







MySQL手动生成sql脚本一次性导入并更新大量数据(八千万条)
需求
这两天一个以前的项目有了新需求,需要给项目的数据库进行一下改造,其中主要涉及到超大数据量的一次性更新,之前这个项目也涉及了超大量数据的插入,正好统一记录一下
需求是需要将服务器一个目录下的大约八千万个文件的路径导入到数据库里,文件名就是这个文件在数据库里的一个唯一标识字段。(数据库里已经有了这些文件的信息,但是没有路径)
思路
怎么搞呢?我最开始打算用的办法是先新建一个专门用来存路径的表,先写一个文件搜索脚本把文件路径信息序列化成json文件,在用 mybatis 标签进行批量导入,后来发现这么大数据量用 mybatis 这么搞太不现实,又慢又有风险。
遂开始思考,一般情况下 MySQL 会涉及到超大规模数据导入的,那就是数据库的备份与恢复。
数据库的恢复会用到 source 命令,比如
mysql> source /data/tables.sql
这里用的 sql 文件一般是使用 dump 工具备份的数据库文件,我找来了一个这样的 sql 用文本编辑器打开看了看内部的结构
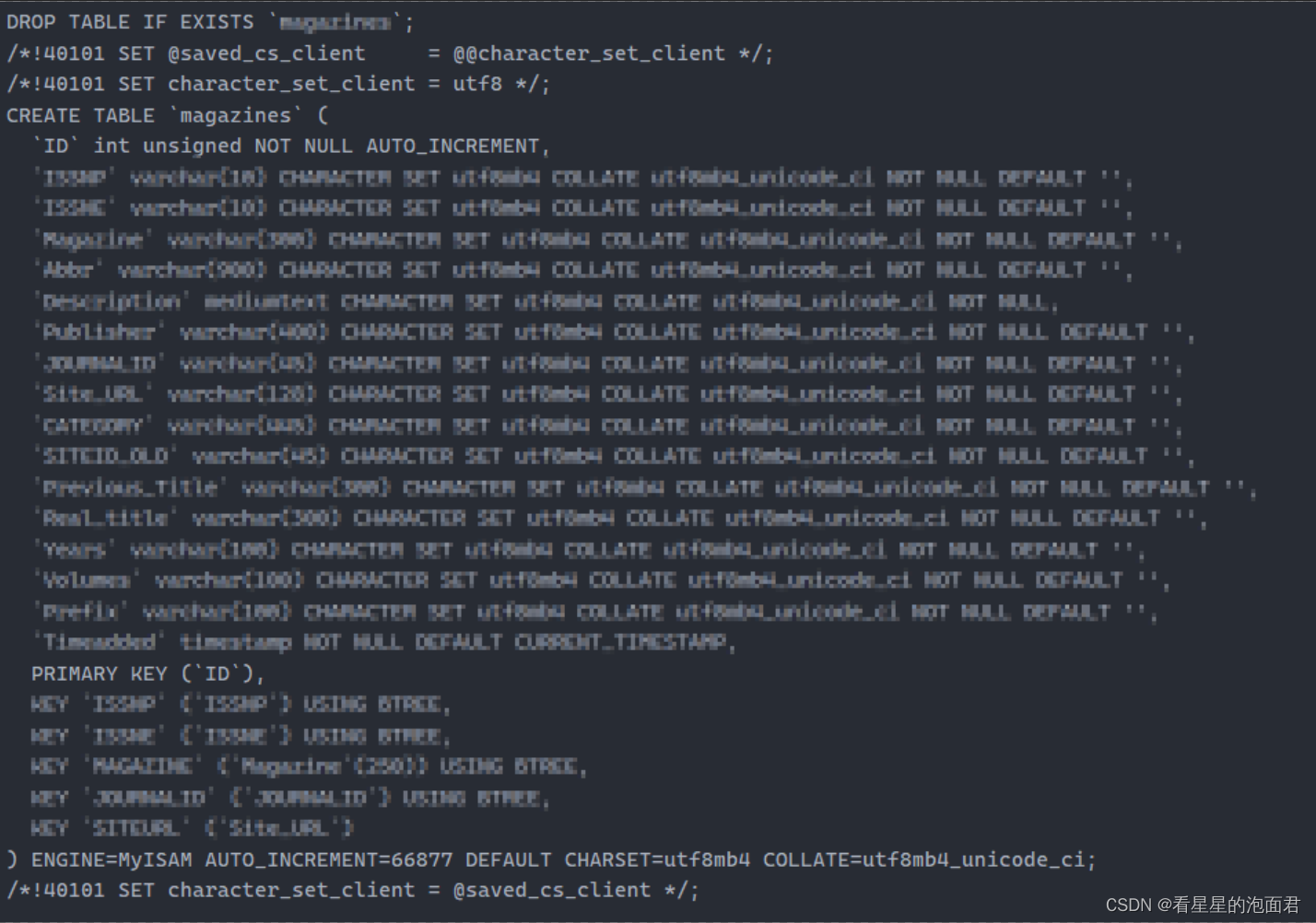

好家伙,这不就是一个超大量的 sql 脚本吗,先删表然后重新 create ,再锁表,然后就是一排排的
insert into table_name values (),(),()...();
insert into table_name values (),(),()...();
一个 insert 大约是插入一千条左右的数据。
原来 source 就是一个本地执行 sql 脚本的命令,现在知道了 sql 结构,那么我们理论上就能自己写一个脚本,把这样的 sql 文件生成出来,用服务器跑 source 命令,实现超大数据的导入。
本地文件路径序列化 json
说干就干,我们用 C# 写一个搜索程序用来生成 json(其实当时是用 Java 写的,这两天用 C# 重写了遍)
internal class Program
{
static int dataindex = 0;
static void Main(string[] args)
{
Directory.CreateDirectory("data");
FileInfo configFile = new("config.json");
if (!configFile.Exists)
{
Console.WriteLine("配置文件不存在");
return;
}
var configJson = File.ReadAllText(configFile.FullName);
var config = JsonConvert.DeserializeObject<Config>(configJson);
if (config == null) return;
Console.WriteLine(config.scan_path);
config.scan_type = config.scan_type ?? "all";
if (config.scan_path == null)
{
Console.WriteLine("没有指定路径");
return;
}
else if (!Directory.Exists(config.scan_path))
{
Console.WriteLine("指定的路径不存在");
return;
}
var uriList = new List<string>();
ScanFile(config.scan_path, config.scan_type, uriList);
if (uriList.Count > 0)
{
FileStream fs = new($"data/data{dataindex}.json", FileMode.Create, FileAccess.Write);
dataindex++;
StreamWriter sw = new(fs);
sw.Write(JsonConvert.SerializeObject(uriList));
sw.Flush();
uriList.Clear();
sw.Close();
fs.Close();
}
}
static void ScanFile(string dir, string type, List<string> uriList)
