







首先呢,我们来看看什么是Speech Separation问题。
 人们可以在一个嘈杂的环境中识别出一个特定声音的来源,这个叫做鸡尾酒会效应。
人们可以在一个嘈杂的环境中识别出一个特定声音的来源,这个叫做鸡尾酒会效应。
 这种应用到机器学习领域,我们要做的就是语音增强:语音-非语音分离(降噪)。
这种应用到机器学习领域,我们要做的就是语音增强:语音-非语音分离(降噪)。
 而Speech Separation就是做不同种类声音的分离的识别工作。
而Speech Separation就是做不同种类声音的分离的识别工作。
 那么我们首先规定一下,本文主要讨论两种声音,单一麦克风以及独立的演讲者(即培训和测试演讲者完全不同)的识别工作,在我们收集数据时,我们可以收集两端时间相同的声音讯号,然后就同时播放形成一段新的声音讯号就可以了。
那么我们首先规定一下,本文主要讨论两种声音,单一麦克风以及独立的演讲者(即培训和测试演讲者完全不同)的识别工作,在我们收集数据时,我们可以收集两端时间相同的声音讯号,然后就同时播放形成一段新的声音讯号就可以了。
 首先我们先来思考一个问题,我们怎样来评估一个系统是否可以满足我们的需求呢?
首先我们先来思考一个问题,我们怎样来评估一个系统是否可以满足我们的需求呢?
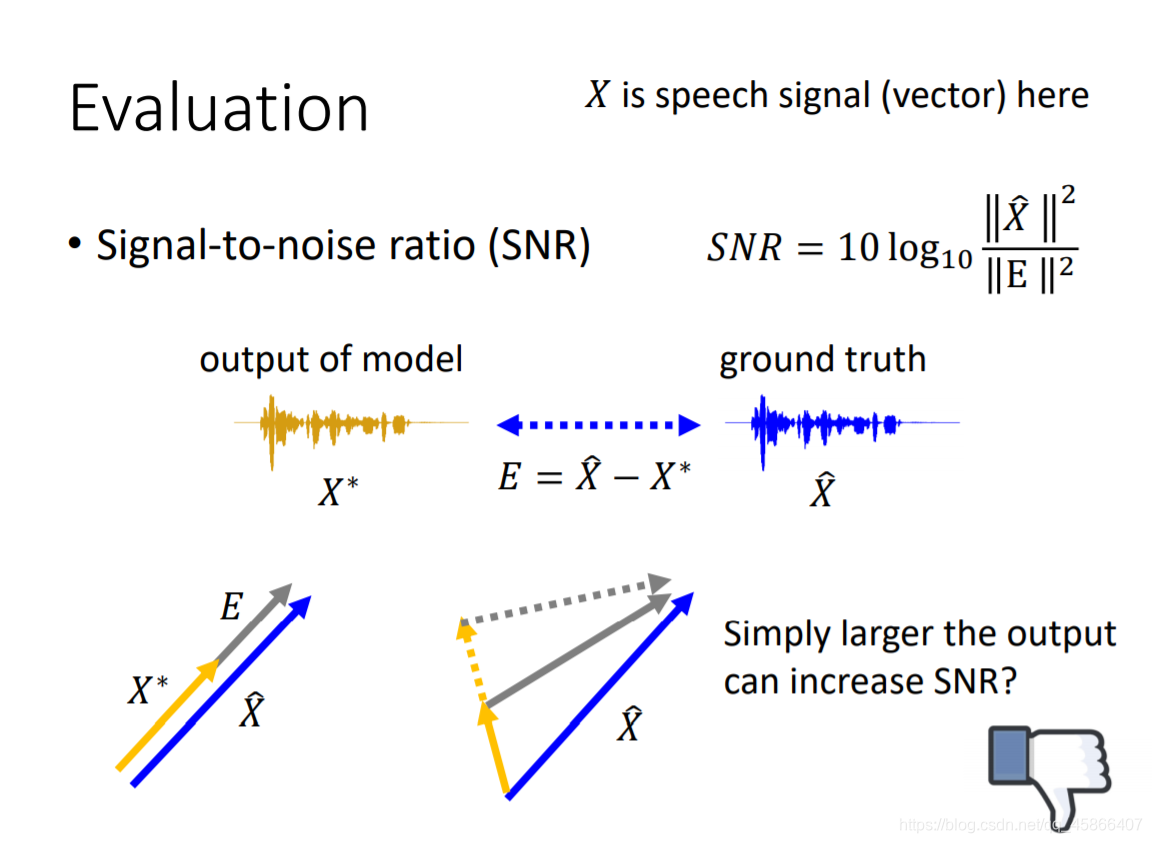 如上图所示,我们如果使用SNR的技术来评估我们的系统的话,会有一个致命的问题,我们的X*只要越大,那么我们的评估结果就会更高,这肯定不是我们想要的,所以我们有以下的改进措施。
如上图所示,我们如果使用SNR的技术来评估我们的系统的话,会有一个致命的问题,我们的X*只要越大,那么我们的评估结果就会更高,这肯定不是我们想要的,所以我们有以下的改进措施。
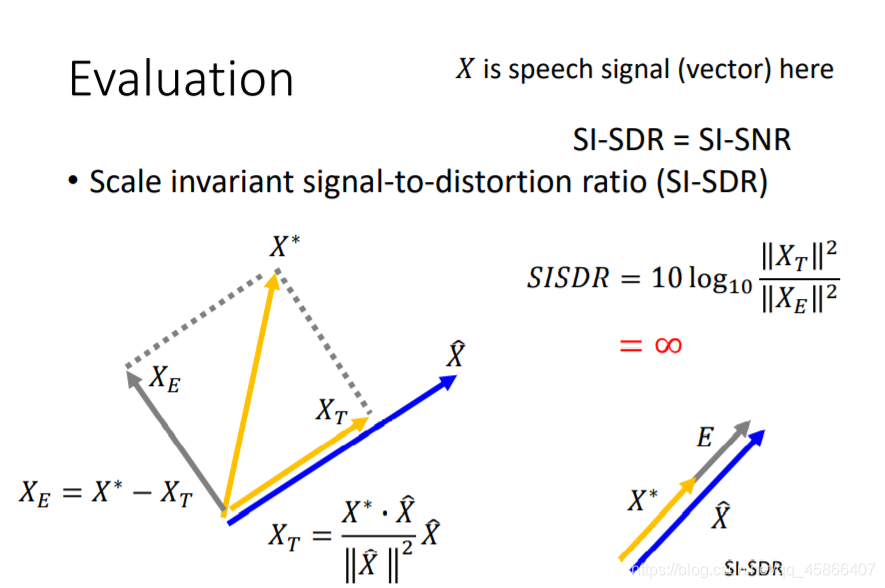 上面这种方法是SI-SDR,我们可以发现,其实相当于将X分解成了两个相互垂直的方向,这样的话,就算X的总长度变大,两个方向会同等比例的放大,而我们计算的是二者的范数之比,其实就对于我们的结果没有影响了。