







excel表格中身份证信息提取出生年月日,年龄,性别,出生地

身份证号码的意义
①前1、2位数字表示:所在省份的代码,河南的省份代码是41哦!
②第3、4位数字表示:所在城市的代码;
③第5、6位数字表示:所在区县的代码;
④第7~14位数字表示:出生年、月、日;
⑤第15、16位数字表示:所在地的派出所的代码;
⑥第17位数字表示性别:奇数表示男性,偶数表示女性;
⑦第18位数字是校检码:也有的说是个人信息码,一般是随计算机随机产生,用来检验身份证的正确性。校检码可以是0~9的数字,有时也用x表示10。
1.年龄
=YEAR(NOW())-MID(A2,7,4)
- =YEAR(NOW()) 这个函数,这个代表当前日期年份
- 用当前年份减出生年份,也就是身份证号第7位数字的后4个数字,
- 函数为mid(A2,7,4)
- A2代表身份证所在单元格,
- 7表示从第7位开始,
- 4表示选取4个数字。
2.出生年月
=TEXT(MID(A2,7,8),"0000年00月00日")
- 其中的A2表示的是身份证号码处在第A列第二行,
- 7表示的是从第7位开始,
- 8表示的是出生年月的8位,
- "0000-00-00"表示按照年月日的方式输出,年份占4位,月份和日期各占2位
3.性别
=IF(MOD(MID(A2,17,1),2),"男","女")
4.代码实现 出生地
https://qq.ip138.com/idsearch/index.asp(百度搜索身份证归属地查询第一个就是)。你在这个网站上输入身份证号码,它就会给你把性别、生日、户籍地给你弄出来。
接下来用爬虫实现
提前下载包
- pandas
- lxml
- openpyxl
下载通用命令加速版:
pip install 包名 -i https://pypi.douban.com/simple
# 把需要用到的库一股脑import进来
import importlib, sys
importlib.reload(sys)
import time
import pandas as pd
import urllib.request
from lxml import etree
start = time.time()
# 先将存有身份证号码信息的txt文件读取进来
df = pd.read_table('E:/SFZ.txt', sep='\t', header=None, dtype=str, na_filter=False)
# 定义接下来存储身份证号码、性别、生日、户籍地信息的4个list
idcard = []
sex1 = []
birthday1 = []
address1 = []
# 通过循环,依次将每个身份证号码对应的信息获取
for i in range(df.shape[0]):
# 多一个try,防止某个号码出差自己中止代码执行
try:
# print (df.iloc[i,0])
# 查看身份证查询网页的网址,发现规律,按照规律组成url
url = "https://qq.ip138.com/idsearch/index.asp?userid=" + df.iloc[i, 0] + "&action=idcard"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'
}
# 获取内容
request = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(request)
content = res.read().decode('utf-8')
# 解析网页源码 获取我们需要的数据
tree = etree.HTML(content)
sex = tree.xpath('//div[@class="bd"]//tbody/tr[2]/td[2]/p/text()')[0]
birthday = tree.xpath('//div[@class="bd"]//tbody/tr[3]/td[2]/p/text()')[0]
address = tree.xpath('//div[@class="bd"]//tbody/tr[5]/td[2]/p/text()')[0]
# 添加到列表
idcard.append(df.iloc[i, 0])
sex1.append(sex)
birthday1.append(birthday)
address1.append(address)
except Exception as e:
print(Exception, ":", e)
# 打包数据
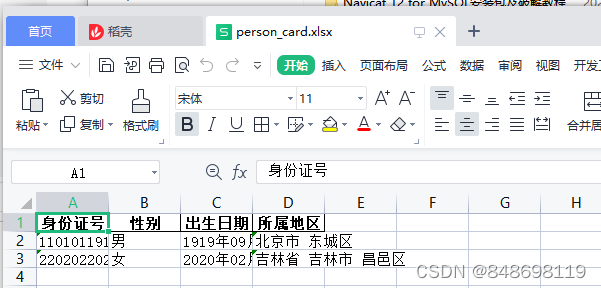
data = pd.DataFrame({'身份证号': idcard, '性别': sex1, '出生日期': birthday1, '所属地区': address1})
print(data)
# # 将数据输出成一个excel文件
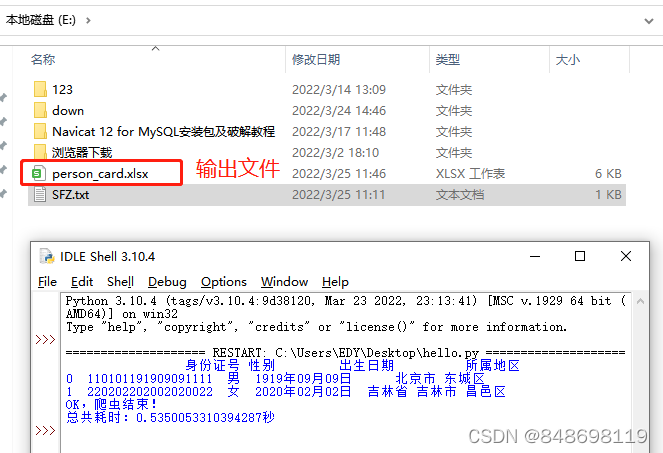
pd.DataFrame.to_excel(data, "E:\\person_card.xlsx", header=True, encoding='gbk', index=False)
end = time.time()
print(u'OK,爬虫结束!')
print(u'总共耗时:' + str(end - start) + '秒')
1.报错:ModuleNotFoundError: No module named 'pandas'
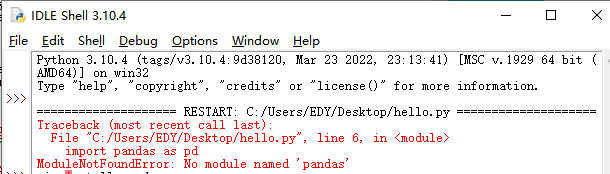
- win+R
- cmd
- 输入:
pip install pandas -i https://pypi.douban.com/simple
- 回车

