






mysql
1、sql语句
1.1 DQL(数据查询语言)
select //5
//distinct表示去除重复数据
{distinct} [table line name] as [别名],[table line name],[分组函数]......
from //1
[table name] [别名]
//表内连接时使用join on代码结构性更好
//用了leftt和right则为外连接,没有则为内连接
//可以连接多次,使用多次join...on...都是看做与第一个表连接
{left/right} join
[table name] [别名]
on
[where statement]
{left/right} join...on...
.......
where //2
[where statement]
group by //3
[table line name]
having //4
[where statement]
order by //6
[table line name] [desc(降序) or asc],[table line name] [desc(降序) or asc]...
分组函数(多行处理函数)
-
分组函数不能出现在where之后,所有分组函数都忽略null
-
分组函数都是在group by之后运行,对每组分别进行处理,having对分组后在筛选
-
在使用order by之后select之后只能使用分组函数和参与分组的列
| 运算符 | 描述 |
|---|---|
| sum([table line name]) | 和(有null其中计算的最后结果一定为null/0) |
| max( ) | 最大 |
| min( ) | 最小 |
| avg( ) | 平均 |
| count( ) | 计数 |
单行处理函数
ifnull([table line name],[data]) : 当表列数据为null时当作data
条件查询(where语句)
| 运算符 | 说明 |
|---|---|
| =,<>或!=,<,<=,>,>= | 大小比较 |
| between…and… | 在两个值之间 |
| is null(is not null) | 为null(不为null) |
| and(or) | 并且(或者)(and的优先级高) |
| like | 模糊查询(%任意多个字符 _任意一个字符 \_%表示字符%) |
| in | 包含,相当于多个or(not in 不包含) in(data1,data2) |
| not | 取非 |
连接
内连接
- A,B表连接,没有主次之分,两张表是平等的
select
[table line name]......
from
[table name A]
join
[table name B]
on
[where statement];
外连接
- A,B表连接,有一张表是主表,一张副表,主要查询主表,捎带查询副表,当副表中的数据没有和主表的数据匹配,副表自动模拟出NULL与之匹配
select
[table line name]......
from
[table name A]
left/right join
[table name B]
on
[where statement];
全连接
- 两张表都是主表
union的用法
- 将查询结果集相加。
- 可以将两张不相干的数据拼接在一起
limit(mysql特有,oracle相同的机制rownum)
//最后执行,从0取起,取5个
\select...from...\ limit 0,5;
//取前5个
limit 5;
1.2 DDL(数据定义语言)
1.2.1 mysql数据类型
| 数据类型 | 说明 |
|---|---|
| int | 整数型 |
| bigint | 长整型 |
| float | 浮点型 |
| char | 定长字符串 |
| varchar | 可变长字符串(最大255字符) |
| data | 日期类型 |
| BLOB | 二进制大对象 |
| CLOB | 字符大对象 |
1.2.2 数据库操作
show databases; //显示所有数据库
use [database name]; //使用数据库
show tables; //显示使用数据库中的所有表
show tables from [database name]//显示目标数据库中所有表
create database [database name]; //创建数据库
drop database [database name]; //删除数据库
source [.sql file src]; //使用.sql脚本
desc [table name]; //查看表的结构
show create table [table name]; //查看创建表的所有语句
select database(); //查看使用的数据结构
select version(); //查看mysql版本
1.2.3 创建表
create table [table name](
字段名1 数据类型 {列级完整性约束},
字段名2 数据类型 {列级完整性约束},
......
