






批量插入数据的业务场景我们经常会遇到,众所周知,批量操作是很耗时的,因此本次就来讨论如何优化
创建基础工程和表
1.自行搭建springboot项目并引入mybatis-plus
2.创建表,这里我暂时只给两个字段
3.此处还引入hutool,用于生成id
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.18</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
表结构
CREATE TABLE `student` (
`id` varchar(36) COLLATE utf8mb4_general_ci NOT NULL,
`name` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
实体类
@Data
@TableName
public class Student {
private String id;
private String name;
}
创建好项目和数据库后,添加测试代码
请求controller
@RestController
public class TestController {
@Autowired
private IStudentService service;
@GetMapping("insert/{number}")
public void insert(@PathVariable Integer number) {
service.insert(number);
System.out.println(number + " 条插入完成");
}
}
service类
public interface IStudentService extends IService<Student> {
void insert(Integer number);
}
1.使用mybatis-plus自带的批量插入功能
@Service
@RequiredArgsConstructor
public class IStudentServiceImpl extends ServiceImpl<StudentMapper, Student> implements IStudentService {
@Override
@Transactional
public void insert(Integer number) {
List<Student> list = new ArrayList<>();
for (int i = 0; i < number; i++) {
Student course = new Student();
course.setName("name" + i);
course.setId(String.valueOf(IdUtil.getSnowflakeNextId()));
list.add(course);
}
//使用mybatis-plus
mp(list);
}
private void mp(List<Student> list) {
System.out.println("mybatis-plus操作--start");
StopWatch stopWatch = new StopWatch();
stopWatch.start();
super.saveBatch(list);
stopWatch.stop();
long total = stopWatch.getTotal(TimeUnit.SECONDS);
System.out.println("mybatis-plus操作,耗时" + total);
}
}
在controller处执行请求,插入100000条
结果
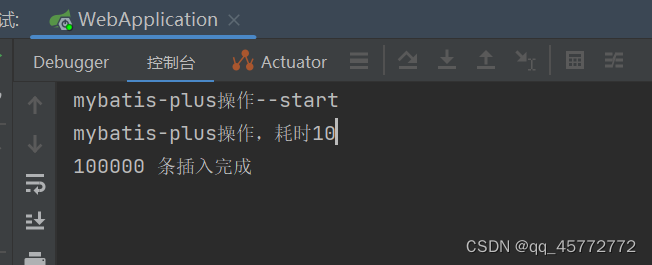
10秒钟,有点久
翻看源码后发现它是一条条for循环插入的。。。好家伙
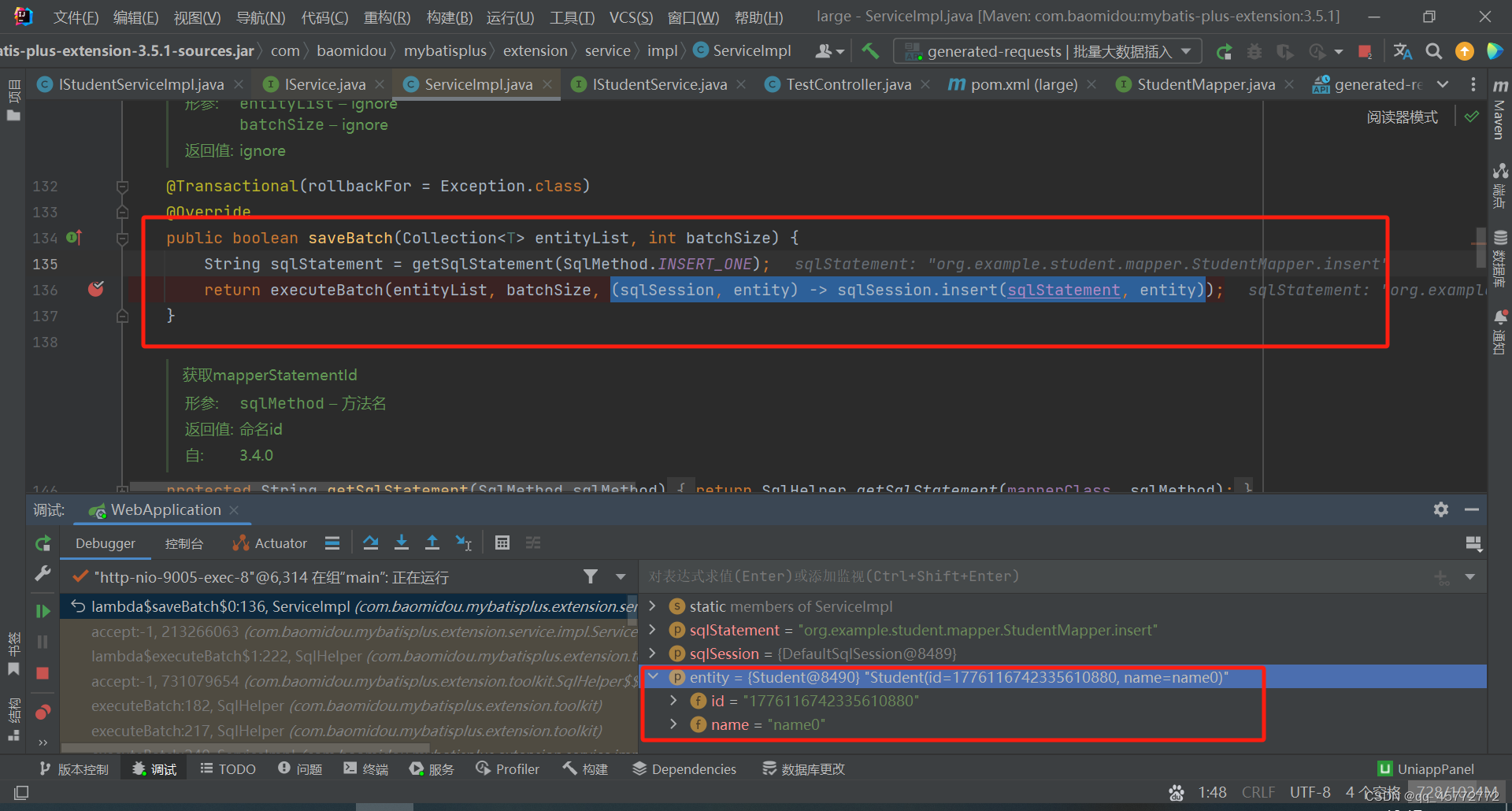
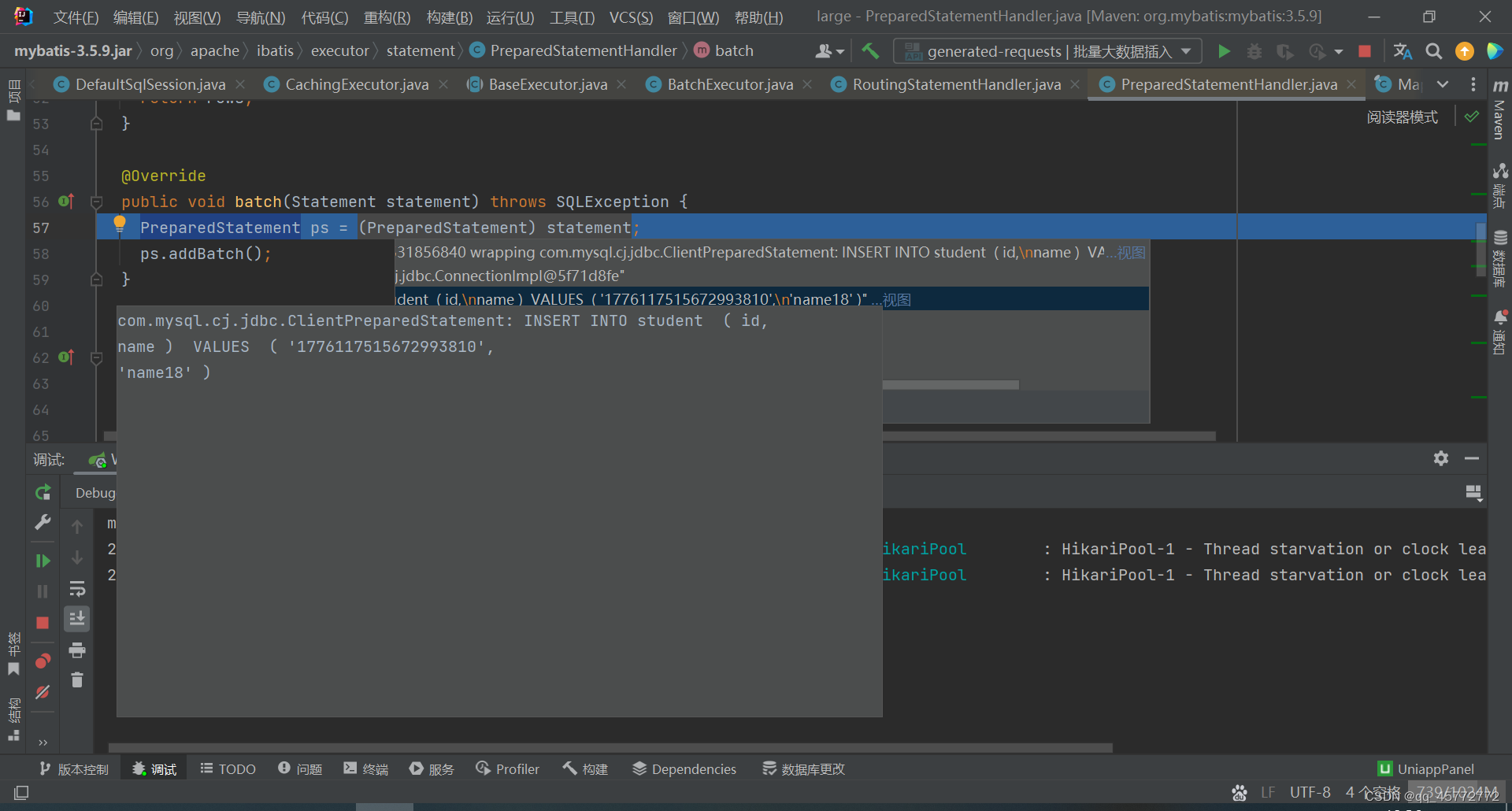
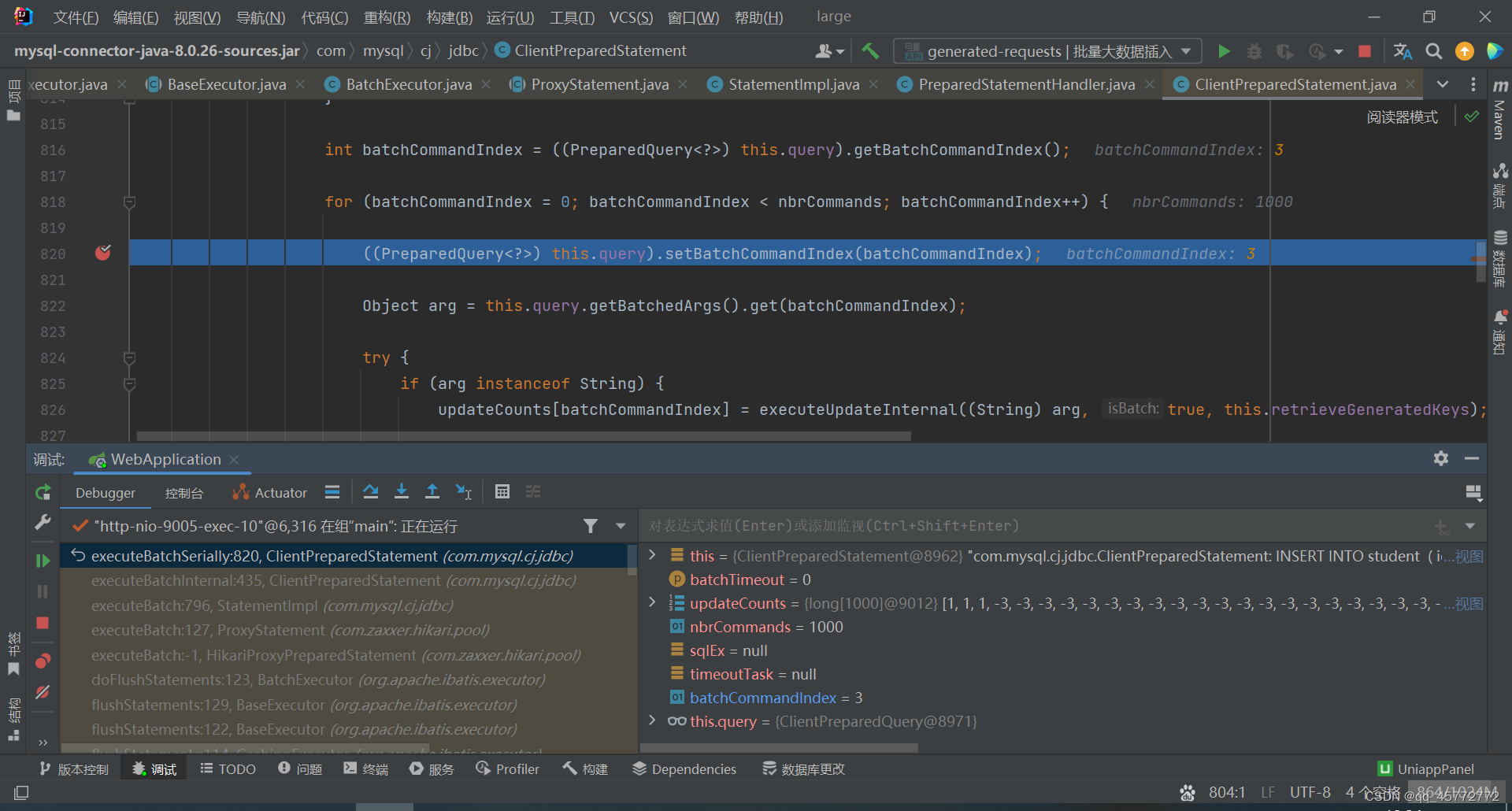
这是把10w条数据分批插入,每批是1000条循环?
