







Hive 优化
并行优化
并行编译
- Hive默认情况下,只能同时编译一个SQL到MapReduce代码的转换,并对这个过程上锁。
- 为了提高效率,同时减少死锁发生的可能性,我们需要将这个一次只能编译一个的操作,优化为并行执行。
# 参数:
set hive.driver.parallel.compilation=true;
# 默认这个参数是False;
# 搭配参数:
hive.driver.parallel.compilation.global.limit
# 表示,最大的并行度是多少。默认是3
这个优化不能提交性能,但是能够提高体验
并行Stage执行
Hive的SQL在翻译成MR任务的时候,可能会有很多的stage(阶段)
阶段之间都会有依赖关系:
- 前后依赖(前面的MR执行完成,后面的MR才可以去运行)
- 无依赖
如果多个State之间没有依赖,他们如果能够并行执行就能够提高集群的整体资源利用率。
# 参数:
set hive.exec.parallel=true,可以开启并发执行,默认为false。
set hive.exec.parallel.thread.number=16; //同一个sql允许的最大并行度,默认为8。
小文件优化
建议在企业中去使用,个人虚拟机电脑的性能不足,会导致性能下降。
前置条件:MapReduce的执行结果,不是一个单独的文件。而是多个文件。
如果MR任务的结果产生了很多的小文件存储在HDFS中,那么就会造成性能的下降(对NameNode的压力会很大)
小文件的HDFS影响
对磁盘寻道不友好(排除SSD,这里指的是机械硬盘)
- 95%的HDFS集群底层都是机械硬盘(少量土豪用SSD)
- 机械硬盘在随机读写上的性能是非常弱势的(对比SSD)
- 因为小文件代表了更多的block,更多的block代表了更多的数据并非连续的存储在磁盘的某一区域而是分散存储。
- 因为block多带来的分散存储,导致磁盘会频繁的进行随机寻址。
对NameNode的压力很大
- 在HDFS中文件是以
block存储的。每一个块在HDFS中都有记录。如果文件较小,并且比较多的话,就导致block的数量会变的更多,更多的block会消耗更多的NameNode的资源。
举例:
磁盘占用率100%,但是每秒传输数据量,不到5MB/s
底层原因就是:小文件太多,磁盘在做频繁的随机寻址
Hive执行MapReduce也会产生很多的结果文件。
这些结果文件,都不一定每一个都达到了一个block的大小。
随着时间的推移,结果文件会越攒越多,最终还是导致了文件过多对HDFS的影响,以及文件都不一定达到block的大小,也是一种小文件过多的问题。
对于这个问题,我们可以要求Hive在执行完毕后,合并结果文件。
合并后不是一个文件,而是可能多个文件。
每一个文件默认是按照HDFS的block大小来设定的
# 是否开启合并Map端小文件,在Map-only的任务结束时合并小文件,true是打开。
hive.merge.mapfiles
# 是否开启合并Reduce端小文件,在map-reduce作业结束时合并小文件。true是打开。
hive.merge.mapredfiles
# 合并后MR输出文件的大小,默认为256M。建议设置为255M
hive.merge.size.per.task
# 对小文件判断的平均大小阈值(结果文件的平均大小如果小于阈值,才会进行合并的操作)
hive.merge.smallfiles.avgsize
矢量化查询
对于分布式系统的优化,有两个方向:
-
增加分布式能力(增加并行计算能力)(横向拓展)
说白了就是加机器,加CPU数量
-
增加单机的处理能力(纵向拓展)
矢量化查询,就是类型2的优化。
MapReduce默认情况下,对数据的处理是一条条的处理的。
一条条处理是很正常的处理方式,写到这里,没有任何歧义,只是为了烘托矢量化查询而已。
矢量化查询是指,对数据一批批的处理。
要执行矢量化是有要求的:
- 必须是
ORC存储
# 开启矢量化查询
set hive.vectorized.execution.enabled=true;
# 开启矢量化在reduce端
set hive.vectorized.execution.reduce.enabled = true;
这种带有enable类型的,只是指开启某个功能,功能能不能用得上,是hive的判断。
比如前面将的map join
读取零拷贝优化
