







Linux操作系统
1. 认识fork
通过man fork可以看出这个函数创建了一个子进程

调用fork函数,查看实际表现出来的现象
#include<stdio.h>
2 #include<unistd.h>
3
4 int main()
5 {
6 printf("输出一遍\n");
7 fork();
8 sleep(1);
9 printf("输出两遍pid:%d,ppid:%d\n",getpid(),getppid());
10 sleep(1);
11 return 0;
12 }
执行程序,fork创建了子进程,之后的printf输出了两遍。

我们可以看到第一次输出的进程id它的父进程是bash。
第二次输出的进程id的父进程id是第一次输出的进程。
所以可以这么理解:
bash - 爷爷
第一个进程 - 儿子
第二个进程 - 孙子

通过阅读帮助文档,上面说明fork函数是有两个返回值的,返回值为当前进程的子进程id,我们将这两个返回值看一下。
#include<stdio.h>
2 #include<unistd.h>
3
4 int main()
5 {
6 printf("输出一遍\n");
7 pid_t ret = fork();
8 sleep(1);
9 printf("输出两遍pid:%d,ppid:%d,ret:%d\n",getpid(),getppid(),ret);
10 sleep(1);
11 return 0;
12 }
可以看到程序的进程通过fork创建子进程,子进程id是20044(孙子)
这个子进程没有子进程所以ret为0;

但是上面的编码不够严谨,一般多进程书写方式应该如下:用if-else语句嵌套分流。
1 #include<stdio.h>
2 #include<unistd.h>
3
4 int main()
5 {
6 pid_t ret = fork();
7 if(ret>0)
8 {
9 printf("pid:%d , ppid:%d , ret:%d\n",getpid(),getppid(),ret);
10 }
11
12 else if(ret==0)
13 {
14 printf("pid:%d , ppid:%d , ret: %d\n",getpid(),getppid(),ret);
15 }
16 else{
17 printf("fork err");
18
19 }
20 sleep(1);
21 return 0;
22 }
~

在c和c++学习过程中,if和else if是不能同时运行的,同样死循环也是同样的道理。但是在多进程中他可以运行,因为是两个执行流分别执行。
1.1 fork父子执行顺序,代码,和数据复制问题
学习进程的时候知道,进程就是可执行程序的镜像加载到内存,但是进程比可执行程序要大,原因是还有了组织管理他所用的数据结构(目前学到的task_struct)
那么创建了子进程就要在创建一组数据结构+代码+数据
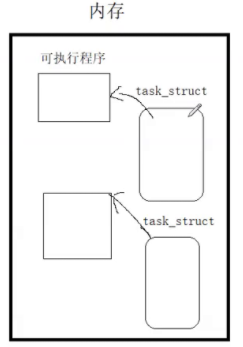
在创建子进程的时候,代码是共享的(只读),数据是自己私有的(在写时进行了拷贝)。创建完毕之后,两者穿插开始执行,没有先后顺序,具体要看调度策略和进程的优先级,比如说先来先服务,时间片轮转等。
1.2 为什么fork会有两个返回值?多进程怎么运行的?
第一个问题:
首先fork是一个函数,还是系统调用。

return id之前,函数逻辑(共享的代码)被执行完,子进程已经创建,现在已经有两个进程,依次返回自己的id(私有的数据),所以就有了两个返回值。这也正说明了进程的独立性。
注意:虽然共享了所有代码,但是由于有程序计数器(上下文)的存在,所以子进程在fork之后开始执行。
第二个问题:
cpu内部为了实现进程调动,为进程创建一个循环队列,循环队列在内存里面,运行的时候一个个加载在队列里。
1.3 为何给父进程返回pid,给子进程返回0呢?
父进程可能存在很多个子进程,所以必须通过这个返回的子进程ID来跟踪某个子进程。
而子进程只有一个父进程,父进程的ID可以通过getppid取得。这个子进程的id可以通过getpid来获取自己的id。
通过论坛可以看看大佬的回答(手动翻译)

