






链式编程
链式编程简单来说就是一个方法返回引用本身:
public class demo {
public static void main(String[] args) {
Person person = new Person().setName("李四").setAge(18);
System.out.println(person);
}
}
class Person{
private String name;
private int age;
public String getName() {
return name;
}
public Person setName(String name) {
this.name = name;
//返回this,方便调用下一个set
return this;
}
public int getAge() {
return age;
}
public Person setAge(int age) {
this.age = age;
return this;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
山寨Stream API
public class MockStream {
public static void main(String[] args) throws JsonProcessingException {
MyList<Person> personMyList = new MyList<>();
personMyList.add(new Person("李健", 46));
personMyList.add(new Person("周深", 28));
personMyList.add(new Person("张学友", 59));
// 需求:过滤出年龄大于40的歌手的名字
MyList<String> result = personMyList.filter(person -> person.getAge() > 40).map(Person::getName);
prettyPrint(result.getList());
System.out.println("\n---------------------------------------------\n");
// 对比真正的Stream API
List<Person> list = new ArrayList<>();
list.add(new Person("李健", 46));
list.add(new Person("周深", 28));
list.add(new Person("张学友", 59));
List<String> collect = list
.stream() // 真正的Stream API需要先转成stream流
.filter(person -> person.getAge() > 40) // 过滤出年纪大于40的歌手
.map(Person::getName) // 拿到他们的名字
.collect(Collectors.toList()); // 整理成List<String>
prettyPrint(collect);
}
/**
* 按JSON格式输出
*
* @param obj
* @throws JsonProcessingException
*/
private static void prettyPrint(Object obj) throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
String s = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(obj);
System.out.println(s);
}
}
@Data
@AllArgsConstructor
class Person {
private String name;
private Integer age;
}
@Getter
class MyList<T> {
private List<T> list = new ArrayList<>();
public boolean add(T t) {
return list.add(t);
}
/**
* 给MyList传递具体的判断规则,然后MyList把内部现有符合判断(true)的元素集返回
* @param predicate
* @return
*/
public MyList<T> filter(Predicate<T> predicate){
MyList<T> filteredList = new MyList<>();
for (T t : list) {
if (predicate.test(t)) {
// 收集判断为true的元素
filteredList.add(t);
}
}
return filteredList;
}
/**
* 把MyList中的List<T>转为List<R>
*
* @param mapper
* @param <R>
* @return
*/
public <R> MyList<R> map(Function<T, R> mapper) {
MyList<R> mappedList = new MyList<>();
for (T t : list) {
mappedList.add(mapper.apply(t));
}
return mappedList;
}
}
/**
* 定义一个Predicate接口,名字无所谓
*
* @param <T>
*/
@FunctionalInterface
interface Predicate<T> {
/**
* 定义了一个test()方法,传入任意对象,返回true or false,具体判断逻辑由子类实现
*
* @param t
* @return
*/
boolean test(T t);
}
/**
* 定义一个Function接口,名字无所谓
*
* @param <E>
* @param <R>
*/
@FunctionalInterface
interface Function<E, R> {
/**
* 定义一个apply()方法,接收一个E返回一个R。也就是把E映射成R
*
* @param e
* @return
*/
R apply(E e);
}
上面的山寨stream api使用到了接口多态。
接口,用的是函数式接口,即接口内部有且仅有一个抽象方法。
多态,原本指的是接口下有多个子类实例可以指向接口引用,但由于函数式接口恰好仅有一个方法,此时接口多态等同于“方法多态”,即一个抽象方法拥有多个不同的具体实现。
接口多态
我们都知道Java是面向对象的语言,它具备多态性。私以为,多态的精髓在于晚绑定。什么意思呢?
PocketMon pocketMon = new Pikaqiu();
pocketMon.releaseSkill();
只看pocketMon.releaseSkill()你能猜出来技能是电击还是喷火吗?
这种现象其实很奇妙:明明代码都写死了,但虚拟机却无法提前确定具体会是哪只神奇宝贝在调用releaseSkill(),除非实际运行到这行代码。而这,正是得益于多态。
多态的原理,本质上还是jvm通过运行时查找方法表实现的,可以简单理解为,JVM在运行时需要去循环遍历这个方法对应的多态实现,选择与当前运行时对象匹配的方法进行调用。
多态是“晚绑定”思想的体现:对于java而言,方法的调用并不是编译时期绑定的,而是运行时动态绑定的,取决于引用具体指向的实例。
方法多态
"方法多态"是生造的。
看一个需求:
要求写一个cook()方法,传入鸡翅和可乐,你给我做出可乐鸡翅。
public static CokaChickenWing coke(Chicken chicken, Coka coka){
1.放油、放姜;
2.放鸡翅;
3.倒可乐;
4.return CokaChickenWing;
}
上面直接就把代码写死了,但是,网上也有人说应该先倒可乐再放鸡翅,每个人的口味不同,做法也不同。有没有办法把这两步延迟确定呢?让调用者自己来安排到底是先倒可乐还是先放鸡翅。
可以这样:
public static CokaChickenWing coke(Chicken chicken, Coka coka,Function twoStep){
1.放油、放姜;
twoStep;
4.return CokaChickenWing;
}
想法很好:既然这两步不确定,那么就由调用者来决定吧,让调用者自己传进来。
但是java中并不能直接传递方法,但可以用策略模式解决这个问题:
定义一个接口
public interface TwoStep{
void execute();
}
public static CokaChickenWing cook(Chicken chicken, Coka coka, TwoStep twoStep){
1.放油、放姜;
2~3.twoStep.excute();
4.return CokaChickenWing;
}
这里twoStep.excute()是确定的吗?