概念:尽量减少在读取的时候读取的数据量的大小。
条件:
- ORC存储(列存储)
- 查询只用到的部分的列
一般情况下,我们写SQL是有一部分的SQL是只会用到表中的部分的列,并不是要全部的列。
这种场景下,就可以只加载用到的列即可。不用到的不去加载(必须是列式存储)。
# 参数
set hive.exec.orc.zerocopy=true;
依旧是开启功能,能否用上,看hive的判断
数据倾斜优化
数据倾斜:在分布式程序分配任务的时候,任务分配的不平均。
数据倾斜,在企业开发中是经常遇到的,以及是非常影响性能的一种场景。
数据倾斜一旦发生,横向拓展只能缓解这个情况,而不能解决这个情况。
如果遇到数据倾斜,一定要从根本上去解决这个问题。而不是想着加机器来解决。
JOIN的时候的倾斜
方案一
用前面讲过的map join SMB join 这些优化去解决。
效果不太好,本身这些提高执行性能的方案,顺带着将倾斜的性能也提升一点,本质上不是解决倾斜的方案。
方案二
Sekw Join
方案的方式是:
对倾斜列的数据,进行单独处理。也就是遇到倾斜列的数据的时候,直接找一个中间目录临时存储,当前MR不去处理
等当前MR完成后,在单独处理这个倾斜的数据集。
这种解决方式有一个前置条件,Hive必须要知道,哪个列的数据倾斜了。
如何让Hive知晓哪个列是倾斜列,就有2种方式
方式1:运行时判断
在执行MR的过程中,Hive会对数据记录计数器,当计数器的值大于某个阈值的时候,认为这个数据是倾斜的列,对其进行单独处理。
方式2:编译时判断
指的就是,执行SQL的人提前知晓某个列就是倾斜列。
在建表的时候,就指定某个列是倾斜列即可。
# 参数
# 开启倾斜优化,针对倾斜优化的总开关
set hive.optimize.skewjoin=true;
# 设置运行时判断的时候,对倾斜数据量的阈值
set hive.skewjoin.key=100000;
# 开启编译时的倾斜优化,针对编译时的开关
set hive.optimize.skewjoin.compiletime=true;
# 示例语句,这个语句用于编译时判断,提前告知Hive哪个列是倾斜的
CREATE TABLE list_bucket_single (key STRING, value STRING)
-- 倾斜的字段和需要拆分的key值
SKEWED BY (id) ON (1,5,6)
-- 为倾斜值创建子目录单独存放
[STORED AS DIRECTORIES];
-- 上面的参数可以组合一块使用
-- 当表有SKEWED BY的设置,走编译时优化
-- 如果表没有这个设置,就运行时优化
在企业场景中,满足编译时的判断的场景不多,多数时候还是靠运行时来优化。
编译时的一种场景举例:
比如,传智播客的北京和上海校区很火爆,90%的学生都来这俩校区。
学生报名的事实表,铁定在北京和上海两个校区的ID上产生倾斜。
这样的场景才是适合编译时的,也就是在干活之前就分析出来哪个地方是倾斜了。
数据倾斜,无法避免,这是事实产生事件的现实映射。
只要你没有能力解决现实事件,那么事件的产生就会倾斜。
我们要做的是,在数据倾斜的前提下,完成性能优化。
Union优化
在前面的优化中,不管是运行时优化,还是编译时优化,都会产生两份结果。
这两份结果最终都需要进行Union操作合并为一份结果
参数:
set hive.optimize.union.remove=true;
开启这个参数的时候,对中间数据进行重复性利用。提升union的性能。
重复利用:不会单独开启任务对多份数据执行合并,而是每一个任务在执行之后直接将结果输出到目的地。
不开启Union合并优化:
MR1 对普通数据进行处理,输入路径:/tmp/1
MR2 对倾斜数据进行处理,输入路径:/tmp/2
合并后,数据写入最终目的地:/user/hive/warehouse/xxx.db/xxxtable/
如果开启了优化:
MR1 对普通数据进行处理,输入路径:/user/hive/warehouse/xxx.db/xxxtable/
MR2 对倾斜数据进行处理,输入路径:/user/hive/warehouse/xxx.db/xxxtable/
GROUP BY分组统计的倾斜处理
对于数据倾斜,典型的两个性能点:
- Join操作
- Group BY操作
分组
必聚合。
前提条件:对数据走平均打散,不按照hash散列
优化1:
利用MapReduce的Combina 机制,在Map端完成预聚合操作。
