






目录
一.wireshark抓取网络数据包(疯狂聊天室)
1.下载并打开疯狂聊天室程序
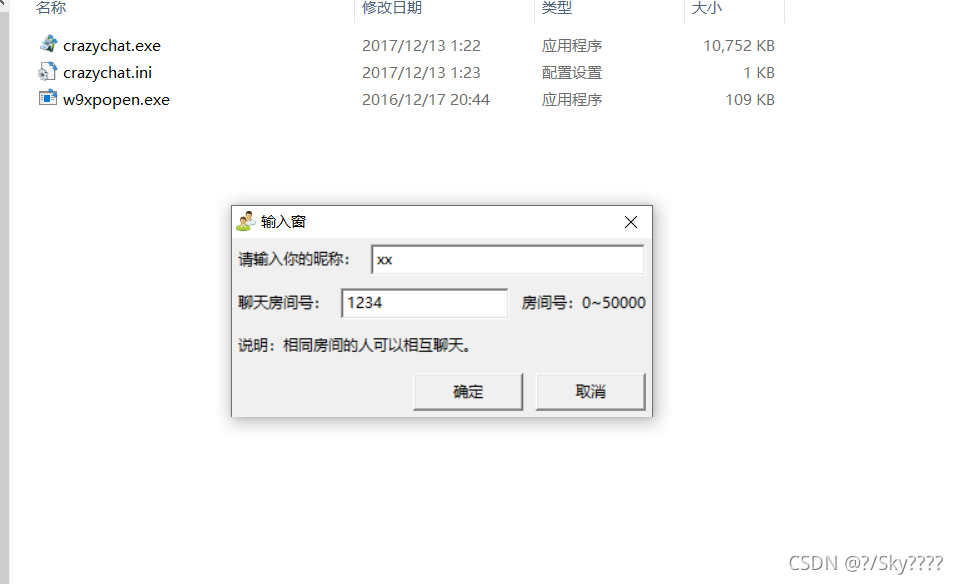
两台设备输入相同的房间号并发送信息
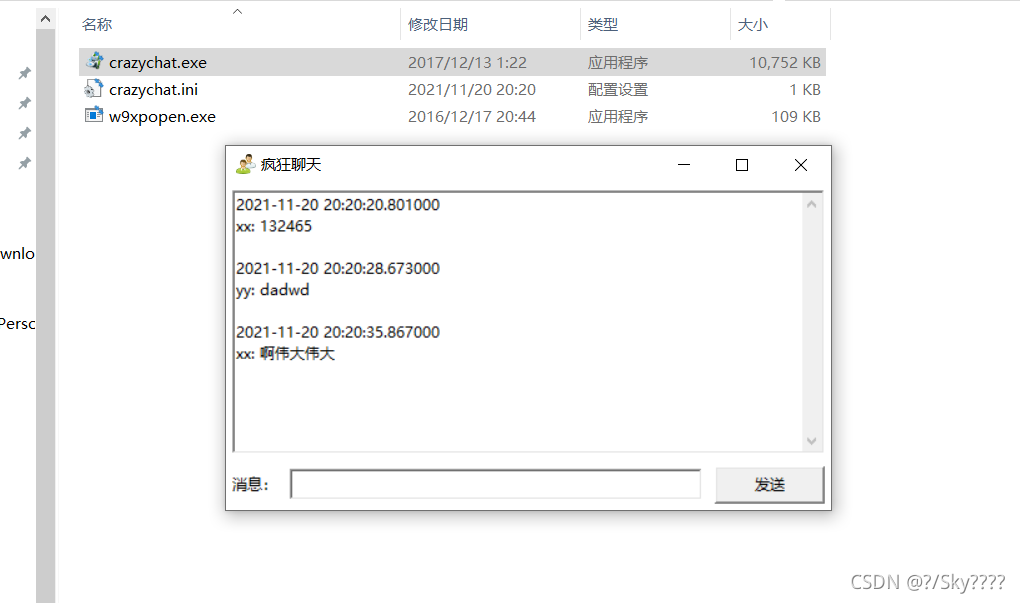
2.wireshark抓包
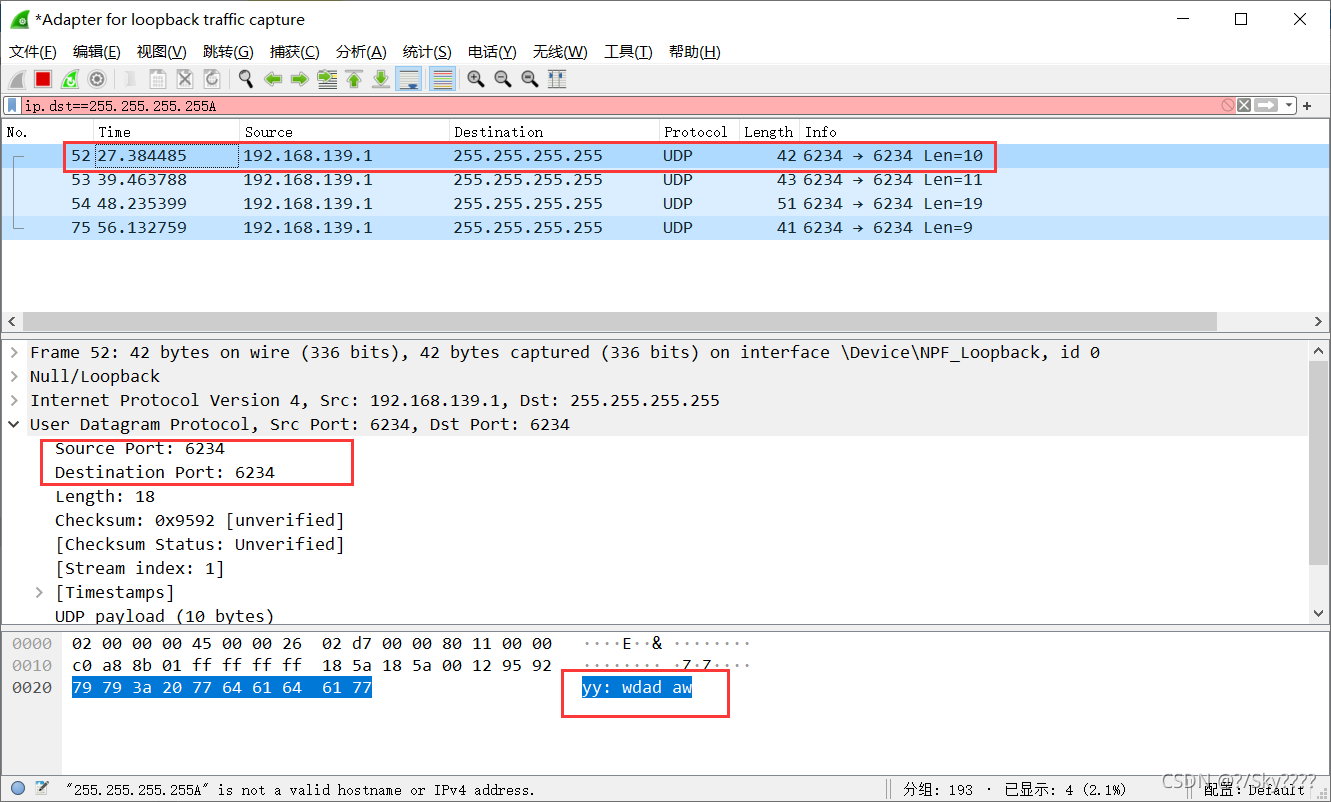
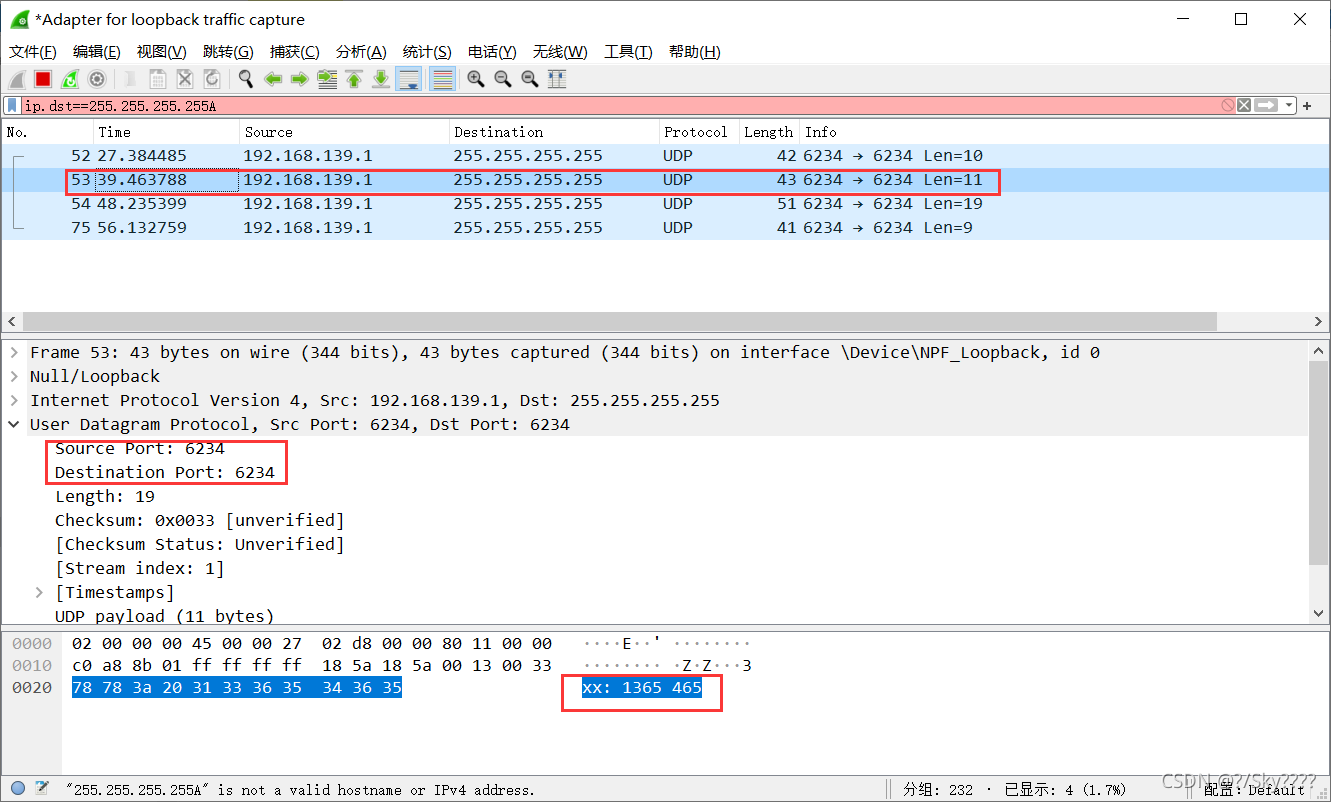
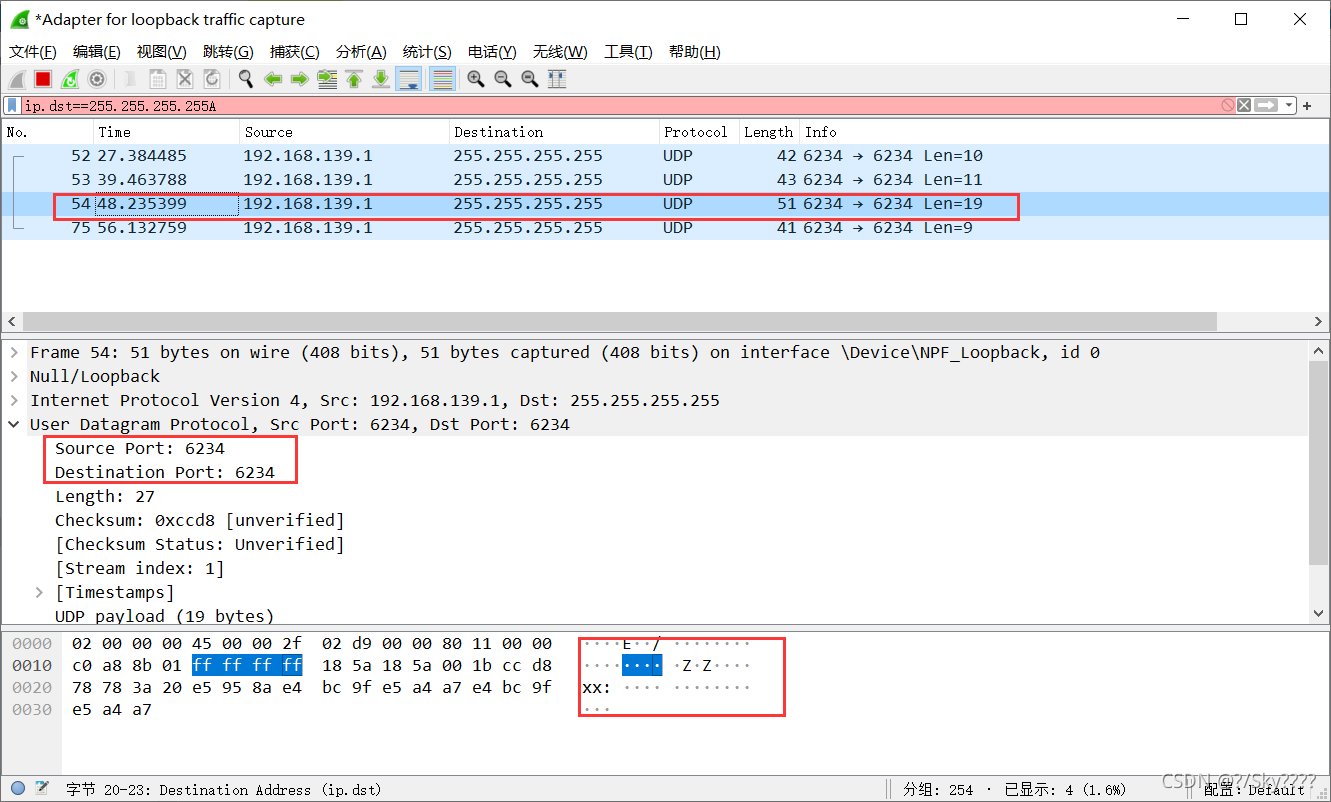
对比三条信息可以看到:
- 此程序网络连接采用的是UDP协议和6234端口号