没有
你说它是先倒可乐,再放鸡翅?我偏要说它是先放鸡翅,再倒可乐!反正接口也没方法体,具体实现要看你传进来什么对象
所以twoStep.excute()充其量只是先替“某些操作占个坑”,后面再确定。
什么时候确定呢?
main(){
TwoStep twoStep = new TwoStep(){
@Override
public void excute(){
2.先放鸡翅
3.再倒可乐
}
}
// 调用cook时确定(运行时)
cook(chicken, coka, twoStep);
}
public static CokaChickenWing cook(Chicken chicken, Coka coka, TwoStep twoStep){
1.放油、放姜;
2~3.twoStep.excute();
4.return CokaChickenWing;
}
学过Lambda表达式后,我们换个时髦的写法:
main(){
// 调用cook时确定 方案1
cook(chicken, coka, (鸡翅, 可乐) -> 2.先放鸡翅,3.再倒可乐);
// 调用cook时确定 方案2
cook(chicken, coka, (鸡翅, 可乐) -> 2.先倒可乐,3.再放鸡翅);
}
public static CokaChickenWing cook(Chicken chicken, Coka coka, TwoStep twoStep){
1.放油、放姜;
2~3.twoStep.excute();
4.return CokaChickenWing;
}
这就是所谓的"方法多态",通过函数式接口把形参的坑占住,后续传入不同的lambda实现逻辑。
模拟Stream API:filter()
interface Predicate<T>{
/**
* 定义了一个test()方法,传入任意对象,返回true or false,具体判断逻辑由子类实现
*
* @param t
* @return
*/
boolean test(T t);
}
class PredicateImpl implements Predicate<Person>{
/**
* 判断逻辑是:传入的person是否age>18,是就返回true
*
* @param person
* @return
*/
@Override
public boolean test(Person person) {
return person.getAge()>18;
}
}
@Data
@AllArgsConstructor
class Person{
private String name;
private int age;
}
测试:
public class MockStream {
public static void main(String[] args) {
//1.实体类调用test方法
Person person = new Person("张三",18);
Predicate<Person> predicate = new PredicateImpl();
myPrint(person,predicate);
//2.lambda表达式
myPrint(person, new Predicate<Person>() {
@Override
public boolean test(Person person) {
return person.getAge()==18;
}
});
}
public static void myPrint(Person person, Predicate<Person> filter) {
if (filter.test(person)) {
System.out.println("true");
} else {
System.out.println("false");
}
}
}
myPrint(Person person, Predicate filter)的精髓是,用了函数式接口占坑,我们无需关注Predicate传入myPrint()后将被如何调用,只要关注如何实现Predicate,又由于Predicate只有一个test()方法,所以最终我们只需关注如何实现test()方法。
上面的例子可以看出:
不论具体实现类、匿名类还是Lambda表达式,其实做的事情本质上是一样的:
- 先让函数式接口占坑
- 自己不慌不忙制定映射规则,规则可以被藏在具体类、匿名类中,或者Lambda表达式本身
有了上面的铺垫,我们来仔细看看之前山寨Stream API对filter()的实现:
class MyList<T>{
private List<T> list = new ArrayList<>();
// 1.外部调用add()添加的元素都会被存在list
public boolean add(T t) {
return list.add(t);
}
/**
* 过滤方法,接收过滤规则
* @param predicate
* @return
*/
public List<T> filter(Predicate<T> predicate){
List<T> filteredList = new ArrayList<>();
for (T t : list) {
// 2.把规则应用于list
if (predicate.test(t)) {
// 3.收集符合条件的元素
filteredList.add(t);
}
}
return filteredList;
}
}
● filter(Predicate predicate)方法需要一个过滤规则,但这个规则不能写死,所以随便搞了一个接口占坑
● 具体的过滤规则被延迟到传入具体类实例或Lambda时才确定
public class MockStream {
public static void main(String[] args) throws JsonProcessingException {
MyList<Person> personMyList = new MyList<>();
personMyList.add(new Person("李健", 46));
personMyList.add(new Person("周深", 28));
personMyList.add(new Person("张学友", 59));
// 过渡1:把Lambda赋值给变量,然后在传递
Predicate<Person> predicate = person -> person.getAge() > 40;
List<Person> filteredList = personMyList.filter(predicate);
prettyPrint(filteredList);
System.out.println("\n---------------------------------------------\n");
// 不像Stream API?这样写呢?
