






本文主要对自动驾驶论文《Interaction-Aware Planning with Deep Inverse Reinforcement Learning for Human-like Autonomous Driving in Merge Scenarios》做分享与解读,来源IEEE-ITS(一区)主要介绍一下内容、场景以及主要创新贡献点及其对应的方法细节。
内容简介
本文提出了一种针对高速公路匝道合流场景下的拟人自动驾驶考虑交互的决策和规划方法。本文的方法并没有直接模仿人类匝道合流的行为,而是利用深度逆强化学习(DIRL)从自然驾驶数据中学习人类使用的决策和规划奖励函数,以提高可解释性。
本文采用了决策模块,通过选择适当的匝道合流间隙来减少规划的解空间。为了考虑交互因素,本文在规划模块中设计了融合自动驾驶车辆(主车,EV)和社会车辆的联合轨迹的奖励函数来评估规划轨迹的优劣。社会车辆的轨迹需要被预测,本文通过响应EV的行为来预测社会车辆的轨迹。决策和规划算法都遵循了一个“抽样、评估和选择”的框架。
场景介绍
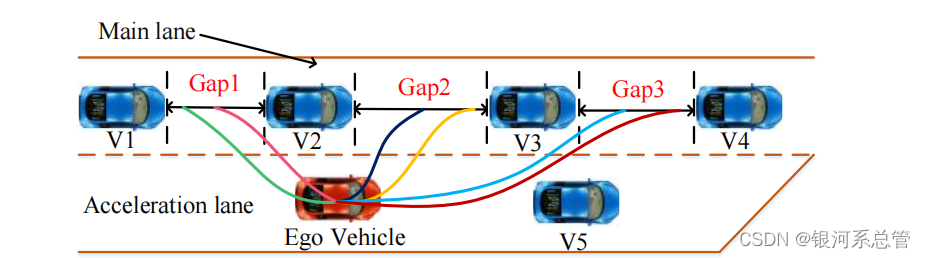
主车位于加速车道,目标是合并进入左侧的普通车道。在这个过程中仅考虑同样位于加速车道的前车V5(如果存在)以及普通车道距离主车最近的四辆车V1,2,3,4(如果存在)。主车需要选择目标的切入间隙(图中的gap1,2,3),被称为目标间隔(target gap)。
主要创新点及对应的方法特色
“有效降低了解空间的维度”——如何降低解空间?
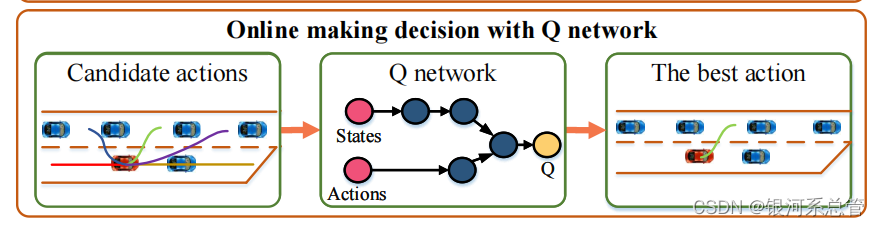
- 首先本文在决策模块中将决策归纳为五个动作:切入gap1、切入gap2、切入gap3、不切入但加速、不切入但减速;也就是说后续的规划是基于这五个动作其中一个展开的,不需要规划所有可能的情况,这一决策模块有效缩减了解空间的大小。
- 采用了一种基于采样的五次多项式拟合轨迹规划方法,通过采样间隔的设计,可减小解空间,将连续空间转换为离散空间。
“使用深度逆强化学习实现拟人决策规划”——如何利用深度逆强化学习?