2.报错:ModuleNotFoundError: No module named 'lxml'
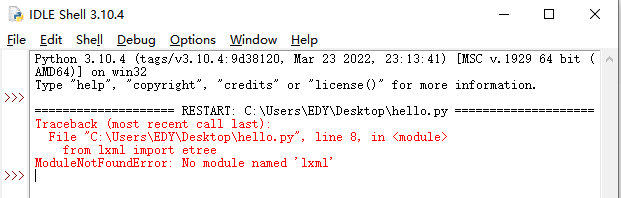
- win+R
- cmd
- 输入:
pip install lxml -i https://pypi.douban.com/simple
- 回车
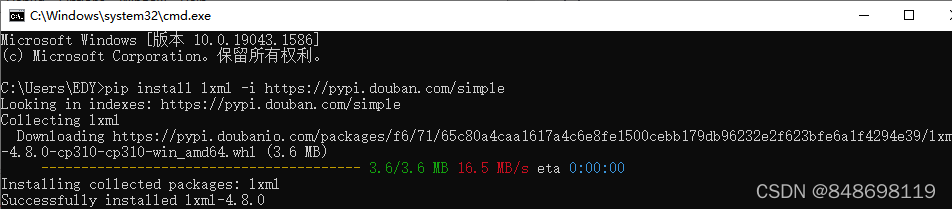
3.报错:ModuleNotFoundError: No module named 'openpyxl'
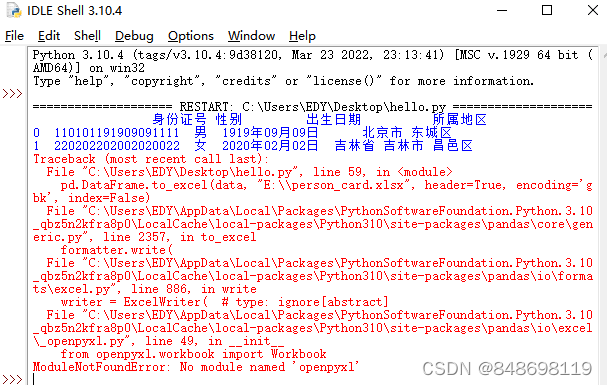
- win+R
- cmd
- 输入:
pip install openpyxl -i https://pypi.douban.com/simple
- 回车
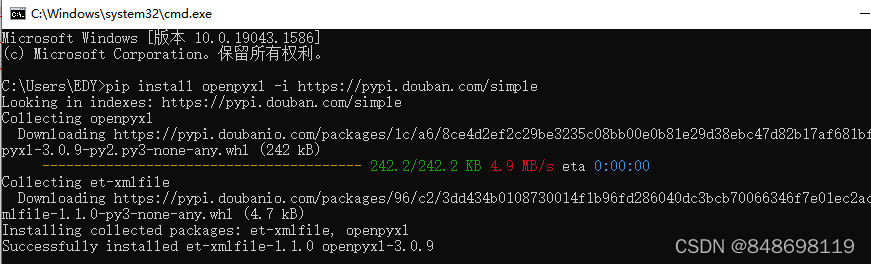
4.最终成功输出一个Excel表格



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