{表级完整性约束}
);
//将查询语句得到的表创建起来
create table [table name] as [select statement];
1.2.4 删除表
drop table [table name];
1.2.5 修改表
alter table [table name] [add/modify/change/drop/rename to]
[add 字段名 类型 约束]
[drop 字段名]
[modify 字段名 新类型]
[change 字段名 新字段名 新类型 约束]
[rename to 新表名]
1.2.6 约束
//非空约束(not null)字段不能为空
字段名1 数据类型 not null, //列级约束
//唯一约束(unique)字段不能重复
字段名2 数据类型 unique, //列级约束
unique(字段名1,字段名2), //表级约束
//主键约束(primary key)字段不能重复和为空,用于表中每条数据的唯一标识
字段名3 数据类型 primary key, //列级约束
primary key(字段名...) //表级约束,一个字段则为单一主键,多个字段则为复合主键(不推荐用)
字段名4 int primary key auto_increment, //表示主键字段自动维护一个自增的数字,从1开始
//外键约束(foreign key)
//子表的字段名1引用父表的字段名2,字段名1的值只能为字段名2中的值或者null
//字段名2可以为主键和唯一约束unique
foreign key(字段名1) references [father table name](字段名2)
//检查约束(check)(Oracle有,但mysql没有)
//额外(非约束)
auto_increment(自动增长)
1.3 DML(数据操作语言)
1.3.1 插入数据
insert into [table name](字段名1,字段名2...) values(值1,值2...);
insert into [table name] values(值1,值2...); //按照表的结构列顺序赋值
insert into [table name] values(...),(...),(...); //插入多行数据
insert into [table name] as [select statement]; //对表的结构有要求,列数必须相同
1.3.2 删除数据
delete from [table name] where [where statement];
delete from [table name]; //删除表所有数据,没有释放对应的空间
truncate table [table name]; //删除表所有数据,释放对应空间,无法回滚,永久丢失
1.3.3 修改数据
update [table name] set 字段名1=值1,字段名2=值2... where [where statement];
update [table name] set 字段名1=值1,字段名2=值2...; //所有数据改为对应赋值
1.4 DCL(数据控制语言)
1.4.1 用户管理
user mysql;
select * from user;
create user 用户名@主机名 identified by 密码
alter user 用户名@主机名 identified with mysql_native_password by 新密码
drop user 用户名@主机名
1.4.2 权限管理
权限列表
- all
- select
- insert
- update
- delete
- create
- drop
- alter
show grants for 用户名@主机名
grant 权限列表 on 数据库名.表名 to 用户名@主机名
revoke 权限列表 on 数据库名.表名 to 用户名@主机名
2、函数
2.1 字符串函数
- concat(str1,str2)
- lower(str)
- upper(str)
- lpad(str,len,pad)
- rpad(str,len,pad)
- trim(str)
- substring(str,index,len)
2.2 数值函数
- ceil(x)
- floor(x)
- mod(x,y)
- rand()
- round(x,3) 四舍五入,保留几位小数
2.3 日期函数
- curdate()
- curtime()
- now()
- year(date)
- month(date)
- day(date)
- date_add(date,[xxx])
- datediff(date1,date2)
2.4 流程函数
- if(val,Y,N)
- ifnull(val,val2)
- case val when val1 then result1 case defaultval end
- case when [] then val1 when [] then val2 case defaultval end
3、存储引擎
- (Oracle中对应机制,但不叫存储引擎,Oracle中没有特殊的名字,就是“表的存储方式”)
//查看当前版本mysql支持的存储引擎
show engines \G;
| 特点 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 |
| 事务安全 | 支持 | - | - |
| 锁机制 | 行级 | 表级 | 表级 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | - | - | 支持 |
| 全文索引 | 支持(5.6版本后) | 支持 | - |
| 空间使用 | 高 | 低 | N/A |
| 内存使用 | 高 | 低 | 中等 |
| 批量插入速度 | 低 | 高 | 高 |
| 支持外键 | 支持 | - | - |
4、事务
-
事务只和DML(insert,delete,update)语句有关
-
事务的特性:ACID
A: 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
C: 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
I: 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
D: 持久性(Durability):事务旦提交或回滚,它对数据库中的数据的改变就是永久的。
4.1 隔离级别
| 隔离级别 | 说明 | 缺点 |
|---|---|---|
| 读未提交(read uncommitted) | 对方事务还没提交,我们当前事务可以读取对方未提交的数据 | 读未提交存在脏读(Dirty read)现象 |
| 读已提交(read committed) | 对方事务提交了后,我方可以读取到 | 不可重复读我们开启事务时对方修改前数据 |
| 可重复读(repeatable read) | 我方看见的一直是开启事务时的数据 | 若对方修改过数据,我方读取的数据都是幻象 |
