







目录
任务要求
- 整合、完善已完成的编译程序各阶段相关功能,并能可视化演示。
- 完成编译后端,生成汇编代码。
开发环境
操作系统:Windows10
开发工具::DEV-C++、VISUAL C++ 6.0
实验原理
编译过程分为词法分析、语法分析、语义分析、生成中间代码、代码优化、生成目标代码(这里没有涉及到代码优化功能的内容,只有五个功能版块)。
词法分析
词法分析中,实现的功能是分割每个单词,同时判断每个单词的类型,并二元组的形式将其输出。
【程序框架】:

【输入】:以txt格式保存的源码文本。
【输出】:存储在结构体中的单词信息。
【函数】:
char hexdigit(char buffer);//十六进制数
int digit3(char num[]);//八进制数
char Digit(char buffer);//其他数字常量
char cut1(char buffer);//注释处理
char charprocess(char buffer);//其他字符
char Alpha(char buffer);//字母
char stringprocess(char buffer);//字符串常量
int search(char searchchar[ ]);//关键字【其他定义+数据结构】:
char key[35][20]= {"main","void","char","short","int","string","bool","long","float","double",
"sizeof","signed","unsigner","strcut","union","enum","typedef","auto","static",
"extern","register","const","volatile","if","else","for","while","do","break",
"goto","continue","return","switch","case","default"};
typedef struct
{
int typenum;//种别码
char type[10];//单词类型
char word[20];//单词
int wline;//单词在代码中的位置
}WordChart;
WordChart w[MAXSIZE];
char tree[MAXSIZE][MAXSIZE];//存储语法分析过程
int tlen=-1;
char E[MAXSIZE][MAXSIZE];//存储错误信息
int Elen=-1;【程序关键处理部分】:
①注释处理:灵活运用文件指针,当识别到单行注释的标志‘//’,文件指针直接跳到当前位置的下一行开始的字符;若识别到多行注释标识‘/*’,文件指针则一直往下一个字符移动直到识别到'*/';若‘/’只是一个运算符,则文件指针回退。
//处理代码注释
char cut1(char buffer)
{
buffer=fgetc(fp);//多行注释
if(buffer=='*')
{
buffer=fgetc(fp);
while(buffer!=EOF)
{
while(buffer!='*')
{
if(buffer=='\n')line++;
buffer=fgetc(fp);
}
buffer=fgetc(fp);
if(buffer=='/')
{
buffer=fgetc(fp);
break;
}
else continue;
}
}
else if(buffer=='/')//单行注释
{
fgets(buf,sizeof buf,fp);//跳到下一行
}
else
{
fseek(fp,-2L,1);//若‘/’是运算符,则回退到‘/’的前一个字符
buffer=fgetc(fp);
return(Other(buffer));
}
return(buffer);
}②数字处理:包括科学记数法、八进制、十六进制、小数、负数正数。根据状态转换图来编写程序。
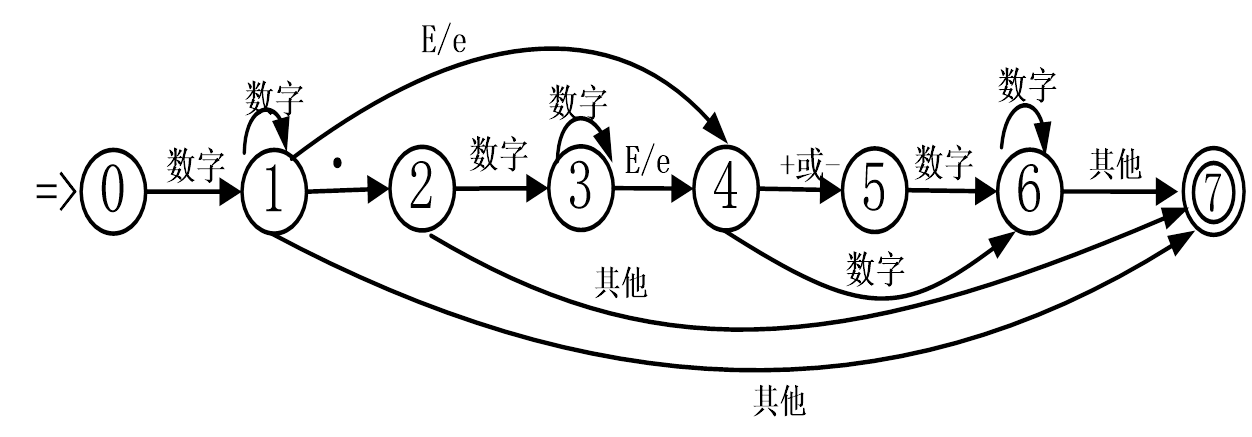
char Digit(char buffer)//小数、整数、科学记数法
