







目录
下面有关servlet中init,service,destroy方法描述错误的是?
阅读如下代码。 请问,对语句行 test.hello(). 描述正确的有()
Java是一门支持反射的语言,基于反射为Java提供了丰富的动态性支持,下面关于Java反射的描述,哪些是错误的:( )
final、finally和finalize的区别中,下述说法正确的有?
下面有关servlet中init,service,destroy方法描述错误的是?
正确答案: D 你的答案: D (正确)
init()方法是servlet生命的起点。一旦加载了某个servlet,服务器将立即调用它的init()方法service()方法处理客户机发出的所有请求destroy()方法标志servlet生命周期的结束servlet在多线程下使用了同步机制,因此,在并发编程下servlet是线程安全的来源:https://www.nowcoder.com/questionTerminal/6f32a414e2554f709444dc30b1b2a6b5
答案为D。
servlet在多线程下其本身并不是线程安全的。
如果在类中定义成员变量,而在service中根据不同的线程对该成员变量进行更改,那么在并发的时候就会引起错误。
最好是在方法中,定义局部变量,而不是类变量或者对象的成员变量。
由于方法中的局部变量是在栈中,彼此各自都拥有独立的运行空间而不会互相干扰,因此才做到线程安全。
下列说法正确的是( )
正确答案: C 你的答案: C (正确)
volatile,synchronized 都可以修改变量,方法以及代码块volatile,synchronized 在多线程中都会存在阻塞问题volatile能保证数据的可见性,但不能完全保证数据的原子性,synchronized即保证了数据的可见性也保证了原子性volatile解决的是变量在多个线程之间的可见性、原子性,而sychroized解决的是多个线程之间访问资源的同步性来源:https://www.nowcoder.com/questionTerminal/0b9f888ae88245c99c556be4ee679212
synchronized关键字和volatile关键字比较:
- volatile关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized关键字要好。
- 但是volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块。
- synchronized关键字在JavaSE1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁以及其它各种优化之后执行效率有了显著提升,实际开发中使用 synchronized 关键字的场景还是更多一些。
- 多线程访问volatile关键字不会发生阻塞,而synchronized关键字可能会发生阻塞
- volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证。
- volatile关键字主要用于解决变量在多个线程之间的可见性,而 synchronized关键字解决的是多个线程之间访问资源的同步性。
以下描述正确的是
正确答案: B 你的答案: B (正确)
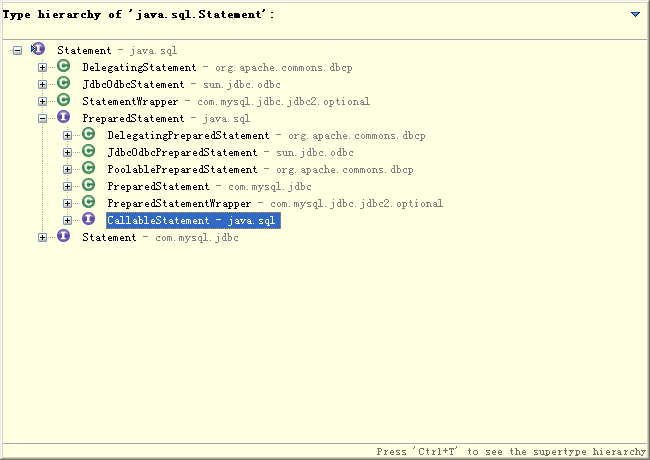
CallableStatement是PreparedStatement的父接口PreparedStatement是CallableStatement的父接口CallableStatement是Statement的父接口PreparedStatement是Statement的父接口来源:https://www.nowcoder.com/questionTerminal/1f97e08e75f54aa5ae252f64a6f9d934
Statement 每次执行sql语句,数据库都要执行sql语句的编译 ,最好用于仅执行一次查询并返回结果的情形,效率高于PreparedStatement.
