




假如现在我们有一个需求是根据用户的id来查询用户的详细信息。
Controller 实现代码如下:
Service层的实现类代码如下: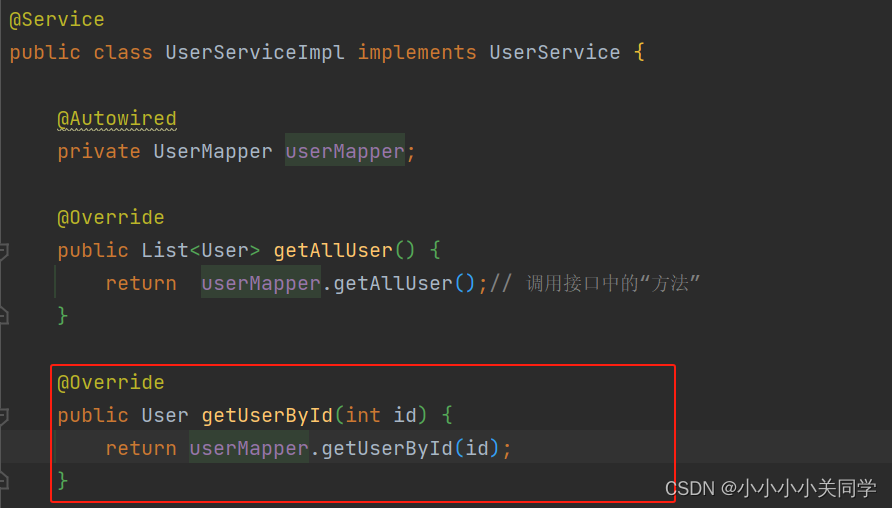
mapper层接口和XML文件如下: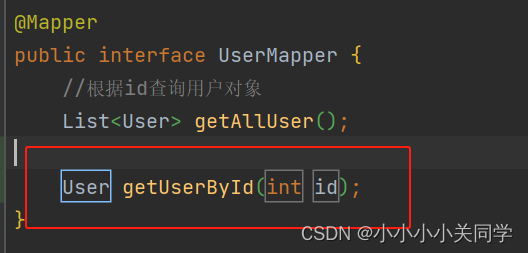

代码中使用到的#{}实际上就是对SQL语句进行预编译处理,会将#{}替换为?号,使用PreparedStatement的set方法来赋值。select * from userinfo where id=#{id} 也可以用select * from userinfo where id=${id}来代替,他们都可以完成现在的需求。
问题来了既然他们这么相似、那为什么还要有这两个东西??两者之间肯定是有区别的。
主要区别
先直接将他们之间的核心区别,然后通过例子演示。
1. #{} 解析为一个 JDBC 预编译语句(prepared statement)的参数标记符,一个 #{ } 被解析为一个参数占位符(?);而${}仅仅为一个纯碎的字符替换,是MyBatis 在处理 ${} 时,就是把 ${} 替换成变量的值。
2. #{} 很大程度上可以防止SQL注入(SQL注入是发生在编译的过程中,因为恶意注入了某些特殊字符,最后被编译成了恶意的执行操作);而${} 主要用于SQL拼接的时候,有很大的SQL注入隐患。
3.在某些特殊场合下只能用${},不能用#{}。例如:在使用排序时ORDER BY ${id},如果使用#{id},则会被解析成ORDER BY “id”,这显然是一种错误的写法。这也对应了第二点的说法,排序功能, 表名, 字段名作为参数时, 这些情况需要使⽤${}
4.模糊查询虽然${}可以完成, 但因为存在SQL注⼊的问题,所以通常使⽤mysql内置函数concat来完成
1.1 SQL注入
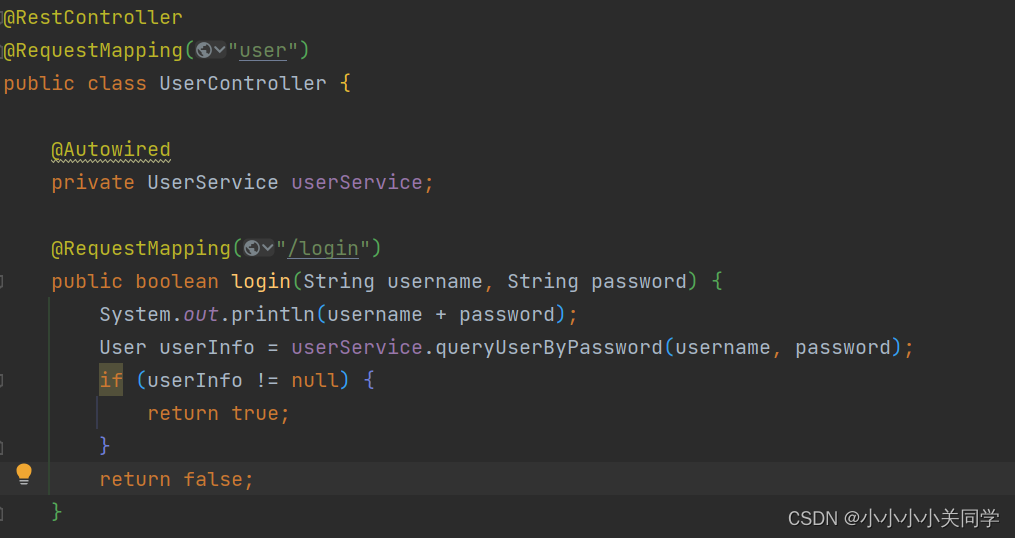
控制层:
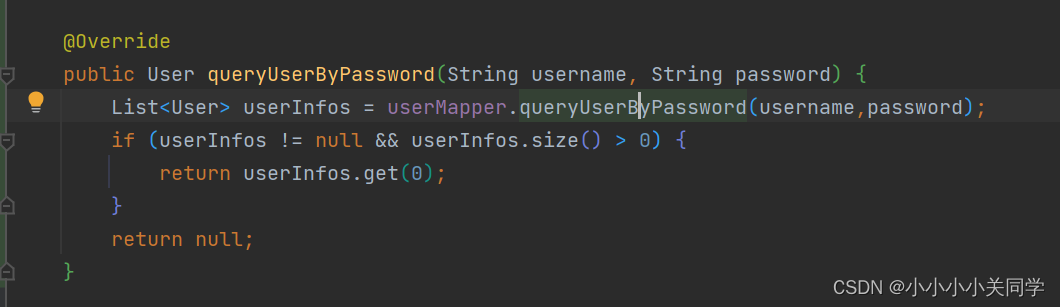
服务层:
DAO层:( 使用${ } )
List<User> queryUserByPassword(@Param("username") String username, @Param("password") String password);
}