{
char ch[20];
int i;
int tag;
int flag=0;
int count1=0;
ch[0]=buffer;
ch[1]='\0';
if(buffer=='0')
{
buffer=fgetc(fp);
if(buffer=='X'||buffer=='x') return(hexdigit(buffer));
else if(isalpha(buffer)||buffer=='_')
{
ch[1]=buffer;
buffer=fgetc(fp);
i=2;
while(isalpha(buffer)||isdigit(buffer)||buffer=='_')
{
ch[i]=buffer;
i++;
buffer=fgetc(fp);
}
ch[i]='\0';
strncpy(str,ch+1,i);
fprintf(fp0,"%d:%s:[Error]invalid suffix '%s' on integer constant\n",line,ch,str);
error++;
return(fgetc(fp));
}
else if((buffer>=32&&buffer<=34)||(buffer>=37&&buffer<=45)||(buffer==47)||(buffer>=58&&buffer<=63)||(buffer==93)||(buffer>=124&&buffer<=125)||buffer=='\n')
{ if(buffer=='\n')line++;
w[++len].typenum=34;
strcpy(w[len].word,ch);
strcpy(w[len].type,"常量");
fprintf(fp1,"(%s,34)\n",ch);
return(buffer);
}
else if(buffer=='.')
{
ch[1]=buffer;
buffer=fgetc(fp);
i=2;
while(isdigit(buffer))
{
ch[i]=buffer;
i++;
buffer=fgetc(fp);
}
ch[i]='\0';
w[++len].typenum=35;
strcpy(w[len].word,ch);
strcpy(w[len].type,"常量");
fprintf(fp1,"(%s,35)\n",ch);
return(buffer);
}
else
{
ch[1]=buffer;i=2;buffer=fgetc(fp);
}
}
else
{
buffer=fgetc(fp);
i=1;
}
while(isdigit(buffer)||buffer=='.')
{
if(buffer=='.')count1++;
ch[i]=buffer;
i++;
buffer=fgetc(fp);
}
ch[i]='\0';
if(count1>1)
{
fprintf(fp0,"%d:%s:[Error] too many decimal points in number\n",line,ch);
error++;return(buffer);
}
if(buffer=='e')
{
ch[i]=buffer;
i++;
ch[i]='\0';
buffer=fgetc(fp);
if(buffer=='+'||buffer=='-')
{
ch[i]=buffer;
i++;
ch[i]='\0';
buffer=fgetc(fp);
if(isdigit(buffer))
{
while(isdigit(buffer))
{
ch[i]=buffer;i++;
buffer=fgetc(fp);
}
ch[i]='\0';
w[++len].typenum=67;
strcpy(w[len].word,ch);
strcpy(w[len].type,"常量");
fprintf(fp1,"(%s,67)\n",ch);
id=3;
}
else
{
fprintf(fp0,"%d:%s%c:[Error]\n",line,ch,buffer);
error++;
}
}
else if(isdigit(buffer))