{
DirectoryInfo directory = new(dir);
var dirInfos = directory.GetDirectories();
if (dirInfos.Length != 0)
{
foreach (var sdir in dirInfos)
{
ScanFile(sdir.FullName, type, uriList);
}
}
var fileInfos = directory.GetFiles();
if (fileInfos.Length > 0)
{
foreach (var file in fileInfos)
{
if (type == "all" || $".{type}" == Path.GetExtension(file.FullName))
uriList.Add(file.FullName);
if (uriList.Count > 4000000)
{
FileStream fs = new($"data/data{dataindex}.json", FileMode.Create, FileAccess.Write);
dataindex++;
StreamWriter sw = new(fs);
sw.Write(JsonConvert.SerializeObject(uriList));
sw.Flush();
uriList.Clear();
sw.Close();
fs.Close();
}
}
}
}
}
第一个需求,新表导入大量数据
然后再用这些 json 生成 sql
internal class Program
{
static void Main(string[] args)
{
Directory.CreateDirectory("sql");
/*
-- sci_lib.library_dir definition
DROP TABLE IF EXISTS `library_dir`;
CREATE TABLE `library_dir` (
`id` bigint NOT NULL AUTO_INCREMENT,
`doi` varchar(100) NOT NULL,
`dir` varchar(300) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `library_dir_doi_IDX` (`doi`) USING BTREE
) ENGINE=MyISAM AUTO_INCREMENT=199999 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
LOCK TABLES `library_dir` WRITE;
INSERT INTO `library_dir`
(),
();
UNLOCK TABLES;
*/
StreamWriter insertDbSql = new(new FileStream("sql/insert_db.sql", FileMode.Create, FileAccess.Write));
try
{
insertDbSql.Write(@"DROP TABLE IF EXISTS `library_dir`;\n");
insertDbSql.Write("CREATE TABLE `library_dir` (\n" +
" `id` bigint NOT NULL AUTO_INCREMENT,\n" +
" `doi` varchar(200) NOT NULL,\n" +
" `dir` varchar(600) NOT NULL,\n" +
" PRIMARY KEY (`id`),\n" +
" KEY `library_dir_doi_IDX` (`doi`) USING BTREE\n" +
") ENGINE=MyISAM DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;\n");
insertDbSql.Write("LOCK TABLES `library_dir` WRITE;\n");
insertDbSql.Flush();
insertDbSql.Write("INSERT INTO `library_dir` VALUES");