List<Person> filter = personMyList.filter(person -> person.getAge() > 40);
prettyPrint(filter);
// 不要问我为什么没有stream()和collect(),问就是不会写。
System.out.println("\n---------------------------------------------\n");
// 有请真正的Stream API(要用真的List了,不能用山寨MyList)
List<Person> list = new ArrayList<>();
list.add(new Person("李健", 46));
list.add(new Person("周深", 28));
list.add(new Person("张学友", 59));
List<Person> collect = list.stream().filter(person -> person.getAge() > 40).collect(Collectors.toList());
prettyPrint(collect);
}
/**
* 按JSON格式输出
*
* @param obj
* @throws JsonProcessingException
*/
private static void prettyPrint(Object obj) throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
String s = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(obj);
System.out.println(s);
}
}
// 省略Predicate、Person、MyList
模拟Stream API:map()
/**
* 定义一个Function接口
* 从接口看Function<E, R>中,E(Enter)表示入参类型,R(Return)表示返回值类型
*
* @param <E> 入参类型
* @param <R> 返回值类型
*/
@FunctionalInterface
interface Function<E, R> {
/**
* 定义一个apply()方法,接收一个E返回一个R。也就是把E映射成R
*
* @param e
* @return
*/
R apply(E e);
}
/**
* Function接口的实现类,规定传入Person类型返回Integer类型
*/
class FunctionImpl implements Function<Person, Integer> {
/**
* 传入person对象,返回age
*
* @param person
* @return
*/
@Override
public Integer apply(Person person) {
return person.getAge();
}
}
public class MockStream {
public static void main(String[] args) {
Person bravo = new Person("bravo", 18);
// 1.具体实现类,Function<Person, Integer>中,Person是入参类型,Integer是返回值类型
Function<Person, Integer> function1 = new FunctionImpl();
myPrint(bravo, function1);
// 2.匿名类
Function<Person, Integer> function2 = new Function<Person, Integer>() {
@Override
public Integer apply(Person person) {
return person.getAge();
}
};
myPrint(bravo, function2);
// 3.Lambda表达式 person(入参类型) -> person.getAge()(返回值类型)
Function<Person, Integer> function3 = person -> person.getAge();
myPrint(bravo, function3);
}
public static void myPrint(Person person, Function<Person, Integer> mapper) {
System.out.println(mapper.apply(person));
}
}
之前我们在MyList中写了个filter()方法并用Predicate接口占了坑,它接收一个“过滤器”来过滤元素。而现在,map()方法用Function接口占坑,它需要接收一个“转换器”来帮元素“变身”:
class MyList<T> {
private List<T> list = new ArrayList<>();
public boolean add(T t) {
return list.add(t);
}
/**
* 把MyList中的List<T>转为List<R>
* 不要关注Function<T, R>接口本身,而应该关注apply()
* apply()接收T t,返回R t。具体实现需要我们从外面传入,这里只是占个坑
*
* @param mapper
* @param <R>
* @return
*/
public <R> List<R> map(Function<T, R> mapper) {
List<R> mappedList = new ArrayList<>();
for (T t : list) {
// mapper通过apply()方法把T t 变成 R t,然后加入到新的list中
mappedList.add(mapper.apply(t));
}
return mappedList;
}
}
无论filter(Predicate predicate)还是map(Function mapper),其实就是接口占坑、Lambda填坑的过程,其中函数式接口只有唯一方法,所以可以直接把接口多态看做方法多态。比如Predicate只有一个抽象方法boolean test(),那么你写一个符合的具体实现即可:没有入参,返回值为boolean。
Stream API
Stream API与接口默认方法、静态方法
之前说的函数式接口,说到过java8新增的接口中的静态方法和默认方法:

为什么Java8要引入静态方法和默认方法呢?
看Collection接口:

我们发现有3个default方法,而且都是JDK1.8新增的:
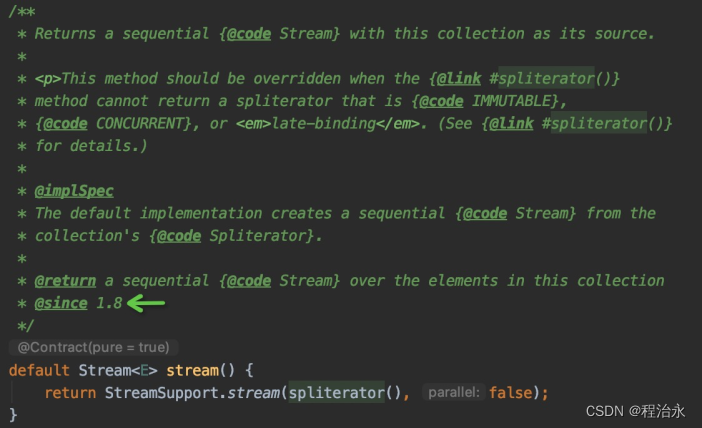
这下明白了吧,list.stream().filter()…用的这么爽,其实都直接继承自顶级父接口Collection。
这和引入default有啥关系呢?
