










公众号:yk 坤帝
后台回复 Urllib库基本使用 获取全部源代码
1.什么是Urllib?
2.相⽐Python2变化
3.urlopen模块
4.响应与响应类型
4.1 状态码、响应头
4.2 request 模块
5.Handler与代理
6.cookie解析
7.异常处理
8.URL深入解析
8.1 urlparse模块
8.2 urlunparse模块
8.3 urljoin模块
8.4 urlencode模块
1.什么是Urllib?
Python内置的HTTP请求库
urllib.request 请求模块
urllib.error 异常处理模块
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块
2.相⽐Python2变化
Python2
import urllib2
response = urllib2.urlopen('http://www.baidu.com')
Python3
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
3.urlopen模块
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(response.read().decode('utf-8'))

公众号:yk 坤帝
后台回复 Urllib库基本使用 获取全部源代码
import urllib.parse
import urllib.request
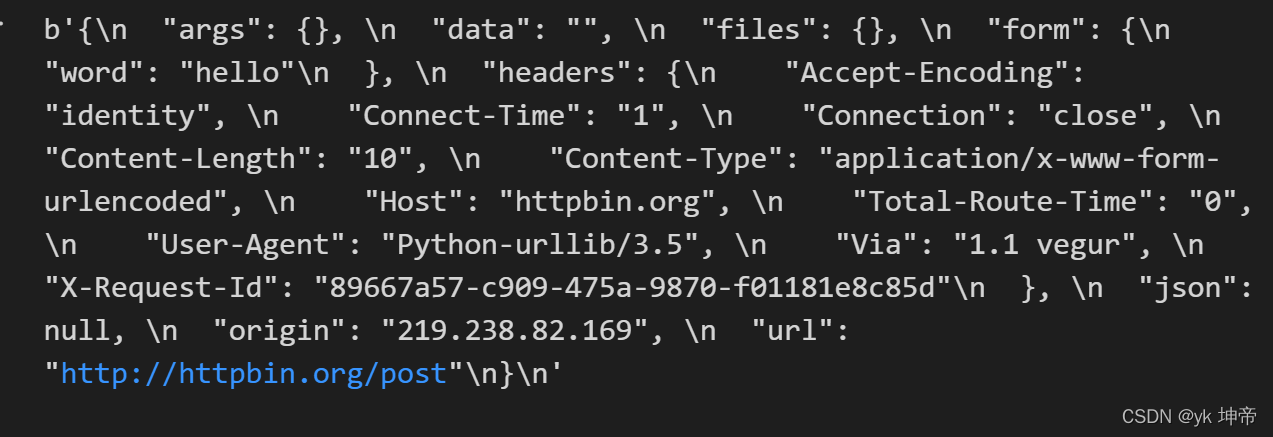
data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
response = urllib.request.urlopen('http://httpbin.org/post', data=data)
print(response.read())
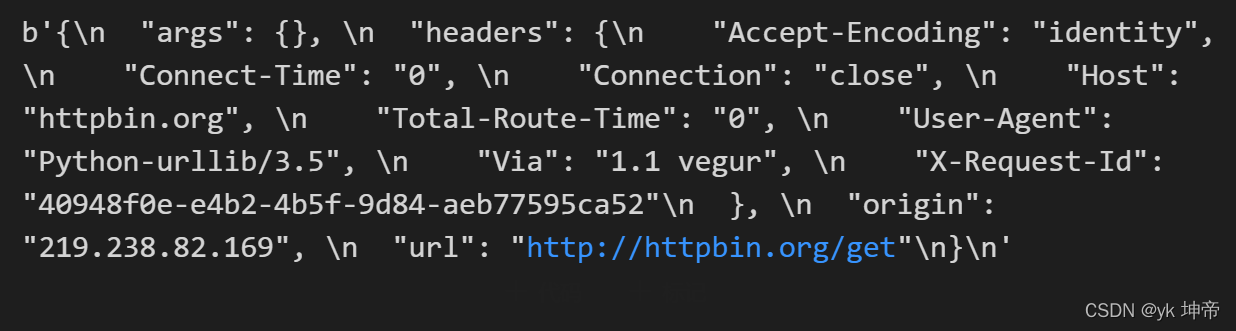
import urllib.request
response = urllib.request.urlopen('http://httpbin.org/get', timeout=1)
print(response.read())
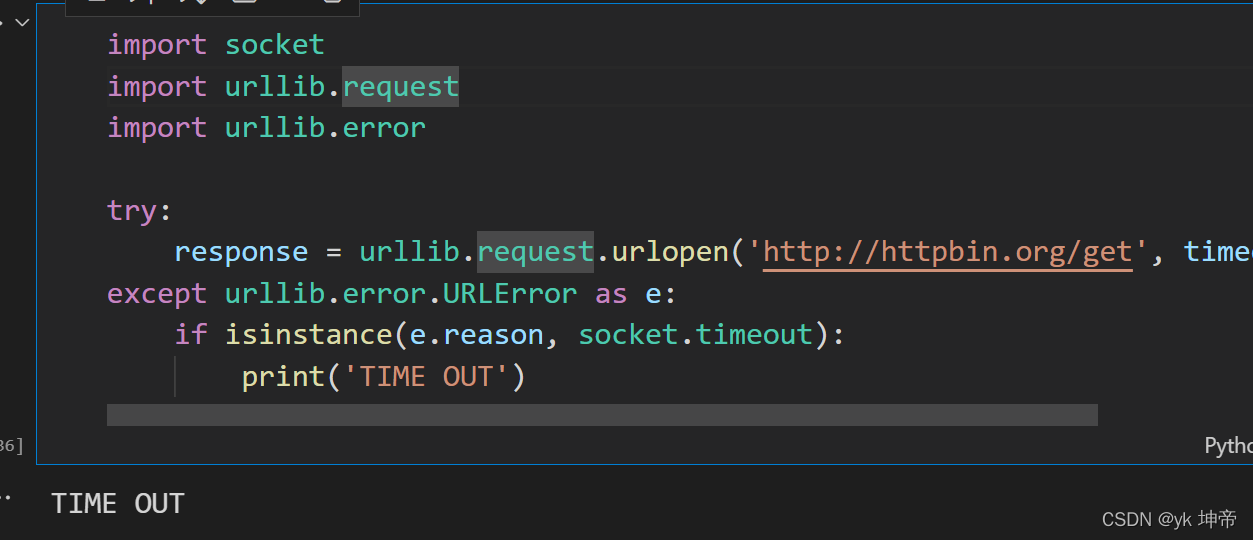
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://httpbin.org/get', timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout):
print('TIME OUT')
4.响应与响应类型
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(type(response))

