







GAN详解与MINIST手写数字生成实战
GAN简介
GAN(Generative Adversarial Nets) 用中文来说就是 生成对抗网络,它是Ian J. Goodfellow在2014年提出的一种深度学习网络模型。它包含两个模型:生成模型和辨别模型。生成模型是用来捕捉真实数据分布来生成符合原始数据分布的新的数据,辨别模型是用来辨别真实数据和生成模型生成的数据。生成模型的目的是为了来让辨别模型犯错,辨别模型的目的是为了区分生成数据和真实数据。这就好像是两个模型在互相对抗,在对抗中不断吸取经验从而来让自身得到提升,可以类比博弈论中的两人对抗游戏。GAN 可以通过**MLP(多层感知机)**来进行误差反传进行训练。这样就比使用马尔科夫链或者对近似推理过程展开更加简单。由于GAN在生成图像方面有很好的效果,所以得到了很广泛的应用,比如生成名人小时候的照片,将真实人物变成卡通形式,甚至还可以生成世界上不存在的人的脸部照片。
GAN论文原理
对于生成器,以生成图片为例,我们需要输入一个噪声
z
z
z,就类似一个一百维的变量吧,然后
z
z
z通过从真实数据
x
x
x中学习到的分布
p
g
p_g
pg去进行映射,就可以生成一张图片
G
(
z
)
G(z)
G(z)
对于辨别器D,我们就是去对生成数据和真实数据进行分类,类似一个两类的分类器。设
D
(
x
)
D(x)
D(x)表示
x
x
x是来自真实数据而不是
p
g
p_g
pg的概率。
根据GAN的需求,我们需要尽可能让辨别器能够辨别真实数据和生成数据并且让生成器生成数据让辨别器尽可能犯错。简而言之就是最大化
l
o
g
(
D
(
x
)
)
log(D(x))
log(D(x)),最小化
l
o
g
(
1
−
D
(
G
(
x
)
)
)
log(1-D(G(x)))
log(1−D(G(x))),所以我们可以得到如下公式:
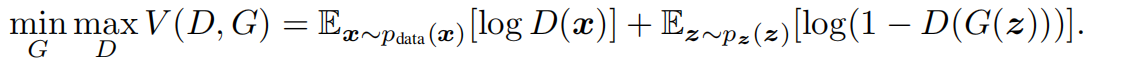
这样
D
D
D和
G
G
G就在好像进行两人对抗游戏。
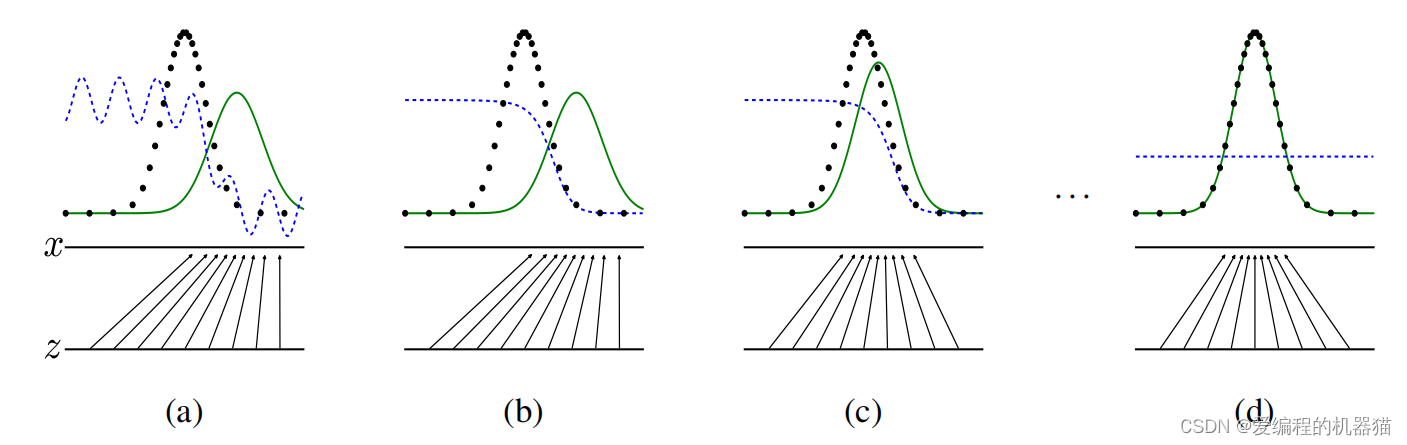
这是GAN的训练过程,其中绿色的线为生成器生成的数据,黑色的点为真实数据,蓝色的点为辨别器的结果。从a-b-c-d可以看出,生成器生成的数据在不断向真实数据拟合,辨别的结果也在不断改变,最后黑色的点和绿色的线完全拟合时辨别器无法辨别真实数据和生成数据时,此时辨别器的曲线值为0.5(0表示生成数据,1表示真实数据),就无法通过辨别器的值来辨别数据来源。
下面介绍GAN的算法:

这里比较重要的就是
k
k
k的取值,它会关系到我们模型训练的好坏。
k
k
k的取值不能太小,也不能太大。如果
k
k
k的取值太小,这样每次更新生成器后辨别器得不到充分的更新,无法很好辨别真实数据和生成数据,这时就算不更新生成器也能糊弄辨别器,此时更新生成器的意义不大;如果
k
k
k的取值太大,意味着生成器更新后辨别器会被更新得很好,此时上述生成器梯度公式中
l
o
g
(
1
−
D
(
G
(
z
(
i
)
)
)
)
log(1-D(G(z^{(i)})))
log(1−D(G(z(i))))就是0,这是就对0求梯度,这样在生成模型的更新上会有困难。这里我们类比一个例子更好理解:假设辨别器就是警察,生成器就是造假者。如果警察太厉害,那么造假者生产一点假钞就被一锅端了,那么造假者就没法赚到钱,不能去进一步改进工艺;如果警察太无力,无法比较好分辨真钞和假钞,那么造假者随便生产点东西都能赚到钱,这样生产者就不会想着去改进工艺。所以两方面都不行,最好的就是两方实力相当,这样都能互相促进进步。