不妨想一下,要想操作stream首先要先获得stream,获流应该放在Collection及其子接口、实现类中。
但如果作为抽象方法抽取到Collection中,那么原先的整个继承链都会产生较大的震动:
JDK官方要从Collection接口沿着继承链向下都实现一遍stream()方法。这还不是最大的问题,最致命的是全球各地保不齐就有人直接实现了Collection,比如MyArrayList啥的,此时如果贸然往Collection增加一个抽象方法,那么当他们升级到JDK1.8后就会立即编译错误,强制他们自己实现stream()…
所以JDK的做法是,把获取Stream的一部分方法封装到StreamSupport类,另一部分封装到Stream类,StreamSupport用来补足原先的集合体系,比如Collection,然后引入default方法包装一下,内部调用StreamSupport完成偷天换日。而得到Stream后的一系列filter、map操作是针对Stream的,已经封装在Stream类中,和原来的集合无关。
Stream API
我们常用的集合其实来自两个流派:Collection和Map
认识几个重要的接口和类
● Collection
● Stream
● StreamSupport
● Collector
● Collectors
Collection
之前介绍过了,为了不影响之前的实现,JDK引入了接口默认方法,并且在Collection中提供了一系列将集合转为Stream的方法:
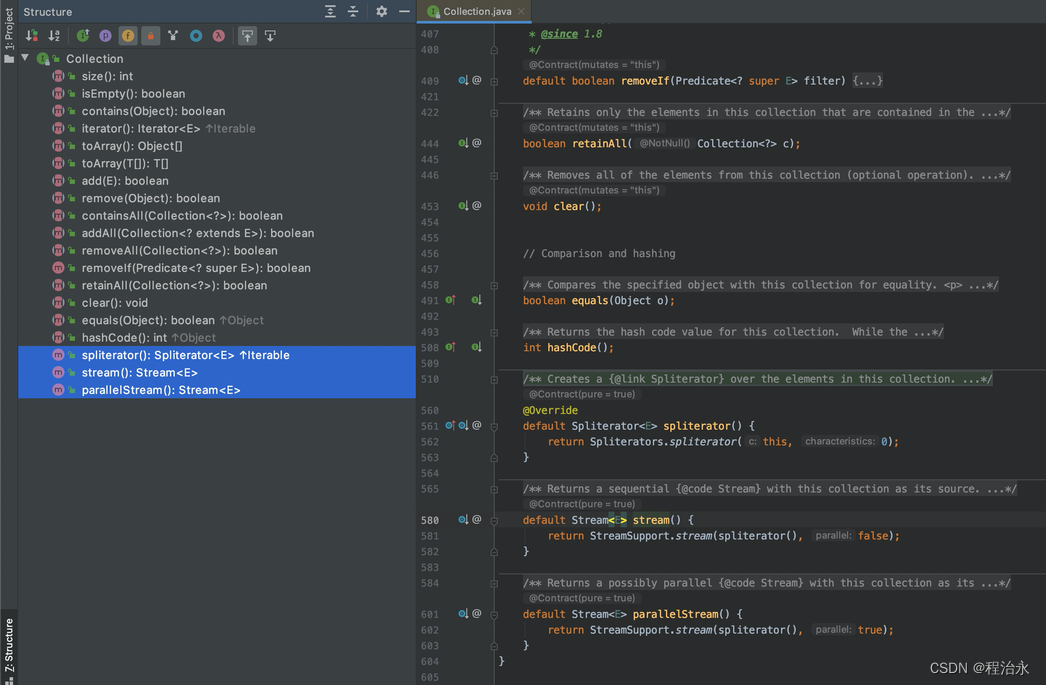
要想使用Stream API,第一步就是获取Stream,而Collection提供了stream()和parallelStream()两个方法,后续Collection的子类比如ArrayList、HashSet等都可以直接使用顶级父接口定义好的默认方法将自身集合转为Stream。
Stream
Java的集合在设计之初就只是一种容器,用来存储元素,内部并没有提供处理元素的方法。更多时候,我们其实是使用集合提供的遍历方法,然后手动在外部进行判断并处理元素。
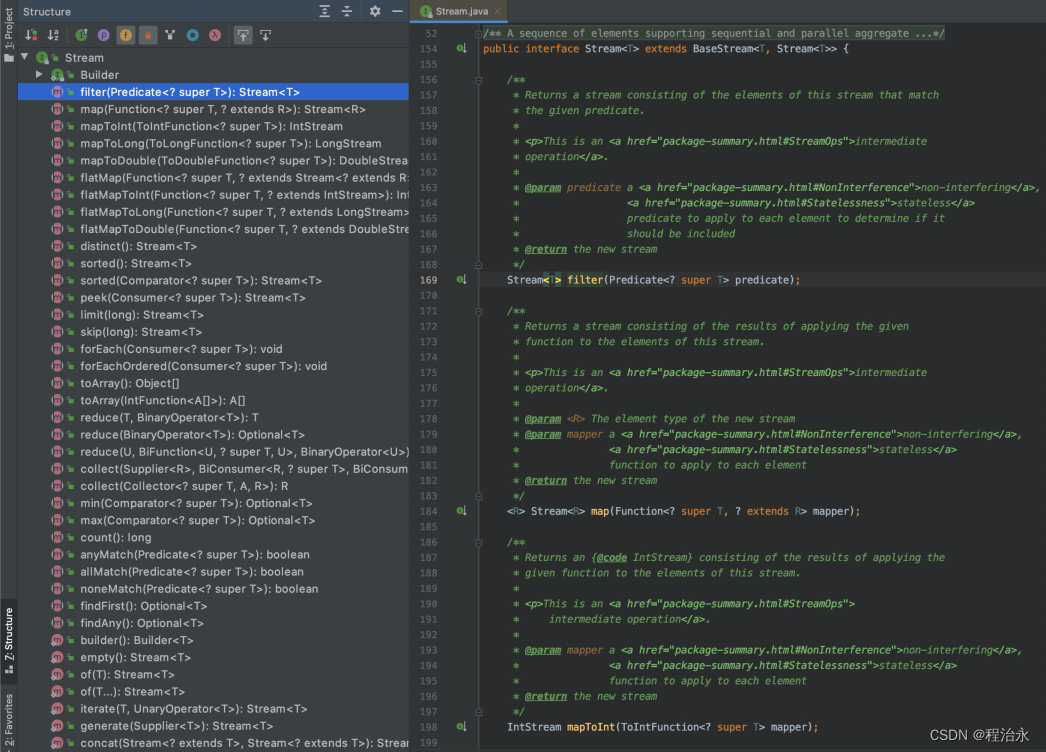
Stream是什么呢?简单来说,可以理解为更高级的Iterator,把集合转为Stream后,我们就可以使用Stream对元素进行一系列操作。
来,感受一下,平时使用的filter()、map()、sorted()、collect()都来自哪:
StreamSupport
没啥好介绍的,一般不会直接使用StreamSupport,Collection接口借助它实现了stream()和parallelStream()。

collect()、Collector、Collectors
collect()是用来收集处理后的元素的,它有两个重载的方法:
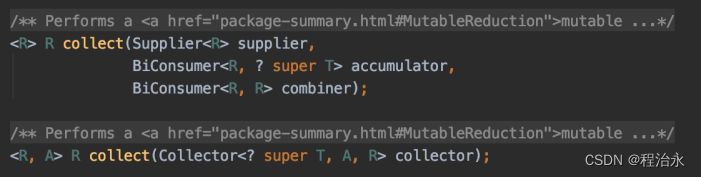 我们暂时只看下面那个,它接收一个Collector对象,而我们一般不会自己去new Collector对象,因为JDK给我提供了Collectors,可以调用Collectors提供的方法返回Collector对象:
我们暂时只看下面那个,它接收一个Collector对象,而我们一般不会自己去new Collector对象,因为JDK给我提供了Collectors,可以调用Collectors提供的方法返回Collector对象:

所以collect()、Collector、Collectors三者的关系是:
collect()通过传入不同的Collector对象来明确如何收集元素,比如收集成List还是Set还是拼接字符串?而通常我们不需要自己实现Collector接口,只需要通过Collectors获取。
基础操作
map/filter
public class MapAndFilter {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
//1.先获取流
Stream<Person> stream = list.stream();
//2.过滤年纪大于18的
Stream<Person> filteredByAgeStream = stream.filter(p->p.getAge() > 18);
//3.只要名字