{
while(isdigit(buffer))
{
ch[i]=buffer;i++;
ch[i]='\0';
buffer=fgetc(fp);
}
id=3;
w[++len].typenum=67;
strcpy(w[len].word,ch);
strcpy(w[len].type,"常量");
fprintf(fp1,"(%s,67)\n",ch);
}
else
{
fprintf(fp0,"%d:%s:[Error] invalid suffix '%c' on integer constant\n",line,ch,ch[i-1]);
error++;
buffer=fgetc(fp);
}
}
else if(isalpha(buffer)||buffer=='_')
{
ch[i]=buffer;
buffer=fgetc(fp);
i++;
while(isalpha(buffer)||isdigit(buffer)||buffer=='_')
{
ch[i]=buffer;
i++;
buffer=fgetc(fp);
}
ch[i]='\0';
strncpy(str,ch+1,i);
error++;
fprintf(fp0,"%d:%s:[Error]invalid suffix '%s' on integer constant\n",line,ch,str);
return(fgetc(fp));
}
else if(ch[0]!='0'&&((buffer>=32&&buffer<=34)||(buffer>=37&&buffer<=45)||(buffer==47)||(buffer>=58&&buffer<=63)||(buffer==93)||(buffer>=124&&buffer<=125)||buffer=='\n'))
{ if(buffer=='\n')line++;
id=3;
if(count1==1)
{
w[++len].typenum=35;
strcpy(w[len].word,ch);
strcpy(w[len].type,"常量");
fprintf(fp1,"(%s,35)\n",ch);
}
else
{
w[++len].typenum=34;
strcpy(w[len].word,ch);
strcpy(w[len].type,"常量");
fprintf(fp1,"(%s,34)\n",ch);
}
}
else if((buffer>='a'&&buffer<='z')||(buffer>='A'&&buffer<='Z')||buffer=='_')
{
fprintf(fp0,"%d:%s%c:[Error] invalid suffix '%c' on integer constant\n",line,ch,buffer,buffer);
error++;
buffer=fgetc(fp);
}
else if(ch[0]=='0'||count1==0)
{
tag=digit3(ch);
if(tag==1)
{
w[++len].typenum=69;
strcpy(w[len].word,ch);
strcpy(w[len].type,"常量");
fprintf(fp1,"(%s,69)\n",ch);
}
else
{error++;fprintf(fp0,"%d:%s:[Error]八进制格式错误\n",line,ch);}
}
else
{
fprintf(fp0,"%d:%s%c:[Error] invalid suffix '%c' on integer constant\n",line,ch,buffer,buffer);
error++;
}
return buffer;
}语法分析
对给定的一个上下无关文法,分析任意一个源码的语法结构。采用的是递归下降语法分析。
【递归下降分析思想】:自顶向下分析就是从文法的开始符触发并寻找出这样一个推导序列:推导出的句子恰好为输入符号串;或者说,能否从根节点出发向下生长出一颗语法树,其叶节点组成的句子恰好为输入符号串。显然,语法树的每一步生长(每一步推导)都以能否与输入符号串匹配为准,如果最终句子得到识别,则证明输入符号串为该文发的一个句子;否则,输入符号串不是该文法的句子。