看来大数据的批插入不能用这个方法,否则10w次的io,客户气得半夜跑过来给你一砖头
现在使用另一种方法
批插入肯定是要访问数据库的,这是避免不了的,因此我们可以把访问的次数减少,那不就好了?也就是减少io,减少sqlSession会话次数
如下,在mapper重新生成了sql语句
@Insert("<script>" +
"INSERT INTO `student`(`id`, `name`) " +
"VALUES " +
"<foreach collection= 'list' item= 'item' separator= ','> " +
"(#{item.id},#{item.name})" +
"</foreach></script>")
void batch(@Param("list") List<Student> list);
也就是10w条语句改成一条,一次性执行,减少循环过程
代码如下
@Service
@RequiredArgsConstructor
public class IStudentServiceImpl extends ServiceImpl<StudentMapper, Student> implements IStudentService {
@Override
@Transactional
public void insert(Integer number) {
List<Student> list = new ArrayList<>();
for (int i = 0; i < number; i++) {
Student course = new Student();
course.setName("name" + i);
course.setId(String.valueOf(IdUtil.getSnowflakeNextId()));
list.add(course);
}
//使用mybatis-plus
// mp(list);
//使用自定义的sql批处理
consumer(list);
}
private void mp(List<Student> list) {
System.out.println("mybatis-plus操作--start");
StopWatch stopWatch = new StopWatch();
stopWatch.start();
super.saveBatch(list);
stopWatch.stop();
long total = stopWatch.getTotal(TimeUnit.SECONDS);
System.out.println("mybatis-plus操作,耗时" + total);
}
/**
* 使用自定义的sql批操作
* @param list
*/
private void consumer(List<Student> list) {
System.out.println("使用自定义的sql批操作--start");
StopWatch stopWatch = new StopWatch();
stopWatch.start();
baseMapper.batch(list);
stopWatch.stop();
long total = stopWatch.getTotal(TimeUnit.SECONDS);
System.out.println("使用自定义的sql批操作,耗时" + total);
}
}
执行结果
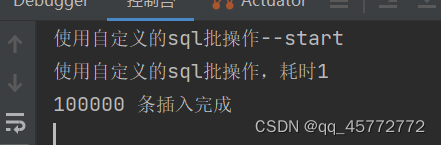
快很多了
后续的测试发现,插入的内容太多,就会出现问题
我把上面的name值换成和id一样的取值,增加了name值的长度,因此sql语句长度也增加了

### Error updating database. Cause: com.mysql.cj.jdbc.exceptions.PacketTooBigException: Packet for query is too large (5,300,043 > 4,194,304). You can change this value on the server by setting the 'max_allowed_packet' variable.