- 发送英文和数字信息可以看到抓取的信息,但是中文信息是乱码,说明汉字可能经过了某种编码转换
二.对南阳理工学院ACM题目网站练习题目数据的抓取和保存
1.打开目标网站,查看代码
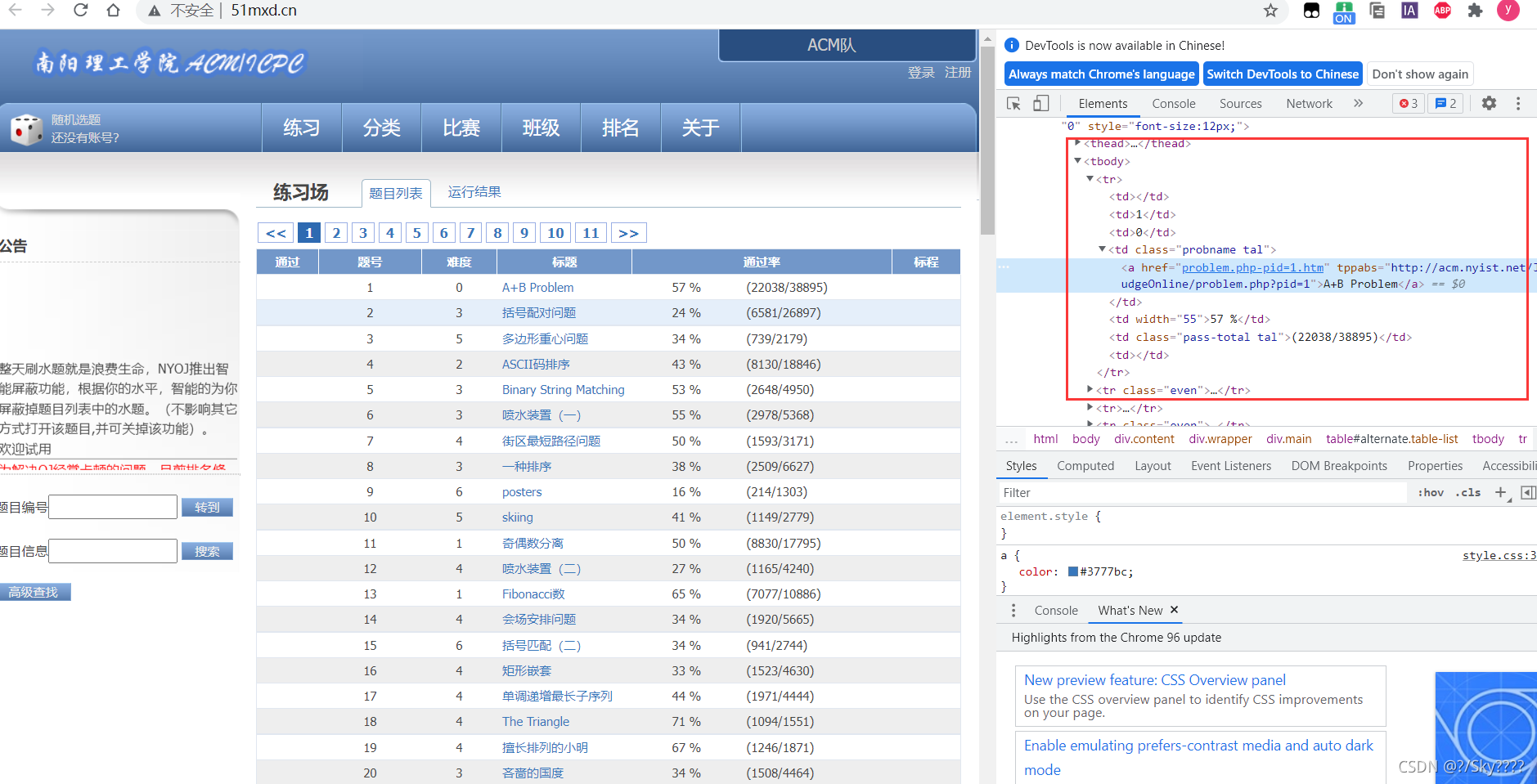
2.利用jupyter爬取
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
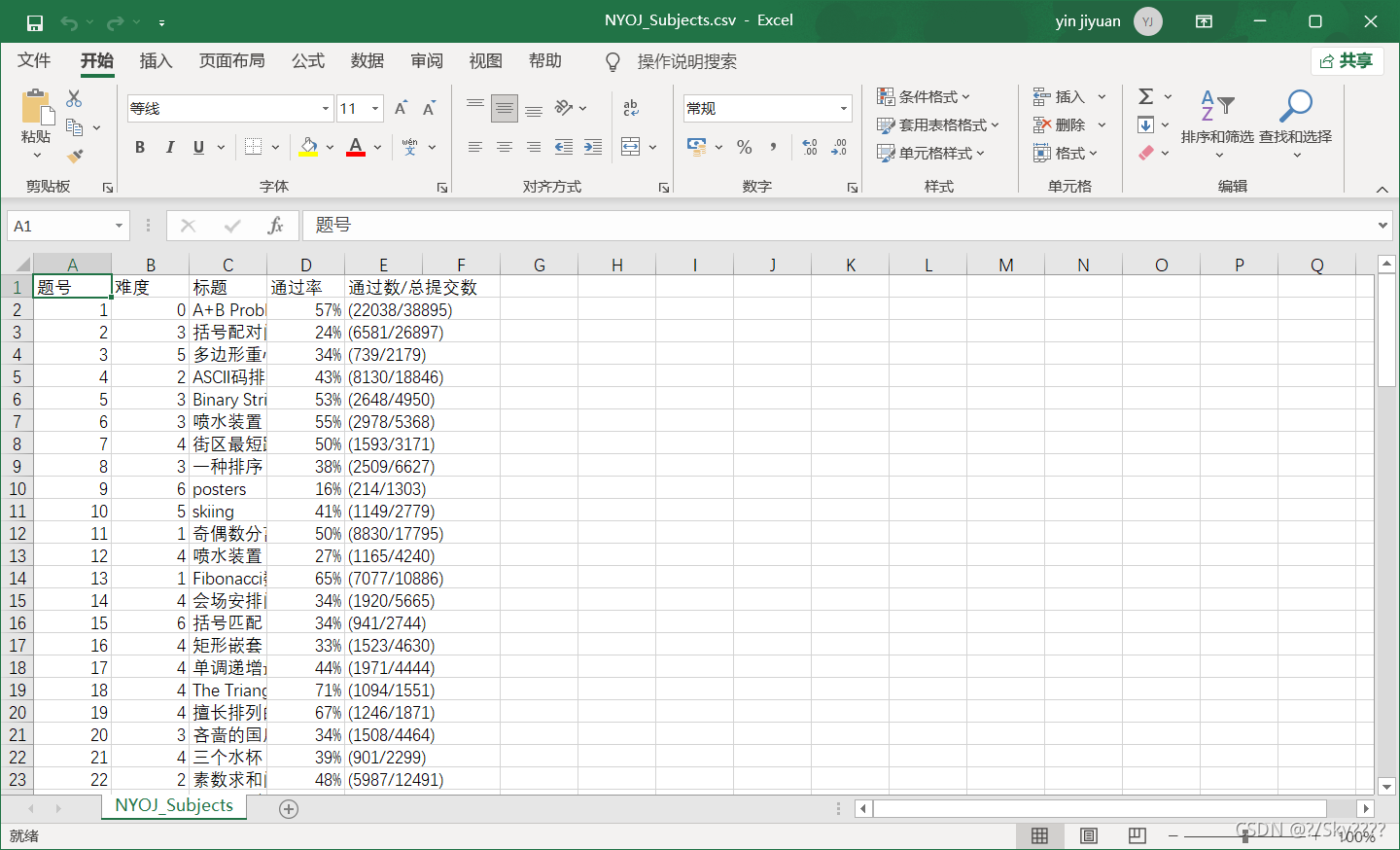
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
for pages in tqdm(range(1, 1 + 1)):
