







 该博客主要介绍了一种高级程序设计语言的词法分析程序设计,包括识别关键字、标识符、常数和运算符等二十类单词。程序流程涉及数据结构的选择和测试用例的设计。内容涵盖错误处理、输出格式以及关键代码实现,例如数字和浮点数的解析。示例源代码展示了如何处理和输出不同类型的单词。
该博客主要介绍了一种高级程序设计语言的词法分析程序设计,包括识别关键字、标识符、常数和运算符等二十类单词。程序流程涉及数据结构的选择和测试用例的设计。内容涵盖错误处理、输出格式以及关键代码实现,例如数字和浮点数的解析。示例源代码展示了如何处理和输出不同类型的单词。
一、实验内容
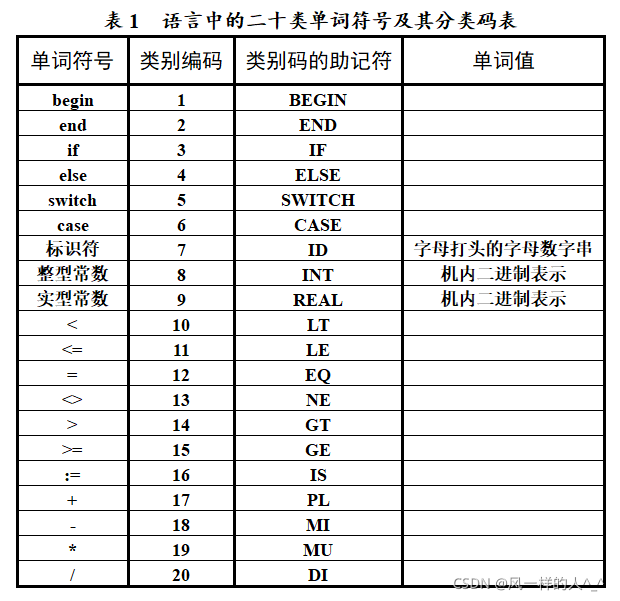
假定一种高级程序设计语言中的单词主要包括关键字begin、end、if、else、switch、case;标识符;整型常数;实型常数;六种关系运算符;一个赋值符和四个算术运算符,试构造能识别这些单词的词法分析程序(二十类单词的分类码参见表1)。
输入:由符合和不符合所规定的单词类别结构的各类单词组成的源程序文件。
输出:把所识别出的每一单词均按形如(CLASS,VALUE)的二元式形式输出,并将结果放到某个文件中。对于标识符和常数,CLASS字段为相应的类别码的助记符;VALUE字段则是该标识符、常数的具体值。对于关键字和运算符,采用一词一类的编码形式,仅需在二元式的CLASS字段上放置相应单词的类别码的助记符,VALUE字段则为“空”。
二、要求:
1、上机前完成词法分析程序的程序流程设计,并选择好相应的数据结构。
2、用于测试扫描器的实例源文件中至少应包含两行以上的源代码。
3、对于输入的测试用例的源程序文件,词法正确的单词分析结果在输出文件中以二元式形式输出,错误的字符串给出错误提示信息。
例如,若输入文件中的内容为:“if myid>=8 x:=2.6E-2 else x:=y”,则输出文件中的内容应为:
(IF, )
(ID,’myid’)
(GE, )
(INT,8)
(ID,’x’)
(IS, )
(REAL,0.026)
(ELSE, )
(ID,’x’)
(IS, )
(ID,’y’)
三、代码
# include <stdio.h>
#include<iostream>
# include <ctype.h>
# include <string.h>
#include<sstream>
#define BEGIN 1
#define END 2
#define IF 3
#define ELSE 4
#define SWITCH 5
#define CASE 6
# define INT 7
# define REAL 8
#define DOUBLE 9
#define FLOAT 10
#define LONG 11
#define RETURN 12
#define VOID 13
# define ID 101
# define LT 102
# define LE 103
# define EQ 104
# define NE 105
# define GT 106
# define GE 107
# define IS 108
# define PL 109
# define MI 110
# define MU 111
# define DI 112
# define DIGIT 113
# define POINT 114
# define OTHER 115
# define POWER 116
# define PLUS 117
# define MINUS 118
# define UCON 119 //Suppose the class number of unsigned constant is 7
# define ClassOther 200
# define EndState - 1
int w, n, p, e, d;
int Class; //Used to indicate class of the word
int ICON;
float FCON;
static int CurrentState; //Used to present current state, the initial value:0
int GetChar(void);
int EXCUTE(int, int);
double const LEX(char *);
/* 建立保留字表 */
#define MAX_KEY_NUMBER 20 /*关键字的数量*/
#define KEY_WORD_END "waiting for your expanding" /*关键字结束标记*/
const char *KeyWordTable[MAX_KEY_NUMBER] = { "begin","end", "if", "else", "switch","case",
"int","real","double","float","long","return","void",KEY_WORD_END };
char TOKEN[20];
extern int lookup(char*);
extern void out(int, const char*);
extern void report_error(const char*);
int HandleOtherWord(void)
{
return ClassOther;
}
int HandleError(void)
{printf("Error!\n"); return 0; }
int GetChar(char c)
{
if (isdigit(c)) { d = c - '0'; return DIGIT; }
if (c == '.') return POINT;
if (c == 'E' || c == 'e') return POWER;
if (c == '+') return PLUS;
if (c == '-') return MINUS;
return OTHER;
}
int EXCUTE(int state, int symbol)
{
switch (state)
{
case 0:switch (symbol)
