






 K-Means聚类算法是一种迭代的分类方法,用于将样本根据坐标距离划分为预设的K类。算法通过不断调整聚类中心来达到最佳划分效果。文中提供了一个MATLAB代码示例,展示了如何使用K-Means进行聚类并绘制结果。
K-Means聚类算法是一种迭代的分类方法,用于将样本根据坐标距离划分为预设的K类。算法通过不断调整聚类中心来达到最佳划分效果。文中提供了一个MATLAB代码示例,展示了如何使用K-Means进行聚类并绘制结果。
-
概述
K-Means聚类算法也叫K-均值聚类算法
简单来说,可以利用它来进行分类。
怎么分类呢?
你知道你有的这些样本的坐标之后,距离相近的点就会分为一类,如果你知道有三类,那他会根据坐标之间的距离划分为三类。 -
定义
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是,预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。 -
原理
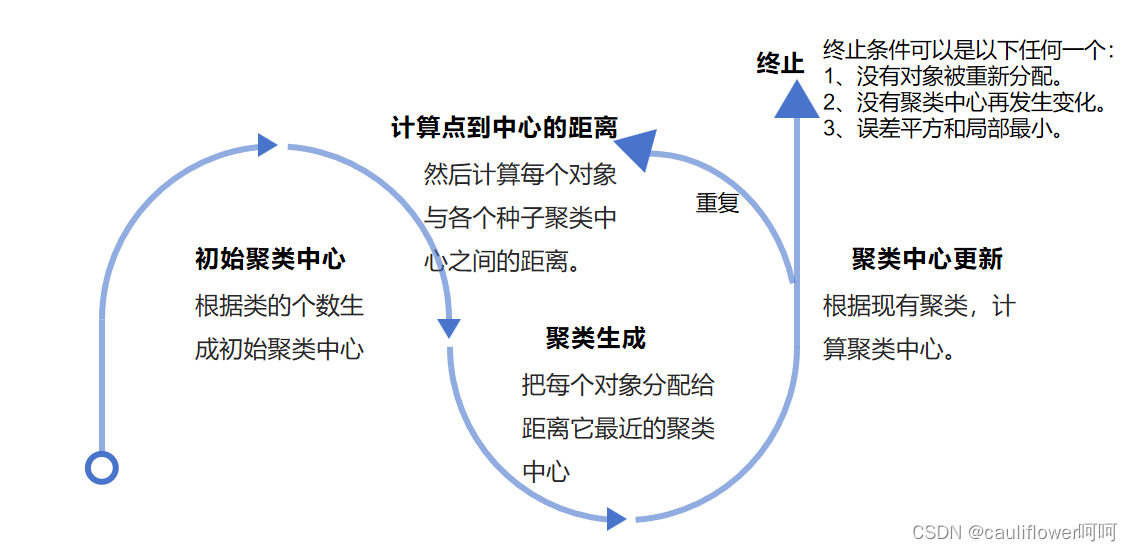
-
代码
以下是使用MATLAB实现k-means聚类算法并绘制聚类结果的代码示例:
function kmeans_plot(X, k)
% 初始化聚类中心
m = size(X, 1); % 数据点的数量
centroids = X(randperm(m, k), 😃;
previous_centroids = centroids;% 迭代聚类
converged = false;
while ~converged
% 为每个数据点分配到最近的聚类中心
distances = sqdist(X, centroids);
[~, cluster_idx] = min(distances, [], 2);% 更新聚类中心的位置 for j = 1:k centroids(j
K-Means聚类算法

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