# 网址
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# 获取网页内容
r.raise_for_status()
# 编码
r.encoding = 'utf-8'
# 创建 BeautifulSoup对象
soup = BeautifulSoup(r.text, 'html5lib')
# 找到所有td标签
td = soup.find_all('td')
subject = []
for t in td:
# 一列一列的获取值组成一行
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
#存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')
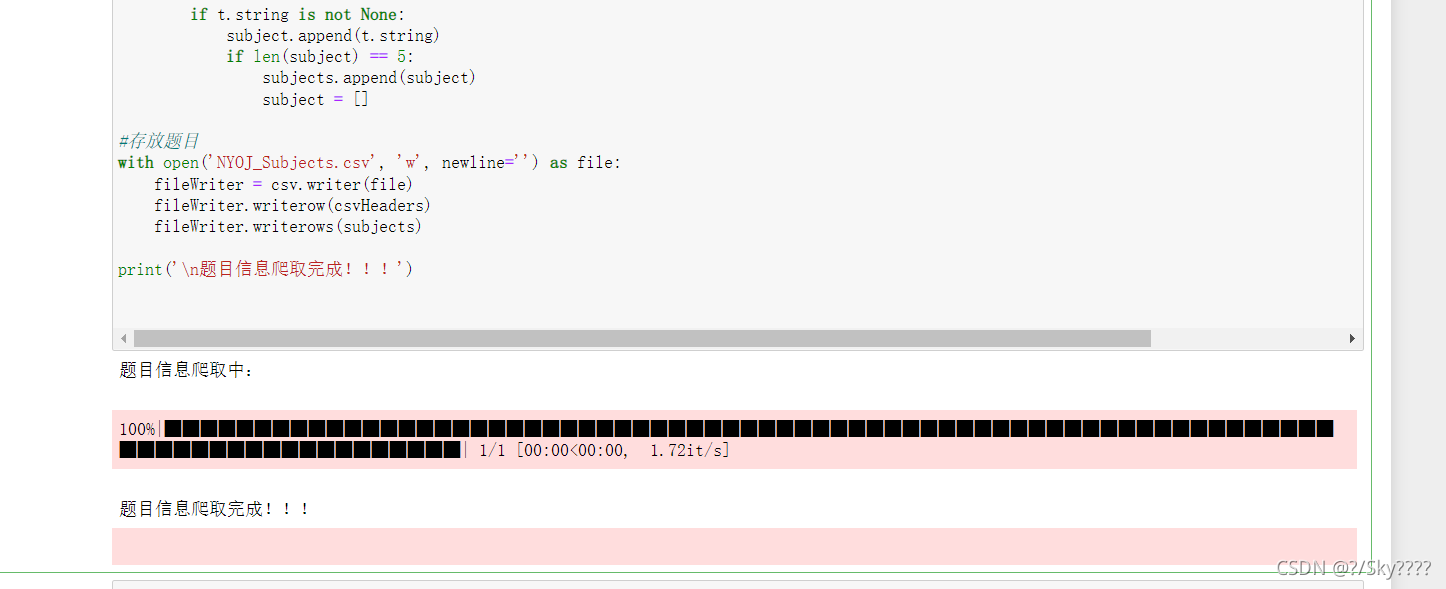
运行结果:
三.爬取重庆交通大学新闻网站中近几年所有的信息通知的发布日期和标题全部爬取下来,并写到CSV电子表格中
1.打开网站
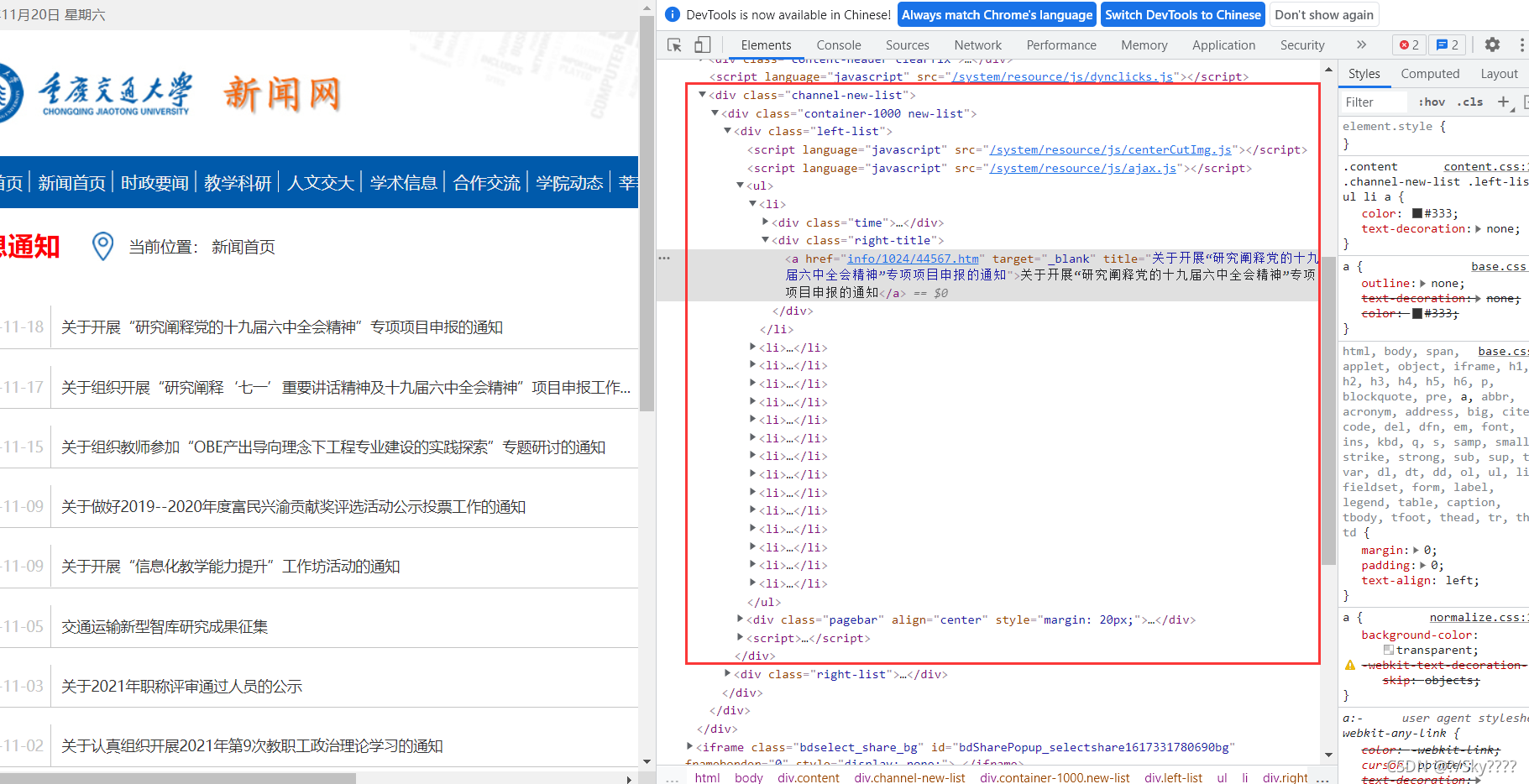
2.运行代码爬取
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
import urllib.request, urllib.error # 制定URL 获取网页数据
# 所有新闻
subjects = []
