







1. k8s 网络
Kubernetes网络是指在Kubernetes集群中不同组件之间进行通信和交互的网络架构。
本文通过一下五个层次介绍 k8s 网络
- 容器网络接口(CNI)
- Pod网络
- Service网络
- Ingress网络
- NetworkPolicy
1.1 容器网络接口CNI(Container Network Interface)
Kubernetes网络的底层是CNI层,是一个标准,不同的Pod网络技术可以实现独立的CNI插件形式和K8s进行集成,用于为容器分配IP地址、创建网络接口和配置网络环境。
- Pod是最小的可调度单元,通常包含一个或多个容器。Pod内的容器可以通过localhost(127.0.0.1)进行通信,这种通信方式不需要网络环境的支持,因此可以实现较低的延迟和较高的吞吐量。
- 在Pod内部,容器之间可以通过共享网络命名空间进行通信。所有容器共享Pod的IP地址和网络命名空间,它们可以使用localhost或Pod的IP地址进行通信。可以通过在Pod的配置文件中指定容器之间的端口映射来定义容器之间的通信方式。
- 节点上的Kubelet通过CNI标准接口操作Pod网路,例如添加或删除网络接口等,它不需要关心Pod网络的具体实现细节
- 例如,在一个Pod中有两个容器A和B,A需要向B发送HTTP请求。可以在Pod的配置文件中为容器A和容器B分别指定端口号,然后在容器A中使用localhost和容器B的端口号进行通信。容器B在接收到请求后可以返回HTTP响应。
1.1.1 Network Namespace
Network Namespace 里面能网络实现的内核基础。狭义上来说 runC 容器技术是不依赖于任何硬件的,它的执行基础就是它的内核里面,进程的内核代表就是 task,它如果不需要隔离,那么用的是主机的空间( namespace)。

如果一个独立的网络 proxy,或者 mount proxy,里面就要填上真正的私有数据。它可以看到的数据结构如上图所示。
从感官上来看一个隔离的网络空间,它会拥有自己的网卡或者说是网络设备。网卡可能是虚拟的,也可能是物理网卡,它会拥有自己的 IP 地址、IP 表和路由表、拥有自己的协议栈状态。这里面特指就是 TCP/Ip协议栈,它会有自己的status,会有自己的 iptables、ipvs。
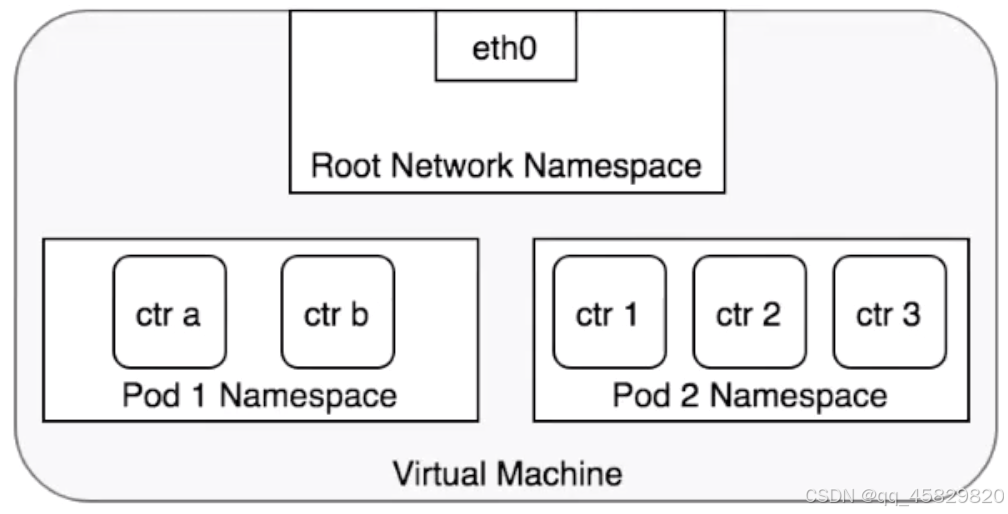
这张图可以清晰表明 pod 里 Netns 的关系,每个 pod 都有着独立的网络空间,pod net container 会共享这个网络空间。一般 K8s 会推荐选用 Loopback 接口,在 pod net container 之间进行通信,而所有的 container 通过 pod 的 IP 对外提供服务。另外对于宿主机上的 Root Netns,可以把它看做一个特殊的网络空间,只不过它的 Pid 是1。
1.1.2 pod的网络设置流程
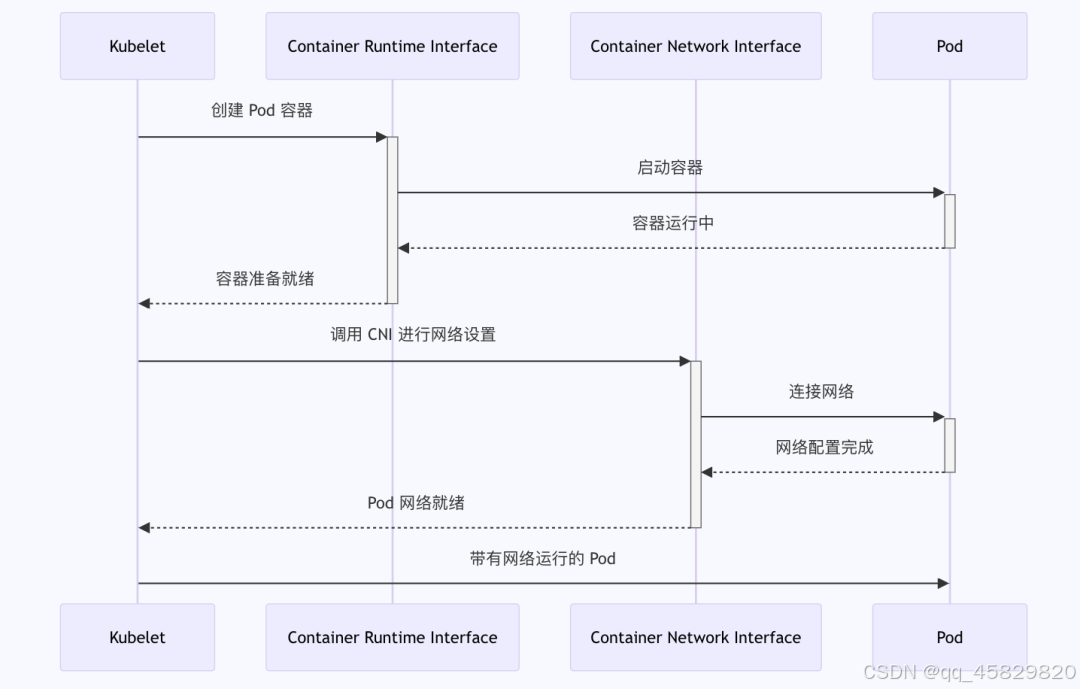
-
1. Kubelet 到 CRI:Kubelet 指示 CRI 创建已调度的 Pod 的容器。
-