{
case DIGIT: n = 0; p = 0; e = 1; w = d; CurrentState = 1; Class = UCON; break;
case POINT: w = 0; n = 0; p = 0; e = 1; CurrentState = 3; Class = UCON; break;
default: HandleOtherWord(); Class = ClassOther;
CurrentState = EndState;
}
break;
case 1:switch (symbol)
{
case DIGIT: w = w * 10 + d; break; //CurrentState=1
case POINT: CurrentState = 2; break;
case POWER: CurrentState = 4; break;
default: ICON = w; CurrentState = EndState;
}
break;
case 2:switch (symbol)
{
case DIGIT: n++; w = w * 10 + d; break;
case POWER: CurrentState = 4; break;
default: FCON = w * pow(10, e*p - n); CurrentState = EndState;
}
break;
case 3:switch (symbol)
{
case DIGIT: n++; w = w * 10 + d; CurrentState = 2; break;
default: HandleError(); CurrentState = EndState;
}
break;
case 4:switch (symbol)
{
case DIGIT: p = p * 10 + d; CurrentState = 6; break;
case MINUS: e = -1; CurrentState = 5; break;
case PLUS: CurrentState = 5; break;
default: HandleError(); CurrentState = EndState;
}
break;
case 5:switch (symbol)
{
case DIGIT: p = p * 10 + d; CurrentState = 6; break;
default: HandleError(); CurrentState = EndState;
}
break;
case 6:switch (symbol)
{
case DIGIT:p = p * 10 + d; break;
default: FCON = w * pow(10, e*p - n); CurrentState = EndState;
}
break;
}
return CurrentState;
}
double const LEX(char* c)
{
int len=strlen(c);
int ch,count=0;
CurrentState = 0;
while (CurrentState != EndState)
{
ch=GetChar(c[count]);
if(count<=len)
EXCUTE(CurrentState, ch);
count++;
}
return w*pow(10,e*p-n);
}
void report_error(const char *ch)
{
std::cout << "出错"<<": "<<"错误类型-"<<ch<<"错误"<<std::endl;
}
int lookup(char *token)
{
int n = 0;
while (strcmp(KeyWordTable[n], KEY_WORD_END)) /*strcmp比较两串是否相同,若相同返回0*/
{
if (!strcmp(KeyWordTable[n], token)) /*比较token所指向的关键字和保留字表中哪个关键字相符*/
{
return n + 1; /*根据单词分类码表I,设置正确的关键字类别码,并返回此类别码的值*/
break;
}
n++;
}
return 0; /*单词不是关键字,而是标识符*/
}
void out(int a, const char* b)
{
const char *str = "";
if (a == 1) str = "BEGIN";
if (a == 2) str = "END";
if (a == 3) str = "IF";
if (a == 4) str = "ELSE";
if (a == 5) str = "SWITCH";
if (a == 6) str = "CASE";
if (a == 7) str = "INT";
if (a == 8) str = "REAL";
if (a == 9) str = "DOUBLE";
if (a == 10) str = "FLOAT";
if (a == 11) str = "LONG";
if (a == 12) str = "RETURN";
if (a == 13) str = "VOID";
if (a == 101) str = "ID";
if (a == 102) str = "LT";
if (a == 103) str = "LE";
if (a == 104) str = "EQ";
if (a == 105)str = "NE";
if (a == 106)str = "GT";
if (a == 107)str = "GE";
if (a == 108)str = "IS";
if (a == 109)str = "PL";
if (a == 110)str = "MI";
if (a == 111)str = "MU";
if (a == 112)str = "DI";
std::cout <<"("<< str<< "," << b <<")"<< std::endl;
}
void scanner_example(FILE *fp)
{