var dataFiles = new DirectoryInfo("data").GetFiles();
List<string>? pdfList = null;
long id = 1;
for (int i = 0; i < dataFiles.Length; i++)
{
pdfList = JsonConvert.DeserializeObject<List<string>>(File.ReadAllText(dataFiles[i].FullName))!;
for (int j = 0; j < pdfList.Count; j++)
{
var decodePDF = Path.GetFileNameWithoutExtension(pdfList[j]);
var pdf = new FileInfo(pdfList[j]);
var doi = pdf.Directory!.Name + "/" + HttpUtility.UrlDecode(decodePDF);
var dir = pdfList[j];
dir = dir.Replace(@"\", @"\\");
insertDbSql.Write($"({id},'{doi}','{dir}')");
id++;
if (id % 1000 == 0)
{
insertDbSql.Write(";\n");
insertDbSql.Write("INSERT INTO `library_dir` VALUES");
insertDbSql.Flush();
}
else if (!(i == (dataFiles.Length - 1) && j == (pdfList.Count - 1)))
insertDbSql.Write(",");
}
pdfList = null;
insertDbSql.Flush();
Console.WriteLine("已处理" + (i + 1) + "个文件,sql 中已有" + (id - 1) + "条数据");
}
insertDbSql.Write(";\n");
insertDbSql.Write("UNLOCK TABLES;\n");
insertDbSql.Flush();
}
finally
{
insertDbSql.Close();
}
}
生成 sql 后直接在 MySQL 里用 source 执行就行了,时间还挺快的,用了一两个小时左右
新需求,单表大量更新
本来像之前那样搞好像相安无事了,但是这两天新需求就出了问题
这个项目一个主要功能是搜索后或者根据一些条件选择一些文件打包成 zip 然后让用户下载,
然后经常出现用户选择的文件没有被打包的情况,原因是数据库原表里的文件在本地并不是全都有,而用户搜索则是在原表中搜索。这个问题其实也好解决,两个表连接然后让第二个表里没有的数据排除掉就好了,但是问题出在了第二个表上,因为本地文件有些混乱,第二张表里文件统一标识的那一列每个标识并不一定唯一,总之就是太乱了,sql不好写,性能也差,八千条数据的表的多表连接还是挺恐怖的,所以打算把表改成把路径直接存到第一个表里的方法。
其实在当时(需求1)也考虑过这样的方法,但是这样作存在一些问题,因为这一个有八千万条数据的大表,修改表结构很耗费时间,而且批量的更新数据比批量插入数据要更难实现,所以选择了新建表存路径,现在就得想办法改成这个方案了。
首先是更改表结构,这个简单
打上这个命令
mysql> ALTER TABLE database.table ADD dir varchar(600) NULL;
然后等一晚上就有新字段了。
接下来的重点是如何比较效率的去批量更新这个字段了。经过本地测试,source 命令是支持执行 update 语句的,正好之前扫描文件用的 json 文件还在,那就直接生成一个 sql 里面放一行行的 update 语句就好了。
于是初步用脚本生成了一个下面结构的 sql
LOCK TABLES table WRITE;
update scimag set xxx='xxx' where xx='xx';
update scimag set xxx='xxx' where xx='xx';
update scimag set xxx='xxx' where xx='xx';
update scimag set xxx='xxx' where xx='xx';
...