PreparedStatement是预编译的,使用PreparedStatement有几个好处
a. 在执行可变参数的一条SQL时,PreparedStatement比Statement的效率高,因为DBMS预编译一条SQL当然会比多次编译一条SQL的效率要高。
b. 安全性好,有效防止Sql注入等问题。
c. 对于多次重复执行的语句,使用PreparedStament效率会更高一点,并且在这种情况下也比较适合使用batch;
d. 代码的可读性和可维护性。
CallableStatement接口扩展 PreparedStatement,用来调用存储过程,它提供了对输出和输入/输出参数的支持。CallableStatement 接口还具有对 PreparedStatement 接口提供的输入参数的支持。
对下面Spring声明式事务的配置含义的说明错误的是()
<bean id="txProxyTemplate" abstract="true"
class=
"org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<property name="transactionManager" ref="myTransactionManager" />
<property name="transactionAttributes">
<props>
<prop key="get*">PROPAGATION_REQUIRED,readOnly</prop>
<prop key="*">PROPAGATION_REQUIRED</prop>
</props>
</property>
</bean>正确答案: C 你的答案: B (错误)
定义了声明式事务的配置模板对get方法采用只读事务缺少sessionFactory属性的注入配置需要事务管理的bean的代理时,通过parent引用这个配置模板,代码如下:
<bean id="petBiz" parent="txProxyTemplate"> <property name="target" ref="petTarget"/> </bean>来源:https://www.nowcoder.com/questionTerminal/0ae7fe7ffb2345fba9c967eb18af0d5c
1.Spring本身并不直接管理事务,而是提供了事务管理器接口,对于不同的框架或者数据源则用不同的事务管理器;而对于事务,它把相关的属性都封装到一个实体里边去,有以下的属性:
1
2
3
4
intpropagationBehavior;/*事务的传播行为*/
intisolationLevel;/*事务隔离级别*/
inttimeout;/*事务完成的最短时间*/
booleanreadOnly;/*是否只读*/Spring提供了对编程式事务和声明式事务的支持,编程式事务是嵌在业务代码中的,而声明式事务是基于xml文件配置。
2. readOnly -- 事务隔离级别,表示只读数据,不更新数据
1
3.PROPAGATION_REQUIRED--支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择。
1
2
3
4
5
PROPAGATION_SUPPORTS--支持当前事务,如果当前没有事务,就以非事务方式执行。
PROPAGATION_MANDATORY--支持当前事务,如果当前没有事务,就抛出异常。
PROPAGATION_REQUIRES_NEW--新建事务,如果当前存在事务,把当前事务挂起。
PROPAGATION_NOT_SUPPORTED--以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
PROPAGATION_NEVER--以非事务方式执行,如果当前存在事务,则抛出异常。
off-heap是指那种内存()
正确答案: B 你的答案: B (正确)
JVM GC能管理的内存JVM进程管理的内存在JVM老年代内存区在JVM新生代内存来源:https://www.nowcoder.com/questionTerminal/7a0dadaccd364f68a41cca5d22d2e09e
off-heap叫做堆外内存,将你的对象从堆中脱离出来序列化,然后存储在一大块内存中,这就像它存储到磁盘上一样,但它仍然在RAM中。对象在这种状态下不能直接使用,它们必须首先反序列化,也不受垃圾收集。
序列化和反序列化将会影响部分性能(所以可以考虑使用FST-serialization)使用堆外内存能够降低GC导致的暂停。
堆外内存不受垃圾收集器管理,也不属于老年代,新生代。
下面哪一项不属于优化Hibernate所鼓励的?
正确答案: A 你的答案: D (错误)
使用单向一对多关联,不使用双向一对多不用一对一,用多对一取代配置对象缓存,不使用集合缓存继承类使用显式多态来源:https://www.nowcoder.com/questionTerminal/a09bab3e083e4ed9a6b4e6479acde180
优化Hibernate所鼓励的7大措施:
1.尽量使用many-to-one,避免使用单项one-to-many
2.灵活使用单向one-to-many
3.不用一对一,使用多对一代替一对一
4.配置对象缓存,不使用集合缓存
5.一对多使用Bag 多对一使用Set
6.继承使用显示多态 HQL:from object polymorphism="exlicit" 避免查处所有对象
7.消除大表,使用二级缓存
阅读如下代码。 请问,对语句行 test.hello(). 描述正确的有()
package NowCoder;
class Test {
public static void hello() {
System.out.println("hello");
}
}
public class MyApplication {
public static void main(String[] args) {
// TODO Auto-generated method stub
Test test=null;
test.hello();
}
}正确答案: A 你的答案: D (错误)
能编译通过,并正确运行因为使用了未初始化的变量,所以不能编译通过以错误的方式访问了静态方法能编译通过,但因变量为null,不能正常运行来源:https://www.nowcoder.com/questionTerminal/733630b017f74bf3bcf54dc8a82dc3cf
因为Test类的hello方法是静态的,所以是属于类的,当实例化该类的时候,静态会被优先加载而且只加载一次,所以不受实例化new Test();影响,只要是使用到了Test类,都会加载静态hello方法!