逆强化学习(IRL)用于从观察到的智能体行为中推断出其背后的奖励函数。与传统的强化学习不同,强化学习通常假设已知奖励函数,然后寻找最优的策略。而逆强化学习的目标是逆向解析,即从智能体的行为推断出它们可能追求的奖励函数,从而更好地理解其动机和行为。
因此可以利用逆强化学习理解其他社会车辆驾驶时的奖励函数,从而理解社会车辆驾驶员的行为机理。本文中深度逆强化学习指的是将驾驶员的奖励函数刻画为一个深度神经网络,文中具体的使用方法如下:
- 在决策过程中,首先利用NGSIM中的匝道汇入数据训练一个离线的奖励网络,目的是使网络输出的最高value的动作就是数据集中车辆的实际动作;实际使用中,主车选择value最高的动作作为最佳动作。
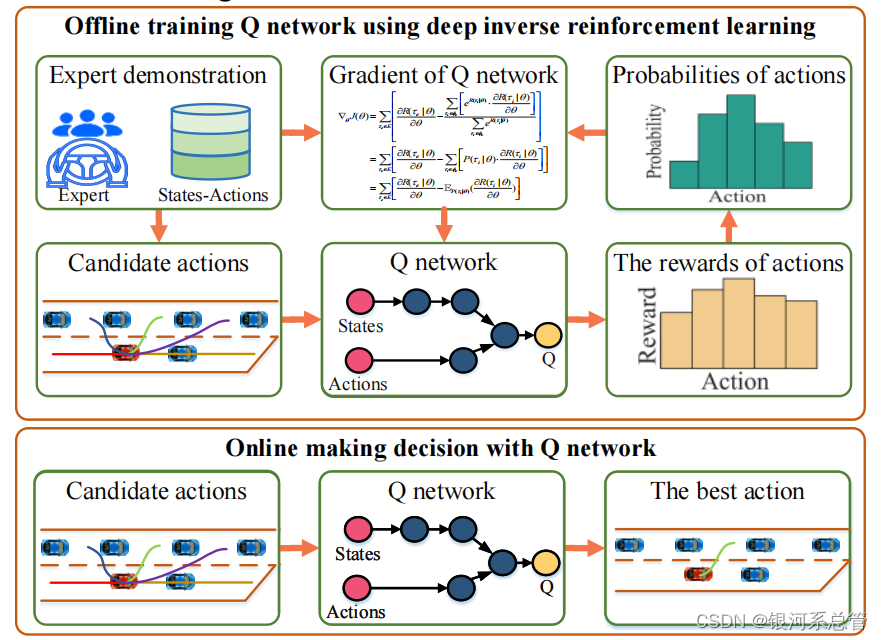
图3 决策中的深度逆强化学习 - 在规划过程中,主车存在多条规划候选轨迹,对应的主车隔壁车道上的后车的轨迹可以被预测出,将主车和后车的联合轨迹作为网络输入,得到联合轨迹的value,最终选择最高value对应的轨迹。该奖励网络的训练也是基于NGSIM的实际数据作为专家表示。
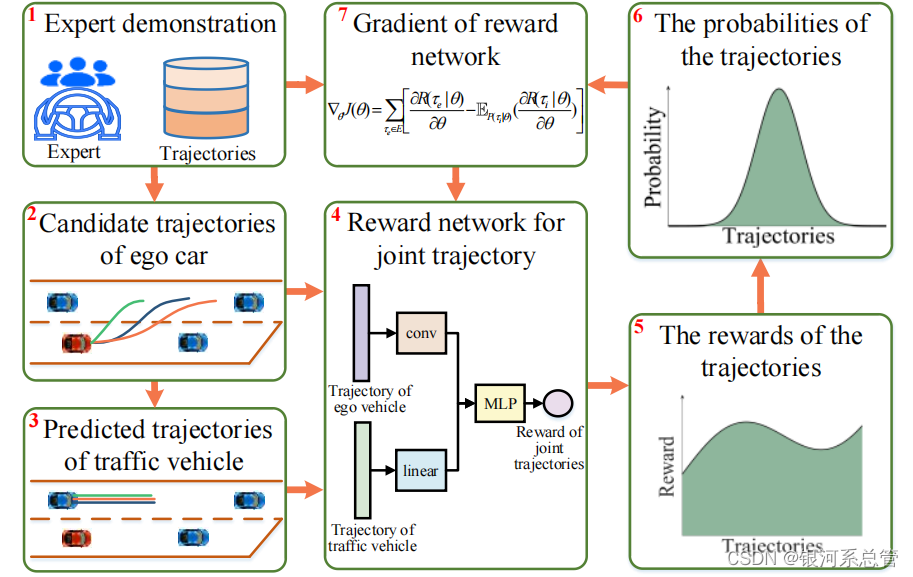
图4 规划中的深度逆强化学习


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