update scimag set xxx='xxx' where xx='xx';
update scimag set xxx='xxx' where xx='xx';
update scimag set xxx='xxx' where xx='xx';
UNLOCK TABLES;
本来信心满满,在本地用数据量十万条的测试数据库进行了测试,但是用时让我傻眼了
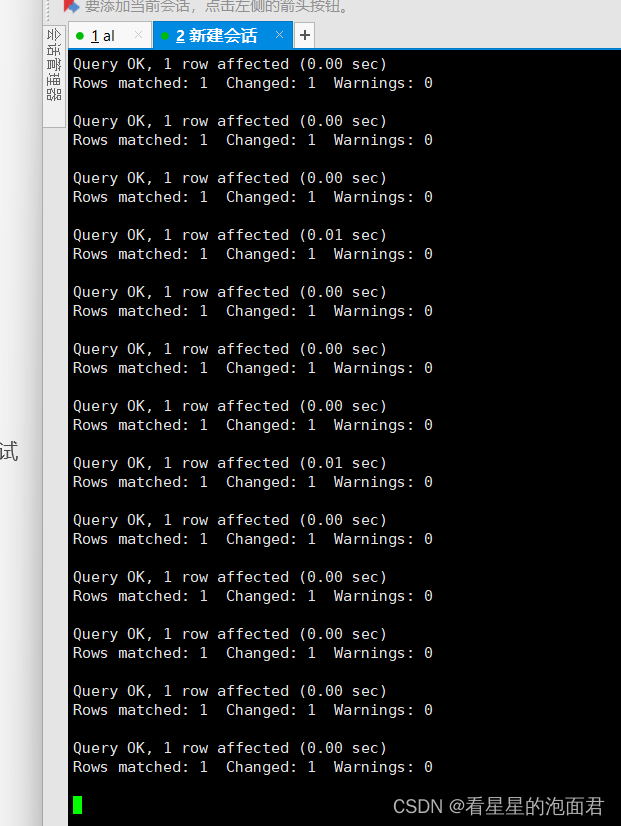
一共十万条数据,居然用了小三分钟才弄完?太慢了。
于是开始研究 MySQL 怎么批量更新数据,
replace into 和 insert into…on duplicate key update 都不合适,没法用,但是找到了一个鬼才写法
update users
set job = case id
when 1 then 'value1'
when 2 then 'value2'
end
where id in(1, 2);
这样就实现了批量的更新,试着生成用这个语法的 sql
using Newtonsoft.Json;
using System.Web;
Directory.CreateDirectory("sql");
const int updateNum = 1000;
/*
LOCK TABLES `table` WRITE;
update users
set job = case id
when 1 then 'value1'
when 2 then 'value2'
end
where id in(1, 2);
UNLOCK TABLES;
*/
StreamWriter insertDbSql = new(new FileStream("sql/insert_db3.sql", FileMode.Create, FileAccess.Write));
try
{
insertDbSql.Write("LOCK TABLES `scimag` WRITE;\n");
insertDbSql.Flush();
insertDbSql.Write("UPDATE scimag SET\n");
insertDbSql.Write(" dir = CASE DOI\n");
var dataFiles = new DirectoryInfo("data").GetFiles();
List<string>? pdfList = null;
List<string> add2 = new();
long id = 1;
// 文件层的循环
for (int i = 0; i < dataFiles.Length; i++)
{
pdfList = JsonConvert.DeserializeObject<List<string>>(File.ReadAllText(dataFiles[i].FullName))!;
for (int j = 0; j < pdfList.Count; j++)
{
var decodePDF = Path.GetFileNameWithoutExtension(pdfList[j]);
var pdf = new FileInfo(pdfList[j]);
var doi = pdf.Directory!.Name + "/" + HttpUtility.UrlDecode(decodePDF);
var dir = pdfList[j];
dir = dir.Replace(@"\", @"\\");
insertDbSql.Write($"WHEN '{doi}' THEN '{dir}'\n");
add2.Add(doi);
id++;
if (id % updateNum == 0)
{
insertDbSql.Write("END\n" +
"WHERE DOI IN (\n");
for (int a = 0; a < add2.Count; a++)
{