另外,在其他类的静态方法中也是可以调用公开的静态方法,此题hello方法是使用public修饰的所以在MyApplication中调用hello也是可以的。
总结:即使Test test=null;这里也会加载静态方法,所以test数据中包含Test类的初始化数据。(静态的,构造的,成员属性)
因此test.hello是会调用到hello方法的。
关于匿名内部类叙述正确的是? ( )
正确答案: B 你的答案: D (错误)
匿名内部类可以继承一个基类,不可以实现一个接口匿名内部类不可以定义构造器匿名内部类不能用于形参以上说法都不正确来源:https://www.nowcoder.com/questionTerminal/57c3b77e2a594bbd9c3989819278dea4
在使用匿名内部类的过程中,我们需要注意如下几点:
1、使用匿名内部类时,我们必须是继承一个类或者实现一个接口,但是两者不可兼得,同时也只能继承一个类或者实现一个接口。
2、匿名内部类中是不能定义构造函数的。
3、匿名内部类中不能存在任何的静态成员变量和静态方法。
4、匿名内部类为局部内部类,所以局部内部类的所有限制同样对匿名内部类生效。
5、匿名内部类不能是抽象的,它必须要实现继承的类或者实现的接口的所有抽象方法。
Hashtable 和 HashMap 的区别是:
正确答案: B C D E 你的答案: B C E (错误)
Hashtable 是一个哈希表,该类继承了 AbstractMap,实现了 Map 接口HashMap 是内部基于哈希表实现,该类继承AbstractMap,实现Map接口Hashtable 线程安全的,而 HashMap 是线程不安全的Properties 类 继承了 Hashtable 类,而 Hashtable 类则继承Dictionary 类HashMap允许将 null 作为一个 entry 的 key 或者 value,而 Hashtable 不允许。来源:https://www.nowcoder.com/questionTerminal/a2230836563b4e26b3b32b108cfcf051
Hashtable:
(1)Hashtable 是一个散列表,它存储的内容是键值对(key-value)映射。
(2)Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。
(3)HashTable直接使用对象的hashCode。
HashMap:
(1)由数组+链表组成的,基于哈希表的Map实现,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的。
(2)不是线程安全的,HashMap可以接受为null的键(key)和值(value)。
(3)HashMap重新计算hash值
Hashtable,HashMap,Properties继承关系如下:
1
2
3
4
publicclassHashtable<K,V>extendsDictionary<K,V>
implementsMap<K,V>, Cloneable, java.io.Serializable
publicclassHashMap<K,V>extendsAbstractMap<K,V>implementsMap<K,V>, Cloneable, Serializable
1
2
3
4
java.lang.Objecct
java.util.Dictionary<K,V>
java.util.Hashtable<Object,Object>
java.util.Properties
Java是一门支持反射的语言,基于反射为Java提供了丰富的动态性支持,下面关于Java反射的描述,哪些是错误的:( )
正确答案: A D F 你的答案: E F (错误)
Java反射主要涉及的类如Class, Method, Filed,等,他们都在java.lang.reflet包下通过反射可以动态的实现一个接口,形成一个新的类,并可以用这个类创建对象,调用对象方法通过反射,可以突破Java语言提供的对象成员、类成员的保护机制,访问一般方式不能访问的成员Java反射机制提供了字节码修改的技术,可以动态的修剪一个类Java的反射机制会给内存带来额外的开销。例如对永生堆的要求比不通过反射要求的更多Java反射机制一般会带来效率问题,效率问题主要发生在查找类的方法和字段对象,因此通过缓存需要反射类的字段和方法就能达到与之间调用类的方法和访问类的字段一样的效率A Class类在java.lang包