因为,分组是必聚合的,所以,我们可以做预聚合
参数:
hive.map.aggr=true;
优化2:
大combina机制,对预聚合产生在第一个MR的reduce端。
最终聚合产生在第二个MR中
将Map端的Combina扩散到真个MR,最终的聚合交由第二个MR来做。
在绝对的性能上:优化1是性能最好的,因为节省了很多的中间数据传输。同时一个MR搞定,不需要搞第二个MR来做。
但是,如果数据量巨大,这个MapReduce的任务的压力就会很大,同时执行时间可能很长。
执行时间过长,中间的变量就不好控。一旦出现问题,重头再来。
所以,对于海量数据一般使用优化2的方式,因为如果出现问题,起码可以从第一阶段的结果再来。
参数:
hive.groupby.skewindata=true;
MapReduce迭代计算的概念(补充)
迭代计算,就是一步步的计算出结果的方式。
方式比一次性计算出结果效率要低,但是稳定性和数据的可复用性更好。
在很多的企业业务计算中,有的数据计算是很复杂的。
可能:
- 如果要在一个MapReduce中完成这个业务,代码写起来很复杂
- 根本就不可能在一个MapReduce中完成整个业务的计算。
MapReduce的计算模型
上面提到:有可能会:根本就不可能在一个MapReduce中完成整个业务的计算。
这个是因为MapReduce的计算模型,就2个:
- Map模型
- Reduce模型
严格意义来说,MR叫做可供使用的算子就2个,一个是map算子一个是reduce算子
很多的业务计算都受限map和reduce方法的限制,因为,比如map方法
map(传入参数固定){
我们只能在这个部分,做自由处理。
return 返回形式固定
}
reduce(传入参数固定){
我们只能在这个部分,做自由处理。
return 返回形式固定
}
MR的迭代
基于前面的概念,所以很多的业务计算本质上是迭代的计算。
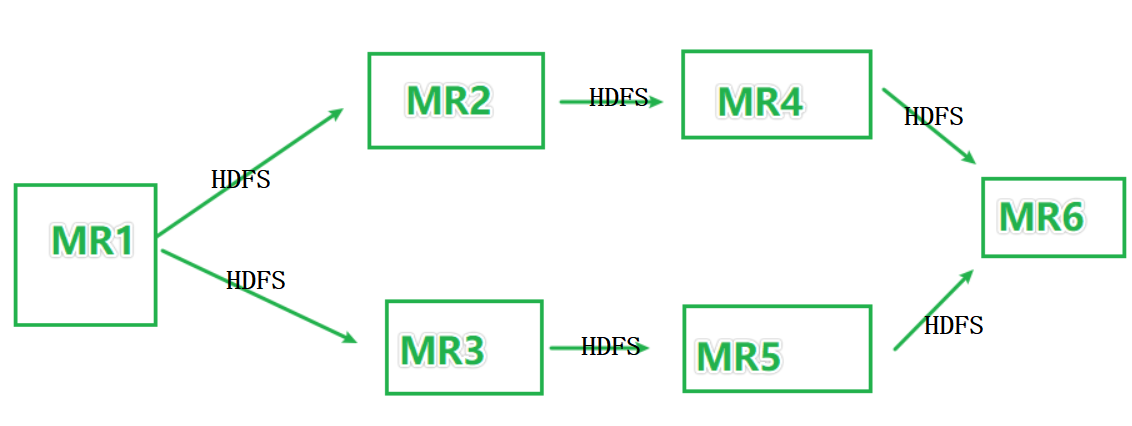
如图,某些复杂的业务场景可能会如图所示执行MR的迭代计算。
上图中,MR之间基于HDFS完成数据的共享。
迭代计算中,中间产生的数据,都是中间结果。
这些中间结果就类似数仓中,ODS->DWD->DWM->DWS->APP的迭代过程。
上图本质上是一个有向无环图(DAG)
有向是指:MR1走向MR6的方向
无环:没有形成闭环
前面分组倾斜处理优化中的优化2方案,就是一种迭代计算的思想延伸。
Hive分桶优化
分桶的概念
分桶和分区不同,分区是粗粒度的划分数据,并且是大范围的
分桶是细粒度的数据划分
分区划分的是文件夹
分桶划分的是文件
分区的规则是:按照指定key的值来确定文件夹
分桶的规则是:按照hash散列来计算数据应该落入哪个分桶的文件中。
总结:分区就是通过文件夹的方式大范围切分表数据
分桶就是通过区分文件的方式在细粒度上切分表数据
什么时候用分桶
-
查询性能优化(在有JOIN的场景下)
- 如果分区数量过多,会对文件系统造成负载压力。
- 分桶是hash散列,如果分桶key相同,一定在一个文件内。当进行JOIN的时候,分桶就可以帮助完成文件对文件的对应。提升JOIN的性能
-
数据采样
我们用的都是大数据系统,特点是数据量够大。
大量的数据如果做验证,比较消耗性能。
如果能够抽取一部分数据做验证
分桶就比较适合做数据采样用。
分桶表的数据写入
分桶表,不能够用load data的形式加载,也就是说只能够INSERT 来执行数据插入。
也就是,分桶表不能够直接用sqoop导入数据
sqoop导入的方案
创建一个不带分桶的临时表,用sqoop将数据导入临时表
执行:INSERT INTO 正式表 SELECT * FROM 临时表;
MapJoin优化
分桶本身也能提供优化,除了标准分桶外,还有一个MapJoin的优化。
MapJoin优化:将Join发生在Map端,而不在Reduce端。
如果在map端进行Join,每一个map都要有对应的数据存在内存中,也就是:
- 主表可能数据是分散在各个map的
- 被关联的表,肯定要全量的存在各个map的内存中
场景限制
一般用于,大表 Join 小表的场景
参数
# 开启自动执行MapJoin(达到条件,会自动走Map的Join而不是Reduce的Join)
set hive.auto.convert.join=true;