递归下降分析法是一种自顶向下的分析方法,文法的每个非终结符对应一个递归过程(函数)。分析过程就是从文法开始符触发执行一组递归过程(函数),这样向下推到直到推出句子;或者说从根节点出发,自顶向下为输入串寻找一个最左匹配序列,建立一颗语法树。
【程序框架】:
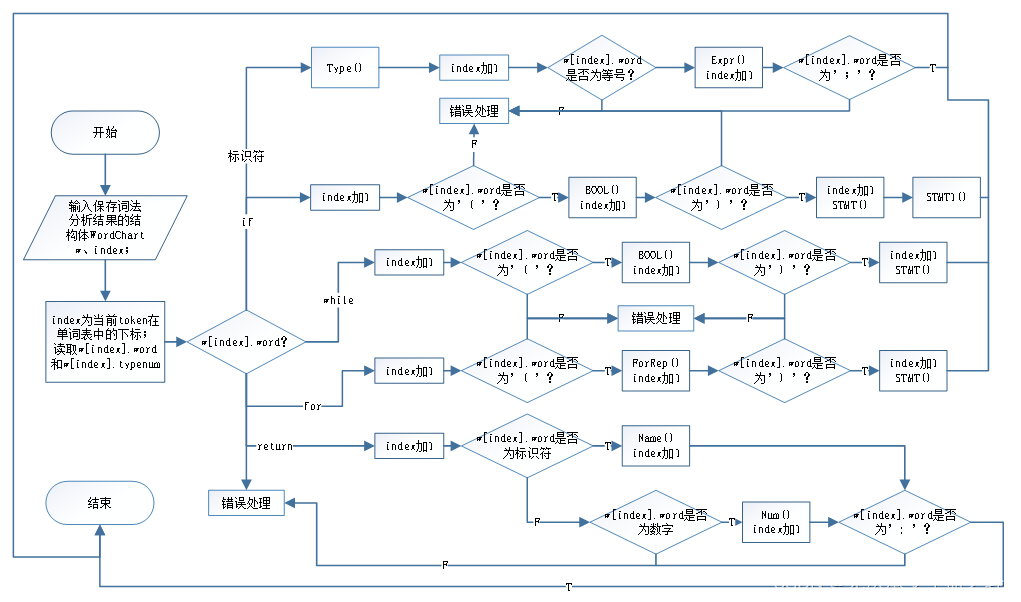
【输入】:存储在结构体WordChart中的词法分析结果。
【输出】:整个源码的语法分析过程。
【自定义文法】:
可分析的执行语句为主函数、定义变量、if-else、while循环、for循环、return、赋值语句、算式表达式、关系表达式、布尔表达式。
<Prog> →<Main>
<Main> → <Type1> main ( ) <Block>
<Block> → { <Decls> <STMTS> }
<Decls> → <Type> <NameList> ; <Decls> | empty
<NameList> → <Name> <NameList1>
<NameList1> → , <Name> <NameList1> | empty
<Type1> → int |void
<Type> → int |char|float|string|double|bool
<Name> → 标识符
<STMTS> → <STMT> <STMTS> | empty
<STMT> → <Name> = <Expr> ;
<STMT> → if ( <BOOL> ) <STMT> <STMT1>
<STMT1> → else <STMT> | empty
<STMT> → while ( <BOOL> ) <STMT>
<STMT> → <Block>
<STMT> → return 数字;|return <Name>;
<STMT> →for (<ForRep>)<STMT>
<ForRep>→<Rep>;<Rep2>;<Rep1>
<Rep>→<Name>=<Expr>|empty
<Rep1>→<Name><RepOp2>|empty
<Rep2>→<BOOL>|empty
<RelOp2> → ++ | - -
<BOOL> → <BOOL1> <BOOL2>
<BOOL1> → <Expr> <RelOp> <Expr>
<BOOL2> → <RelOp1> <BOOL1>|empty
<RelOp> → < | <= | > | >= | == | !=
<RelOp1> → || | &&
<Expr> → <Term> <Expr1>
<Expr1> → <AddOp> <Term> <Expr1> | empty
<Term> → <Factor> <Term1>
<Term1> → <MulOp> <Factor> <Term1> | empty
<Factor> → id | number | ( <Expr> )
<AddOp> → + | -
<MulOp> → * | / | %【函数】:
表1 为所有非终结符函数:
| 函数定义、执行语句框架(‘{}’) |
变量定义 |
操作语句 |
比尔表达式、关系表达式 |
算式表达式 |
| Int Prog(); |
Int Decls(); |
Int STMTS(); |
Int BOOL(); |
Int Expr(); |
| Int Main(); |
Int NameList(); |
Int STMT(); |
Int BOOL1(); |
Int Expr1(); |
| Int Block(); |
Int NameList1(); |
Int STMT1(); |
Int BOOL2() |
Int Term(); |
| bool Type1(); |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6509
6509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