2. CRI 到 Pod:容器运行时在 Pod 中启动容器。
-
3. Pod 到 CRI:一旦容器运行,它会向容器运行时发出信号。
-
4. CRI 到 Kubelet:容器运行时通知 Kubelet 容器已准备就绪。
-
5. Kubelet 到 CNI:容器已启动,Kubelet 调用 CNI 为 Pod 设置网络。
-
6. CNI 到 Pod:CNI 为 Pod 配置网络,将其连接到必要的网络接口。
-
7. Pod 到 CNI:网络配置完成后,Pod 向 CNI 确认网络设置。
-
8. CNI 到 Kubelet:CNI 通知 Kubelet Pod 的网络已准备就绪。
-
9. Kubelet 到 Pod:现在 Pod 完全可操作,两个容器均已运行且网络已配置。
1.2 Pod的网络
Pod 网络(也称为集群网络)处理 Pod 之间的通信。它确保(除非故意进行网络分段):
- 所有 Pod 可以与所有其他 Pod 进行通信, 无论它们是在同一个节点还是在不同的节点上。 Pod 可以直接相互通信,而无需使用代理或地址转换(NAT)。
- Pod是Kubernetes中最小的部署单元,每个Pod都有一个唯一的IP地址,Pod内的容器共享该IP地址和网络命名空间。
1.3 Service 网络
Service网络层是Kubernetes网络的中间层,它定义了Service之间的网络通信,为Service提供了一个虚拟IP地址,将请求路由到后端Pod的实际IP地址。
Service网络层可以使用ClusterIP、NodePort、LoadBalancer等多种类型。
注:这一层解决的是—Pod与Service之间的网络 。下一章节节详细介绍
1.4 Ingress网络层(Gateway API)
Ingress网络层是Kubernetes网络的顶层,它允许外部流量进入Kubernetes集群,并将请求路由到不同的Service。已经停止维护,被Gateway API取代。
注:这一层解决的是—Internet与Service之间的网络。
1.4.1 Gateway API
Gateway API 具有三种稳定的 API 类别:
- GatewayClass: 定义一组具有配置相同的网关,由实现该类的控制器管理。
- Gateway: 定义流量处理基础设施(例如云负载均衡器)的一个实例。
- HTTPRoute: 定义特定于 HTTP 的规则,用于将流量从网关监听器映射到后端网络端点的表示。 这些端点通常表示为 Service。
Gateway API 被组织成不同的 API 类别,这些 API 类别具有相互依赖的关系,以支持组织中角色导向的特点。 一个 Gateway 对象只能与一个 GatewayClass 相关联;GatewayClass 描述负责管理此类 Gateway 的网关控制器。 各个(可以是多个)路由类别(例如 HTTPRoute)可以关联到此 Gateway 对象。 Gateway 可以对能够挂接到其 listeners 的路由进行过滤,从而与路由形成双向信任模型。
下图说明这三个稳定的 Gateway API 类别之间的关系:
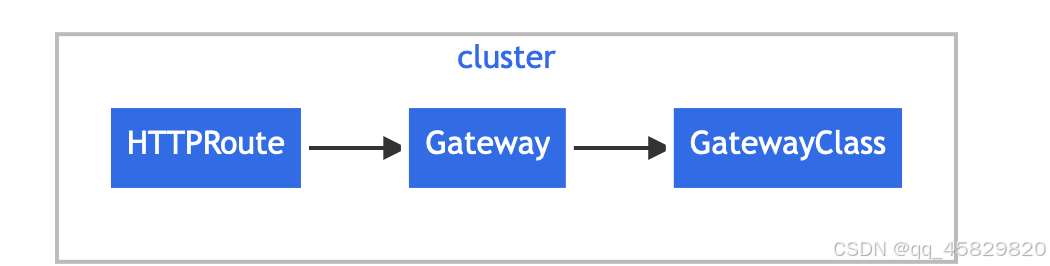