4.1 状态码、响应头
公众号:yk 坤帝
后台回复 Urllib库基本使用 获取全部源代码
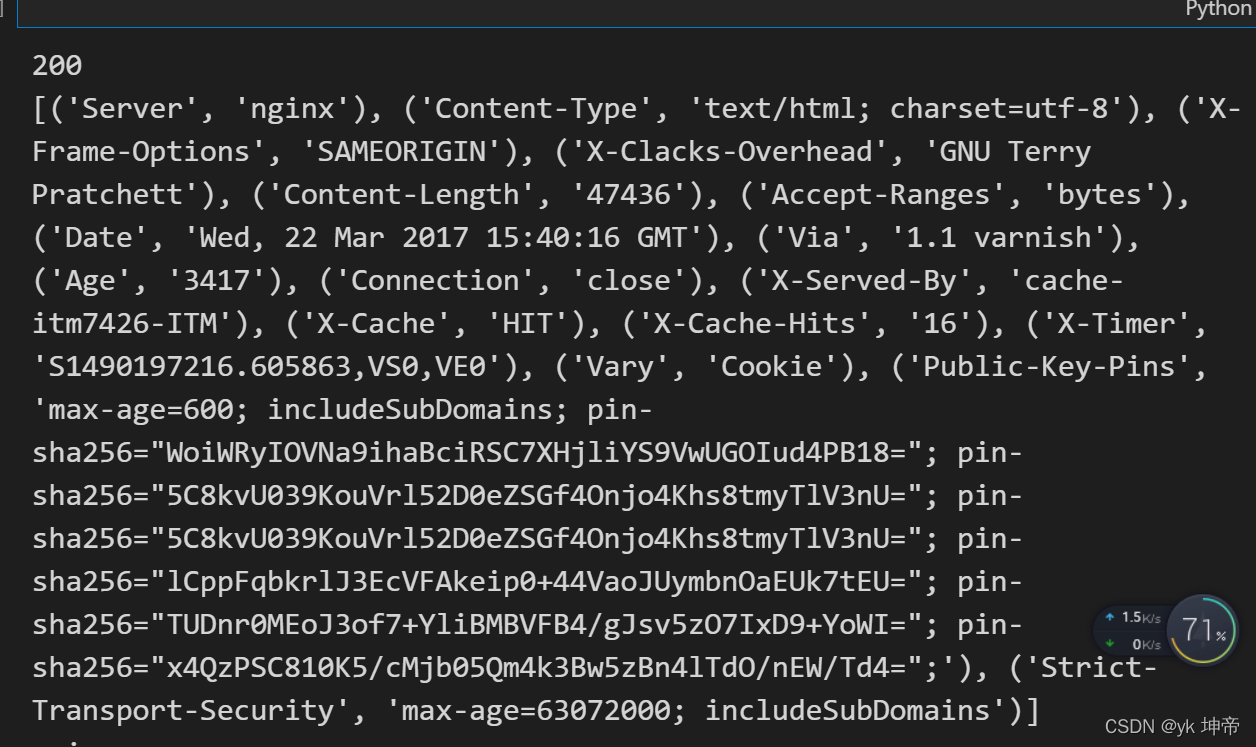
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(response.status)
print(response.getheaders())
print(response.getheader('Server'))
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(response.read().decode('utf-8'))
4.2 request 模块
import urllib.request
request = urllib.request.Request('https://python.org')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
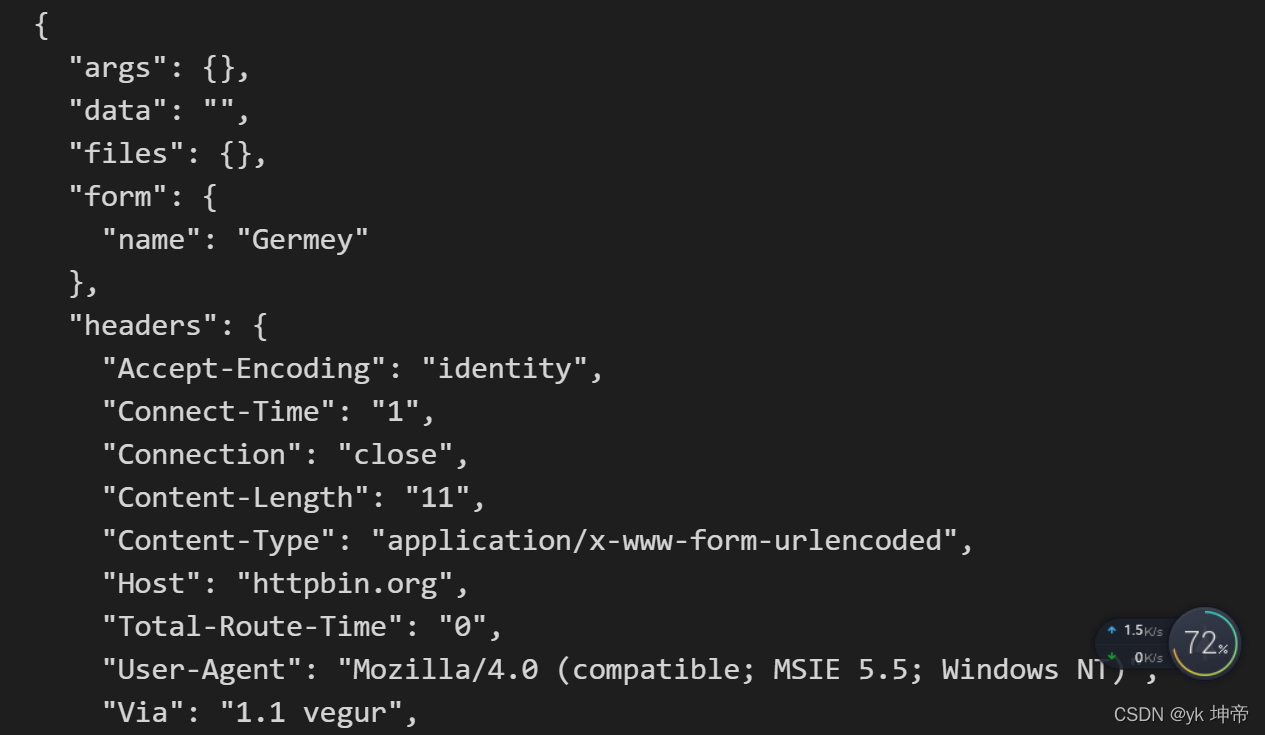
from urllib import request, parse
url = 'http://httpbin.org/post'
headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)',
'Host': 'httpbin.org'
}
dict = {
'name': 'Germey'
}
data = bytes(parse.urlencode(dict), encoding='utf8')
