







List系列集合的使用
List系列集合有序,可重复,有索引的。
List集合继承了Collection集合的全部功能
List系列集合有索引:
public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上。
public E get(int index):返回集合中指定位置的元素。
public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。
public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回更新前的元素值。
ArrayList实现类集合底层基于数组存储数据的,查询快,增删慢(相对的,其实还是很快的)!
开发中ArrayList集合用的最多!!
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import java.util.Vector;
public class ListDemo01 {
public static void main(String[] args) {
// 1.创建一个ArrayList集合对象:这是一行经典代码!
// List:有序,可重复,有索引的。
List<String> lists = new ArrayList<>();
lists.add("java1");
lists.add("java2");
lists.add("java1");
lists.add("java2");
System.out.println(lists);
// 2.在某个索引位置插入元素。
lists.add(0,"MySQL");
System.out.println(lists);
// 3.根据索引删除元素,返回被删除元素
System.out.println(lists.remove(0));
System.out.println(lists);
// 4.根据索引获取元素
System.out.println(lists.get(0));
// 5.修改索引位置处的元素
System.out.println(lists.set(1, "mybatis"));
System.out.println(lists);
}
}
List4种遍历方式
(1)for循环。
(2)迭代器。
(3)foreach。
(4)JDK 1.8新技术。
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
import java.util.List;
public class ListDemo02 {
public static void main(String[] args) {
List<String> lists = new ArrayList<>();
lists.add("java1");
lists.add("java2");
lists.add("java3");
//1、for循环
for (int i = 0; i < lists.size(); i++) {
String list = lists.get(i);
System.out.println(list);
}
System.out.println("---------------------------------");
//2、迭代器
Iterator<String> it = lists.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
System.out.println("---------------------------------");
//3、forEach
for (String ele:lists) {
System.out.println(ele);
}
System.out.println("---------------------------------");
//4、Lambda表达式
lists.forEach(s -> {
System.out.println(s);
});
lists.forEach(s -> System.out.println(s));
lists.forEach(System.out::println);
System.out.println("---------------------------------");
}
}
LinkedList集合
LinkedList: 添加的元素是有序,可重复,有索引的。
LinkedList也是List的实现类:底层是基于链表的,增删比较快,查询慢!!
LinkedList是支持双链表,定位前后的元素是非常快的,增删首尾的元素也是最快的
所以LinkedList除了拥有List集合的全部功能还多了很多操作首尾元素的特殊功能:
public void addFirst(E e):将指定元素插入此列表的开头。
public void addLast(E e):将指定元素添加到此列表的结尾。
public E getFirst():返回此列表的第一个元素。
public E getLast():返回此列表的最后一个元素。
public E removeFirst():移除并返回此列表的第一个元素。
public E removeLast():移除并返回此列表的最后一个元素。
public E pop():从此列表所表示的堆栈处弹出一个元素。
public void push(E e):将元素推入此列表所表示的堆栈。
如果查询多而增删少用ArrayList集合。(用的最多的)
如果查询少而增删首尾较多用LinkedList集合。
import java.util.LinkedList;
import java.util.List;
public class ListDemo03 {
public static void main(String[] args) {
// 1.用LinkedList做一个队列:先进先出,后进后出。
LinkedList<String> queue = new LinkedList<>();
// 入队
queue.addLast("1号");
queue.addLast("2号");
queue.addLast("3号");
queue.addLast("4号");
System.out.println(queue);
//出队
System.out.println(queue.removeFirst());
//做一个栈
LinkedList<String> stack = new LinkedList<>();
stack.push("第一颗子弹");
stack.push("第二颗子弹");
stack.push("第三颗子弹");
stack.push("第四颗子弹");
System.out.println(stack);
System.out.println(stack.pop());
System.out.println(stack.pop());
System.out.println(stack.pop());
System.out.println(stack.pop());
}
}
HashSet集合
HashSet:添加的元素,是无序,不重复,无索引的。
import java.util.*;
public class HashSetDemo01 {
public static void main(String[] args) {
// 无序,不重复,无索引的。
Set<String> sets = new HashSet<>(); // 一行经典代码!!
sets.add("Mybatis");
sets.add("Java");
sets.add("Java");
sets.add("MySQL");
sets.add("MySQL");
sets.add("Spring");
// [Java, MySQL, Spring, Mybatis]
System.out.println(sets);
}
}
两个问题(面试热点):
1)Set集合添加元素如何进行去重复?