【GatewayClass】
Gateway 可以由不同的控制器实现,通常具有不同的配置。 Gateway 必须引用某 GatewayClass,而后者中包含实现该类的控制器的名称。
下面是一个最精简的 GatewayClass 示例:
apiVersion: gateway.networking.k8s.io/v1
kind: GatewayClass
metadata:
name: example-class
spec:
controllerName: example.com/gateway-controller在此示例中,一个实现了 Gateway API 的控制器被配置为管理某些 GatewayClass 对象, 这些对象的控制器名为 example.com/gateway-controller。 归属于此类的 Gateway 对象将由此实现的控制器来管理。
有关此 API 类别的完整定义,请参阅 GatewayClass。
【Gateway】
Gateway 用来描述流量处理基础设施的一个实例。Gateway 定义了一个网络端点,该端点可用于处理流量, 即对 Service 等后端进行过滤、平衡、拆分等。 例如,Gateway 可以代表某个云负载均衡器,或配置为接受 HTTP 流量的集群内代理服务器。
下面是一个精简的 Gateway 资源示例:
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: example-gateway
spec:
gatewayClassName: example-class
listeners:
- name: http
protocol: HTTP
port: 80在此示例中,流量处理基础设施的实例被编程为监听 80 端口上的 HTTP 流量。 由于未指定 addresses 字段,因此对应实现的控制器负责将地址或主机名设置到 Gateway 之上。 该地址用作网络端点,用于处理路由中定义的后端网络端点的流量。
【HTTPRoute】
HTTPRoute 类别指定从 Gateway 监听器到后端网络端点的 HTTP 请求的路由行为。 对于服务后端,实现可以将后端网络端点表示为服务 IP 或服务的支持端点。 HTTPRoute 表示将被应用到下层 Gateway 实现的配置。 例如,定义新的 HTTPRoute 可能会导致在云负载均衡器或集群内代理服务器中配置额外的流量路由。
下面是一个最精简的 HTTPRoute 示例:
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: example-httproute
spec:
parentRefs:
- name: example-gateway
hostnames:
- "www.example.com"
rules:
- matches:
- path:
type: PathPrefix
value: /login
backendRefs:
- name: example-svc