req = request.Request(url=url, data=data, headers=headers, method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))
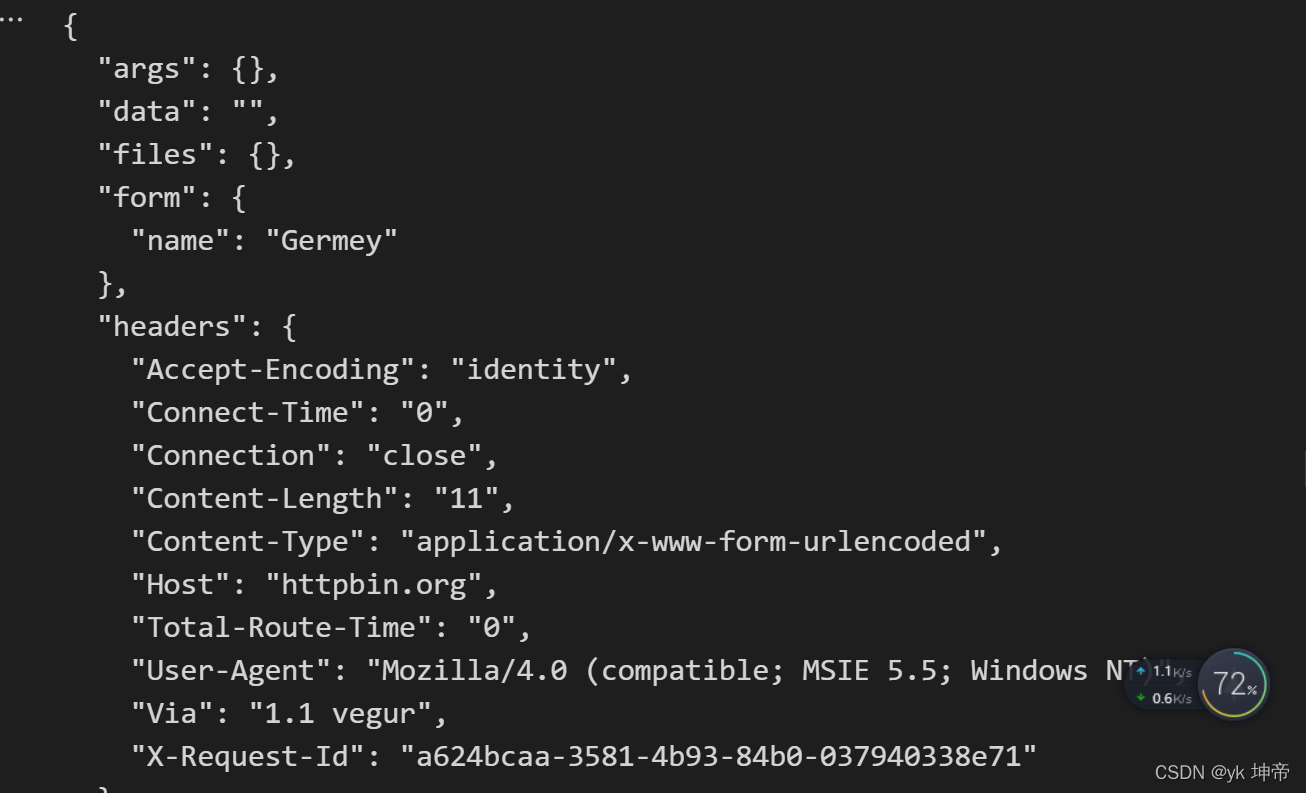
公众号:yk 坤帝
后台回复 Urllib库基本使用 获取全部源代码
from urllib import request, parse
url = 'http://httpbin.org/post'
dict = {
'name': 'Germey'
}
data = bytes(parse.urlencode(dict), encoding='utf8')
req = request.Request(url=url, data=data, method='POST')
req.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)')
response = request.urlopen(req)
print(response.read().decode('utf-8'))
5.Handler与代理ip的使用
import urllib.request
proxy_handler = urllib.request.ProxyHandler({
'http': 'http://127.0.0.1:9743',
'https': 'https://127.0.0.1:9743'
})
opener = urllib.request.build_opener(proxy_handler)
response = opener.open('http://httpbin.org/get')
print(response.read())