那么接下来呢,我们来讲讲具体怎么实现这个评估的过程。
上面这种方法是SI-SDR,我们可以发现,其实相当于将X分解成了两个相互垂直的方向,这样的话,就算X的总长度变大,两个方向会同等比例的放大,而我们计算的是二者的范数之比,其实就对于我们的结果没有影响了。那么接下来呢,我们来讲讲具体怎么实现这个评估的过程。
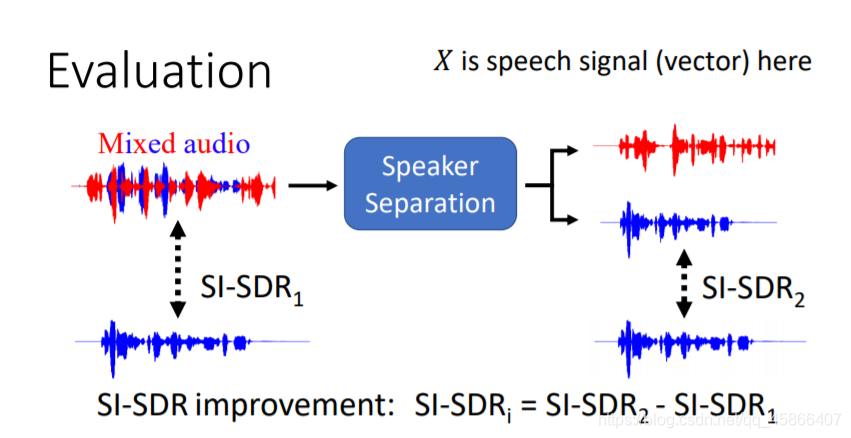 我们可以看看,先对原始数据进行SI-SDR1,接着经过Speaker Separation之后,我们对结果进行SI-SDR2,接着对两次的结果进行修正。并且我们要注意,尽量不要让我们的模型结果受到性别,腔调等这些因素的影响。
我们可以看看,先对原始数据进行SI-SDR1,接着经过Speaker Separation之后,我们对结果进行SI-SDR2,接着对两次的结果进行修正。并且我们要注意,尽量不要让我们的模型结果受到性别,腔调等这些因素的影响。