Stream<String> nameStream = filteredByAgeStream.map(Person::getName);
// 4.现在返回值是Stream<String>,没法直接使用,帮我收集成List<String>
List<String> list1 = nameStream.collect(Collectors.toList());
System.out.println(list1);
}
}
@Data
@AllArgsConstructor
@NoArgsConstructor
class Person{
private String name;
private Integer age;
private String address;
private Double salary;
}
sorted
在此之前,我们先来见见一位老朋友:Comparator。这个接口其实早在JDK1.2就有了,但当时只有两个方法:
● compare()
● equals()

注意,这里面的equals是Object的。
JDK1.8通过默认方法的形式引入了很多额外的方法,比如reversed()、Comparing()等。
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
// JDK8之前:Collections工具类+匿名内部类。Collections类似于Arrays工具类,我经常用Arrays.asList()
Collections.sort(list, new Comparator<Person>() {
@Override
public int compare(Person p1, Person p2) {
return p1.getName().length()-p2.getName().length();
}
});
// JDK8之前:List本身也实现了sort()
list.sort(new Comparator<Person>() {
@Override
public int compare(Person p1, Person p2) {
return p1.getName().length()-p2.getName().length();
}
});
// JDK8之后:Lambda传参给Comparator接口,其实就是实现Comparator#compare()。注意,equals()是Object的,不妨碍
list.sort((p1,p2)->p1.getName().length()-p2.getName().length());
// JDK8之后:使用JDK1.8为Comparator接口新增的comparing()方法
list.sort(Comparator.comparingInt(p -> p.getName().length()));
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
大家不好奇吗?sort()需要的是Comparator接口的实现,调用Comparator.comparing()怎么也可以?
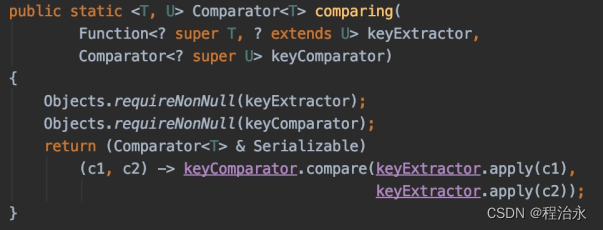
好家伙,Comparator.comparing()返回的也是Comparator…
OK,铺垫够了,来玩一下Stream#sorted(),看看和List#sort()有啥区别。
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
// 直接链式操作
List<String> nameList = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.collect(Collectors.toList());
System.out.println(nameList);
// 我想按姓名长度排序
List<String> sortedNameList = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.sorted()
.collect(Collectors.toList());
System.out.println(sortedNameList);
// 你:我擦,说好的排序呢?