port: 8080在此示例中,来自 Gateway example-gateway 的 HTTP 流量, 如果 Host 的标头设置为 www.example.com 且请求路径指定为 /login, 将被路由到 Service example-svc 的 8080 端口。
1.4.2 请求数据流
以下是使用 Gateway 和 HTTPRoute 将 HTTP 流量路由到服务的简单示:

在此示例中,实现为反向代理的 Gateway 的请求数据流如下:
- 客户端开始准备 URL 为
http://www.example.com的 HTTP 请求 - 客户端的 DNS 解析器查询目标名称并了解与 Gateway 关联的一个或多个 IP 地址的映射。
- 客户端向 Gateway IP 地址发送请求;反向代理接收 HTTP 请求并使用 Host: 标头来匹配基于 Gateway 和附加的 HTTPRoute 所获得的配置。
- 可选的,反向代理可以根据 HTTPRoute 的匹配规则进行请求头和(或)路径匹配。
- 可选地,反向代理可以修改请求;例如,根据 HTTPRoute 的过滤规则添加或删除标头。
- 最后,反向代理将请求转发到一个或多个后端。
1.5 Network Policy
如果你希望在 IP 地址或端口层面(OSI 第 3 层或第 4 层)控制网络流量, NetworkPolicy 可以让你为集群内以及 Pod 与外界之间的网络流量指定规则。 你的集群必须使用支持 NetworkPolicy 实施的网络插件。
Pod 可以与之通信的实体是通过如下三个标识符的组合来辩识的:
- 其他被允许的 Pod(例外:Pod 无法阻塞对自身的访问)
- 被允许的名字空间
- IP 组块(例外:与 Pod 运行所在的节点的通信总是被允许的, 无论 Pod 或节点的 IP 地址)
在定义基于 Pod 或名字空间的 NetworkPolicy 时, 你会使用选择算符来设定哪些流量可以进入或离开与该算符匹配的 Pod。
另外,当创建基于 IP 的 NetworkPolicy 时,我们基于 IP 组块(CIDR 范围)来定义策略。
1.5.1 Pod 隔离的两种类型
Pod 有两种隔离:出口的隔离和入口的隔离。它们涉及到可以建立哪些连接。 这里的“隔离”不是绝对的,而是意味着“有一些限制”。 另外的,“非隔离方向”意味着在所述方向上没有限制。这两种隔离(或不隔离)是独立声明的, 并且都与从一个 Pod 到另一个 Pod 的连接有关。
默认情况下,一个 Pod 的出口是非隔离的,即所有外向连接都是被允许的。如果有任何的 NetworkPolicy 选择该 Pod 并在其 policyTypes 中包含 "Egress",则该 Pod 是出口隔离的, 我们称这样的策略适用于该 Pod 的出口。当一个 Pod 的出口被隔离时, 唯一允许的来自 Pod 的连接是适用于出口的 Pod 的某个 NetworkPolicy 的 egress 列表所允许的连接。 针对那些允许连接的应答流量也将被隐式允许。 这些 egress 列表的效果是相加的。
