







一、读写分离简介
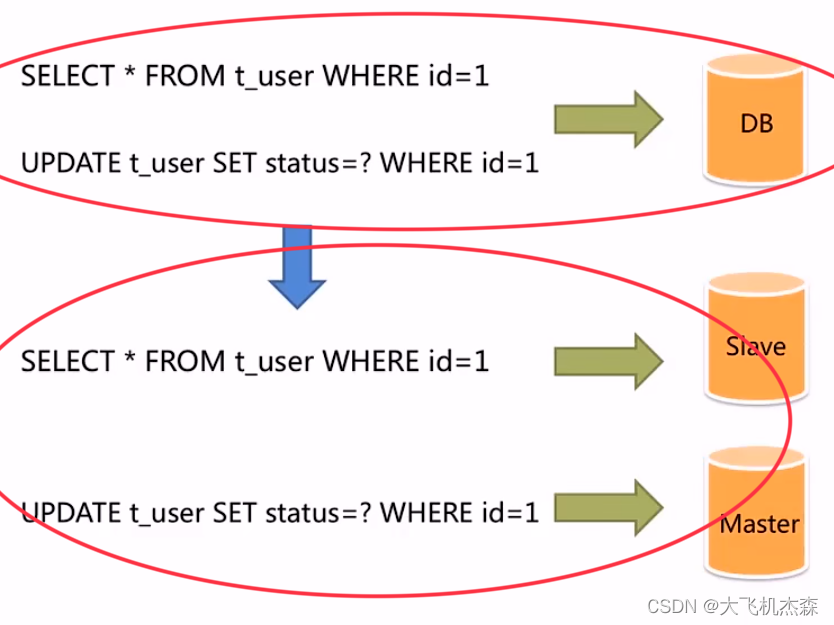
- 在实现读写分离之前,所有的SQL语句都是由一个数据库来执行的;
- 在实现读写分离之后,我们会让SQL语句“分流”,事务性的增删改的语句让主库Master去执行,查询语句则让从库Slave去执行,这样就减轻了单个服务器的压力。有效的避免了由数据更新导致的行级锁,使整个系统的查询性能得到极大改善。
二、Sharding-JDBC框架介绍
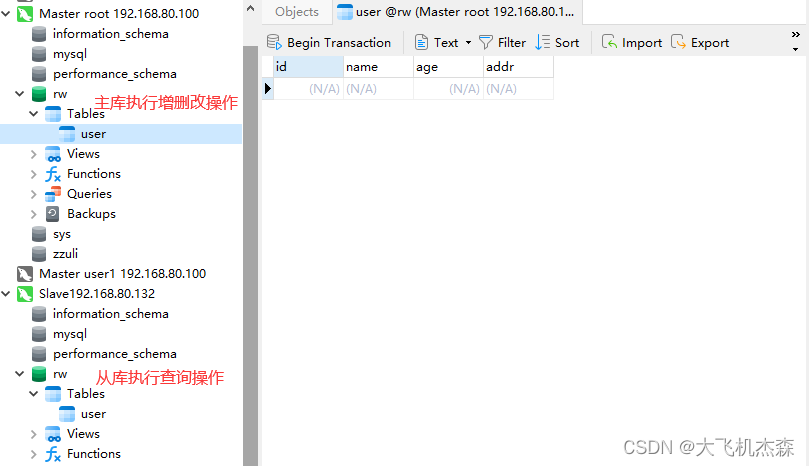
 在主库创建一张user表,从库也会自动复制一份
在主库创建一张user表,从库也会自动复制一份
创建一个简单的项目
 三、使用Sharding-JDBC框架实现读写分离
三、使用Sharding-JDBC框架实现读写分离
1、导入Sharding-JDBC的maven坐标
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>2、在配置文件中配置读写分离规则
3、在配置文件中配置允许bean定义覆盖配置项
spring:
shardingsphere:
datasource:
names:
master,slave #定义两个数据源的名字
# 主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.80.100:3306/rw?characterEncoding=utf-8 #包含主库的ip
username: root
password: root
# 从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.80.132:3306/rw?characterEncoding=utf-8 #包含从库的ip
username: root
password: root
masterslave:
# 读写分离配置
load-balance-algorithm-type: round_robin #指定从库负载均衡策略:轮询
# 最终的数据源名称
name: dataSource
# 指定主库数据源
master-data-source-name: master
# 指定从库数据源列表,若有多个,用逗号分隔
slave-data-source-names: slave
props:
sql:
show: true #开启SQL显示(在控制台显示SQL语句),默认false
main:
allow-bean-definition-overriding: true #开启bean定义覆盖
server:
port: 8080
mybatis-plus:
configuration:
#在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
id-type: ASSIGN_ID
四、测试
1、我们先访问一下查询的mapping,在这里打上断点,打开dataSource属性,接着打开dataSourceMap会看到有两个数据源,一个是我们的主库的,一个是我们的从库

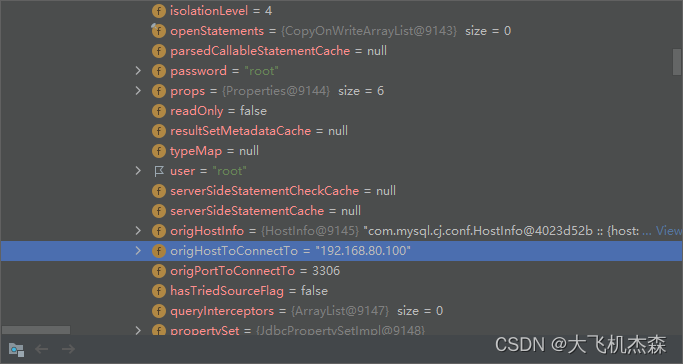
2、打开master—>value—>connections—>0—>conn—> origHostToConnectTo我们就可以看到master数据库的ip地址;slave数据库亦然。

3、放行之后,我们打开控制台看一眼,查询的SQL被slave从库所执行 。

4、我们再试一下新增的操作
 这个地方报了一个错,因为mybatis-plus使用的雪花算法,我们前面数据库中id字段使用的int类型,超出了int的范围,我们去数据库把id字段的数据类型改为bigint就ok了。通过控制台的信息,我们可以看到增操作使用的master数据库。
这个地方报了一个错,因为mybatis-plus使用的雪花算法,我们前面数据库中id字段使用的int类型,超出了int的范围,我们去数据库把id字段的数据类型改为bigint就ok了。通过控制台的信息,我们可以看到增操作使用的master数据库。

至此,读写分离我们已经测试成功!















 159
159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