// Stream:别扯淡,你告诉我排序规则了吗?(默认自然排序)
// 明白了,那就按照长度倒序吧(注意细节啊,str2-str1才是倒序)
List<String> realSortedNameList = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.sorted((str1, str2) -> str2.length() - str1.length())
.collect(Collectors.toList());
System.out.println(realSortedNameList);
// 优化一下:我记得在之前那张很大的思维导图上看到过,sorted()有重载方法,是sorted(Comparator)
// 上面Lambda其实就是调用sorted(Comparator),用Lambda给Comparator接口赋值
// 但Comparator还供了一些方法,能返回Comparator实例
List<String> optimizeNameList = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.sorted(Comparator.reverseOrder())
.collect(Collectors.toList());
System.out.println(optimizeNameList);
// 又是一样的套路,Comparator.reverseOrder()返回的其实是一个Comparator!!
// 但上面的有点投机取巧,来个正常点的,使用Comparator.comparing()
List<String> result1 = list.stream()
.filter(person -> person.getAge() > 18)
.map(Person::getName)
.sorted(Comparator.comparing(t -> t, (str1, str2) -> str2.length() - str1.length()))
.collect(Collectors.toList());
System.out.println(result1);
// 我去,更麻烦了!!
// 不急,我们先来了解上面案例中Comparator的两个参数
// 第一个是Function映射,就是指定要排序的字段,由于经过上一步map操作,已经是name了,就不需要映射了,所以是t->t
// 第二个是比较规则
// 我们把map和sorted调换一下顺序,看起来就不那么别扭了
List<String> result2 = list.stream()
.filter(person -> person.getAge() > 18)
.sorted(Comparator.comparing(Person::getName, String::compareTo).reversed())
.map(Person::getName)
.collect(Collectors.toList());
System.out.println(result2);
// 为什么Comparator.comparing().reversed()可以链式调用呢?
// 上面说了哦,因为Comparator.comparing()返回的还是Comparator对象~
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
看看下面的代码:
public static void main(String[] args) {
List<Person> result = list.stream().sorted().collect(Collectors.toList());
System.out.println(result);
}
会报错,为什么?

在学习Java基础时,我们了解到,如果希望进行对象间的比较:
● 要么对象实现Comparable接口(对象自身可比较)
● 要么传入Comparator进行比较(引入中介,帮对象们进行比较)
而上面sorted()既然没有传入Comparator,那么Person要实现Comparable接口:
public static void main(String[] args) {
List<Person> result = list.stream().sorted().collect(Collectors.toList());
System.out.println(result);
}
@Getter
@Setter
@EqualsAndHashCode
@AllArgsConstructor
static class Person implements Comparable<Person> {
private String name;
private Integer age;
private String address;
private Double salary;
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
", salary=" + salary +
'}';
}
// 定义比较规则
@Override
public int compareTo(Person anotherPerson) {
return anotherPerson.getAge() - this.getAge();
}
}
这样就可以了。
但是,同样是sorted(),为什么下面的代码不会报错呢?
public static void main(String[] args) {
List<Integer> result = StreamTest.list.stream()
.map(Person::getAge)
.sorted()
.collect(Collectors.toList());
System.out.println(result);
}
这是因为String、Integer都已经实现了Comparable接口:

sorted()容易采坑而且语义不够明确,个人建议使用sort(Comparator),显式地传入比较器:
public class ComparatorTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, 170));
list.add(new Person("am", 19, 180));
list.add(new Person("am", 20, 180));
list.add(new Person("iron", 19, 181));
list.add(new Person("iron", 19, 179));
list.add(new Person("man", 17, 160));
list.add(new Person("man", 16, 160));
}
public static void main(String[] args) {
// 先按身高降序,再按年龄降序
list.sort(Comparator.comparingInt(Person::getHeight).thenComparingInt(Person::getAge).reversed());
System.out.println(list);
// 先按身高升序,再按年龄升序
list.sort(Comparator.comparingInt(Person::getHeight).thenComparingInt(Person::getAge));
System.out.println(list);
// 先按身高降序,再按年龄升序
list.sort(Comparator.comparingInt(Person::getHeight).reversed().thenComparingInt(Person::getAge));
System.out.println(list);
// 先按身高升序,再按年龄降序
list.sort(Comparator.comparingInt(Person::getHeight).thenComparing(Person::getAge, Comparator.reverseOrder()));
System.out.println(list);
/**
* 大家可以理解为Comparator要实现排序可以有两种方式:
* 1、comparingInt(keyExtractor)、comparingLong(keyExtractor)... + reversed()表示倒序,默认正序
* 2、comparing(keyExtractor, Comparator.reverseOrder()),不传Comparator.reverseOrder()表示正序
*
* 第四个需求如果采用reversed(),似乎达不到效果,反正我没查到。
* 个人建议,单个简单的排序,无论正序倒序,可以使用第一种,简单一些。但如果涉及多个联合排序,建议使用第二种,语义明确不易搞错。
*
* 最后,上面是直接使用Collection的sort()方法,请大家自行改成Stream中的sorted()实现一遍。
*/
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private Integer height;
}
}
limit/skip
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
List<String> result = list.stream()
.filter(person -> person.getAge() > 17)
// peek()先不用管,它不会影响整个流程,就是打印看看filter操作后还剩什么元素
.peek(person -> System.out.println(person.getName()))
.skip(1)
.limit(2)
.map(Person::getName)
.collect(Collectors.toList());
System.out.println(result);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
所谓的skip(N)就是跳过前面N个元素,limit(N)就是只取N个元素。
