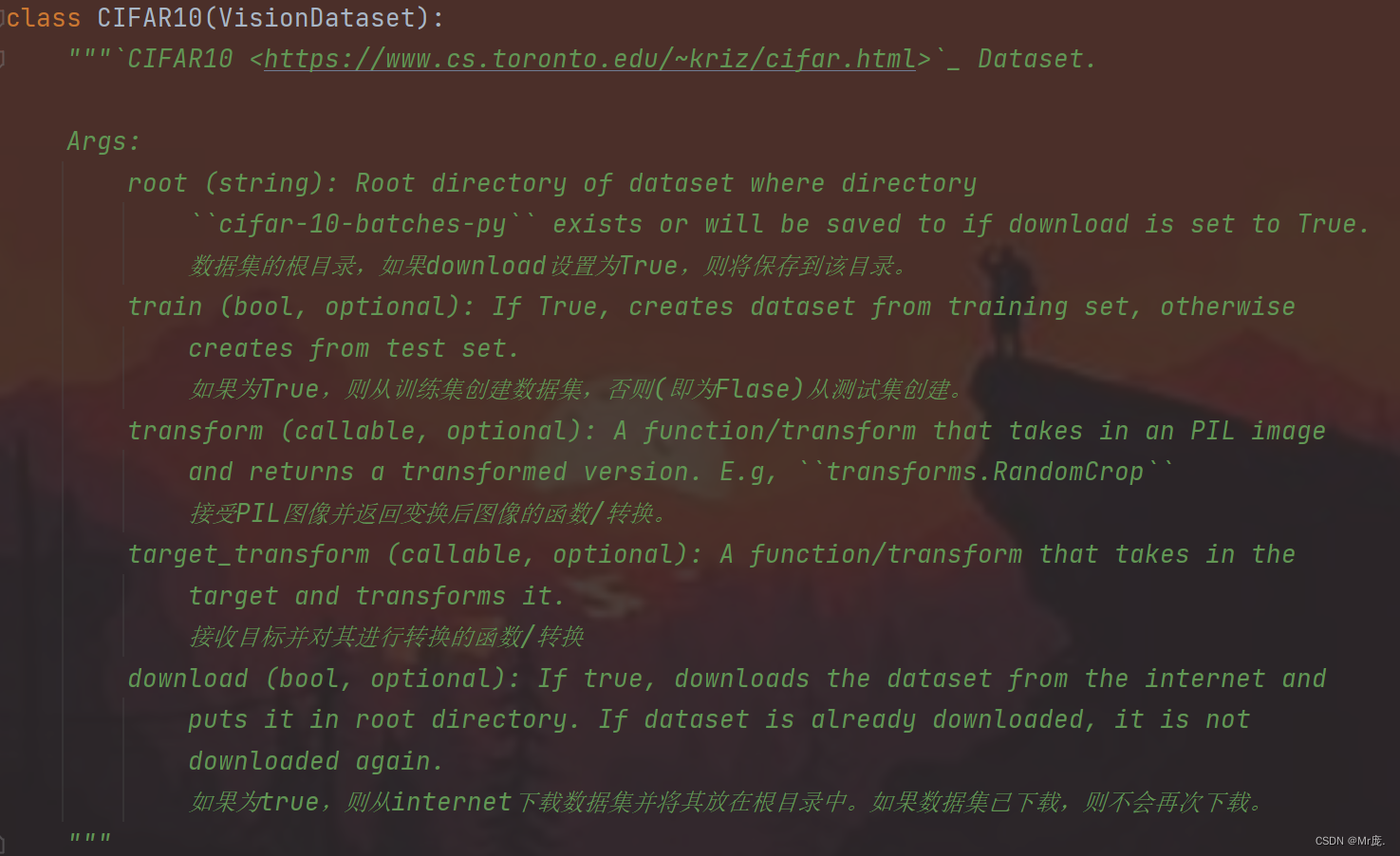
作用:CIFAR-10数据集的加载和数据处理。
1.使用说明
【实例化】datasets.CIFAR10(root: str,
train: bool = True,
transform: Optional[Callable] = None,
target_transform: Optional[Callable] = None,
download: bool = False,
)
- 作用:创建一个CIFAR-10数据集的实例
- root:数据集的根目录,如果download设置为True,则将保存到该目录。
- train:如果为True,则从训练集创建数据集,否则(即为Flase)从测试集创建。
- transform:接受PIL图像并返回变换后图像的function/transform。
E.g,transforms.RandomCrop。 - download:如果为true,则从internet下载数据集并将其放在根目录中。如果数据集已下载,则不会再次下载。
- 例子:
dataset_trans = transforms.Compose([
transforms.ToTensor()
]) # 创建一个 Compose 实例
# 创建 CIFAR10 实例(注:初始为PIL图片)
train_set = datasets.CIFAR10(root="./dataset", transform=dataset_trans, train=True, download=True)
print(test_set[0]) # 打印第一张图片信息 Tensor Image(注:为经过ToTensor前是PIL Image)
img, target = test_set[0] # 第一个参数为Tensor数据,第二个参数为类别索引
print(test_set.classes)
# ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
print(test_set.classes[target]) # 'cat'
2.代码实现
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms, datasets
dataset_trans = transforms.Compose([
transforms.ToTensor()
]) # 创建一个 Compose 实例
# .代表当前目录;./根目录,../向上2个根目录
# 创建 CIFAR10 实例(注:初始为PIL图片)
train_set = datasets.CIFAR10(root="./dataset", transform=dataset_trans, train=True, download=True)
test_set = datasets.CIFAR10(root="./dataset", transform=dataset_trans, train=False, download=True)
print(test_set[0]) # 打印第一张图片信息 Tensor Image(注:为经过ToTensor前是PIL Image)
img, target = test_set[0] # 第一个参数为Tensor数据,第二个参数为类别索引
print(test_set.classes)
# ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
print(test_set.classes[target]) # 'cat'
writer = SummaryWriter("dataset_logs") # 创建一个SummaryWriter实例
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i) # 在TensorBoard中添加图片
writer.close() # 一定要把读写关闭,否则TensorBoard中不显示图片
控制台输出:
Files already downloaded and verified
Files already downloaded and verified
(tensor([[[0.6196, 0.6235, 0.6471, ..., 0.5373, 0.4941, 0.4549],
[0.5961, 0.5922, 0.6235, ..., 0.5333, 0.4902, 0.4667],
[0.5922, 0.5922, 0.6196, ..., 0.5451, 0.5098, 0.4706],
...,
[0.2667, 0.1647, 0.1216, ..., 0.1490, 0.0510, 0.1569],
[0.2392, 0.1922, 0.1373, ..., 0.1020, 0.1137, 0.0784],
[0.2118, 0.2196, 0.1765, ..., 0.0941, 0.1333, 0.0824]],
[[0.4392, 0.4353, 0.4549, ..., 0.3725, 0.3569, 0.3333],
[0.4392, 0.4314, 0.4471, ..., 0.3725, 0.3569, 0.3451],
[0.4314, 0.4275, 0.4353, ..., 0.3843, 0.3725, 0.3490],
...,
[0.4863, 0.3922, 0.3451, ..., 0.3804, 0.2510, 0.3333],
[0.4549, 0.4000, 0.3333, ..., 0.3216, 0.3216, 0.2510],
[0.4196, 0.4118, 0.3490, ..., 0.3020, 0.3294, 0.2627]],
[[0.1922, 0.1843, 0.2000, ..., 0.1412, 0.1412, 0.1294],
[0.2000, 0.1569, 0.1765, ..., 0.1216, 0.1255, 0.1333],
[0.1843, 0.1294, 0.1412, ..., 0.1333, 0.1333, 0.1294],
...,
[0.6941, 0.5804, 0.5373, ..., 0.5725, 0.4235, 0.4980],
[0.6588, 0.5804, 0.5176, ..., 0.5098, 0.4941, 0.4196],
[0.6275, 0.5843, 0.5176, ..., 0.4863, 0.5059, 0.4314]]]), 3)
['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
cat
TensorBoard输出:















 2409
2409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