# 模拟浏览器访问
Headers = { # 模拟浏览器头部信息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53"
}
# 表头
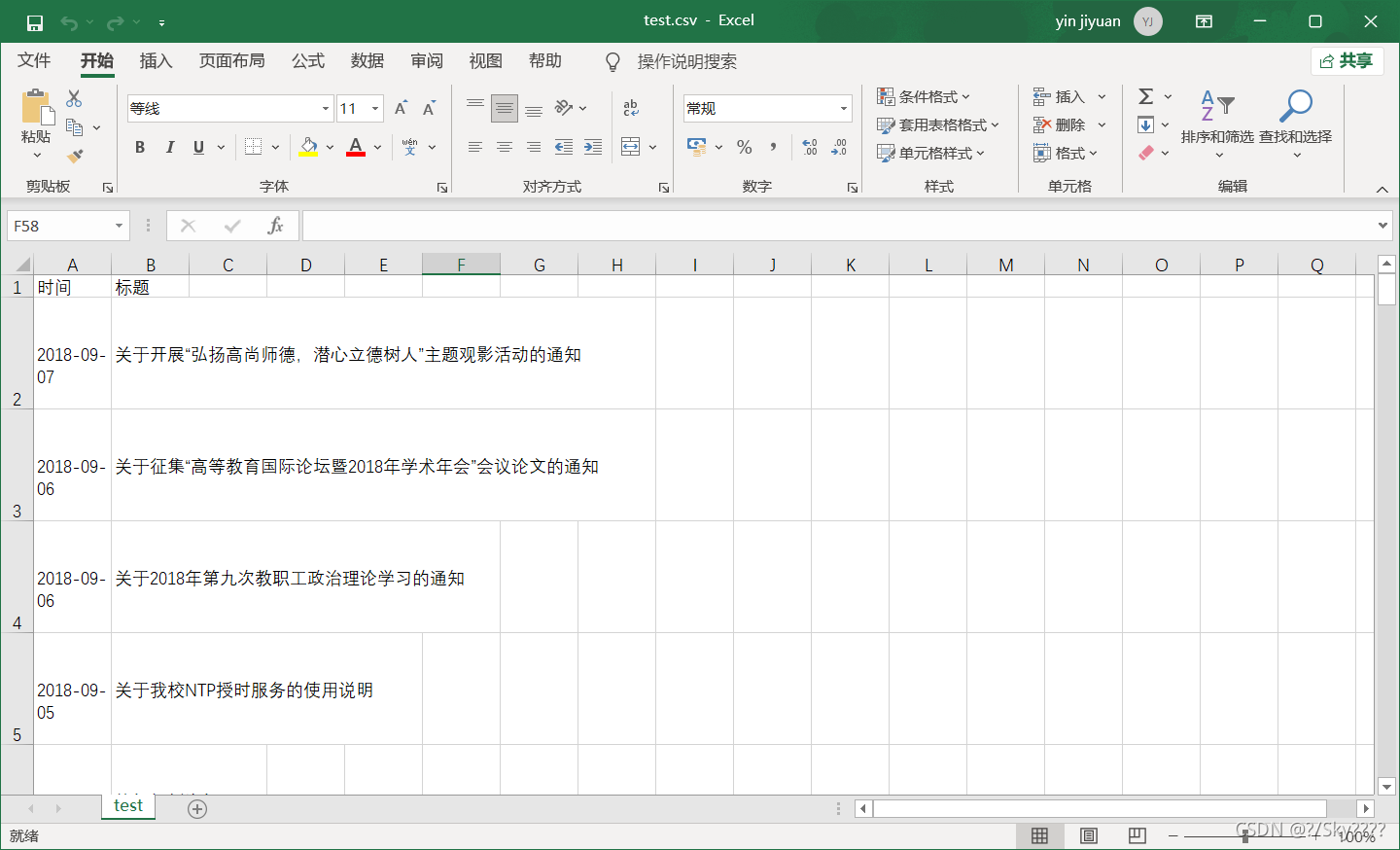
csvHeaders = ['时间', '标题']
print('信息爬取中:\n')
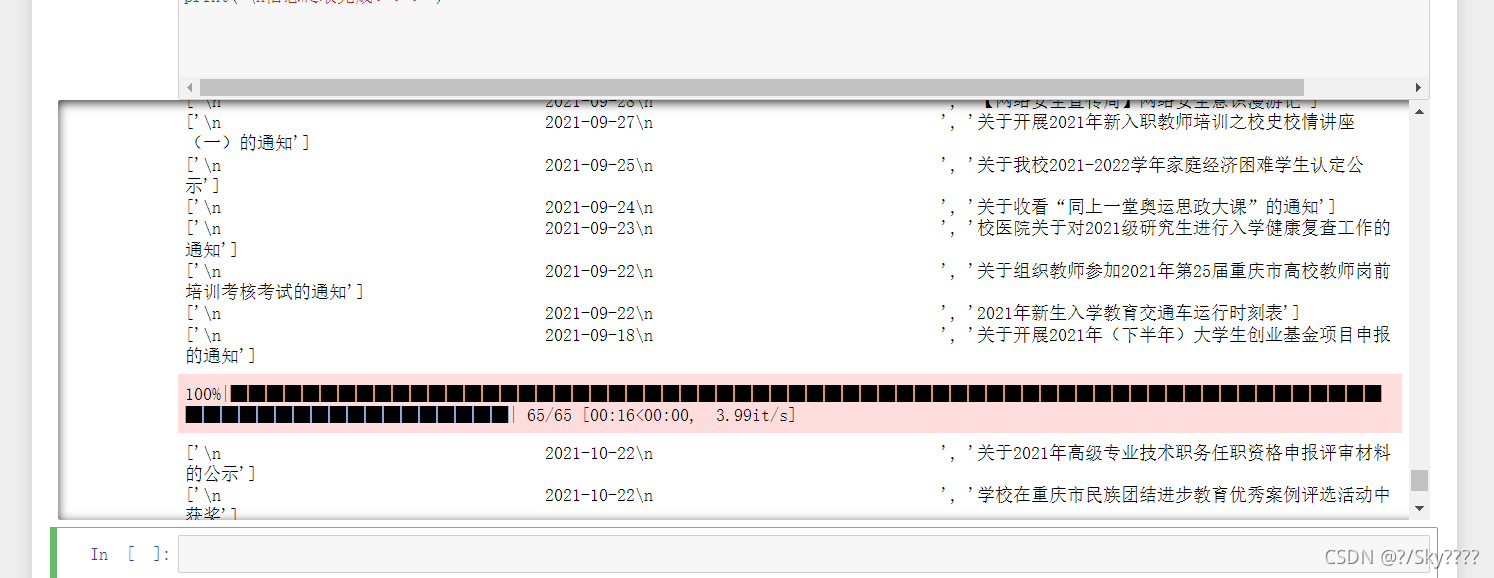
for pages in tqdm(range(1, 65 + 1)):
# 发出请求
request = urllib.request.Request(f'http://news.cqjtu.edu.cn/xxtz/{pages}.htm', headers=Headers)
html = ""
# 如果请求成功则获取网页内容
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
# 解析网页
soup = BeautifulSoup(html, 'html5lib')
# 存放一条新闻
subject = []
# 查找所有li标签
li = soup.find_all('li')
for l in li:
# 查找满足条件的div标签
if l.find_all('div',class_="time") is not None and l.find_all('div',class_="right-title") is not None:
# 时间
for time in l.find_all('div',class_="time"):
subject.append(time.string)
# 标题
for title in l.find_all('div',class_="right-title"):
for t in title.find_all('a',target="_blank"):
subject.append(t.string)
if subject:
print(subject)
subjects.append(subject)
subject = []
# 保存数据
with open('test.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n信息爬取完成!!!')
- 结果
总结
爬虫从初始网页的URL开始,获取初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放X队列,直到满足系统给定的停止条件。
参考
https://blog.csdn.net/qq_47281915/article/details/121344160
https://blog.csdn.net/m0_51120713/article/details/121379942

















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









