









Powered by:NEFU AB-IN
Pseudo-Distributed Operation
Hadoop 也可以在伪分布式模式下的单节点上运行
官方文档:https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/SingleCluster.html
官方文档介绍的很详细,我在此记一下重点
八个文件
- core-site.xml
- hadoop-env.sh
- hdfs-site.xml
- yarn-env.sh
- yarn-site.xml
- mapred-env.sh
- mapred-site.xml
- slaves
五个端口
- 50070 : hadoop-dfs.http.address,查看NameNode状态,该端口的定义位于core-default.xml中,HDFS Web UI端口(可访问)
- 50075 : 查看DataNode的,该地址和端口的定义位于hdfs-default.xml中. 帮助下载50070界面的文件
除此之外还需要在本机的hosts文件中,配置自己主机名和公网ip的映射 - 50010 : DataNode控制端口
- 8088 : hadoop-resourcemanager.webapp.address,YARN Web UI端口(可访问)
- 19888 : hadoop-jobhistory.webapp.address,历史服务器Web UI端口(可访问)
- 50090:Hadoop secondary NameNode服务与Web UI端口(可访问)

-
core-site.xml
配置两个:-
fs.defaultFS: 在local模式下是本地文件系统,需要更改成hdfs
-
hadoop.tmp.dir:配置到比较大的地方
-
注意:
- 第一是改主机名,改成自己的主机名
- 第二是这两部分都要被
<configuration>扩起来
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://AB-IN:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-2.7.2/data/tmp</value> </property> </configuration>
-
-
hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_144 -
hdfs-site.xml
<!-- 默认副本数量为3,即是完全分布式的要求 --> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.http.address</name> <value>0.0.0.0:50070</value> </property> </configuration> -
启动ssh
配置文件/etc/ssh/sshd_configPasswordAuthentication yes PermitRootLogin yessudo apt-get install openssh-server service ssh start比较关键的一句话 ,root@ 后面是要加的主机名,密码是root密码
ssh-copy-id -i ~/.ssh/id_rsa.pub root@localhost -
格式化NameNode
一次就好,千万别每次上机都来一次,会导致namenode和datanode不匹配
如果真的需要格式化的话,就把两个进程结束,再去删/opt/hadoop-2.7.2/data 和 /opt/hadoop-2.7.2/logsbin/hdfs namenode -format出现0了才算成功

-
启动NameNode,启动DataNode
sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanode -
jps 可以查看集群启动状况
-
创建(多级)路径