接下来,我们介绍一种解决Speech Separation的方法— Deep Clustering。
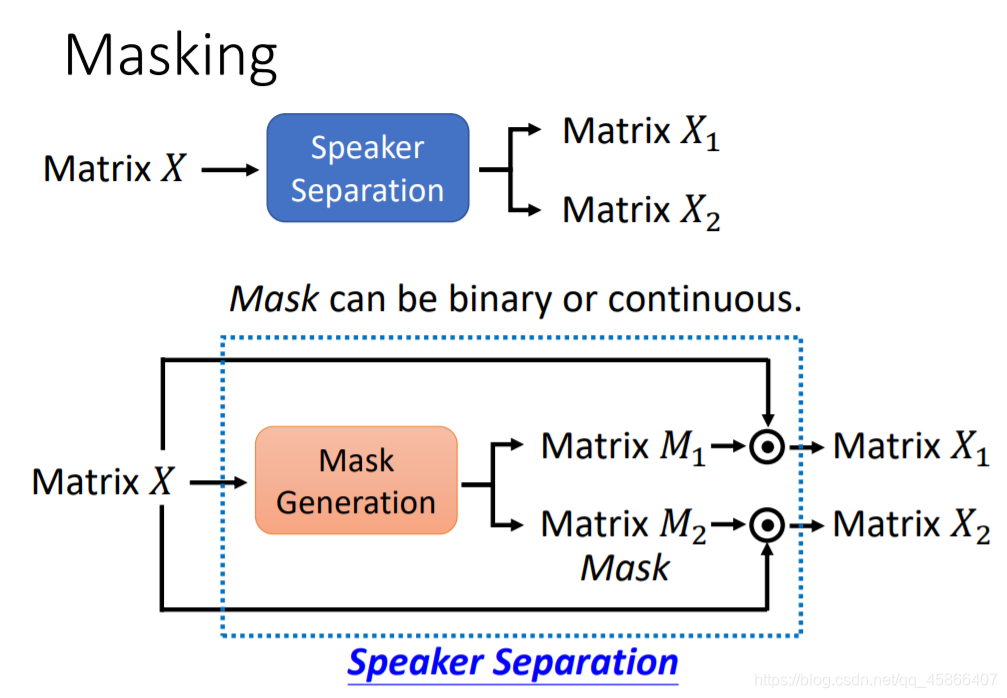 我们可以来看看这种方法,就相当于将我们输入的声音讯号用一个矩阵来表述,然后通过我们的模型,将其再分离成两个矩阵。接下来我们可以具体来看看。
我们可以来看看这种方法,就相当于将我们输入的声音讯号用一个矩阵来表述,然后通过我们的模型,将其再分离成两个矩阵。接下来我们可以具体来看看。
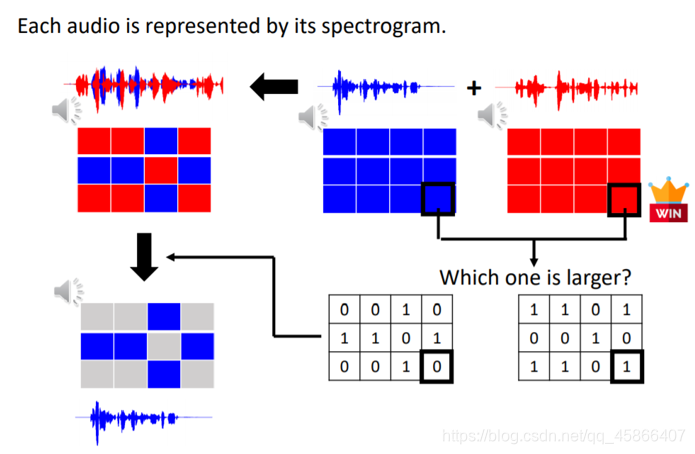
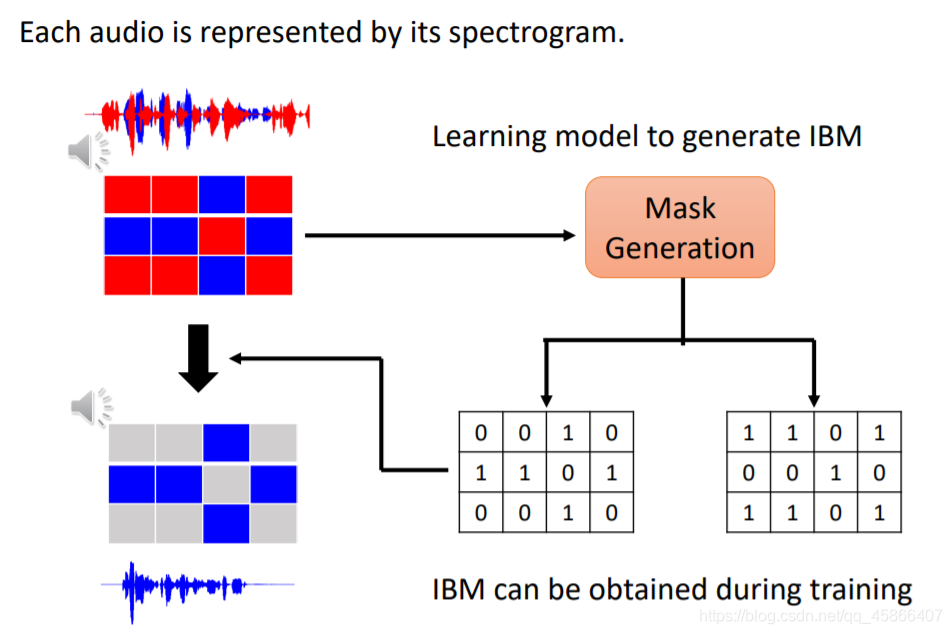 我们可以看看,就是如果是一个二划分,那么我们就可以依靠0,1来划分两个声音讯号,如果相似就记为1,反之记为0.那么我们可不可以尝试用一个三维向量来表征一个声音讯号呢?