char ch='0'; int i, c;
//fgetc:从文件指针stream指向的文件中读取一个字符,读取一个字节后,光标位置后移一个字节
//这个函数的返回值,是返回所读取的一个字节。如果读到文件末尾或者读取出错时返回EOF(-1)
while (!feof(fp))
{
*TOKEN = { '\0' };
if (ch == -1) break;
ch = fgetc(fp);
//******** isalpha:判断字符ch是否为英文字母,若为英文字母,返回非0(小写字母为2,大写字母为1)。若不是字母,返回0
if (isalpha(ch)) /*it must be a identifer!*/
{//首字母识别为英文字母
TOKEN[0] = ch; ch = fgetc(fp); i = 1; //储存数组token[]存放当前字符,ch指向文件的下一个字符
//isalnum:判断字符变量c是否为字母或数字,若是则返回非零,否则返回零。
while (isalnum(ch)|(ch=='_'))
{
TOKEN[i] = ch; i++;
ch = fgetc(fp);
}
TOKEN[i] = '\0';
//int fseek(FILE *stream, long offset, int fromwhere);
//如果执行成功,stream将指向以fromwhere为基准,偏移offset个字节的位置,函数返回0。如果执行失败,则不改变stream指向的位置,函数返回一个非0值。
fseek(fp, -1, 1); /* retract*/ //撤回一步compile.txt
c = lookup(TOKEN);
if (c == 0) out(ID, TOKEN); else out(c, " ");
}
//上一个if完成的工作:找出以字母开头的字符串,之后可字母可数字,最后进行查找(两种情况:关键字|标识符)
//********首字母识别为"_"
else if(ch=='_')
{
TOKEN[0] = ch; ch = fgetc(fp); i = 1;
while (isalnum(ch)|(ch=='_'))
{
TOKEN[i] = ch; i++;
ch = fgetc(fp);
}
TOKEN[i] = '\0';
fseek(fp, -1, 1);
out(ID,TOKEN);
}
else
//********首字母识别为数字
if (isdigit(ch)) //若参数c为阿拉伯数字0~9,则返回非0值,否则返回0
{
bool flag=false; //判断是否为整型常量
TOKEN[0] = ch; ch = fgetc(fp); i = 1;
int having_E=0;
while (isdigit(ch)|(ch=='.')|(ch=='e')|(ch=='E')|(having_E>0?(ch=='-'):0))
{
if(!isdigit(ch)) flag=true; //判定当前数不是整型常量
if((ch=='E')|(ch=='e')) having_E++;
TOKEN[i] = ch; i++;
ch = fgetc(fp);
}
TOKEN[i] = '\0';
fseek(fp, -1, 1);
//接下来的6步:将double转换为char*,并去掉结尾多余的0
double real_Number=LEX(TOKEN);
std::ostringstream oss1;
oss1<<real_Number;
char realNumber[50];
memset(realNumber,0,50);
//先转化为流,再转换为string,然后再转换为char
std::strcat(realNumber,(oss1.str()).c_str());
out(flag==true?REAL:INT, realNumber);
}
//上一个if完成的工作:识别出整形常量
//********首字母识别为运算符
else
switch (ch)
{
//第一个符号是 < 的情况
case '<': ch=fgetc(fp);
if(ch=='=')out(LE," ");
else if(ch=='>') out (NE," ");
else
{
fseek (fp,-1,1);
out (LT," ");
}
break;
//第一个符号是 = 的情况
case '=':
{
out(EQ, " ");
break;
}
//第一个符号是 > 的情况
case '>': ch=fgetc(fp);
if(ch=='=')out(GE," ");
else
{
fseek(fp,-1,1);
out(GT," ");
}
break;
//第一个符号是 : 的情况
case ':':
{
ch=fgetc(fp);
if(ch=='=')
{
out(IS, " ");
}
else {
report_error("运算符");
}
break;
}
case '+': out(PL," "); break;
case '-': out(MI," "); break;
case '*': out(MU," "); break;
case '/': out(DI," "); break;
//其他情况
default:
{
if (ch == 32) {}
else if(ch == 10) {} //换行
else {
report_error("运算符"); ch = fgetc(fp);
}
break;
}
}
}
return;
}
int main(int argc, char *argv[])
{
FILE *stream;
fopen_s(&stream, "E:\\compile.txt", "r");
scanner_example(stream);
}
说明:
- 结果输出只在控制台进行了显示,若要输出到文件,可自行百度。
- main函数中有文件路径,记得更改。

















 7699
7699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