MINIST手写数字生成实战
这是一个利用手写数据集进行训练得到的GAN,生成器接收随机噪声作为输入,然后输出一张手写数字图像;判别器的输入则是两幅图像,分别是真的手写数字图像和生成器生成的假图像,然后输出对这两幅图像的判别结果。
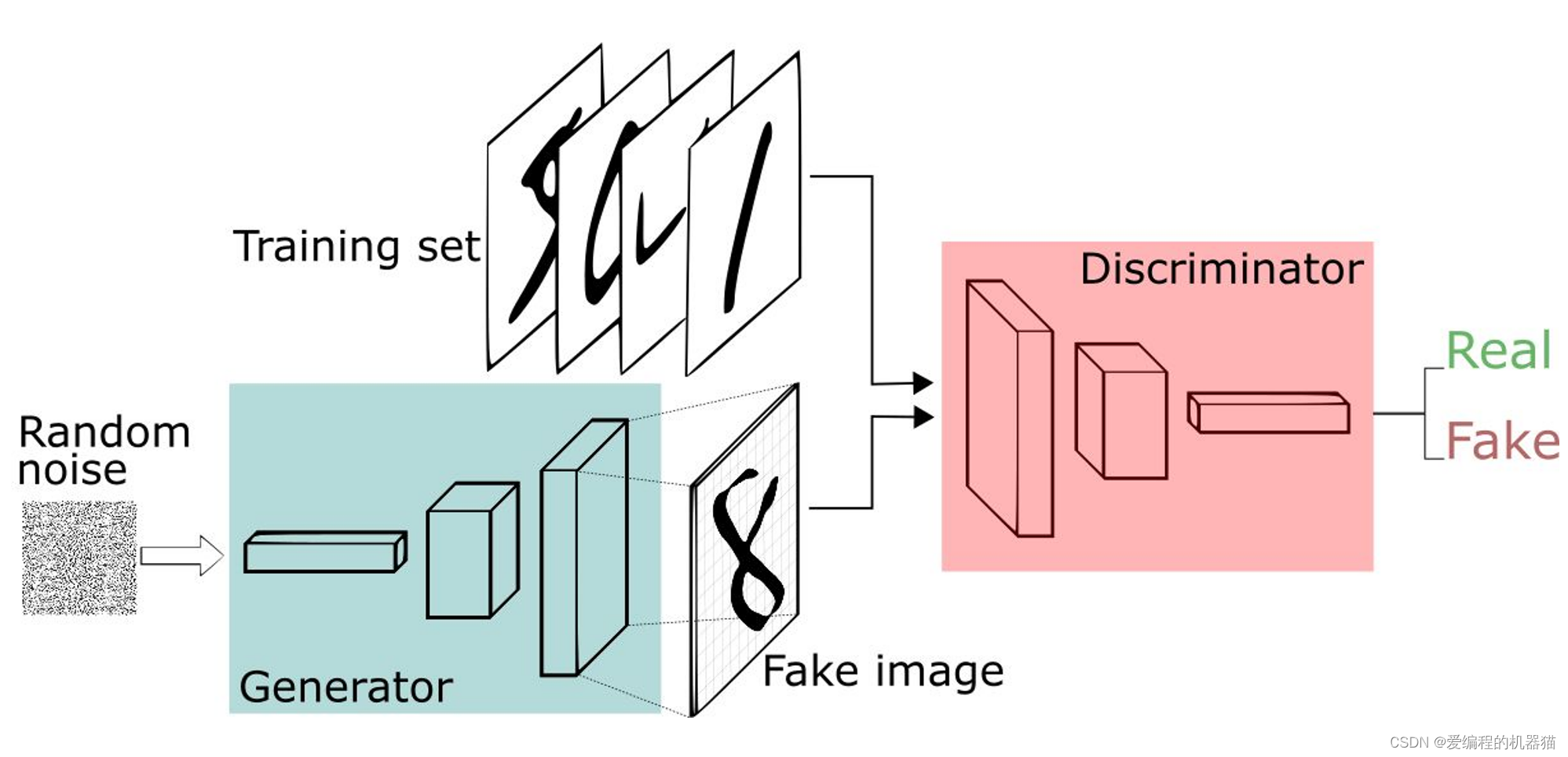
1、导入MINIST数据集。
train_data = dataloader.DataLoader(datasets.MNIST(root='data/', train=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
]), download=True), shuffle=True, batch_size=batch_sz)
2、构建辨别器和生成器
辨别器:
class discrimination(nn.Module):
def __init__(self):
super(discrimination, self).__init__()
self.hidden0 = nn.Sequential(
nn.Linear(784, 1024),
nn.LeakyReLU(0.2),
)
self.hidden1 = nn.Sequential(
nn.Linear(1024, 512),
nn.LeakyReLU(0.2),
)
self.hidden2 = nn.Sequential(
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
)
self.out = nn.Sequential(
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
x = self.hidden0(x)
x = self.hidden1(x)
x = self.hidden2(x)
x = self.out(x)
return x
这里我们对辨别器网络构造采用4层,前三层用LeakyReLu,最后一层用sigmoid。使用LeakyReLu是因为不会将零以下的数全部置为零,所以使用LeakyReLU 激活函数相比使用ReLU 能够更好地使梯度流过网络。使用sigmoid是因为能够将输出值约束在区间[0, 1]
生成器:
class generate(nn.Module):
def __init__(self):
super(generate, self).__init__()
self.hidden0 = nn.Sequential(
nn.Linear(100, 256),
nn.LeakyReLU(0.2)
)
self.hidden1 = nn.Sequential(
nn.Linear(256, 512),
nn.LeakyReLU(0.2)
)
self.hidden2 = nn.Sequential(
nn.Linear(512, 1024),
nn.LeakyReLU(0.2)
)
self.out = nn.Sequential(
nn.Linear(1024, 784),
nn.Tanh()
)
def forward(self, x):
x = self.hidden0(x)
x = self.hidden1(x)
x = self.hidden2(x)
x = self.out(x)
return x
生成器前面三层和辨别器一样,最后一层采用tanh激活函数,是为了与对MNIST 数据进行的归一化同步,以将其值转换到[-1, 1] 中,以便判别器始终获取数据点处于相同值域的数据集。
3、训练模型