6.cookie解析
import http.cookiejar, urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
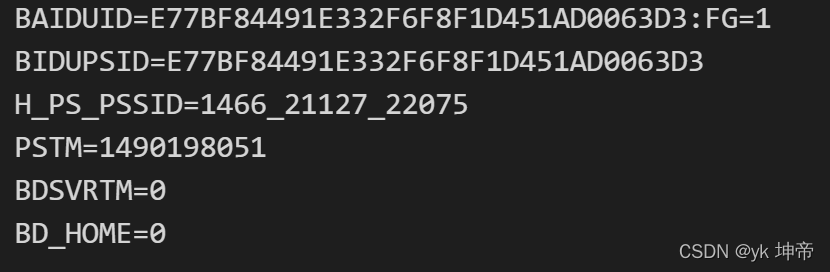
for item in cookie:
print(item.name+"="+item.value)
import http.cookiejar, urllib.request
filename = "cookie.txt"
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
import http.cookiejar, urllib.request
cookie = http.cookiejar.LWPCookieJar()
cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
print(response.read().decode('utf-8'))

7.异常处理
from urllib import request, error
try:
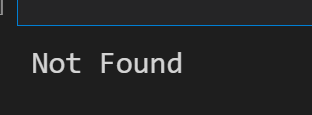
response = request.urlopen('http://cuiqingcai.com/index.htm')
except error.URLError as e:
print(e.reason)
from urllib import request, error
try:
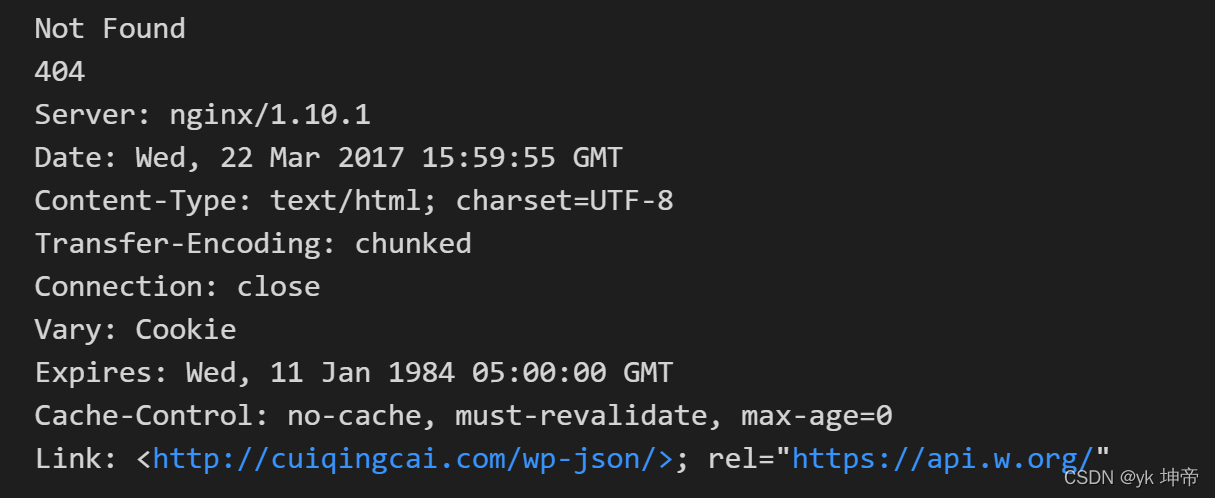
response = request.urlopen('http://cuiqingcai.com/index.htm')
except error.HTTPError as e:
print(e.reason, e.code, e.headers, sep='\n')
except error.URLError as e:
print(e.reason)
else:
print('Request Successfully')
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('https://www.baidu.com', timeout=0.01)
except urllib.error.URLError as e:
print(type(e.reason))
if isinstance(e.reason, socket.timeout):
print('TIME OUT')