| 序列化读(Serialization read) | 一个事务开启后,不能开启另一个事务 | 效率低下 |
4.2 事务命令
//开启事务,关闭mysql的自动提交功能
start transaction;
//回滚
rollback
//提交
commit
//设置事务的全局隔离级别
set global transaction isolation level [read uncommitted]
//查看现在的隔离级别
select @@global.transaction_isolation;
4.3 事务原理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JSJmxIWH-1658505969974)(https://cdn.jsdelivr.net/gh/l1727894442/image/20220722205815.png)]
4.3.1 MySQL日志
- redo log (保证持久性)
重做日志,记录的是事务提交时数据页的物理修改,是用来实现事务的持久性。
该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log file),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都存到该日志文件中,用于在刷新脏页到磁盘,发生错误时,进行数据恢复使用。
- undo log (保证原子性)
回滚日志,用于记录数据被修改前的信息,作用包含两个:提供回滚和MⅣCC(多版本并发控制)。
undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update-一条记录时,它记录一条对应相反的update记录。当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。
Undo log销毁:undo log在事务执行时产生,事务提交时,并不会立即删除undo log,因为这些日志可能还用于MVCC。
Undo log存储:undo log采用段的方式进行管理和记录,存放在前面介绍的rollback segment回滚段中,内部包含1024个undo log
segment。
4.3.2 MVCC
- 当前读
读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。对于我们日常的操作,如:select…lock in share mode(共享锁),select…for update、update、insert、delete(排他锁)都是一种当前读。
- 快照读
简单的select(不加锁)就是快照读,快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读。
- Read Committed:每次select,都生成一个快照读。
- Repeatable Read:开启事务后第一个selecti语句才是快照读的地方。
- Serializable:快照读会退化为当前读。
- MVCC基本概念
全称Multi–Version Concurrency Control,多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供了一个非阻塞读功能。MVCC的具体实现,还需要依赖于数据库记录中的三个隐式字段、undo log日志、readView。
5、索引
5.1 索引分类
-
主键索引
-
唯一索引
-
常规索引
-
全文索引
-
聚集索引
-
二级索引
-
联合索引
-
单行索引
5.2 索引命令
/*
创建 常规/全文/唯一 索引
*/
create [fulltext/unique] index [index name] on [table name]([column]...);
drop index [index name] on [table name];
/*
建议使用/忽略/强制使用 目标索引进行查询
*/
select * from table use index(索引名) where ...;
select * from table ignore index(索引名) where ...;
select * from table force index(索引名) where ...;
5.3 索引失效情况
- 联合索引不符合最左前缀原则
- 联合索引使用范围查询< >时,后续索引失效
- 在索引列上进行函数运算
- 类型隐式转换导致索引失效
- 模糊匹配前面使用%导致索引失效
- 使用了or条件查询,若一侧有索引,一侧无索引,索引失效
5.4 SQL优化
使用explain查询select语句的使用情况
explain select …
5.4.1 insert优化
- 批量插入
#insert优化,大量数据插入可以直接使用load命令吧普通文件中数据插入
#客户端连接服务端时,加入参数 --local-infile
mysql --local-infile -u root -p
#设置全局参数local_infile为1
set global local_infile=1;
#执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/sql.log' into table 'tb_user' fields terminated by ',' lines terminated by '\n'
- 手动提交事务
- 主键顺序插入
5.4.2 主键优化
- 满足业务需求的情况下,尽量降低主键的长度
- 插入数据时,最好顺序插入
- 尽量不要使用UUID作为主键或其他自然主键,如身份证号等
5.4.3 order by优化
order by优化
创建索引的时候可以指定排序的方法
create index indexname on table(column1 desc,column2 desc)
5.4.4 limit优化
覆盖索引加子查询可以优化limit查询
select s.* from table s,(select id from table order by id limit 2000000,10) t where s.id=t.id
5.4.5 update优化
update的时候where条件使用索引列,防止把行级锁变成表级锁
6、视图
视图是一种虚拟存在的表,视图中的数据并不在数据库中实际存在,数据来自定义视图的查询中使用的表。
create [or replace] view 视图名称 as select语句 [with [cascaded|local] check option]
#使用with check option后对视图进行增删改操作时会检查select中打的where条件
#要对视图做更新操作,那么视图中的行必须与基本表中的行存在一对一的关系,如果视图包含一下任意一项,视图不能更新
/*
1.聚合函数
2.distinct
3.group by
4.having
5.union/union all
*/
drop view [if exists] 视图名称;
7、存储过程
#创建
delimiter $
create procedure 存储过程名(in|out|inout 参数名 参数类型,...)