我们可以看看,就是如果是一个二划分,那么我们就可以依靠0,1来划分两个声音讯号,如果相似就记为1,反之记为0.那么我们可不可以尝试用一个三维向量来表征一个声音讯号呢?
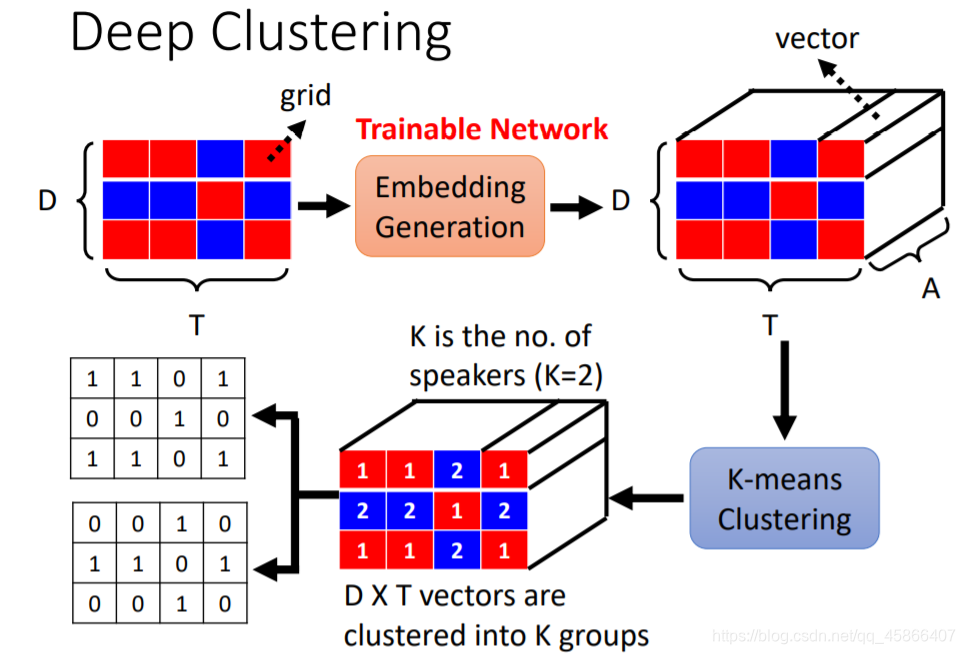
 如上面几张图所示,我们可以根据一个格子及其周围的几个格子来形成一个三维向量,然后我们可以根据不同元素之间是Different Clusters还是Same Clusters就可以对结果进行划分。
如上面几张图所示,我们可以根据一个格子及其周围的几个格子来形成一个三维向量,然后我们可以根据不同元素之间是Different Clusters还是Same Clusters就可以对结果进行划分。
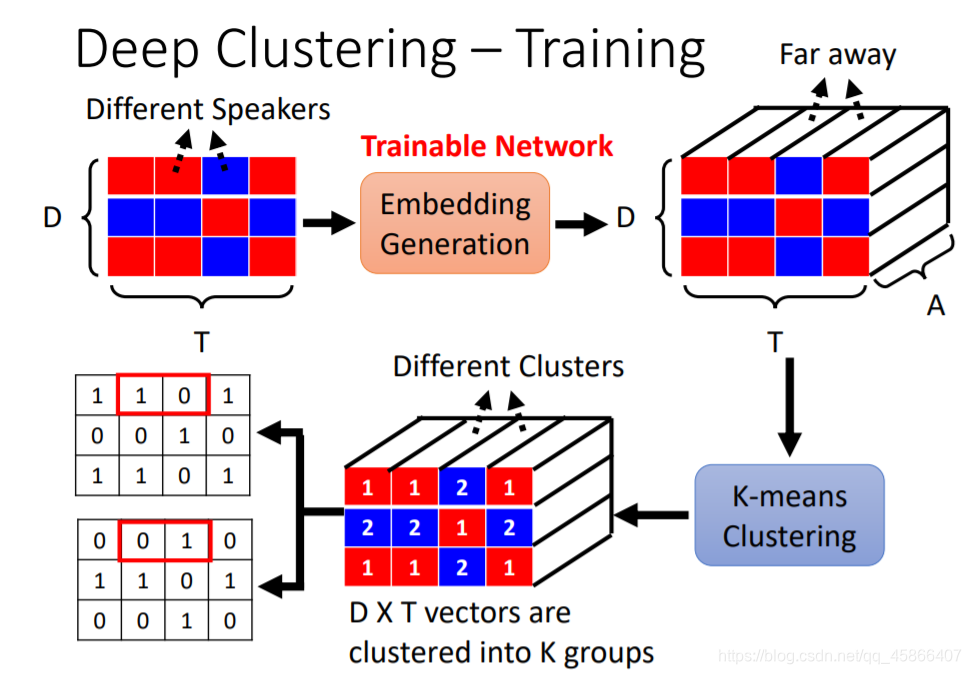
