







leecode高频sql50题-连接-学生们参加各科测试的次数
一、前提条件和题目
前提条件:
学生表: Students
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| student_id | int |
| student_name | varchar |
+---------------+---------+
在 SQL 中,主键为 student_id(学生ID)。
该表内的每一行都记录有学校一名学生的信息。
科目表: Subjects
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| subject_name | varchar |
+--------------+---------+
在 SQL 中,主键为 subject_name(科目名称)。
每一行记录学校的一门科目名称。
考试表: Examinations
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| student_id | int |
| subject_name | varchar |
+--------------+---------+
这个表可能包含重复数据(换句话说,在 SQL 中,这个表没有主键)。
学生表里的一个学生修读科目表里的每一门科目。
这张考试表的每一行记录就表示学生表里的某个学生参加了一次科目表里某门科目的测试。
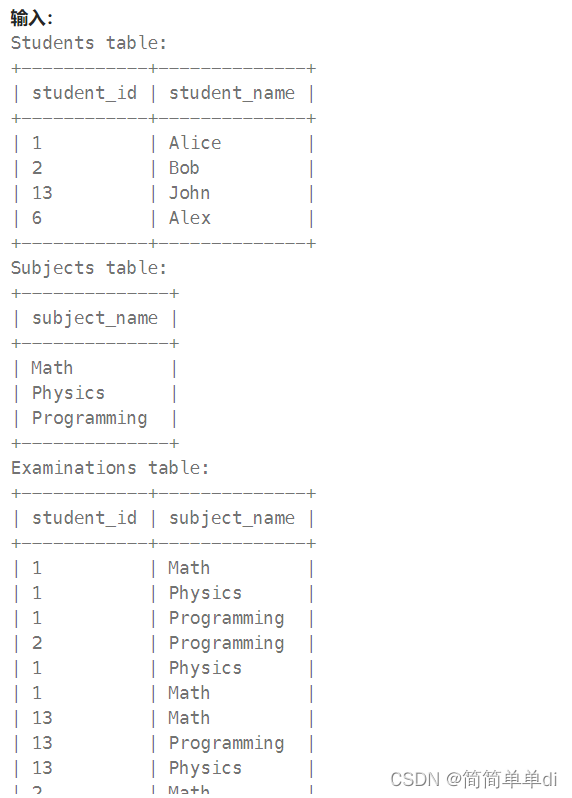
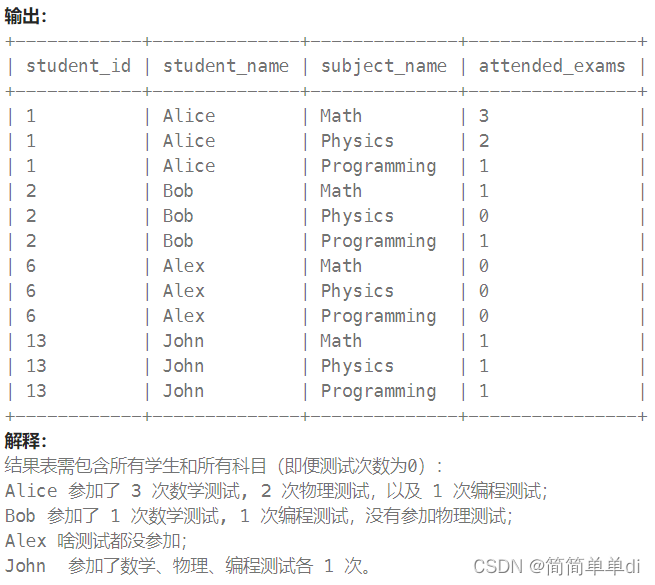
题目:查询出每个学生参加每一门科目测试的次数,结果按 student_id 和 subject_name 排序。
查询结构格式:
二、尝试理解题目
看题目发现有三张表,查看输出知道需要知道四个字段,然后想把学生表和考试表连接起来,然后进行分组
select s.student_id,student_name,subject_name, attended_exams from Students s right join Examinations e on s.student_id=e.student_id group by student_id;
于是需要计算出attended_exams 每个学生每个科目的测试次数,而且中间又觉得科目名没有用。然后实在不知道怎么写,还是看题解吧。
三、理解题解
看了一个题解,如下:
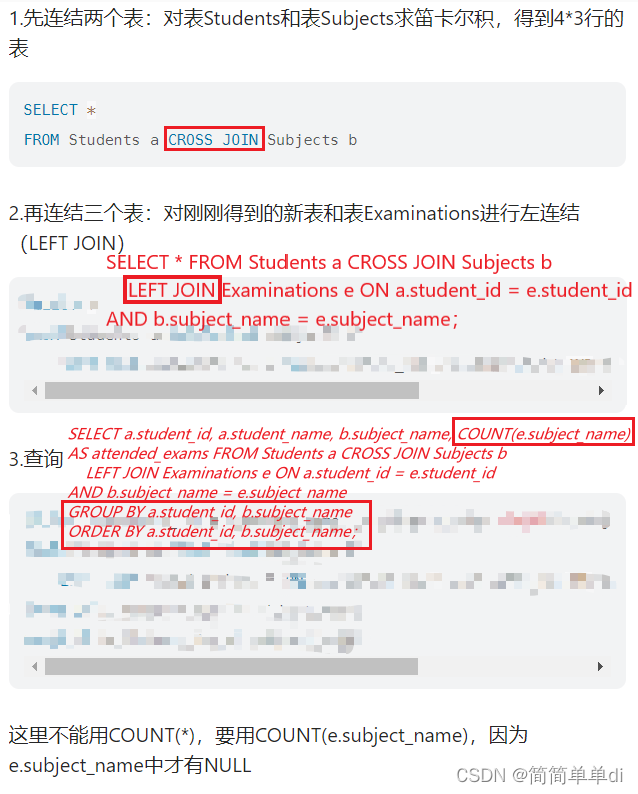
第一步重点是了解CROSS JOIN(交叉连接,笛卡尔连接)
第二步重点是左连接后面的筛选条件没想到
第三步重点是count()和group by
1.CROSS JOIN
我的理解是两张表之间没有相同的字段可以连接起来,利用交叉连接把Students表的一行和Subjects的每一行合并,直到Students表的每一行都完成了合并。
其实哪个表在前面可能有区别,但因为这个有序的意义不大,等用到的时候再说。附上笛卡尔积的理解