[characteristics ...]
begin
存储过程体
end $
delimiter ;
#调用
call 存储过程名();
#查看
show create procedure 存储过程名
#删除
drop procedure 存储过程名
7.1 变量
#系统变量
#session级别的参数只在一个会话有效
#global级别的参数改变在系统重启后也会回复默认值
show [session|global] variables;
show [session|global] variables like '';
select @@session.autocommit;
select @@global.autocommit;
set session autocommit=0;
set global autocommit=1;
#用户变量
declare 变量名 变量类型 [default 值]
set @myname = 'liucheng';
set @myage := 1;
select count(*) into @myage from user;
select @myname,@myage;
7.2 语法
#if判断
if score>=30 then
set result := 'a'
elseif score >=20 then
set result := 'b'
else
set result := 'c'
end if;
#case
case
when month>=1 and month <=3 then
set result := 'a'
when month>3 and month<=6 then
set result := 'b'
else
set result := 'c'
end case;
case month
when 1 then
set result := 'a'
when 2 then
set result := 'b'
else
set result := 'c'
end case;
#while
while n>0 do
set n := n-1
end while;
#repeat
repeat
set n:=n-1
until n>=0
end repeat;
#loop
sum:loop
if n<0 then
leave sum|iterate sum;
end if;
set n := n-1;
end loop sum;
7.3 游标
#声明游标
declare 游标名 cursor for select语句;
#打开游标
open 游标名
#获取游标记录
fetch 游标名 into 变量,变量...
#关闭游标
close 游标名
7.4 存储函数
characteristics说明:
- deterministic:相同的输入参数总是相同的结果
- no sql:不包含sql语句
- reads sql data:包含读取数据的语句,但不包含写入数据的语句
create function 函数名(参数名 参数类型,...)
returns 返回值类型 [characteristics ...]
begin
函数体,需要return语句
end
#调用
select 函数名();
set b := 函数名();
8、触发器
#创建
create trigger 触发器名
[after|before] [insert|update|delete] on 表名 for each row
begin
#这里可以使用new|old使用新|旧的一行数据
#ps: new.id old.id
end;
#查看
show triggers;
#删除
drop trigger 触发器名
9. 锁
9.1 全局锁
- 使用在全局数据备份的情况下,加锁后只能执行DQL语句,其他语句不能执行
对当前数据库加上全局锁
flush tables with read lock
释放全局锁
unlock tables
9.2 表级锁