2. 进程状态
在内核当中进程状态采用数组保存

- R运行状态(running):进程在运行当中或者在运行队列中。
- S睡眠状态(sleeping):进程在等待事件完成(也有的时候叫可中断睡眠(interruptible sleep))。
- D磁盘休眠状态(disk sleep):也叫不可中断休眠状态(uninterruptible sleep ),在这个状态通常在等待io结束。
- T停止状态(stopped): 可以通过发送SIGSTOP信号给进程来停止这个进程,这个被暂停的进程可已通过发送SIGCONT信号来让进程继续运行。
- X死亡状态(dead): 这个状态只是一个返回状态,你不会在任务列表里看到这个状态。
2.1 理解进程的各个状态
-
R状态代表正在运行状态或者处于运行队列之中
-
写一个死循环,并运行他。为什么是s状态呢,因为cpu是很快的,有printf就意味着有io要显示到控制台,导致cpu调度进程99%的时间都在等待,导致查看的时候是S状态,+代表进程在前台运行可以被ctrl+c终止。

要看到R状态,我们可以把printf语句注释掉,只进行死循环
通常在等待事件结束,结束完之后可以继续运行 -
当一个进程正在内存进行Io操作,以硬盘为例,当这个进程正在从硬盘中读数据,由于硬盘速度较慢,此时操作系统失误,或者由于内存不足,杀掉进程,致使IO出现错误,所以把一个进程设置为D状态,代表不可被中断
-
通过kill -l列出命令信息
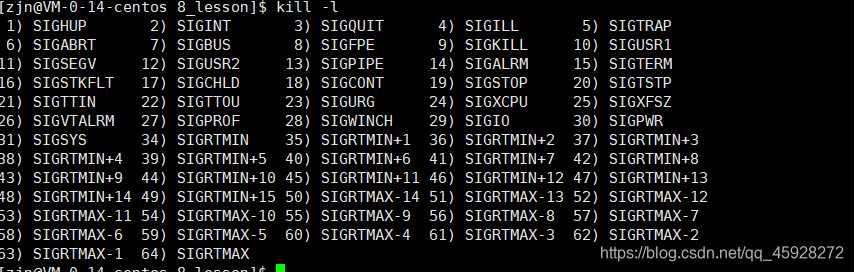
SIGSTOP命令是19号,SIGCOUT是18号。
kill -19来让它进入T状态

kill -18来让他重新运行

-
死亡状态我们看不到,一经死亡操作系统会立马回收。
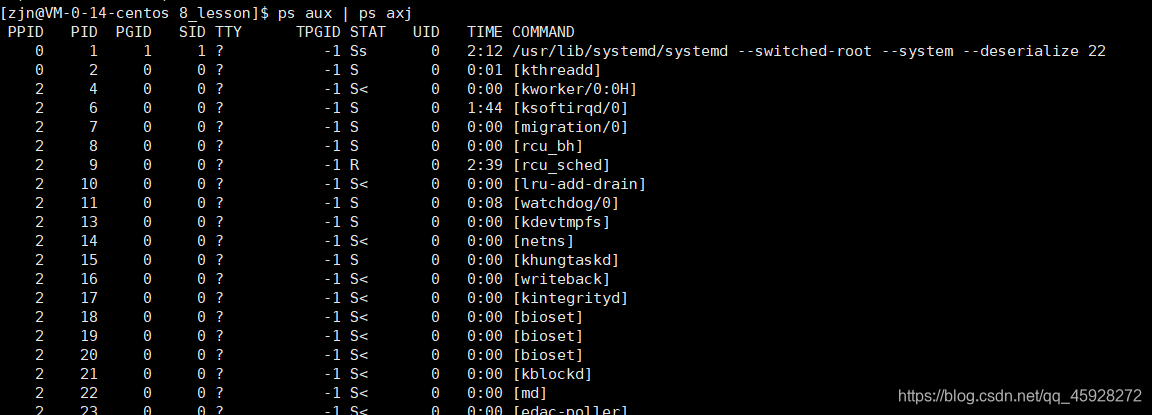
2.3 查看进程之间父子关系
ps aux | ps axj 命令
3. 僵尸进程
- 僵尸状态(zombies)是一个比较特殊的状态。当进程退出且父进程没有读取到子进程退出的返回代码时就会产生僵尸进程。
- 僵尸进程会以终止状态保持在进程表中,并且一直在等待父进程读取自己的退出代码。
- 所以只要子进程退出,父进程还在运行,但父进程没有读取到子进程退出状态的代码子进程进入Z状态。
手动写一个僵尸进程,当10s过后子进程退出,
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<stdlib.h>
4 int main()
5 {
6 pid_t ret = fork();
7 if(ret>0)
8 {
9 while(1)
10 {
11 printf("pid:%d , ppid:%d , ret:%d\n",getpid(),getppid(),ret);
12 sleep(1);
13 }
14 }
15
16 else if(ret==0)
17 {
18 int cout=0;
19 while(cout<5)
20 {
21 printf("pid:%d , ppid:%d , ret: %d\n",getpid(),getppid(),ret);
22 cout++;
23 sleep(2);
24 }
25 exit(0);
26 }
27 else{
28 printf("fork err");
29
30 }
31 sleep(1);
32 return 0;
33 }
~
~
编写一个脚本进行观察,发现子进程出现僵尸状态
while :; do ps axj | head -1 && ps axj | grep proc| grep -v grep; sleep 1 ; echo "#############"; done