collect
collect()是最重要、最难掌握、同时也是功能最丰富的方法。
最常用的4个方法:Collectors.toList()、Collectors.toSet()、Collectors.toMap()、Collectors.joining()
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
// 最常用的4个方法
// 把结果收集为List
List<String> toList = list.stream().map(Person::getAddress).collect(Collectors.toList());
System.out.println(toList);
// 把结果收集为Set
Set<String> toSet = list.stream().map(Person::getAddress).collect(Collectors.toSet());
System.out.println(toSet);
// 把结果收集为Map,前面的是key,后面的是value,如果你希望value是具体的某个字段,可以改为toMap(Person::getName, person -> person.getAge())
Map<String, Person> nameToPersonMap = list.stream().collect(Collectors.toMap(Person::getName, person -> person));
System.out.println(nameToPersonMap);
// 把结果收集起来,并用指定分隔符拼接
String result = list.stream().map(Person::getAddress).collect(Collectors.joining("~"));
System.out.println(result);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
关于collect收集成Map的操作,有一个小坑需要注意:
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("iron", 17, "宁波", 888.8));
}
public static void main(String[] args) {
Map<String, Person> nameToPersonMap = list.stream().collect(Collectors.toMap(Person::getName, person -> person));
System.out.println(nameToPersonMap);
}
@Getter
@Setter
@AllArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
", salary=" + salary +
'}';
}
}
}
会报错
这是因为toMap()不允许key重复,我们必须指定key冲突时的解决策略(比如,保留已存在的key):
public static void main(String[] args) {
Map<String, Person> nameToPersonMap = list.stream()
.collect(Collectors.toMap(Person::getName, person -> person, (preKey, nextKey) -> preKey));
System.out.println(nameToPersonMap);
}
如果你希望key覆盖,可以把(preKey, nextKey) -> preKey)换成(preKey, nextKey) -> nextKey)。
你可能会在同事的代码中发现另一种写法:
public static void main(String[] args) {
Map<String, Person> nameToPersonMap = list.stream().collect(Collectors.toMap(Person::getName, Function.identity());
System.out.println(nameToPersonMap);
}
Function.identity()其实就是v->v:

但它依然没有解决key冲突的问题,而且对于大部分人来说,相比person->person,Function.identity()的可读性不佳。
聚合:max/min/count
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
public static void main(String[] args) {
// 匿名内部类的方式,实现Comparator,明确按什么规则比较(所谓最大,必然是在某种规则下的最值)
Optional<Integer> maxAge = list.stream().map(Person::getAge).max(new Comparator<Integer>() {
@Override
public int compare(Integer age1, Integer age2) {
return age1 - age2;
}
});
System.out.println(maxAge.orElse(0));
Optional<Integer> max = list.stream().map(Person::getAge).max(Integer::compareTo);
System.out.println(max.orElse(0));
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
count
public static void main(String[] args) {
long count = list.stream().filter(person -> person.getAge() > 18).count();
System.out.println(count);
}
distinct
public static void main(String[] args) {
long count = list.stream().map(Person::getAddress).distinct().count();
System.out.println(count);
}
高阶操作
两部分内容:
● 深化一下collect()方法,它还有很多其他玩法
● 介绍flatMap、reduce、匹配查找、peek、forEach等边角料
collect高阶操作
聚合
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
/**
* 演示用collect()方法实现聚合操作,对标max()、min()、count()
* @param args
*/
public static void main(String[] args) {
// 方式1:匿名对象
Optional<Person> max1 = list.stream().collect(Collectors.maxBy(new Comparator<Person>() {
@Override
public int compare(Person p1, Person p2) {
return p1.getAge() - p2.getAge();
}
}));
System.out.println(max1.orElse(null));
// 方式2:Lambda
Optional<Person> max2 = list.stream().collect(Collectors.maxBy((p1, p2) -> p1.getAge() - p2.getAge()));
System.out.println(max2.orElse(null));
// 方式3:方法引用
Optional<Person> max3 = list.stream().collect(Collectors.maxBy(Comparator.comparingInt(Person::getAge)));
System.out.println(max3.orElse(null));
// 方式4:IDEA建议直接使用 max(),不要用 collect(Collector)
Optional<Person> max4 = list.stream().max(Comparator.comparingInt(Person::getAge));
System.out.println(max4.orElse(null));
// 特别是方式3和方式4,可以看做collect()聚合和max()聚合的对比
// 剩下的minBy和counting
Optional<Person> min1 = list.stream().collect(Collectors.minBy(Comparator.comparingInt(Person::getAge)));
Optional<Person> min2 = list.stream().min(Comparator.comparingInt(Person::getAge));
Long count1 = list.stream().collect(Collectors.counting());
Long count2 = list.stream().count();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
分组
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
/**
* 按字段分组
* 按条件分组
*
* @param args
*/
public static void main(String[] args) {
// GROUP BY address
Map<String, List<Person>> groupingByAddress = list.stream().collect(Collectors.groupingBy(Person::getAddress));
System.out.println(groupingByAddress);