1.对于有值特性:直接判断进行去重复。
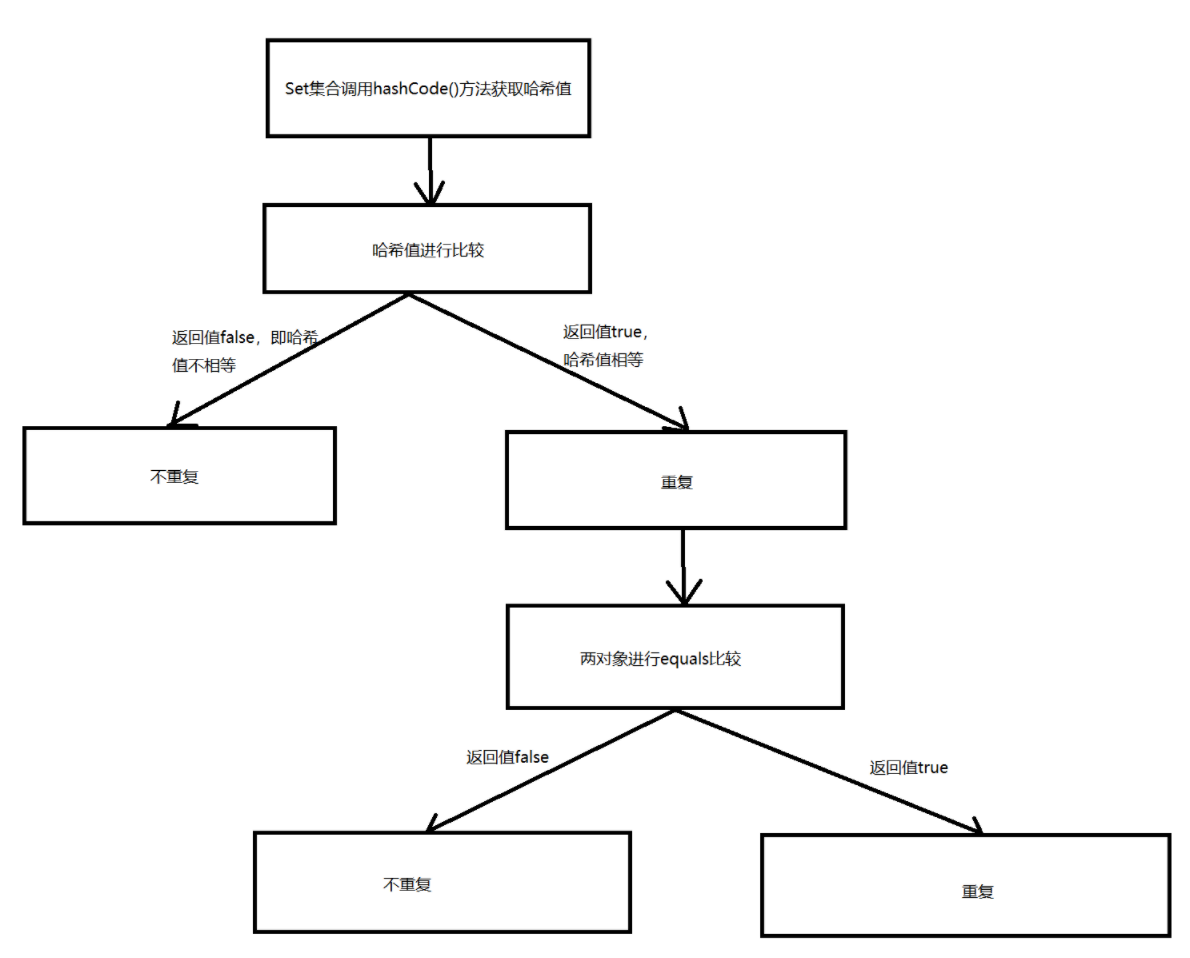
2.对于引用数据类型的类对象(见下图):
Set集合调用hashCode()方法得到哈希值(内存地址),比较两个对象的哈希值
如果不相同,两个对象不重复。
如果哈希值相同,两对象进行equals比较,如果相同则重复,如果不相同认为不重复。
 集合和泛型都只能支持引用数据类型。
集合和泛型都只能支持引用数据类型。
如果希望Set集合认为两个对象只要内容一样就重复了,必须重写对象的hashCode和equals方法。
import java.util.HashSet;
import java.util.Set;
public class HashSetDemo02 {
public static void main(String[] args) {
Set<Integer> sets = new HashSet<>(); // 一行经典代码!!
sets.add(1);
sets.add(1);
sets.add(2);
sets.add(2);
System.out.println(sets);
// 存储一些自定义类型数据:无序不重复
Set<Apple> apples = new HashSet<>();
Apple a1 = new Apple("红富士",39.9,"红色");
Apple a2 = new Apple("阿克苏",39.9,"青红色");
Apple a3 = new Apple("阿克苏",39.9,"青红色");
System.out.println(a1.hashCode());
System.out.println(a2.hashCode());
System.out.println(a3.hashCode());
apples.add(a1);
apples.add(a2);
apples.add(a3);
apples.add(a1);
System.out.println(apples);
}
}
import java.util.Objects;
public class Apple {
private String name;
private double price ;
private String color ;
//构造方法、get、set、tostring方法省略
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Apple apple = (Apple) o;
return Double.compare(apple.price, price) == 0 && Objects.equals(name, apple.name) && Objects.equals(color, apple.color);
}
@Override
public int hashCode() {
return Objects.hash(name, price, color);
}
}
2)Set集合元素无序的原因是什么?
根本原因:底层采用了哈希表存储元素。
JDK 1.8之前:哈希表 = 数组 + 链表 + (哈希算法)
JDK 1.8之后:哈希表 = 数组 + 链表 + 红黑树 + (哈希算法)
当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
Set系列集合优缺点:
增删改查的性能很好!
但是它是无序不重复的!
LinkedHashSet
HashSet的子类
元素是有序, 不重复,无索引.
LinkedHashSet底层依然是哈希表存储元素
但是每个元素都额外带一个链来维护添加顺序!!
优点:不光增删查快,还有序。
缺点:多了一个存储顺序的链会占内存空间!!而且不允许重复,无索引。
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Set;
public class HashSetDemo04 {
public static void main(String[] args) {
// 有序不重复无索引
Set<String> sets = new LinkedHashSet<>();
sets.add("Mybatis");
sets.add("Java");
sets.add("Java");
sets.add("MySQL");
sets.add("MySQL");
sets.add("Spring");
// [Java, MySQL, Spring, Mybatis]
System.out.println(sets);
}
}
总结
如果希望元素可以重复,又有索引,查询要快用ArrayList集合。(用的最多)
如果希望元素可以重复,又有索引,增删要快要用LinkedList集合。(适合查询元素比较少的情况,经常要首尾操作元素的情况)
如果希望增删改查都很快,但是元素不重复以及无序无索引,那么用HashSet集合。
如果希望增删改查都很快且有序,但是元素不重复以及无索引,那么用LinkedHashSet集合。















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