默认情况下,一个 Pod 对入口是非隔离的,即所有入站连接都是被允许的。如果有任何的 NetworkPolicy 选择该 Pod 并在其 policyTypes 中包含 “Ingress”,则该 Pod 被隔离入口, 我们称这种策略适用于该 Pod 的入口。当一个 Pod 的入口被隔离时,唯一允许进入该 Pod 的连接是来自该 Pod 节点的连接和适用于入口的 Pod 的某个 NetworkPolicy 的 ingress列表所允许的连接。针对那些允许连接的应答流量也将被隐式允许。这些 ingress 列表的效果是相加的。
1.5.2 示例
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
podSelector:每个 NetworkPolicy 都包括一个 podSelector, 它对该策略所适用的一组 Pod 进行选择。示例中的策略选择带有 "role=db" 标签的 Pod。 空的 podSelector 选择名字空间下的所有 Pod。
policyTypes:每个 NetworkPolicy 都包含一个 policyTypes 列表,其中包含 Ingress 或 Egress 或两者兼具。policyTypes 字段表示给定的策略是应用于进入所选 Pod 的入站流量还是来自所选 Pod 的出站流量,或两者兼有。 如果 NetworkPolicy 未指定 policyTypes 则默认情况下始终设置 Ingress; 如果 NetworkPolicy 有任何出口规则的话则设置 Egress。
ingress:每个 NetworkPolicy 可包含一个 ingress 规则的白名单列表。 每个规则都允许同时匹配 from 和 ports 部分的流量。示例策略中包含一条简单的规则: 它匹配某个特定端口,来自三个来源中的一个,第一个通过 ipBlock 指定,第二个通过 namespaceSelector 指定,第三个通过 podSelector 指定。
egress:每个 NetworkPolicy 可包含一个 egress 规则的白名单列表。 每个规则都允许匹配 to 和 port 部分的流量。该示例策略包含一条规则, 该规则将指定端口上的流量匹配到 10.0.0.0/24 中的任何目的地。
所以,该网络策略示例:
隔离
default名字空间下role=db的 Pod (如果它们不是已经被隔离的话)。(Ingress 规则)允许以下 Pod 连接到
default名字空间下的带有role=db标签的所有 Pod 的 6379 TCP 端口:
default名字空间下带有role=frontend标签的所有 Pod- 带有
project=myproject标签的所有名字空间中的 Pod- IP 地址范围为
172.17.0.0–172.17.0.255和172.17.2.0–172.17.255.255(即,除了172.17.1.0/24之外的所有172.17.0.0/16)(Egress 规则)允许
default名字空间中任何带有标签role=db的 Pod 到 CIDR10.0.0.0/24下 5978 TCP 端口的连接。
我个人觉得需要决定三件事:
- 第一件事是控制对象,就像这个实例里面 spec 的部分。spec 里面通过 podSelector 或者 namespace 的 selector,可以选择做特定的一组 pod 来接受我们的控制;
