






本篇博客参考了以下几篇文章和视频:
参考1 参考2 武大MOOC
初学数据结构,第一次遇到了一根难啃的骨头——串的模式匹配算法(KMP),虽然网上关于KMP算法的介绍很多,但多半叙述不全面,推导不流畅。因此自己写了这篇博客,尽可能以因果关系呈现KMP算法。
本篇博客尽量以最通俗,详尽的语言解释KMP算法,全文干货,无废话。
KMP是用来干嘛的?
简而言之,KMP算法较好的解决了串的模式匹配问题,即判断模式串(t)是否是目标串(s)的子串,注意子串包含目标串本身,也包含空串。例如aaab是aaabaab的子串,abc是abc的子串。
为什么非要用KMP?
简而言之,因为KMP算法具有很好的效率。一般来讲模式匹配算法有两种即Brute-Force(BF)暴力算法与KMP算法。
那为什么不用BF算法?
简而言之,因为BF算法非常的低效。BF算法采用穷举思想,这也是绝大多数人解决模式匹配问题最先想到的算法。
本文皆用下面的模式串(t)和目标串(s) 举例
s = “abaabaabbabaaabaabbabaab”
t = "abaabbabaab"
蓝色表示匹配成功,红色表示匹配失败。
BF算法最大的问题就在于每当匹配失败时,模式串都要后移一位,然后再从模式串的头部重新与目标串匹配(术语:回溯)。比如下图的step.1-5,step.10-19匹配都没有问题,但在step.6和step.20出现了匹配失败,导致的结果就是模式串后移一位,从头再来。这实质上是一种很无脑、很浪费、很低效的一种算法。
为什么说它浪费?因为它忽视了一些关键信息。
拿step.6来说,匹配失败,在step.7模式串后退一位,其结果必然也是失败的,因为在step1-6的过程中算法已经遍历过s[1]了,s[1]=b而不是a,紧接着在step.9匹配也失败了,其结果其实必然也是失败的,因为在step1-6的过程中算法已经遍历过s[3]了,s[3]=a而不等于t[1]即b。
简单的来说,在step.6匹配失败后,模式串t是可以直接移位到step.10的位置的!因为在step.1-6就已经验证了,模式串的头部a在aba(目标串前3位)里是不可能匹配成功的,直接跳过就行,这就是关键信息。
同理step.20匹配失败后,模式串的头部可以直接移位到abaabaabb a baaabaabbabaabb,加粗斜体的a的位置。

这里就不贴上BF算法的代码了。
BF算法分析
1.算法在字符比较不相等,需要回溯即i = i - j + 1:即回退到s中的下一个字符开始进行字符匹配。
2.最好情况下的时间复杂度为O(m+n)
3.最坏情况下的时间复杂度为O(m*n)
m,n分别为串t,s的长度。

一些概念及定义
前缀的概念:指的是字符串的子串中从原串最前面开始的子串,如abcdef的前缀有:a,ab,abc,abcd,abcde
后缀的概念:指的是字符串的子串中在原串结尾处结尾的子串,如abcdef的后缀有:f,ef,def,cdef,bcdef
注意前缀与后缀不包括原串本身。
最大公约缀的概念:这个概念是我自己起的…对应最大公约数,也就是某个串,既在前缀中又在后缀中,并且它是最长的。
规律?
以上的关键信息及模式串的移位由分析得出,那么怎么不分析,直接得出下次移位的下标位置呢
先观察规律。

紫框是模式串与目标串在step.1-6里确定的最长的匹配串段abaab,很容易可以看出,abaab的最大公约缀是ab,上文分析得到:模式串t是可以直接移位到step.10的位置的!因为在step.1-6就已经验证了,模式串的头部a在aba(目标串前3位)里是不可能匹配成功的,直接跳过就行,这就是关键信息。 有意思的是,step.10中,模式串头部a所在位置刚好就是目标串最长匹配串段abaab(加粗) 中a的位置,后缀的第一个字母a!
再看黄框,abaabbabaa是模式串与目标串在step10-20所确定的最长匹配串段,上文分析得到:模式串的头部可以直接移位到abaabaabb a baaabaabbabaab,加粗斜体的a的位置。abaabbabaa的最大公约缀是abaa,而abaabaabb a baaabaabbabaab 这个a的位置刚好就是step.19配对时最长匹配串段的后缀的第一个字母a。

