







文章目录
复习提纲
第一章 基本概念
第一章 概述


第二章 文法
- 语法是指一组规则,用来定义什么样的符号序列是合法的。语义则是进一步从符号的意义进行判断,合法的符号序列是构成正确的程序。类型匹配、变量作用域等在语法分析阶段无法用上下文无关文法检查,但可以利用语义分析来完成判断。
- 0型:短语文法,产生式左边至少含有一个非终结符;1型:上下文有关文法,文法右边的长度>=左边的长度;2型:上下文无关文法,3型:正规文法;
- 语法树指明用了哪个产生式,但没有指明顺序;最右推导又称规范推导;
- 二义性:一个文法的某个句子存在2棵语法树;
- 语法分析方法:自底向上(从输入符号串开始,逐步归约),自顶向下(从文法开始符号开始)
第三章 词法分析
- 词法分析是读入源程序,输出单词符号
- NFA可以有若干个开始状态,而DFA只能由一个开始状态
第四章 语法分析
- 语法分析的作用主要是识别由词法分析给出的单词符号序列是否是给定文法的正确式子。
- 自顶向下分析(面向目标的分析方法)包括确定分析和不确定分析;自底向上分析包括算符优先分析LR分析。
- 一个预测分析器由三个部分组成:预测分析程序、先进后出栈、预测分析表。
- 若预测分析表没有多重入口,那么该文法是LL(1)文法。
第五章 语法制导翻译
- 语法制导翻译就是在语法分析的同时,根据文法规则进行语义处理,并生成中间代码和目标代码。
- 若产生式左部的单非终结符A的属性由右部各非终结符的属性值决定,则A的属性称为综合属性。
- 若产生式右部符号B的属性值根据左部非终结符的属性值或右部其他符号的属性值决定,则B的属性为继承属性。
- 非终结符既可有综合属性,也可有继承属性,但文法开始符号没有继承属性;终结符只有综合属性,它们由词法程序提供。
第二章 语言基础知识
- 基本概念
- 求给定句型的推导(最左、最右)
- 画出给定句型的语法分析树,并指出其短语,直接短语和句柄
- 证明文法的二义性


第三章 词法分析
- 基本概念
- NFA------〉DFA---------〉最小化 DFA


第四章 语法分析
- 基本概念
- 消除文法的左递归
- 提取公共左因子
- LL(1)文法,求 FIRST 和 FOLLOW,求预测分析表
- SLR(1)分析表构造
- 根据 LR 分析表分析句子
消除左递归:

LL(1):

上图中用到的LR表:
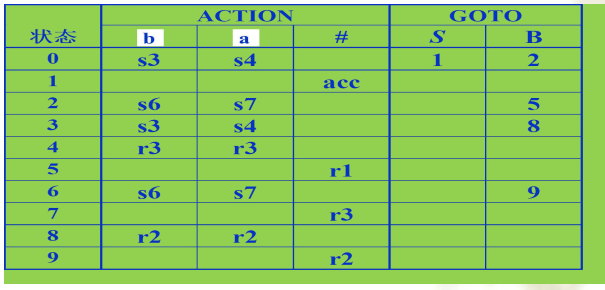
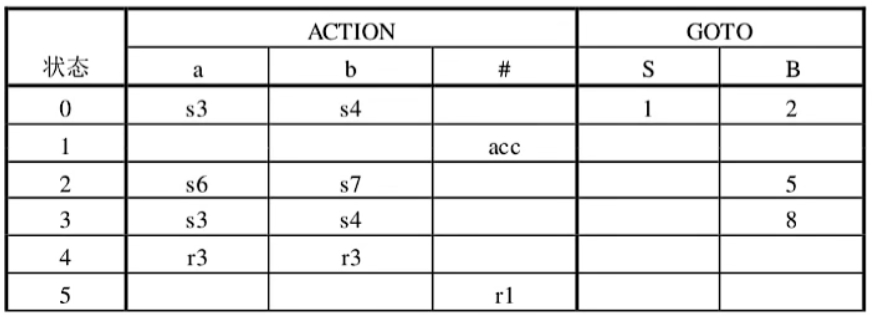