9.2.1 表锁
- 表共享读锁
lock tables [table name] read
unlock tables
设置了表共享读锁后,所有的客户端都不能写入,只能读取
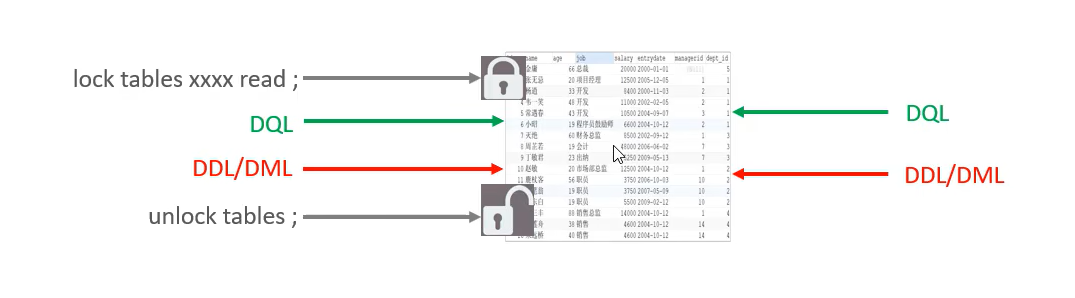
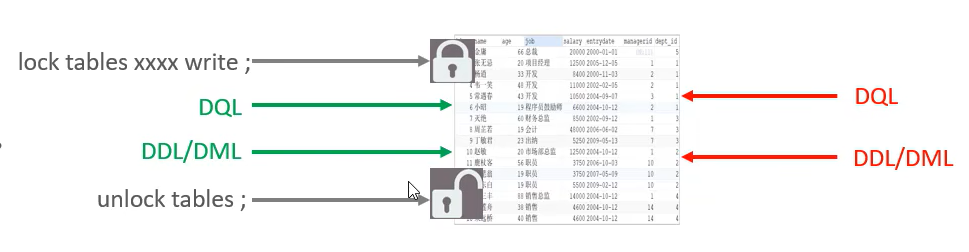
- 表独占写锁
lock table [table name] write
unlock tables
设置了表独占读锁后,所有的其他客户端都不能读写
9.2.2 元数据锁
元数据锁(meta data lock,MDL)
MDL加锁过程是系统自动控制,无需显式使用,在访问一张表的时候会自动加上。MDL锁主要作用是维护表元数据的数据一致性,在表上有活动事务的时候,不可以对元数据进行写入操作。为了避免DML与DDL冲突,保证读写的正确性。

select object_type,object_schema,object_name,lock_type,lock_duration from performance_schema.metadata_ locks
9.2.3 意向锁
为了避免DML在执行时,行锁与表锁的冲突,在IoDB中引入了意向锁,使得表锁不用检查每行数据是否加锁,使用意向锁来减少表锁的检查。
意向共享锁(IS):由语句select…lock in share mode添加。
意向排他锁(IX):由insert、update、delete、select…for update添加。
与其他表兼容情况:
意向共享锁(IS):与表锁共享锁(read)兼容,与表锁排它锁(write)互斥。
意向排他锁(IX):与表锁共享锁(read)及排它锁(write)都互斥。意向锁之间不会互斥。
9.3 行级锁
行级锁,每次操作锁住对应的行数据。锁定粒度最小,发生锁冲突的概率最低,并发度最高。应用在InnoDB存储引擎中。
IoDB的数据是基于索引组织的,行锁是通过对索引上的索引项加锁来实现的,而不是对记录加的锁。对于行级锁,主要分为以下三类:
- 行锁(Record Lock):锁定单个行记录的锁,防止其他事务对此行进行update和delete。在RC、RR隔离级别下都支持。
- 间隙锁(Gap Lock):锁定索引记录间隙(不含该记录),确保索引记录间隙不变,防止其他事务在这个间隙进行insert,产生幻读。在RR隔离级别下都支持。
- 临键锁(Next-Key Lock):行锁和间隙锁组合,同时锁住数据,并锁住数据前面的间隙Gp。在RR隔离级别下支持。
9.3.1 行锁
1.共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排它锁。
2.排他锁(X):允许获取排他锁的事务更新数据,阻止其他事务获得相同数据集的共享锁和排他锁。

10、数据备份
#创建数据库(表)的备份
mysqldump -u [user] -p [password] [database name] {table name}>[.sql file src]
#加上--single-transaction参数不加锁实现一致性备份
mysqldump --single-transaction -u [user] -p [password] [database name] {table name}>[.sql file src]
11、三范式
11.1 第一范式
任何一张表都应该有主键,并且每一个字段原子性不可再分
11.2 第二范式
建立在第一范式的基础之上,所有非主键字段完全依赖主键,不能产生部分依赖
多对多,三张表,关系表两外键
11.3 第三范式
建立在第二范式的基础上,所有非主键字段直接依赖主键,不能产生传递依赖
一对多,两张表,多的表加外键















 42万+
42万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