B 动态代理技术可以动态创建一个代理对象,反射不行
C 反射访问私有成员时,Field调用setAccessible可解除访问符限制
D CGLIB实现了字节码修改,反射不行
E 反射会动态创建额外的对象,比如每个成员方法只有一个Method对象作为root,他不会直接暴露给用户。调用时会返回一个Method的包装类
F 反射带来的效率问题主要是动态解析类,JVM没法对反射代码优化。
类之间存在以下几种常见的关系:
正确答案: A B C 你的答案: A C (错误)
“USES-A”关系“HAS-A”关系“IS-A”关系“INHERIT-A”关系来源:https://www.nowcoder.com/questionTerminal/595f7872e13245a4a0af65a367e3a179
USES-A:依赖关系,A类会用到B类,这种关系具有偶然性,临时性。但B类的变化会影响A类。这种在代码中的体现为:A类方法中的参数包含了B类。
关联关系:A类会用到B类,这是一种强依赖关系,是长期的并非偶然。在代码中的表现为:A类的成员变量中含有B类。
HAS-A:组合关系,拥有关系,是关联关系的一种特例,是整体和部分的关系。比如鸟群和鸟的关系是组合关系,鸟群中每个部分都是鸟。
IS-A:表示继承。父类与子类,这个就不解释了。
要注意:还有一种关系:组合关系也是关联关系的一种特例,它体现一种contains-a的关系,这种关系比聚合更强,也称为强聚合。它同样体现整体与部分的关系,但这种整体和部分是不可分割的。
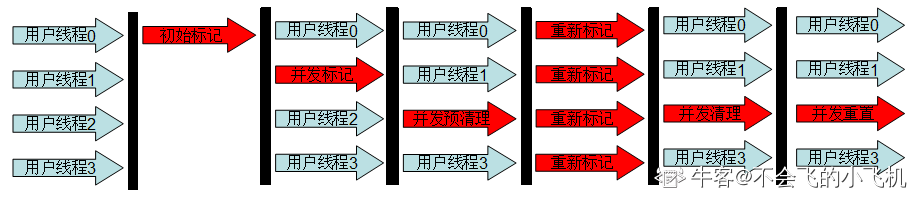
CMS垃圾回收器在那些阶段是没用用户线程参与的
正确答案: A C 你的答案: C D (错误)
初始标记并发标记重新标记并发清理来源:https://www.nowcoder.com/questionTerminal/48ee199608824e409cca879ae50e6022
CMS全称 Concurrent Mark Sweep,是一款并发的、使用标记-清除算法的垃圾回收器,以牺牲吞吐量为代价来获得最短回收停顿时间的垃圾回收器,对于要求服务器响应速度的应用上,这种垃圾回收器非常适合。
CMS的基础算法是:标记—清除。
它的过程可以分为以下6个步骤:
- 初始标记(STW initial mark)
- 并发标记(Concurrent marking)
- 并发预清理(Concurrent precleaning)
- 重新标记(STW remark)
- 并发清理(Concurrent sweeping)
- 并发重置(Concurrent reset)
- 初始标记:在这个阶段,需要虚拟机停顿正在执行的任务,官方的叫法STW(Stop The Word)。这个过程从垃圾回收的"根对象"开始,只扫描到能够和"根对象"直接关联的对象,并作标记。所以这个过程虽然暂停了整个JVM,但是很快就完成了。
- 并发标记:这个阶段紧随初始标记阶段,在初始标记的基础上继续向下追溯标记。并发标记阶段,应用程序的线程和并发标记的线程并发执行,所以用户不会感受到停顿。
- 并发预清理:并发预清理阶段仍然是并发的。在这个阶段,虚拟机查找在执行并发标记阶段新进入老年代的对象(可能会有一些对象从新生代晋升到老年代, 或者有一些对象被分配到老年代)。通过重新扫描,减少下一个阶段"重新标记"的工作,因为下一个阶段会Stop The World。
- 重新标记:这个阶段会暂停虚拟机,收集器线程扫描在CMS堆中剩余的对象。扫描从"根对象"开始向下追溯,并处理对象关联。
- 并发清理:清理垃圾对象,这个阶段收集器线程和应用程序线程并发执行。
- 并发重置:这个阶段,重置CMS收集器的数据结构,等待下一次垃圾回收。
CMS不会整理、压缩堆空间,这样就带来一个问题:经过CMS收集的堆会产生空间碎片,CMS不对堆空间整理压缩节约了垃圾回收的停顿时间,但也带来的堆空间的浪费。
为了解决堆空间浪费问题,CMS回收器不再采用简单的指针指向一块可用堆空 间来为下次对象分配使用。;而是把一些未分配的空间汇总成一个列表,当JVM分配对象空间的时候,会搜索这个列表找到足够大的空间来hold住这个对象。
从上面的图可以看到,为了让应用程序不停顿,CMS线程和应用程序线程并发执行,这样就需要有更多的CPU,单纯靠线程切 换是不靠谱的。并且,重新标记阶段,为空保证STW快速完成,也要用到更多的甚至所有的CPU资源。
B.并发标记 和 D.并发清理 这两个阶段是有用户线程参与的,所以答案选A和C。
final、finally和finalize的区别中,下述说法正确的有?