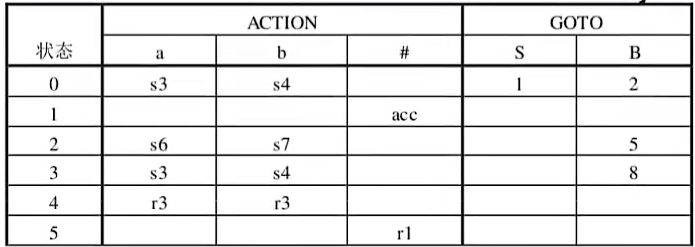
SLR(1)分析表的构造




第五章 语法制导翻译
基本概念,继承属性和综合属性判断
根据给定的语法制导定义或翻译模式,指出语义功能,画出给定句子的注释分析树或给出翻译结果


第六章 中间代码生成
给定表达式,求其逆波兰式、三元式和四元式
给定语句,求其四元式

往年真题考点
填空题
1.综合属性用于自下而上传递信息,继承属性自上而下传递信息。终结符只有综合属性,它由词法分析器提供。
2.编译过程中词法分析器是从源程序中识别出一个个单词符号。
3.设G是一个给定的文法,S是文法的开始符号,如果S推导出x(其中x∈(VN∪VT)*),则称x是文法的一个 句型。
4.在自底向上的分析方法中,LR方法每次归约当前句型的句柄。
5.通常用 上下文无关文法来描述程序语言的语法。
若小写字母表示终结符,大写字母表示非终结符,则A→.aB 称为移进项目。
6.高级程序设计语言的翻译主要有两种方式:编译器和解释器,二者的根本区别在于是否生成目标代码。
单项选择题
1.一个编译程序中,不仅包含词法分析、语法分析、中间代码生成、代码优化和目标代码生成等五个部分,还应包括( 表格处理和出错处理)。其中( 中间代码生成)和代码优化部分不是每个编译程序都必需的。
2.文法G所描述的语言是( 由文法的开始符号推出的所有终结符串 )的集合。
3.一个LR(1)文法合并同心集后若不是LALR(1)文法,则其分析表不可能存在移进—归约冲突。
4.如果一个文法满足( ),则称该文法是二义文法。
① 文法的某一个句子存在两棵(包括两棵)以上的分析树
② 文法中存在某个句子,它有两个(包括两个)以上的最右(最左)推导
③ 文法中存在某个句子,它有两个(包括两个)以上的最右(最左)归约
④ 在进行归约时,文法的某些规范句型的句柄不唯一
5.在语法分析中,自顶向下分析试图为输入符号串构造一个最左推导。
6.已知文法G[S]: S→AA A →Aa︱a 不是LL(1) 文法的理由是FIRST(Aa)∩FIRST(a)≠Φ
应用题
1.(8分)给定文法
E → T { R.i := T.p }
R { E.p := R.s }
R → addop
T { R1.i := mknode( addop.val, R.i, T.p ) }
R { R.s := R1.s }
R → ε { R.s := R.i }
T → ( E ) { T.p := E.p }
T → id { T.p := mkleaf ( id, id.entry ) }
T → num { T.p := mkleaf ( num, num.val ) }
(1) 指出文法中的各非终结符具有哪些综合属性和哪些继承属性
⑵ 画出按本翻译模式处理表达式 a + 20 + ( b - 10 ) 时所生成的语法树。
2.将下列语句翻译为三地址语句的三元式和四元式表示:
a:=(b+c)e+(b+c)/f
解:三元式序列为:
(1)(+,b,c)
(2)( ,(1) ,e)
(3)(+ ,b,c)
(4)(/ ,(3) ,f)
(5)(+ ,(2) ,(4))
(6)(:= ,a,(5))
四元式序列为:
(1)(+ ,b,c,T1)
(2)(* ,T1,e,T2)
(3)(+ ,b,c,T3)
(4)(/ ,T3,f,T4)
(5)(+ ,T2,T4,T5)
(6)(:= ,T5,-,a) //序号(6)尤其值得注意
3.(8分)已知文法G(S):(说明:文法中number,“,”,(,) 是终结符)
S→number | List
List → (Seq)
Seq → Seq, S | S
(1) 请写出句子(4,(3,5))的最左推导
解:
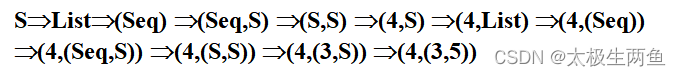
(2) 画出该句子的分析树,并指出其简单短语和句柄。
解:


解: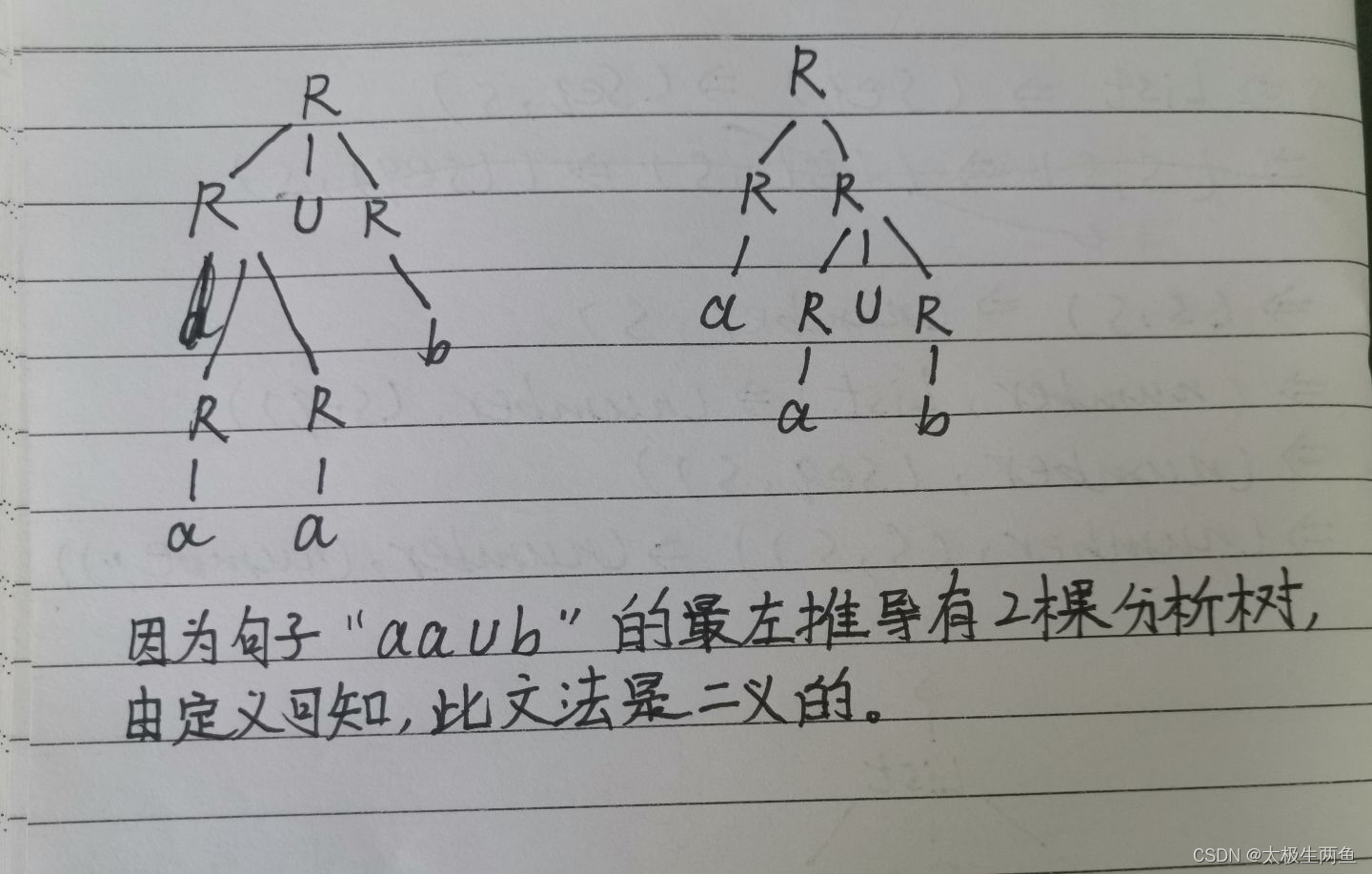
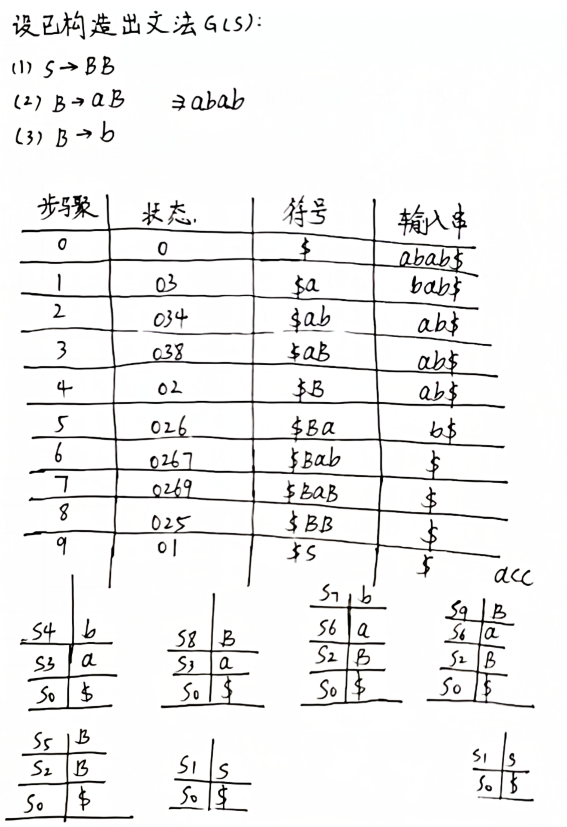
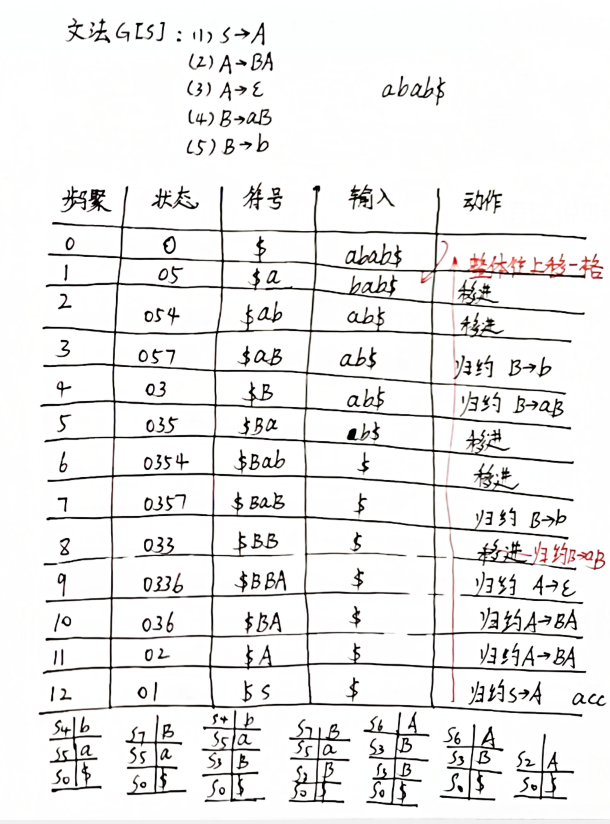
5.(8分)文法G[S]及其LR分析表如下,请给出对串abab$的分析过程。
G[S]: (1) S → A (2) A → BA (3) A → ε (4) B → aB (5) B → b
G[S]的LR分析表:
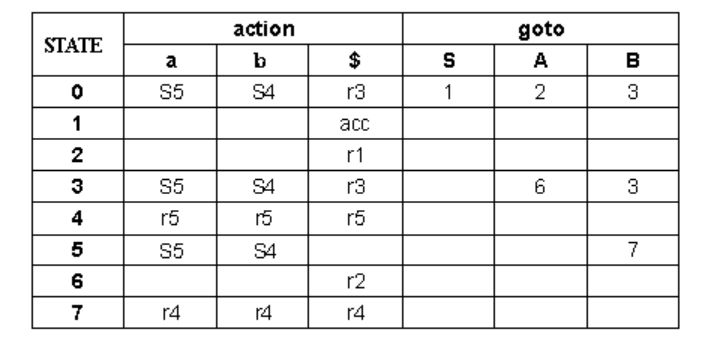
abab$的分析过程如下:
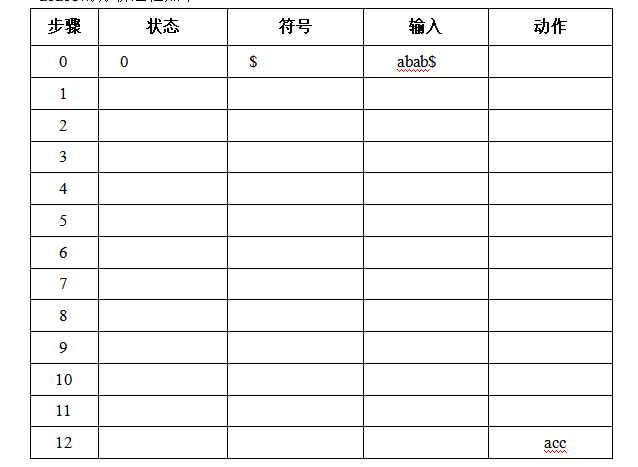
综合题
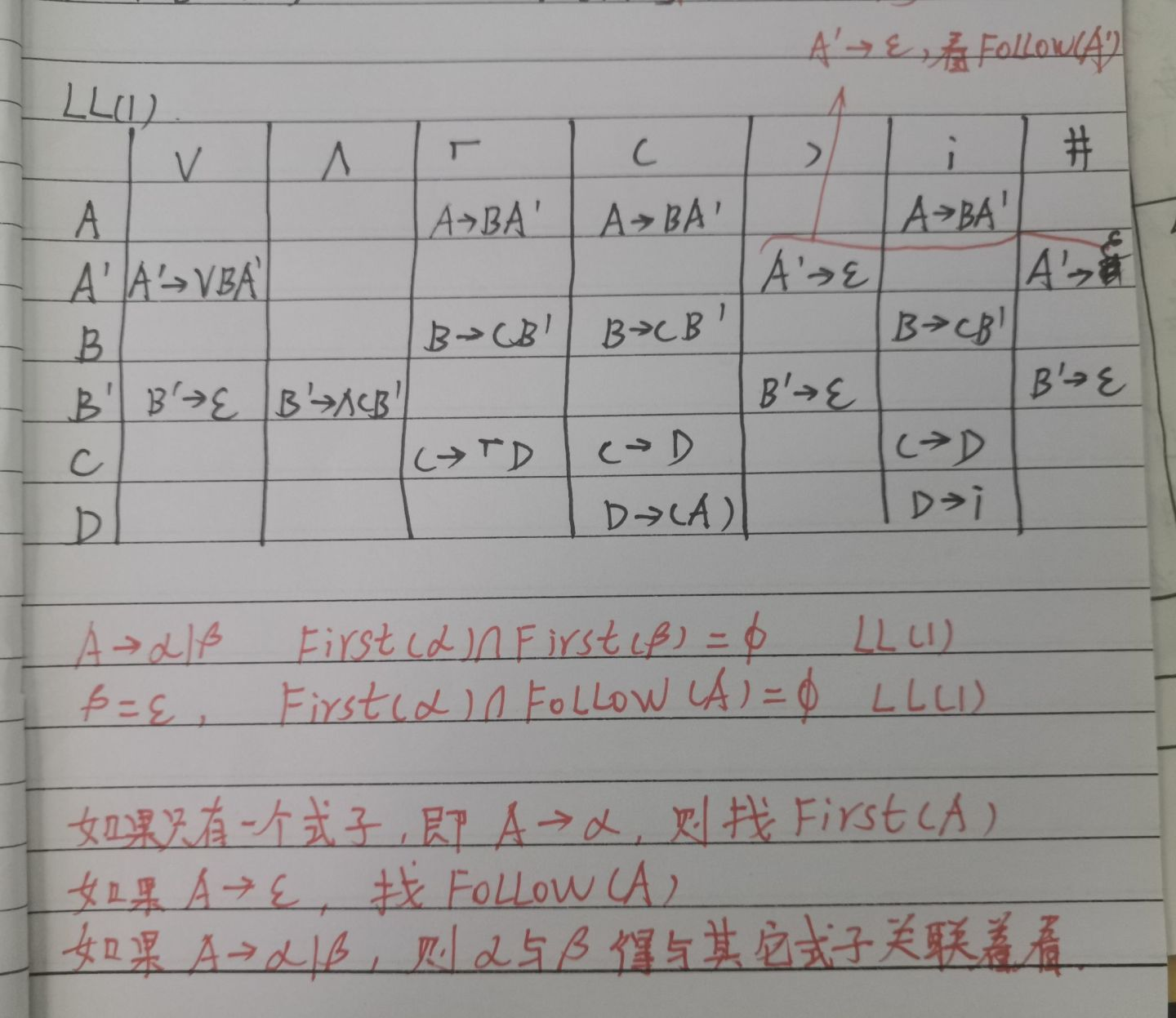
- 考虑文法G:(说明:下面文法中,∨,⌐,∧,(,),i 都是终结符)
A→ A∨B | B
C→ ⌐D | D
B→ B∧C | C
D→ (A) | i
(1) 请消除文法G的左递归

(2) 计算这个无左递归的文法的每个非终结符的 FIRST 集和 FOLLOW 集

(3)构造无左递归文法的LL(1)分析表
2.(15分)对于正规表达式 (a|b)*a(a|b)。
(1) 构造该正规式所对应的NFA(画出转换图)
(2) 将所求得NFA确定化(画出DFA的转换图)
(3)将所求得DFA最小化(画出极小化后的转换图)
第五章 语法制导翻译
基本概念
继承属性&综合属性
注释分析树
翻译结果
第六章
补充
1.由文法的开始符号出发经过若干步(包括0步)推导产生的文法符号序列称为句型。


2.赋值语句不需要回填技术。
3.如果两个临时变量的作用域不相交,则可以将它们分配在同一单元中。
4.运算符与运算对象类型不符属于静态语义错误。
对一般程序设计语言而言,其编译程序的符号表应包含哪些内容及何时填入这些信息不能一概而论。
5.对于一个基本块来说,只有一个入口语句和出口语句。
采用DAG图不可以实现的优化有删除归纳变量。





未完待续。。。
















 5037
5037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