// GROUP BY address, age
Map<String, Map<Integer, List<Person>>> doubleGroupingBy = list.stream()
.collect(Collectors.groupingBy(Person::getAddress, Collectors.groupingBy(Person::getAge)));
System.out.println(doubleGroupingBy);
// 简单来说,就是collect(groupingBy(xx)) 扩展为 collect(groupingBy(xx, groupingBy(yy))),嵌套分组
// 解决了按字段分组、按多个字段分组,我们再考虑一个问题:有时我们分组的条件不是某个字段,而是某个字段是否满足xx条件
// 比如 年龄大于等于18的是成年人,小于18的是未成年人
Map<Boolean, List<Person>> adultsAndTeenagers = list.stream().collect(Collectors.partitioningBy(person -> person.getAge() >= 18));
System.out.println(adultsAndTeenagers);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
支持自定义分组条件的partitioningBy()就派上用场:
public static void main(String[] args) throws JsonProcessingException {
// 简单版
Map<Boolean, List<Person>> result = list.stream().collect(Collectors.partitioningBy(StreamTest::condition));
System.out.println(new ObjectMapper().writerWithDefaultPrettyPrinter().writeValueAsString(result));
}
// 年龄大于18,且来自杭州
private static boolean condition(Person person) {
return person.getAge() > 18
&& "杭州".equals(person.getAddress());
}
统计
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9));
list.add(new Person("am", 19, "温州", 777.7));
list.add(new Person("iron", 21, "杭州", 888.8));
list.add(new Person("man", 17, "宁波", 888.8));
}
/**
* 统计
* @param args
*/
public static void main(String[] args) {
// 平均年龄
Double averageAge = list.stream().collect(Collectors.averagingInt(Person::getAge));
System.out.println(averageAge);
// 平均薪资
Double averageSalary = list.stream().collect(Collectors.averagingDouble(Person::getSalary));
System.out.println(averageSalary);
// 其他的不演示了,大家自己看api提示。简而言之,就是返回某个字段在某个纬度的统计结果
// 有个更绝的,针对某项数据,一次性返回多个纬度的统计结果:总和、平均数、最大值、最小值、总数,但一般用的很少
IntSummaryStatistics allSummaryData = list.stream().collect(Collectors.summarizingInt(Person::getAge));
long sum = allSummaryData.getSum();
double average = allSummaryData.getAverage();
int max = allSummaryData.getMax();
int min = allSummaryData.getMin();
long count = allSummaryData.getCount();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
}
}
flatMap
总的来说,就是flatMap就是把多个流合并成一个流:
public class StreamTest {
private static List<Person> list;
static {
list = new ArrayList<>();
list.add(new Person("i", 18, "杭州", 999.9, new ArrayList<>(Arrays.asList("成年人", "学生", "男性"))));
list.add(new Person("am", 19, "温州", 777.7, new ArrayList<>(Arrays.asList("成年人", "打工人", "宇宙最帅"))));
list.add(new Person("iron", 21, "杭州", 888.8, new ArrayList<>(Arrays.asList("喜欢打篮球", "学生"))));
list.add(new Person("man", 17, "宁波", 888.8, new ArrayList<>(Arrays.asList("未成年人", "家里有矿"))));
}
public static void main(String[] args) {
Set<String> allTags = list.stream().flatMap(person -> person.getTags().stream()).collect(Collectors.toSet());
System.out.println(allTags);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
static class Person {
private String name;
private Integer age;
private String address;
private Double salary;
// 个人标签
private List<String> tags;
}
}
总之,当你遇到List中还有List,然后你又想把第二层的List都拎出来集中处理时,就可以考虑用flatMap(),先把层级打平,再统一处理。
peek()

它接受一个Consumer,一般有两种用法:
● 设置值
● 观察数据
设置值的用法:
public class StreamTest {
public static void main(String[] args) {
list.stream().peek(person -> person.setAge(18)).forEach(System.out::println);
}
}
也就是把所有人的年龄设置为18岁。
peek这个单词本身就带有“观察”的意思。

简单来说,就是查看数据,一般实际开发很少用,但可以用来观察数据的流转:
public class StreamTest {
public static void main(String[] args) {
Stream<Integer> stream = Stream.of(1, 2, 3);
stream.peek(v-> System.out.print(v+",")).map(value -> value + 100).peek(v-> System.out.print(v+",")).forEach(System.out::println);
}
}
结果
1,101,101
2,102,102
3,103,103
用图表示的话,就是这样:

通过peek,我们观察到每一个元素都是逐个通过Stream流的。
匹配/查找
findFirst
public static void main(String[] args) {
Optional<Integer> first = Stream.of(1, 2, 3, 4)
.findFirst();
System.out.println(first.orElse(0));
}
结果:1
只要第一个,后续元素不会继续遍历。
allMatch
public static void main(String[] args) {
boolean b = Stream.of(1, 2, 3, 4)
.peek(v -> System.out.print(v + ","))
.allMatch(v -> v > 2);
}
结果
1,
由于是要allMatch,第一个就不符合,那么其他元素也就没必要测试了。这是一个短路操作。
Collectors.toList()默认返回ArrayList,如何返回LinkedList?
public static void main(String[] args) {
List<String> top2Adult = list.stream()
.filter(person -> person.getAge() >= 18) // 过滤得到年龄大于等于18岁的人
.sorted(Comparator.comparingInt(Person::getAge)) // 按年龄排序
.map(Person::getName) // 得到姓名
.limit(2) // 取前两个数据
.collect(Collectors.toCollection(LinkedList::new)); // 返回LinkedList,其他同理
System.out.println(top2Adult);
}















 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