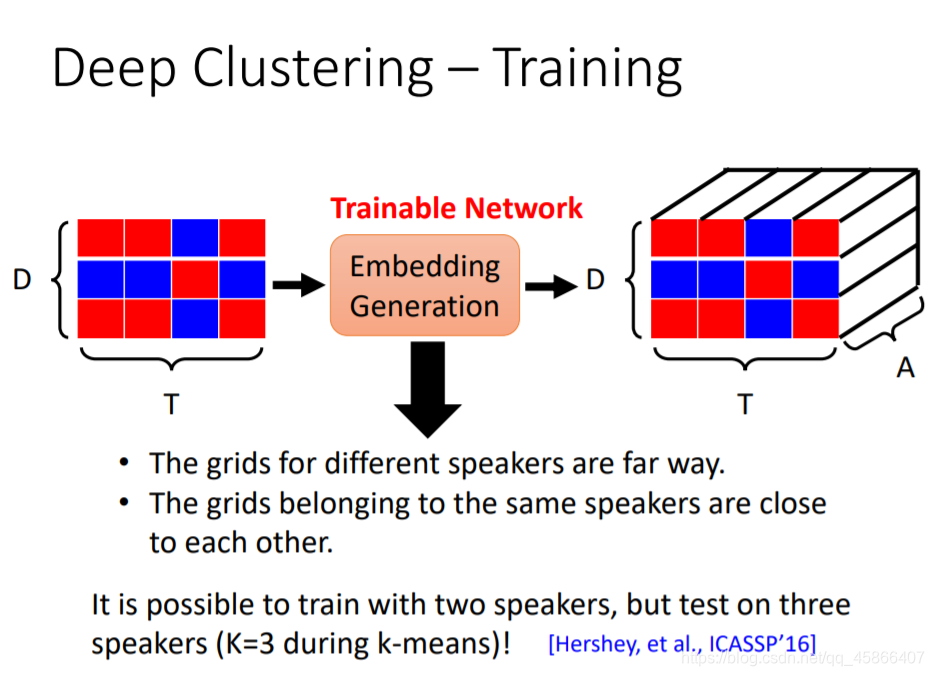 我们可以看到这种方法就可以使Same Clusters更加的接近,而使Different Clusters之间更加的远离,然后再将二者分离,便可以达到我们的预期了。
我们可以看到这种方法就可以使Same Clusters更加的接近,而使Different Clusters之间更加的远离,然后再将二者分离,便可以达到我们的预期了。
接下来,我们再来介绍Permutation Invariant Training 技术,也就是PIT。
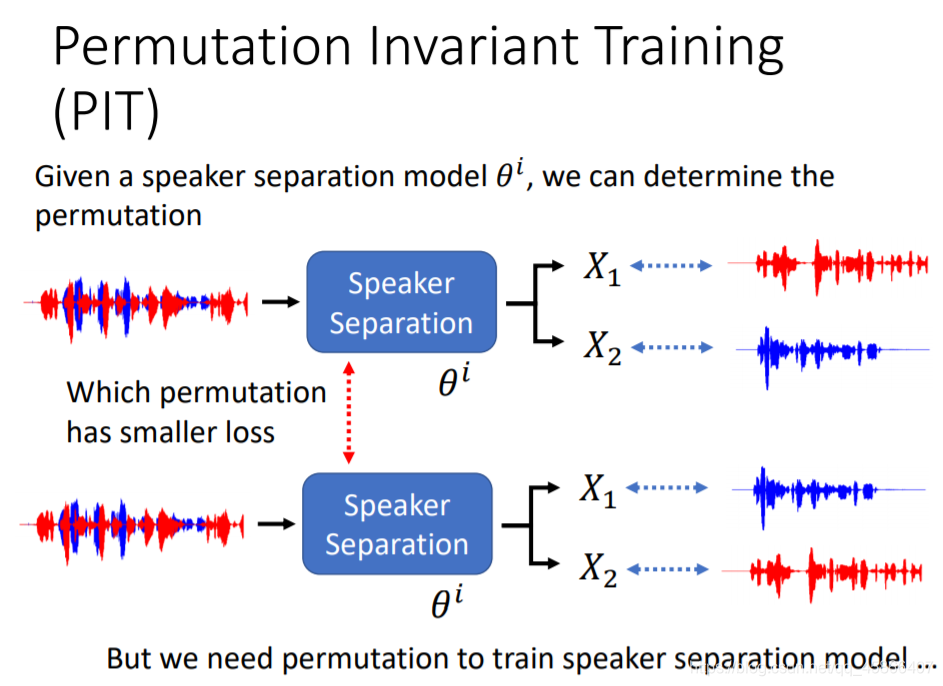 PIT呢,就是给定了一个说话者的分离模型,然后我们就可以进行分离效果,就相当于我们有一个Ө模型,然后我们分别尝试将X1,X2放在第一个输出的情况,分别计算Ө的loss损失,然后就可以判断好坏了。
PIT呢,就是给定了一个说话者的分离模型,然后我们就可以进行分离效果,就相当于我们有一个Ө模型,然后我们分别尝试将X1,X2放在第一个输出的情况,分别计算Ө的loss损失,然后就可以判断好坏了。