- 第二个就是对流向考虑清楚,需要控制入方向还是出方向?还是两个方向都要控制?
- 最重要的就是第三部分,如果要对选择出来的方向加上控制对象来对它流进行描述,具体哪一些 stream 可以放进来,或者放出去?类比这个流特征的五元组,可以通过一些选择器来决定哪一些可以作为我的远端,这是对象的选择;也可以通过 IPBlock 这种机制来得到对哪些 IP 是可以放行的;最后就是哪些协议或哪些端口。其实流特征综合起来就是一个五元组,会把特定的能够接受的流选择出来 。
2. K8s网络模型
Kubernetes网络模型包括以下几个方面:
- Pod间通信:Pod是Kubernetes中最小的部署单元,每个Pod都有一个唯一的IP地址,Pod内的容器共享该IP地址和网络命名空间。Pod间通信可以使用多种技术,如Kubernetes默认的CNI插件、Flannel、Calico、Weave Net等。
- Pod与Service通信:Service是Kubernetes中用于访问Pod的一种抽象机制,它为一组Pod提供一个统一的访问入口,并分发请求到后端的Pod。Pod与Service之间的通信可以直接使用Service的IP地址或DNS名称,Kubernetes会自动将请求路由到后端的Pod。
- Pod与Node通信:Kubernetes中的Pod可以与它所在的节点进行通信,这种通信方式通常用于容器化应用需要访问宿主机上的资源,如宿主机上的文件、设备等。Pod与Node之间的通信可以通过节点IP地址或本地环回地址(127.0.0.1)进行。
- Service与外部网络通信:Kubernetes中的Service可以暴露给外部网络访问,这可以通过Ingress、NodePort或LoadBalancer等机制实现。Ingress是一种Kubernetes中的资源对象,用于将外部HTTP/HTTPS流量路由到Service中,它可以提供负载均衡、SSL终止等功能。NodePort是一种Service类型,它将Service的端口映射到每个节点的固定端口上,从而允许外部网络通过节点IP地址和该端口访问Service。LoadBalancer是一种Service类型,它使用云提供商的负载均衡器将外部网络流量路由到Service中。
3. K8s网络实现
K8s网络的设计主要致力于解决如下问题:
- Docker容器和Docker容器之间的网络
- Pod与Pod之间的网络
- Pod与Service之间的网络 (下一章节详细介绍
- Internet与Service之间的网络=>集群内和集群外的通信
3.1 容器到容器的通信
K8s创建Pod时永远都是首先创建Infra 容器,也可以被称为pause容器,这个容器为其他容器提供了一个共享的基础设施,包括网络和存储功能,其他业务容器共享pause容器的网络栈和Volume挂载卷。
pause 容器被创建后会初始化Network Namespace网络栈,之后其他容器就可以加入到pause 容器中共享Infra容器的网络了。而对于同一个 Pod 里面的所有用户容器来说,它们的进出流量,认为都是通过 pause 容器完成的。