insertDbSql.Write($"'{add2[a]}'");
if (a < add2.Count - 1)
insertDbSql.Write($",\n");
}
add2.Clear();
insertDbSql.Write(");\n");
insertDbSql.Write("UPDATE scimag SET\n");
insertDbSql.Write(" dir = CASE DOI\n");
insertDbSql.Flush();
}
else if (i == dataFiles.Length - 1 && pdfList.Count - j - 1 < updateNum)
{
for (; j < pdfList.Count; j++)
{
decodePDF = Path.GetFileNameWithoutExtension(pdfList[j]);
pdf = new FileInfo(pdfList[j]);
doi = pdf.Directory!.Name + "/" + HttpUtility.UrlDecode(decodePDF);
dir = pdfList[j];
dir = dir.Replace(@"\", @"\\");
insertDbSql.Write($"WHEN '{doi}' THEN '{dir}'\n");
add2.Add(doi);
id++;
}
insertDbSql.Write("END\n" +
"WHERE DOI IN (\n");
for (int a = 0; a < add2.Count; a++)
{
insertDbSql.Write($"'{add2[a]}'");
if(a < add2.Count - 1)
insertDbSql.Write($",\n");
}
add2.Clear();
insertDbSql.Write(")");
insertDbSql.Flush();
}
}
pdfList = null;
insertDbSql.Flush();
Console.WriteLine("已处理" + (i + 1) + "个文件,sql 中已有" + (id - 1) + "条数据");
}
insertDbSql.Write(";\n");
insertDbSql.Write("UNLOCK TABLES;\n");
insertDbSql.Flush();
}
finally
{
insertDbSql.Close();
}
用这样生成的 sql 去测试
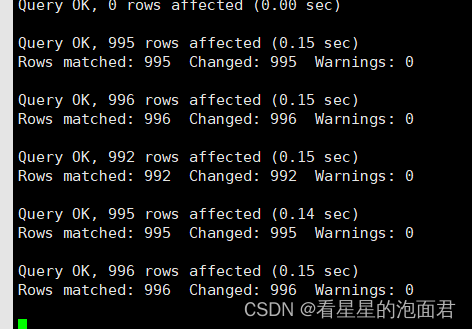
只用了十多秒就完事了,挺不错,这就把脚本搬到服务器上开导,顺带写个博客。
简单猜想单条 update 为什么这么慢
其实从实际存储结构去分析,update 和 insert 不同,批量的 insert 可以在提前划好的空间一大块一大块的填数据,所以一次写多个比单条执行快,但是看上面两条 update 语句其实都是在一条条的导入数据,甚至批量的写法还要加一个条件判断的过程,应该执行更慢才对,为什么会比批量单条快这么多呢?
我的猜测是可能跟日志打印有关,我们都知道,在 Java 中
System.out.println();
是非常慢的,因为他涉及到阻塞 io 打印,还有同步锁,
MySQL在执行 source 时的日志输出很可能也是这个情况,我们再看一眼第一个截图
可以看到,每行数据更新完成后他都会打印一行日志,日志记录的语句执行时间只有 0.00 sec
可能更新用的时间还没他打印日志用的时间长,就这样大量的阻塞io拖慢了语句的执行速度,而批量更新的写法大大减少了日志的打印量所以让执行时间减少,总结就是并不是批量更新更快,而是单条执行被拖慢了。
以上就是本次的项目记录。














 1569
1569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