下面是语法,这个语法也挺有意思的,不重要,依旧是用到的时候再看。但是我后面就留意到这个问题了。

所以这样我也知道了subjects表存在的意义,得到的结果是每个学生都有三个科目。
2.左连接
上面合并的表和第三个表左连接的on后面的条件必然是student_id,但是还有一个与条件subject_name需要相等我是没有第一时间想到的。由于合并的表中的student_id和Examinations表中的student_id字段不是一一对应的,需要再给一个条件使合并的表中的student_id选中Examinations表中多个相同的student_id字段。
3.count()
count()里面的参数是很重要的,count(*)和count(e.subject)的区别不理解,下面是我尝试理解的思路。
1)count(*)的理解:
count(*)是统计记录数,也就是怎么样都不会是0是吗,不会忽略记录值为0的记录,那这个记录数就是1.
2)count(e.subject)的理解:
如果为null就是0吗,忽略记录值为null的,所以这里为null的话就返回0,就是等于忽略了null。
所以这里给自己明确一下,二者都是统计记录数;但是如何使用达到自己的结果是需要仔细斟酌的。这些方式的效率有区别,还有count(1),但是对于目前的我来说不是重点,以后再说。
4.Group by通过之前的题练习后,发现理解的不够深刻,进一步理解
Group by两个字段,有点懵逼了,但是我理了一下后理解了
Group by两个字段,是先对第一个字段分组,然后以这上面分组后的结果再利用第二个地段分组,这个group by的结果是一个结果,但是是两个字段按照顺序依次分组。
把group by查询结果当成一个表count一下记录数,因为这里有两个字段,自然是两个字段分组后的结果当成一个表,我还一直在想为什么count算的不是第一个字段分组后的记录数。
四、总结
1.笛卡尔积的学习,交叉连接的概念挺重要的。
但是有个小插曲,因为在运行时间那里,恰巧点到了第一个运行时间很短的人的答案。
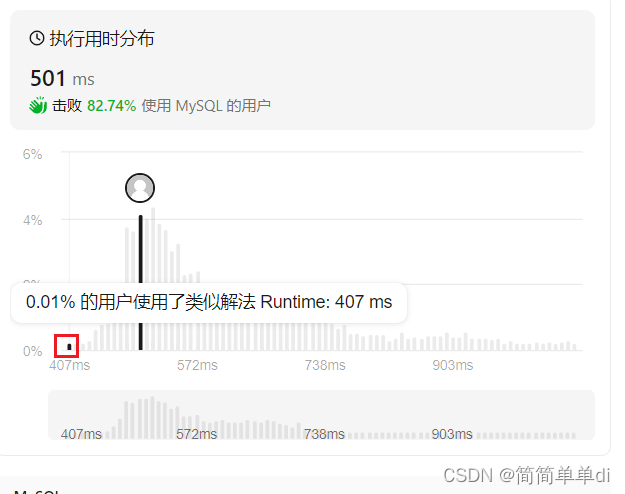
是这样的解法,我发现他没有加cross