可以不加bin/,因PATH中配置了HADOOP_HOMEbin/hdfs dfs -mkdir -p /user/root/input -
(递归)列出
bin/hdfs dfs -ls /user/root/input bin/hdfs dfs -ls -R / -
向HDFS上传文件
将之前在本机上做的 W o r d C o u n t WordCount WordCount案例的输入上传bin/hdfs dfs -put ./wcinput/wc.input /user/root -
基于HDFS运行官方给出的例子:Grep和WordCount程序
现在是伪分布,所以要写hdfs的地址。而且output文件夹不要提前建立bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+' bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/root/input /user/root/output -
输出HDFS上文件的内容
同时在output文件里_SUCCESS,看是否成功bin/hdfs dfs -cat /user/root/output/p* -
yarn-env.sh
配置JAVA_HOMEexport JAVA_HOME=/opt/jdk1.8.0_144 -
yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <!--Reducer获取数据的方式--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--指定Yarn的ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>AB-IN</value> </property> </configuration> -
mapred-env.sh
配置JAVA_HOMEexport JAVA_HOME=/opt/jdk1.8.0_144 -
mapred-site.xml
先将mapred-site.xml.template重命名为mapred-site.xml<configuration> <!--指定MR运行在Yarn上,默认数值是local,即本地资源调配,将其改成yarn--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
启动ResourceManager,NodeManager
保证NameNode和DataNode已经启动sbin/yarn-daemon.sh start resourcemanager sbin/yarn-daemon.sh start nodemanager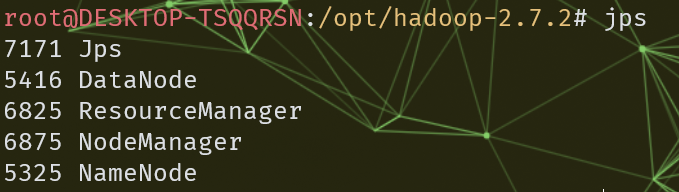
-
再执行wordcount job
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/root/input /user/root/output期间我遇到了这个问题
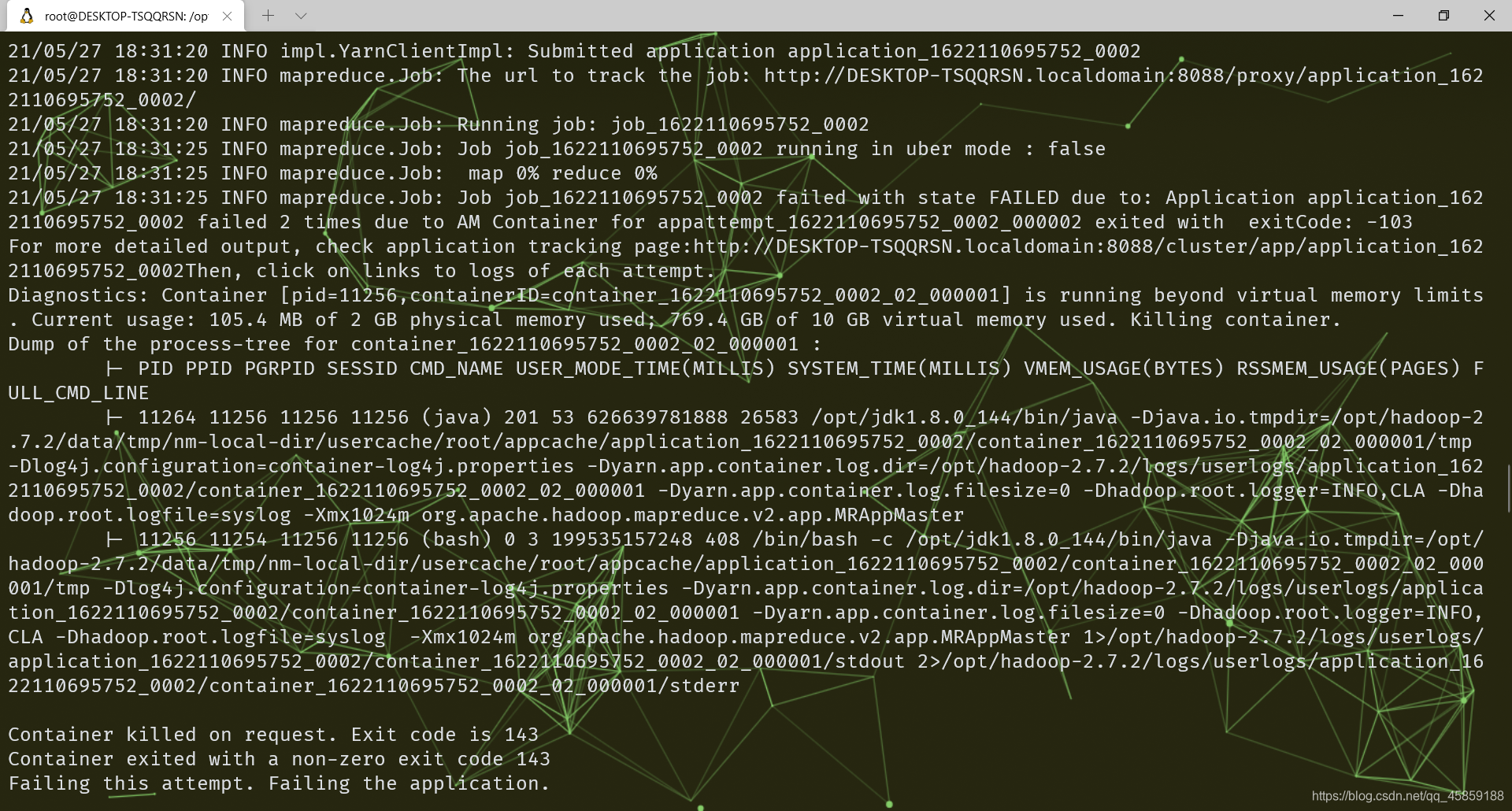
挑重点说769.4 GB of 10 GB virtual memory used. Killing container. Container killed on request. Exit code is 143 Container exited with a non-zero exit code 143看出来时虚拟内存太大了,杀死了container进程
所以在etc/hadoop/yarn-site.xml 加入下面<!--增大默认大小--> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>5</value> </property> <!--不对容器强制执行虚拟内存限制--> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>并重启yarn!!!!