# 使用MapJoin的阈值设置,默认是20MB
set hive.auto.convert.join.noconditionaltask.size=512000000
/* 这个设置表示,如果N张表执行Join,N - 1张表的大小小于这个阈值,即可走MapJoin */
显示的告知Hive走MapJoin
在查询中加入:/*+mapjoin(表)*/
示例:
# 显示的告知Hive,这个查询要走MapJoin
select /*+mapjoin(A)*/ f.a,f.b from A t join B f on ( f.a=t.a and f.ftime=20110802) ;
Bucket-MapJoin
桶MapJoin
大表对大表的场景下,无法使用MapJoin(因为大表指的就是超过了MapJoin允许的大小阈值)
我们可以使用Bucket-MapJoin来进行优化。
表整体无法在Map中hold住,可以将表的分桶在Map中hold
相当于,两个表的分桶和分桶之间,做局部的MapJoin
限制条件
-
必须有分桶
-
bucket数是另一个表bucket数的
整数倍也就是可以做1个文件对一个文件,或者1个文件对2个文件等。
但是不能出现1个文件对1.3个文件
所以要求整数倍
-
分桶列也是JOIN列
参数
# 开启bucket mapjoin的优化
set hive.optimize.bucketmapjoin = true;
SMB Join 优化
Sorted Merge Bucket Join
MapJoin优化了整表的Join流程(整表在Map内存中Join)
BucketMapJoin优化了表的局部Join(桶文件和桶文件之间在Map端的内存中Join)
SMB Join 优化的是,在shuffle过程中的性能提升。
MapReduce执行流程,Map和Reduce之间有Shuffle,Shuffle是需要耗费一定的时间的。
如果提供的数据就是已排好序的,Shuffle就可以被加速吧
SMB的核心就是:
- 在BucketMapJoin的基础上,对桶文件进行排序
通俗说就是:分桶 + 桶排序
CLUSTERED BY(xxx) SORTED BY (xxx) INTO 10 BUCKET;
参数
# 开启排序
set hive.enforce.sorting = true;
# 开启SMB优化的自动尝试
set hive.optimize.bucketmapjoin.sortedmerge = true;
分桶优化小总结
| bucket mapjoin | SMB join |
|---|---|
| set hive.optimize.bucketmapjoin = true; | set hive.optimize.bucketmapjoin = true; set hive.auto.convert.sortmerge.join=true; set hive.optimize.bucketmapjoin.sortedmerge = true; set hive.auto.convert.sortmerge.join.noconditionaltask=true; |
| 一个表的bucket数是另一个表bucket数的整数倍 | 小表的bucket数**=**大表bucket数 |
| bucket列 == join列 | Bucket 列 == Join 列 == sort 列 |
| 必须是应用在map join的场景中 | 必须是应用在bucket mapjoin 的场景中 |
参数总结
# 开启自动执行MapJoin(达到条件,会自动走Map的Join而不是Reduce的Join)
set hive.auto.convert.join=true;
# 使用MapJoin的阈值设置,默认是20MB
set hive.auto.convert.join.noconditionaltask.size=512000000
# 开启bucket mapjoin的优化
set hive.optimize.bucketmapjoin = true;
# 开启排序
set hive.enforce.sorting = true;
# 开启SMB优化的自动尝试
set hive.optimize.bucketmapjoin.sortedmerge = true;















 323
323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