def train_discriminator(optimizer, loss_fn, real_data, fake_data):
optimizer.zero_grad()
discriminator_real_data = discriminator(real_data)
loss_real = loss_fn(discriminator_real_data, torch.ones(real_data.size(0), 1).to(device))
loss_real.backward()
discriminator_fake_data = discriminator(fake_data)
loss_fake = loss_fn(discriminator_fake_data, torch.zeros(fake_data.size(0), 1).to(device))
loss_fake.backward()
optimizer.step()
return loss_real + loss_fake, discriminator_real_data, discriminator_fake_data
def train_generator(optimizer, loss_fn, fake_data):
optimizer.zero_grad()
output_discriminator = discriminator(fake_data)
loss = loss_fn(output_discriminator, torch.ones(output_discriminator.size(0), 1).to(device))
loss.backward()
optimizer.step()
return loss
for epoch in range(num_epoch):
for train_idx, (input_real_batch, _) in enumerate(train_data):
real_data = images2vectors(input_real_batch).to(device)
generated_fake_data = generator(noise(real_data.size(0))).detach()
d_loss, discriminated_real, discriminated_fake = train_discriminator(d_optimizer, loss_fn, real_data,
generated_fake_data)
generated_fake_data = generator(noise(real_data.size(0)))
g_loss = train_generator(g_optimizer, loss_fn, generated_fake_data)
if train_idx == len(train_data) - 1:
print(epoch, 'd_loss: ', d_loss.item(), 'g_loss: ', g_loss.item())
train_discriminator和train_generator是为了分别对辨别器和生成器求loss,并进行反向传播、参数优化。辨别器涉及到真实数据和生成数据俩方面的误差(上面图中有提到),所以将他们相加起来。
源代码见 MINIST手写数字生成
小伙伴喜欢文章的话记得 点赞加关注 哦,后面会更新其他深度学习的文章。
如果有什么写得有问题的地方希望大家能值出,谢谢。














 824
824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