### The error may exist in org/example/student/mapper/StudentMapper.java (best guess)
### The error may involve org.example.student.mapper.StudentMapper.batch-Inline
### The error occurred while setting parameters
我肯定不能随便的改数据库配置的
行吧,来终极大杀器,多线程
将sql批处理拆分成多个线程,一个线程处理3w条(记得加事务)
private void thread(List<Student> list1) {
System.out.println("多线程操作--start");
StopWatch stopWatch = new StopWatch();
stopWatch.start();
int max = 3;
final CountDownLatch countDownLatch = new CountDownLatch(max);
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(max);
task(fixedThreadPool, list1.subList(0, 30000), countDownLatch);
task(fixedThreadPool, list1.subList(30000, 60000), countDownLatch);
task(fixedThreadPool, list1.subList(60000, 100000), countDownLatch);
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
fixedThreadPool.shutdown();
stopWatch.stop();
long total = stopWatch.getTotal(TimeUnit.SECONDS);
System.out.println("多线程操作,耗时" + total);
}
private void task(ExecutorService fixedThreadPool, List<Student> list, CountDownLatch countDownLatch) {
System.out.println("本次插入条数为 = " + list.size());
fixedThreadPool.execute(() -> {
baseMapper.batch(list);
countDownLatch.countDown();
});
}
完整代码如下
@Service
@RequiredArgsConstructor
public class IStudentServiceImpl extends ServiceImpl<StudentMapper, Student> implements IStudentService {
@Override
@Transactional
public void insert(Integer number) {
List<Student> list = new ArrayList<>();
for (int i = 0; i < number; i++) {
Student course = new Student();
// course.setName("name" + i);
// course.setId(String.valueOf(IdUtil.getSnowflakeNextId()));
// list.add(course);
//下面的代码会增加sql语句长度
long snowflakeNextId = IdUtil.getSnowflakeNextId();
course.setName("name" + snowflakeNextId);
course.setId(String.valueOf(snowflakeNextId));
list.add(course);
}
//使用mybatis-plus
// mp(list);
//使用自定义的sql批处理
// consumer(list);
//使用多线程同时操作
thread(list);
}
private void mp(List<Student> list) {
System.out.println("mybatis-plus操作--start");
StopWatch stopWatch = new StopWatch();
stopWatch.start();
super.saveBatch(list);
stopWatch.stop();
long total = stopWatch.getTotal(TimeUnit.SECONDS);
System.out.println("mybatis-plus操作,耗时" + total);
}
/**
* 使用自定义的sql批操作
* @param list
*/
private void consumer(List<Student> list) {
System.out.println("使用自定义的sql批操作--start");
StopWatch stopWatch = new StopWatch();
stopWatch.start();
baseMapper.batch(list);
stopWatch.stop();
long total = stopWatch.getTotal(TimeUnit.SECONDS);
System.out.println("使用自定义的sql批操作,耗时" + total);
}
private void thread(List<Student> list1) {
System.out.println("多线程操作--start");
StopWatch stopWatch = new StopWatch();
stopWatch.start();
int max = 3;
final CountDownLatch countDownLatch = new CountDownLatch(max);
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(max);
task(fixedThreadPool, list1.subList(0, 30000), countDownLatch);
task(fixedThreadPool, list1.subList(30000, 60000), countDownLatch);
task(fixedThreadPool, list1.subList(60000, 100000), countDownLatch);
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
fixedThreadPool.shutdown();
stopWatch.stop();
long total = stopWatch.getTotal(TimeUnit.SECONDS);
System.out.println("多线程操作,耗时" + total);
}
private void task(ExecutorService fixedThreadPool, List<Student> list, CountDownLatch countDownLatch) {
System.out.println("本次插入条数为 = " + list.size());
fixedThreadPool.execute(() -> {
baseMapper.batch(list);
countDownLatch.countDown();
});
}
}
当然,还有其他方法,例如生成sql文件然后由mysql执行,还有就是使用存储过程,这里暂不试了















 1976
1976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