3.1 为什么要有僵尸状态?
保持进程基本退出信息,方便父进程读取,获得退出原因。
一般的话,子进程处于僵尸状态,task_struct是会被保留,进程的退出信息,是放在进程控制块的。
3.2 退出码
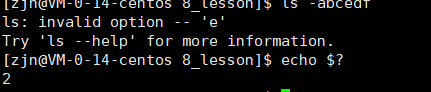
每一条命令都是一个进程,echo $?,可以显示出最近一条命令的退出码,0表示执行成功。

2表示失败
3.4 僵尸进程的危害
- 僵尸进程是保留了基本退出信息和原因。他在等待父进程读取原因,但是一直不读取呢那么子进程就会一直处于Z状态。
- 维护退出状态需要数据,也就是他也属于基本信息处于task_struct中,Z状态一直不退出,就一直需要数据去维护,那么pcb就需要一直维护他。
- 一个进程可以创建多个子进程,如果都不回收,就会造成大量资源的浪费,数据结构对象本身就是要占用内存的。
- 严重可能会导致内存泄漏
4. 孤儿进程
父进程提前退出,子进程还在,子进程就会被称为孤儿进程。
将代码简单修改一下,父进程提前退出
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<stdlib.h>
4 int main()
5 {
6 pid_t ret = fork();
7 if(ret>0)
8 {
9 int cout=0;
10 while(cout<5)
11 {
12 printf("pid:%d , ppid:%d , ret:%d\n",getpid(),getppid(),ret);
13 cout++;
14 sleep(1);
15 }
16 exit(0);
17 }
18
19 else if(ret==0)
20 {
21 while(1)
22 {
23 printf("pid:%d , ppid:%d , ret: %d\n",getpid(),getppid(),ret);
24 sleep(2);
25 }
26 }
27 else{
28 printf("fork err");
29
30 }
31 sleep(1);
32 return 0;
33 }
~
~
可以看到15540父进程退出,15541子进程还在运行

那么当15541这个进程要退出的时候,父进程由于已经退出没有办法读取返回代码,符合僵尸进程的条件变成僵尸状态。由于父进程已经退出,永远不会回收资源,造成内存泄漏。

所以os考虑了这种情况的发生,在父进程退出,子进程还在运行(子进程被称为孤儿进程)的时候重新给他找一个父亲,如图所示就是1号进程systemd。
注:操作系统是一套管理方式,由1号进程帮我们完成管理工作。
拓展:systemd与init
在以前版本1号进程是init,它有以下缺点
- 启动时间长。init进程是串行启动,只有前一个进程启动完,才会启动下一个进程。
- 启动脚本复杂。init进程只是执行启动脚本,不管其他事情。脚本需要自己处理各种情况,这往往使得脚本变得很长。
所以Systemd 就是为了解决这些问题而诞生的。它的设计目标是,为系统的启动和管理提供一套完整的解决方案。根据 Linux 惯例,字母d是守护进程(daemon)的缩写。 Systemd 这个名字的含义,就是它要守护整个系统。
Systemd 的优点是功能强大,使用方便,缺点是体系庞大,非常复杂。事实上,现在还有很多人反对使用 Systemd,理由就是它过于复杂,与操作系统的其他部分强耦合,违反"keep it simple && stupid"的Unix 哲学;但是现在的Centos 7 已经将它作为系统的守护进程组件了。
注:Kelly Johnson提出了KISS原则,指在大战中即使普通机械师也可以修理飞机,所以stupid并不是愚蠢,而是指一般人也能运用(傻瓜式操作),也有简洁,一目了然的意思。















 50
50











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











