







准备环境
- pycharm(社区版即可)
- python 3.7
- Scrapy 2.6.1
一、安装下载 Scrapy 并创建项目
1、下载 Scrapy
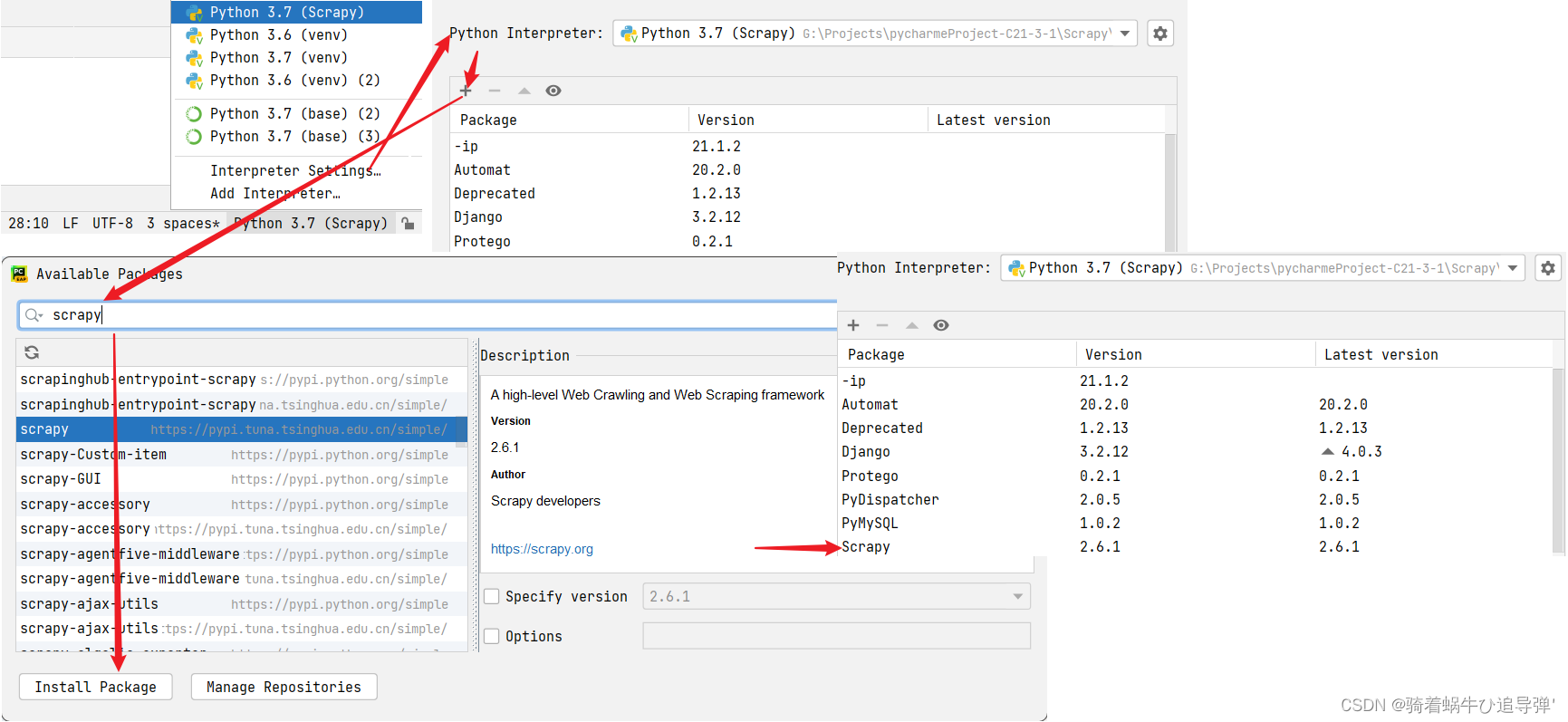
打开pycharm,在新建的项目工程中找到 Interpreter Setting...,弹出窗口点击 + 号搜索 scrapy ,选择最新的 scrapy ,点击 Install Package,等待下载完成后环境中出现 Scrapy 2.6.1 即可:
返回顶部
2、创建 Scrapy 项目
找到控制台的 Terminal,如下图:
在控制台输入命令:scrapy startproject 项目名:
(venv) G:\Projects\pycharmeProject-C21-3-1\Scrapy>scrapy startproject daomubiji
You can start your first spider with:
cd daomubiji
scrapy genspider example example.com

切换到生成的 daomubiji 目录下,使用命令 scrapy genspider 程序文件名 目标网址 生成程序文件 :
(venv) G:\Projects\pycharmeProject-C21-3-1\Scrapy>cd ./daomubiji
(venv) G:\Projects\pycharmeProject-C21-3-1\Scrapy\daomubiji>scrapy genspider articles www.xxx.com
Created spider 'articles' using template 'basic' in module:
daomubiji.spiders.articles
注意:命令中的目标网址会在新生成的源程序文件中存储在变量 start_urls 中,可以先写成 www.xxx.com 后期进行修改

spiders/:放置 spider 代码的目录,用于编写用户自定义的爬虫
items.py:项目中的item文件,用于定义用户要抓取的字段
middlewares.py:主要是对功能的拓展,用于用户添加一些自定义的功能
pipelines.py:管道文件,当 spider 抓取到内容(item)以后,会被送到这里,这些信息在这里会被清洗、去重、保存到数据库等
settings.py:项目的设置文件,配置的默认功能在这里存放
3、基础配置
修改articles.py文件内容,注释或删除allowed_domains变量,将目标网址进行替换:

进入settings.py 将 USER_AGENT 的值设置为目标网站的 USER_AGENT 值;将 ROBOTSTXT_OBEY的参数改为False,目的是使其不遵守Robots协议;添加 :LOG_LEVEL = 'ERROR',控制台打印内容时的输出限制;将 ITEM_PIPELINES 的内容释放
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False # ROBOTSTXT_OBEY的参数改为False,目的是使其不遵守Robots协议
LOG_LEVEL = 'ERROR'
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# 将以下内容的注释去掉
ITEM_PIPELINES = {
'daomubiji.pipelines.DaomubijiPipeline': 300,
}
关于网页的 user-agent 获取:F12 进入网页开发模式,找到网络一栏,在名称中选择网页,右边标头拉到最下面即可看到 user-agent,复制即可!如果没有内容显示,刷新一下网页就可以了~
4、测试 Scrapy 框架
打开 Terminal ,使用命令 :scrapy crawl articles 运行程序文件(articles为spiders下的用户自定义爬取程序名称),等待爬取结束,成功后会显示出目标网页的信息内容,如下图所示:

到此,Scrapy 框架基本下载使用完成!
本人做了测试案例,由于设计内容的版权问题,所以文章未通过审核,大家可以自行下载学习,仅供参考!Scrapy测试案例



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