结果
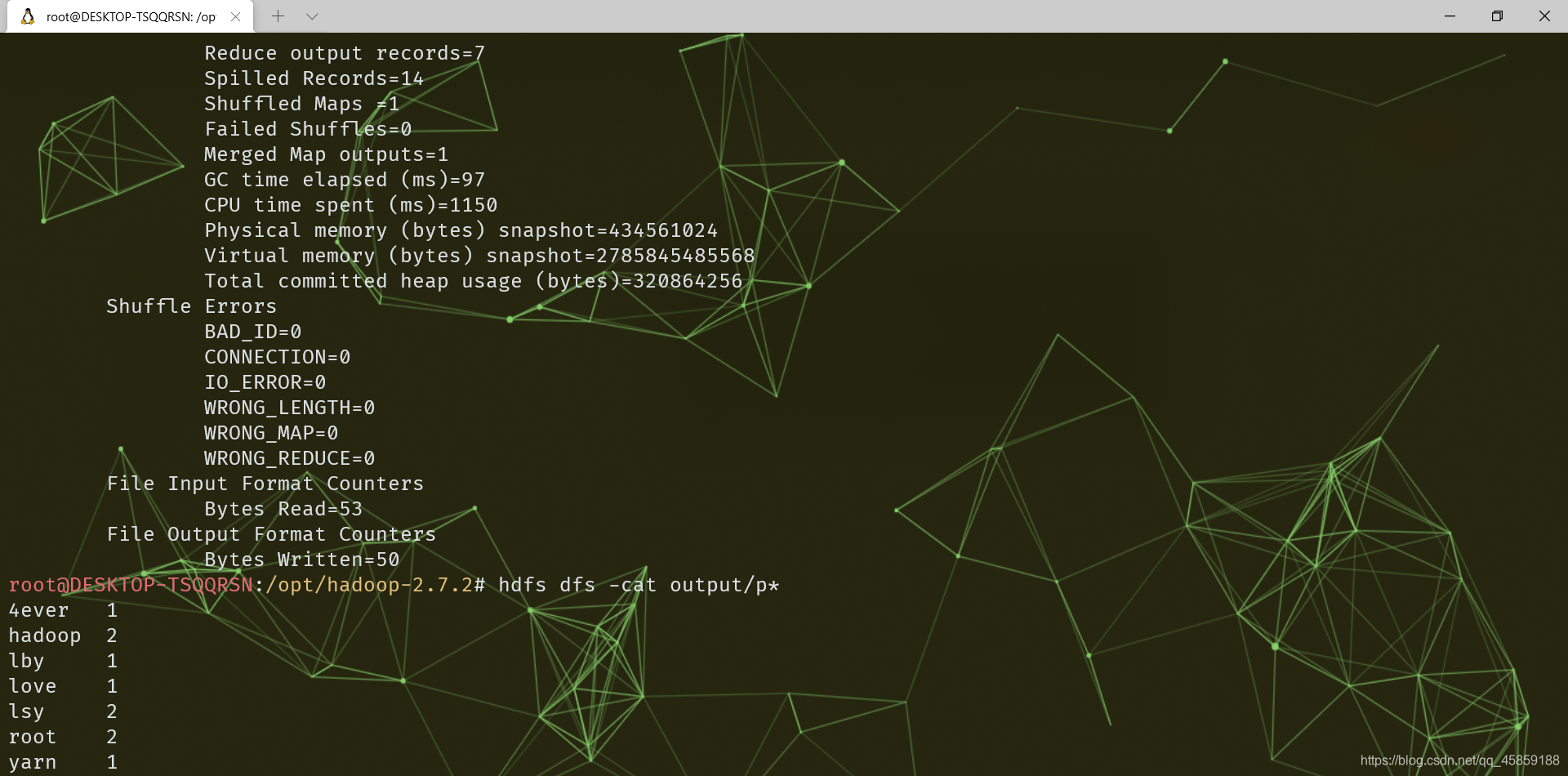
-
配置历史服务器
- mapred-site.xml
<!--历史服务器端地址,即工作端口--> <property> <name>mapreduce.jobhistory.address</name> <value>AB-IN:10020</value> </property> <!--历史服务器Web端地址,即访问端口--> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>0.0.0.0:19888</value> </property> </configuration>- 启动历史服务器
sbin/mr-jobhistory-daemon.sh start historyserver- 查看JobHistory
http://主机名:19888 http://IP:19888 -
配置日志的聚合
-
日志聚合的概念:应用运行完成以后,将程序运行的日志信息上传的HDFS。
日志聚合的好处:可以方便地查看程序运行的详情,方便开发调试。
-
yarn-site.xml
<!--日志聚合功能使能--> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!--日志保留时间设置为七天--> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>0.0.0.0:8088</value> </property>- 重启NodeManager、ResourceManager、HistoryManager
sbin/mr-jobhistory-daemon.sh stop historyserver sbin/yarn-daemon.sh stop nodemanager sbin/yarn-daemon.sh stop resourcemanager sbin/yarn-daemon.sh start resourcemanager sbin/yarn-daemon.sh start nodemanager sbin/mr-jobhistory-daemon.sh start historyserver -
最后关于使用服务器而非wsl的,端口一定要在安全组中放开,如果配置了宝塔服务,在宝塔中端口需要进行二次放行,需要注意。















 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