pause 容器会创建并管理虚拟以太网(veth)接口。在容器启动之前,pause 容器会创建一个虚拟以太网接口,一个保留在宿主机上(称为 vethxxx),另一个保留在容器网络命名空间内并重命名为 eth0,如下图所示。这两个虚拟接口的两端是连接在一起的,从一端进入的数据会从另一端出来。
Pod中的所有容器都共享相同的网络命名空间和IP地址——PodIP,所以在同一个Pod内的容器间通信可以通过localhost直接通信。
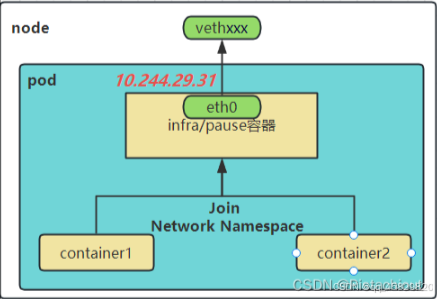
pause容器主要为每个业务容器提供以下功能:
- IPC命名空间:Pod中的多个容器能够使用SystemV IPC或POSIX消息队列进行通信。
- 网络命名空间:Pod中的多个容器能够访问同一个IP和端口范围。
- PID命名空间:Pod中的不同应用程序可以看到其他应用程序的进程ID。
- UTS命名空间:Pod中的多个容器共享一个主机名;
- Volumes(共享存储卷):Pod中的各个容器可以访问在Pod级别定义的Volum
3.2 Pod与Pod之间的通信
3.2.1 同一个Node上的不同Pod之间的通信
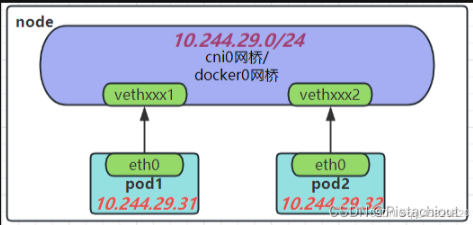
同一节点不同POD之间的通信是通过将容器网络接口(CNI)与主机网络命名空间中的虚拟以太网(veth)接口相连来实现的。 每生成一个新的Pod,那么在Node上都会根据插件来生成一个新的虚拟网卡如vethxxxx或者calixxxx,这个网卡会对应到Pod里的eth0。
如图,veth接口则被保留在主机的网络命名空间中,并被连接到CNI插件(如Flannel或Calico等)创建的虚拟网桥(如cni0或flannel0等)上。一旦这些veth接口被正确地连接起来,它们就可以进行通信了。当一个POD发送数据包时,数据包会通过其veth接口被发送到主机网络命名空间中的veth接口,然后该veth接口会将数据包发送到虚拟网桥上。虚拟网桥又会将数据包路由到目标POD的veth接口,最终将数据包发送到目标POD。
如图所示的ip地址与网桥网段,同一节点的不同POD的IP地址通常属于同一网段,并通过CNI插件连接到同一个虚拟网桥(如cni0)上。虚拟网桥会管理其IP地址空间和分配,确保不同POD的IP地址不会冲突。
具体的IP地址和网段取决于所使用的CNI插件和网络方案。例如,Flannel插件默认使用10.244.x.0/24的网段,其中x是随机分配给每个POD的。这意味着不同POD的IP地址将位于10.244.x.0/24的网段中,其中x是不同的值。
注:
- 每一个Pod有一个真实的全局ip地址,同一个Node内的不同Pod之间可以直接采用对方Pod的Ip地址通信,而且不需要其他的发现机制,如DNS等
- pod通过veth连接到同一个docker0网桥,ip地址是从docker0网段上动态获取,和网桥本身的ip属于同一个网段
3.2.2 不同Node上的不同Pod之间的通信
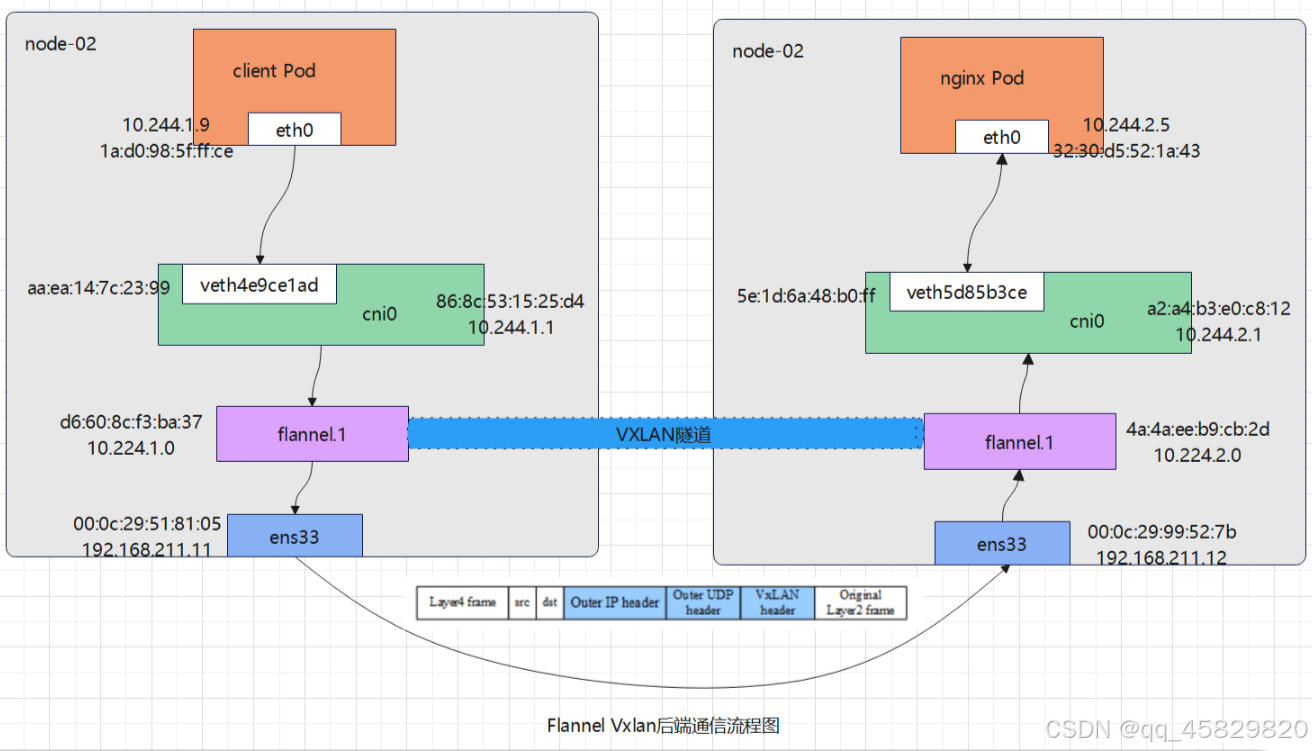
若不同节点pod想要相互通信,在cni0网桥外还有一层CNI插件配置的网络隧道,如上图新的虚拟网卡flannel0接收cni0网桥的数据,并通过维护路由表,对接收到的数据进行封包和转发(vxlan隧道)。