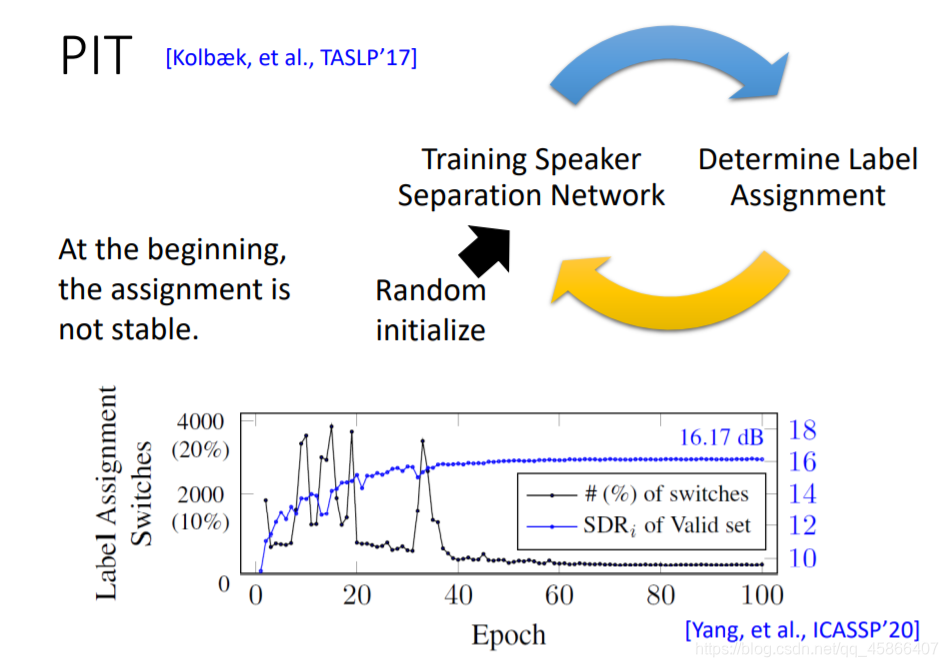 首先我们初始化数据,所以在最开始其实效果并不是很好,但是当数据量很大的时候,我们就会发现PIT技术是很有效果的。
首先我们初始化数据,所以在最开始其实效果并不是很好,但是当数据量很大的时候,我们就会发现PIT技术是很有效果的。
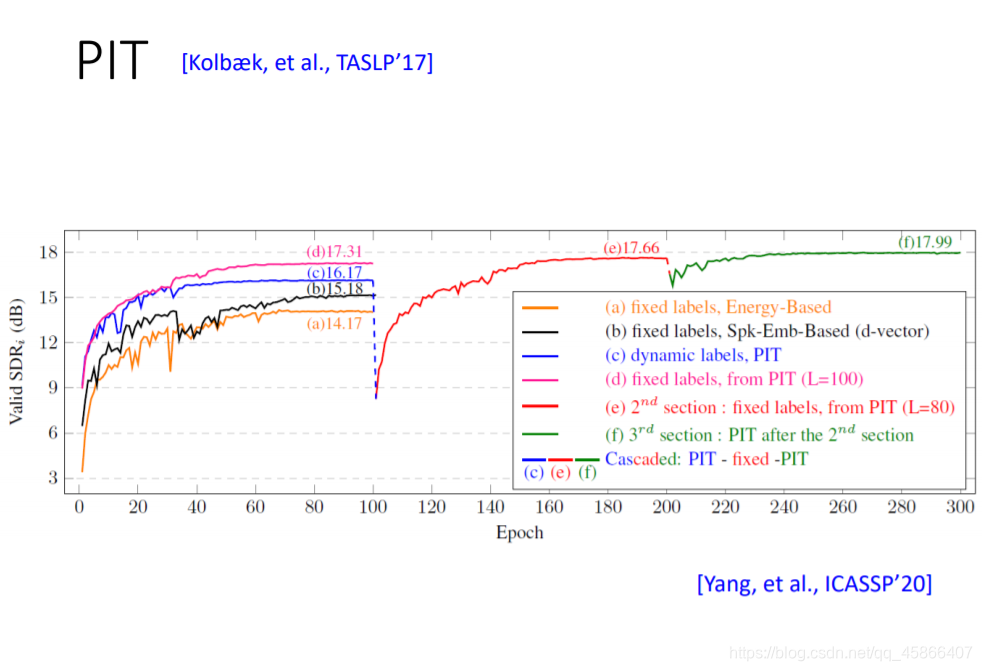 上图我们也可看出PIT技术对于准确度的提升其实也是很明显的。
上图我们也可看出PIT技术对于准确度的提升其实也是很明显的。

















12-10
 3043
3043
3043
05-24
3051
3051
10-14
3628
3628
06-22
6997
6997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