!!!同时注意到跳转之后,模式串和目标串必定会有部分元素相同(即最大公约缀),因此在KMP算法中,跳转之后,直接从最大公约缀后一位开始比较,即棕色箭头。!!!
既然理解了如何跳到下次匹配位置,我们的KMP算法就应运而生了。
即根据不同长度的最长匹配字段->算出最大公约缀->若匹配失败,根据最大公约缀直接跳转到后缀处的第一个字母!
这样就避免了BF算法回溯带来的低效与浪费。
KMP实战
怎么求最大公约缀?
事实上,跳转是依靠数组下标完成的,因此我们需要知道不同长度最大匹配串段的最大公约缀的长度(量化)。一般的,我们用next数组来存储这个长度。
仍然用这个例子。
s = "abaabaabbabaaabaabbabaab"每个元素用s[i]表示
t = "abaabbabaab"每个元素用t[j]表示
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| t[j] | a | b | a | a | b | b | a | b | a | a | b |
| next[j] | -1 | 0 | 0 | 1 | 1 | 2 | 0 | 1 | 2 | 3 | 4 |
| 最大公约缀 | 无 | 无 | 无 | a | a | ab | 无 | a | ab | aba | abaa |
几个注意点:
1.长度大于2的模式串,next[0]=-1,next[1]=0
2.next[j]=-1说明模式串t[j]之前没有任何用于加速匹配的信息,下一趟应从t的开头j++(j=0)开始匹配
3.t[j]前的最大匹配串段在计算最大公约缀的时候,不包括t[j]本身
这样,我们就得到了next数组。
怎么理解next数组?
主要是理解这句话:next[j]=k说明模式串t[j]之前有k个字符已成功匹配,下一趟应从t[k]开始匹配。
在step.6时,发生了匹配失败,此时i = j = 5,查上表,next[5] = 2,说明模式串t[5]之前有2个字符已经成功匹配,下一趟应从t[5]开始匹配。
嗯哼,这不就是上文 !!!同时注意到跳转之后,模式串和目标串必定会有部分元素相同(即最大公约缀),因此在KMP算法中,跳转之后,直接从最大公约缀后一位开始比较,即棕色箭头。!!! 的意思吗。
!!!具体分析一下下图,i = j = 4时,即棕色箭头,匹配成功。i = j = 5时,即紫色箭头,匹配失败,查表,next[5] = 2,那么j跳转到j = 2,继续比较(此时i = 3,i = 4与j = 0,j = 1必然是匹配的)。
同理,i = j = 10时,即淡紫色箭头,匹配失败,查表,next[10] = 4,那么j跳转到j = 4,继续比较(此时i = 6.7,8,9必然与j = 0,1,2,3匹配)。!!!

至此,把以上的过程全部连贯起来,就得到下面这个动图。图源侵删
是不是感觉豁然开朗呢,如果还不懂KMP,请逐字逐句,思考着再看几遍。如果看完仍然不懂,请来砍我。
KMP算法实现
一些基本定义
#include <iostream>
using namespace std;
#define MAXSIZE 100
typedef struct
{
char data[MAXSIZE];
int length;//字符串长度
}SqString;
求next数组算法实现
//求模式串t的next值的算法
void GetNext(SqString t, int next[])
{
int j = 0, k = -1;
next[0] = -1;
while (j < t.length - 1)
{
if (k == -1 || t.data[j] == t.data[k])
{
j++;
k++;
next[j] = k;
}
else
{
k = next[k];//这是非常神奇的一句
}
}
}
建议用笔走一下上面的代码,手动求下next。
KMP算法实现
//KMP
int KMPIndex(SqString t, SqString s)
{
int next[MAXSIZE], i = 0, j = 0;
GetNext(t, next);
while (i < s.length && j < t.length)
{
if (j == -1 || s.data[i] == t.data[j])
{
i++;
j++;
}
else
{
j = next[j];//i不变,j后退
}
}
if (j >= t.length)
{
return i - t.length;//返回匹配模式串的首字符下标
}
else
{
return -1;//返回不匹配
}
}
同上建议手动走一下。
这两段代码很值得咀嚼。
KMP算法分析
1.在KMP算法中求next数组的时间复杂度为O(m),在后面的匹配中因主串s的下标不减即不回溯,比较次数可记为n,所以KMP算法平均时间复杂度O(m+n)。
m,n分别为串t,s的长度。
KMP测试
自己写的测试程序,复制粘贴即可运行:
#include <iostream>
using namespace std;
#define MAXSIZE 100
typedef struct
{
char data[MAXSIZE];
int length;//字符串长度
}SqString;
//求模式串t的next值的算法
void GetNext(SqString t, int next[])
{
int j = 0, k = -1;
next[0] = -1;
while (j < t.length - 1)
{
if (k == -1 || t.data[j] == t.data[k])
{
j++;
k++;
next[j] = k;
}
else
{
k = next[k];
}
}
cout << "next数组为:";
for (int i = 0; i < t.length; i++)
{
cout << next[i];
}
cout << "\n";
}
//KMP
int KMPIndex(SqString t, SqString s)
{
int next[MAXSIZE], i = 0, j = 0;
GetNext(t, next);
while (i < s.length && j < t.length)
{
if (j == -1 || s.data[i] == t.data[j])
{
i++;
j++;
}
else
{
j = next[j];//i不变,j后退
}
}
if (j >= t.length)
{
return i - t.length;//返回匹配模式串的首字符下标
}
else
{
return -1;//返回不匹配
}
}
int main()
{
SqString t;
cout << "请输入t.length:";
cin >> t.length;
cout << "请输入t.data:";
for (int i = 0; i < t.length; i++)
{
cin >> t.data[i];
}
SqString s;
cout << "请输入s.length:";
cin >> s.length;
cout << "请输入s.data:";
for (int i = 0; i < s.length; i++)
{
cin >> s.data[i];
}
cout << "KMP返回值为:"<< KMPIndex(t, s);
}
一些测试结果:
匹配成功返回串首字符下标
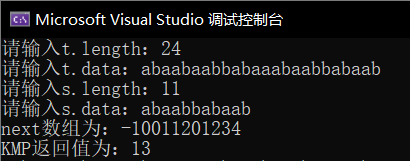
不匹配返回-1
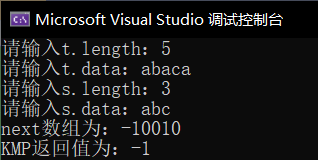
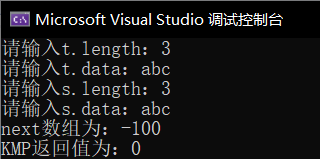
匹配成功返回串首字符下标
KMP改进
KMP也是有瑕疵的,可以进一步改进,大概思路是将next数组改为nextval数组,有兴趣请点击下方链接。
12分17秒开始
以上 如果此篇博客对您有帮助欢迎点赞与转发 有疑问请留言或私信 2020/8/3















 1060
1060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