正确答案: A B 你的答案: A B C (错误)
final用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。finally是异常处理语句结构的一部分,表示总是执行。finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源的回收,例如关闭文件等。引用变量被final修饰之后,不能再指向其他对象,它指向的对象的内容也是不可变的。来源:https://www.nowcoder.com/questionTerminal/47ffaf4670384e34a925e294fcd686c0
选AB
A,D考的一个知识点,final修饰变量,变量的引用(也就是指向的地址)不可变,但是引用的内容可以变(地址中的内容可变)。
B,finally表示总是执行。但是其实finally也有不执行的时候,但是这个题不要扣字眼。
1. 在try中调用System.exit(0),强制退出了程序,finally块不执行。
2. 在进入try块前,出现了异常,finally块不执行。
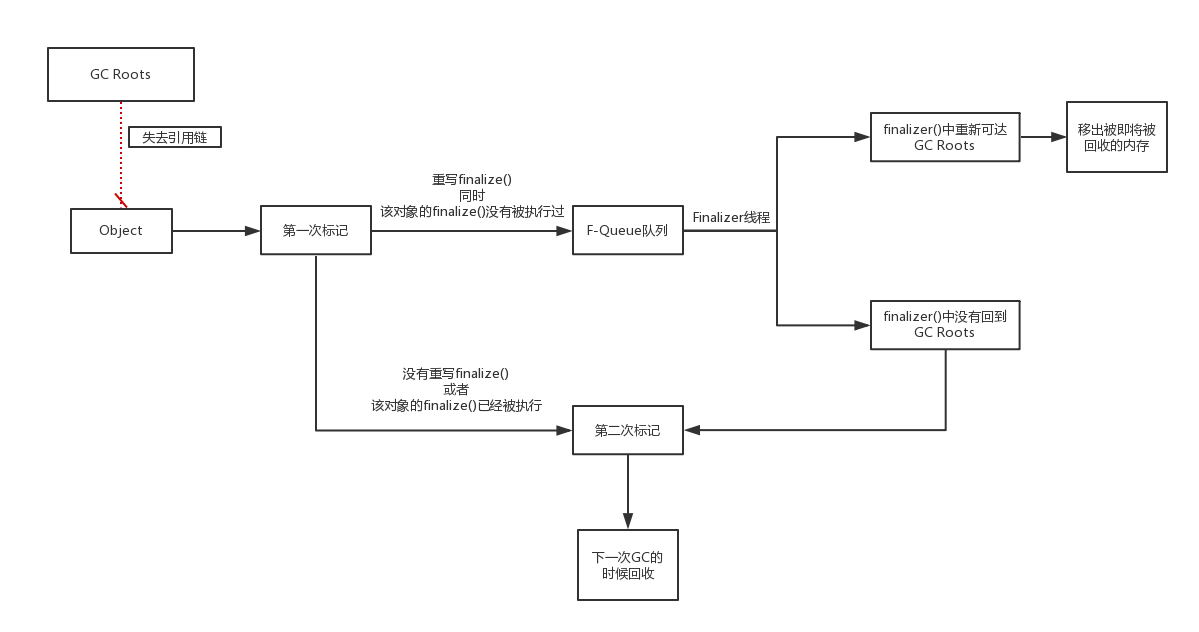
C,finalize方法,这个选项错就错在,这个方法一个对象只能执行一次,只能在第一次进入被回收的队列,而且对象所属于的类重写了finalize方法才会被执行。第二次进入回收队列的时候,不会再执行其finalize方法,而是直接被二次标记,在下一次GC的时候被GC。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