8.URL深入解析
8.1 urlparse模块
urllib.parse.urlparse(urlstring, scheme=’’, allow_fragments=True)
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment')
print(type(result), result)

from urllib.parse import urlparse
result = urlparse('www.baidu.com/index.html;user?id=5#comment', scheme='https')
print(result)

from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment', allow_fragments=False)
print(result)

from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html#comment', allow_fragments=False)
print(result)

8.2 urlunparse模块
from urllib.parse import urlunparse
data = ['http', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment']
print(urlunparse(data))

8.3 urljoin模块
from urllib.parse import urljoin
print(urljoin('http://www.baidu.com', 'FAQ.html'))
print(urljoin('http://www.baidu.com', 'https://cuiqingcai.com/FAQ.html'))
print(urljoin('http://www.baidu.com/about.html', 'https://cuiqingcai.com/FAQ.html'))
print(urljoin('http://www.baidu.com/about.html', 'https://cuiqingcai.com/FAQ.html?question=2'))
print(urljoin('http://www.baidu.com?wd=abc', 'https://cuiqingcai.com/index.php'))
print(urljoin('http://www.baidu.com', '?category=2#comment'))
print(urljoin('www.baidu.com', '?category=2#comment'))
print(urljoin('www.baidu.com#comment', '?category=2'))

8.4 urlencode模块
from urllib.parse import urlencode
params = {
'name': 'germey',
'age': 22
}
base_url = 'http://www.baidu.com?'
url = base_url + urlencode(params)
print(url)

公众号:yk 坤帝
后台回复 Urllib库基本使用 获取全部源代码















 915
915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