于是我猜测如果两张表没有相同的字段,其实好像默认了就会进行交叉连接,即使你写上的是join,没有加上cross。
测试了一下果然,这是两张表查询结果,如下图。
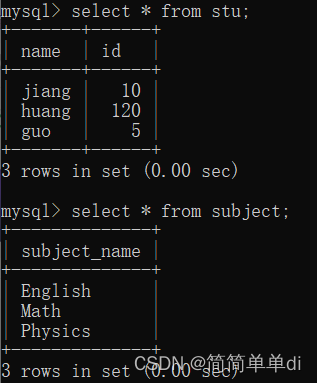
我用select * from stu join subject;进行查询,果然显示的结果表示是交叉连接。如下图
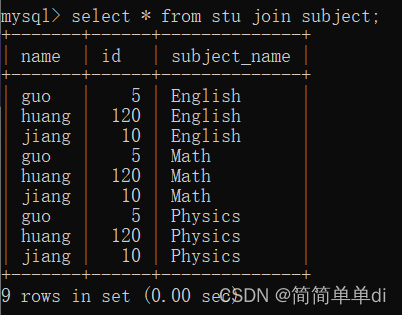
然后我又有个小联想,如果两方有相同的字段,用join进行连接,其实默认的就是内连接是吧,针不戳,联系起来了。
那么就是使用join进行连接的时候,如果两方有相同的字段,就是内连接;没有相同的字段就是交叉连接。但是其实加上了inner,也是一样的结果,如下图。
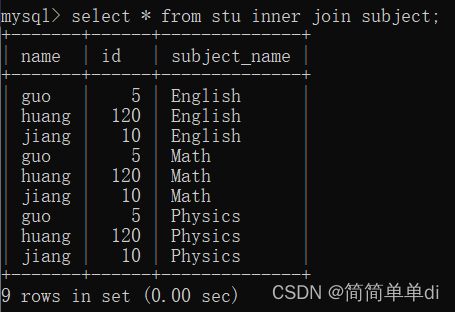
那就是说,join就是inner join的简写,但是如果连接的时候没有相同的字段的话,那就会交叉连接起来,不会报错。对的,就是cross join的写法标准些,便于人理解。其实上面那张截图别人的笛卡尔积语法的图片就有说明了,只是这是我理解的过程,或者说帮助我理解他的话的过程。
2.针对左连接(右连接也是同理),如果不是左右的表连接的字段不是一对一对应的话,需要添加附加条件,使之一一对应。
3.count(*)和count(字段)含义加上案例的深刻理解
4.group by两个字段的理解,分组得到的最终结果是先对第一个字段分组,然后根据结果再利用第二个字段分组;没有以第一个字段分组的中间状态。















 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