数据库现有数据:

知道账号密码 登录 张三账号:
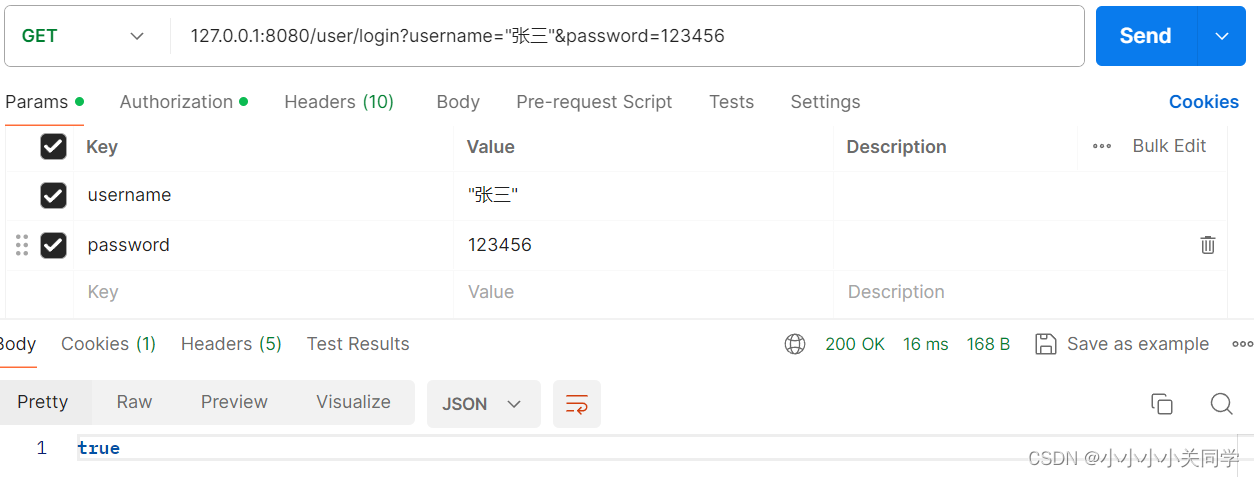
现在我们即使不输正确的密码也可以登录!!!!下图中可以看到,后端返回的结果是true!
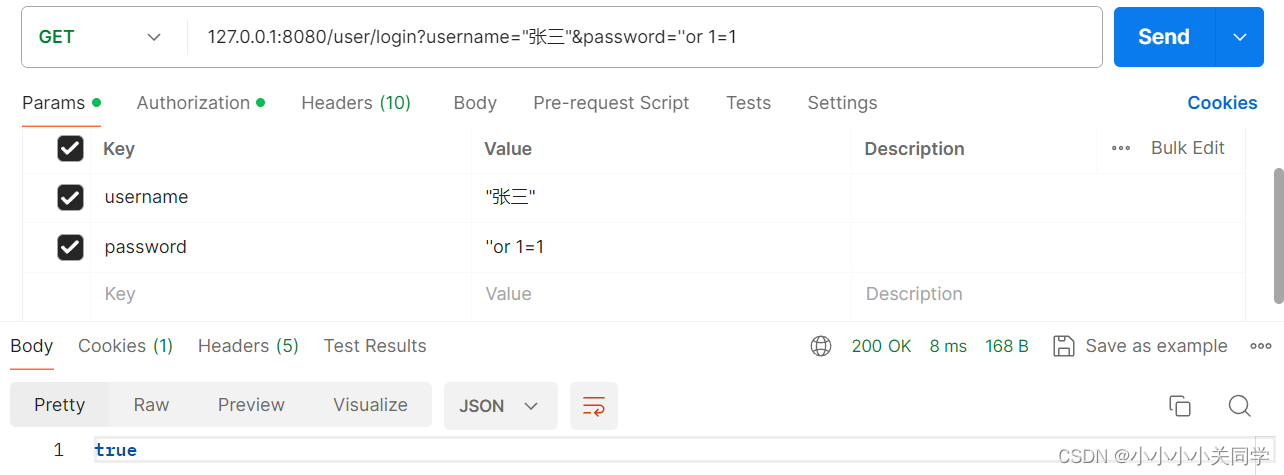
这是因为,通过拼接后最终执行的代码是: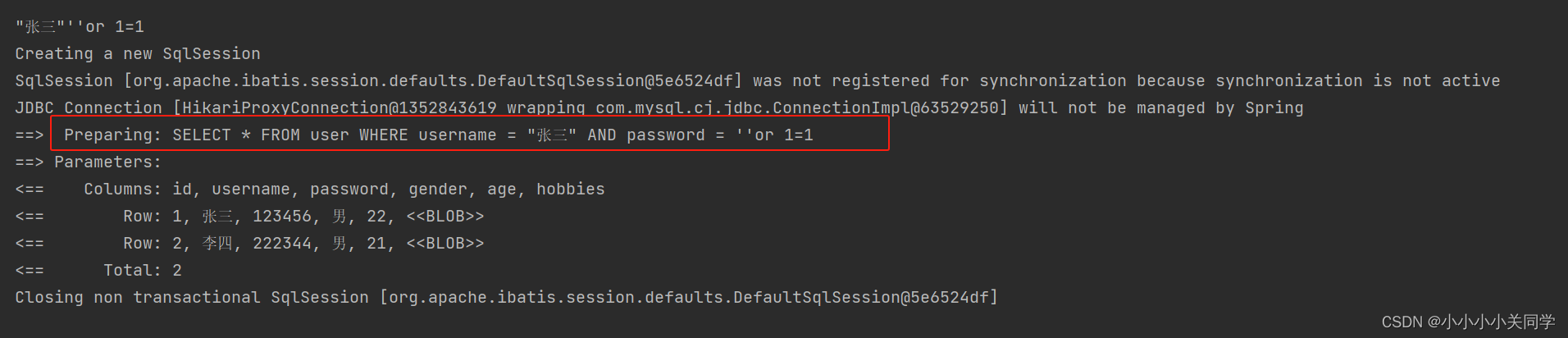
如果我们使用#{}:

再看一下执行结果:此时后端返回的就是false,这就是他们的第一个和第二个区别的展示。

1.2 排序功能
ORDER BY 关键字按照一个或多个列的值对结果集进行升序(ASC)或降序(DESC)排列。我们在传入的EDSC是字符串啊!

这时候就需要使用${}:
1.3 模糊查询
比如我们对用户信息进行查询,并且要求实现模糊查询功能。由于我们使用模糊查询的时候需要使用到'%#{username}%这也是字符串啊!!如果我们使用#{}的话:
<select id="findUserByName2" resultType="com.example.demo.entity.User">
select * from userinfo where username like '%#{username}%';
</select>
<select id="likeSelect" resultType="com.example.demo.entity.User">
select * from userinfo where username like '%${username}%'
</select>
但是,一般还是推荐使用下面的方式来实现模糊查询:使⽤ mysql 的内置函数 concat() + #{}来处理,实现代码如下:
<select id="findUserByName3" resultType="com.example.demo.entity.User">
select * from userinfo where username like concat('%',#{username},'%');
</select>
contat将传入的参数和%拼接在一起,这样就是一个nice的sql语句了。这种方式可以有效地防止SQL注入,也是推荐使用的方式。
总结
1. #{} 解析为一个 JDBC 预编译语句(prepared statement)的参数标记符,一个 #{ } 被解析为一个参数占位符(?);而${}仅仅为一个纯碎的字符替换,是MyBatis 在处理 ${} 时,就是把 ${} 替换成变量的值。
2. #{} 很大程度上可以防止SQL注入(SQL注入是发生在编译的过程中,因为恶意注入了某些特殊字符,最后被编译成了恶意的执行操作);而${} 主要用于SQL拼接的时候,有很大的SQL注入隐患。
3.在某些特殊场合下只能用${},不能用#{}。例如:在使用排序时ORDER BY ${id},如果使用#{id},则会被解析成ORDER BY “id”,这显然是一种错误的写法。这也对应了第二点的说法,排序功能, 表名, 字段名作为参数时, 这些情况需要使⽤${}
4.模糊查询虽然${}可以完成, 但因为存在SQL注⼊的问题,所以通常使⽤mysql内置函数concat来完成



















 948
948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