cni0:网桥设备,每创建一个pod都会创建一对 veth pair。其中一段是pod中的eth0,另一端是cni0网桥中的端口。
VTEP设备:VXLAN Tunnel End Point(虚拟隧道端点),在Flannel中 VNI的默认值是1,这也是为什么宿主机的VTEP设备都叫flannel.1的原因。VTEP设备之间通过二层数据帧进行通信,源VTEP设备收到原始IP包后,在上面加上一个目的MAC地址,封装成一个内部数据帧,发送给目的VTEP设备。
flannel.1:vxlan网关设备,用户 vxlan 报文的解包和封包。不同的 pod 数据流量都从overlay设备以隧道的形式发送到对端。flannel.1不会发送arp请求去获取目标IP的mac地址,而是由Linuxkernel将一个"L3 Miss"事件请求发送到用户空间的flanneld程序,flanneld程序收到内核的请求事件后,从etcd中查找能够匹配该地址的子网flannel.1设备的mac地址,即目标pod所在host中flannel.1设备的mac地址。
flanneld:在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。同时Flanneld监听K8s集群数据库,为flannel.1设备提供封装数据时必要的mac,ip等网络数据信息。
VXLAN:Virtual eXtensible Local Area Network,虚拟扩展局域网。采用L2 over L4(MAC-in-UDP)的报文封装模式,将二层报文用三层协议进行封装,实现二层网络在三层范围内进行扩展,同时满足数据中心大二层虚拟迁移和多租户的需求。flannel只使用了vxlan的部分功能,VNI被固定为1。
内部数据桢,并不能在宿主机的二层网络传输,Linux内核还需要把它进一步封装成为宿主机的一个普通的数据帧,承载着内部数据帧通过宿主机的eth0进行传输。
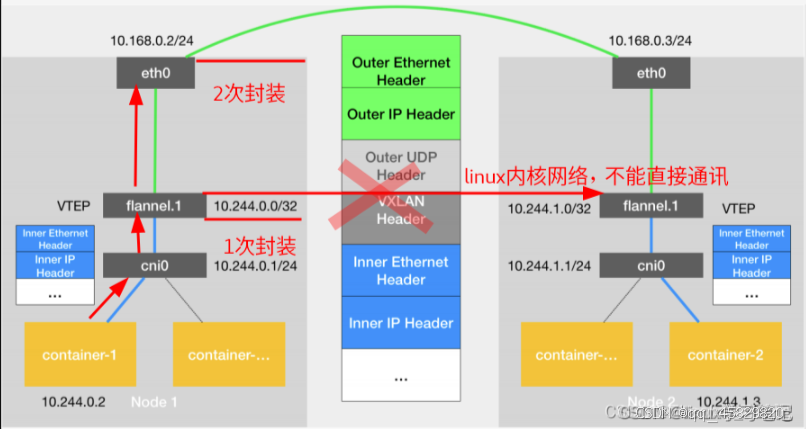
不同node上的pod通信流程:
- pod中的数据,根据pod的路由信息,发送到网桥 cni0
- cni0 根据节点路由表,将数据发送到隧道设备flannel.1
- flannel.1 查看数据包的目的ip,从flanneld获取对端隧道设备的必要信息,封装数据包 flannel.1,将数据包发送到对端设备。
- 数据包中包括 Outer IP 与 Inner IP等相关信息, 将PodIP和所在的NodeIP关联起来,通过这个关联让不同的Pod互相访问。
- 对端节点的网卡接收到数据包,发现数据包为overlay数据包,解开外层封装,并发送内层封装到flannel.1
- 设备 Flannel.1 设备查看数据包,根据路由表匹配,将数据发送给cni0设备
- cni0匹配路由表,发送数据到网桥
----------------
---笔记使用--侵权--联系--删--


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









