






OCR发票识别API实现
1. 阿里云OCR发票识别
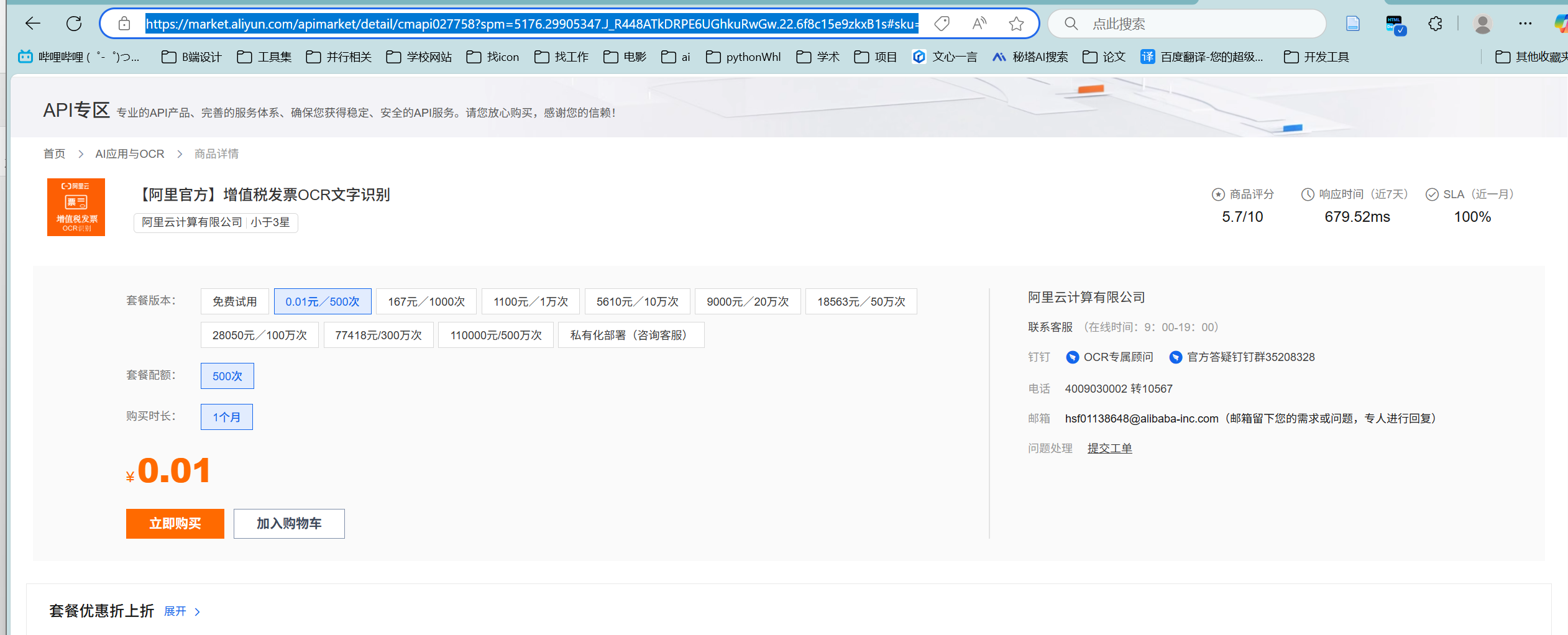
示例:
接口:https://dgfp.market.alicloudapi.com/ocrservice/invoice
参数:{"img":"图片的base64编码"}
图片转base64网址

结果:
{
"angle": 0,
"data": {
"发票代码": "",
"发票号码": "23912000000004155751",
"机打发票代码": "",
"机打发票号码": "",
"开票日期": "2023年06月19日",
"机器编码": "",
"校验码": "",
"受票方名称": "百望股份有限公司",
"受票方税号": "91110108339805094M",
"受票方地址、电话": "",
"受票方开户行、账号": "",
"密码区": "",
"不含税金额": "350.94",
"发票税额": "21.05",
"大写金额": "叁佰柒拾贰圆整",
"发票金额": "372.00",
"销售方名称": "华住酒店管理有限公司大连分公司",
"销售方税号": "91210202071550843F",
"销售方地址、电话": "",
"销售方开户行、账号": "",
"收款人": "",
"复核人": "",
"开票人": "辛梦娣",
"备注": "",
"标题": "电子发票(增值税专用发票)",
"联次": "",
"发票类型": "数电专用发票",
"特殊标识信息": "",
"发票详单": [
{
"货物或应税劳务、服务名称": "*住宿服务*住宿费",
"规格型号": "",
"单位": "天",
"数量": "1",
"单价": "350.943396226415",
"金额": "350.94",
"税率": "6%",
"税额": "21.06"
}
],
"发票代码解析": ""
},
"height": 448,
"orgHeight": 448,
"orgWidth": 660,
。。。。//省略部分
}
下一步根据将识别结果和表单字段对应,从而返回给前端。
2. Tesseract OCR
Tesseract OCR 是一款开源的文本识别(OCR)引擎。它主要用于识别图片中的文字,并将其转换为可编辑的文本。Tesseract OCR 是目前公认最优秀、最精确的开源 OCR 系统之一。
使用 Spring Boot 框架构建 RESTful API,并集成了 Tesseract OCR 引擎进行文字识别。项目地址:
3. 利用java调用大模型进行识别
基于百度智能云-千帆大模型实现
收费标准:大概0.05元/次,消耗产生自输入token和输出token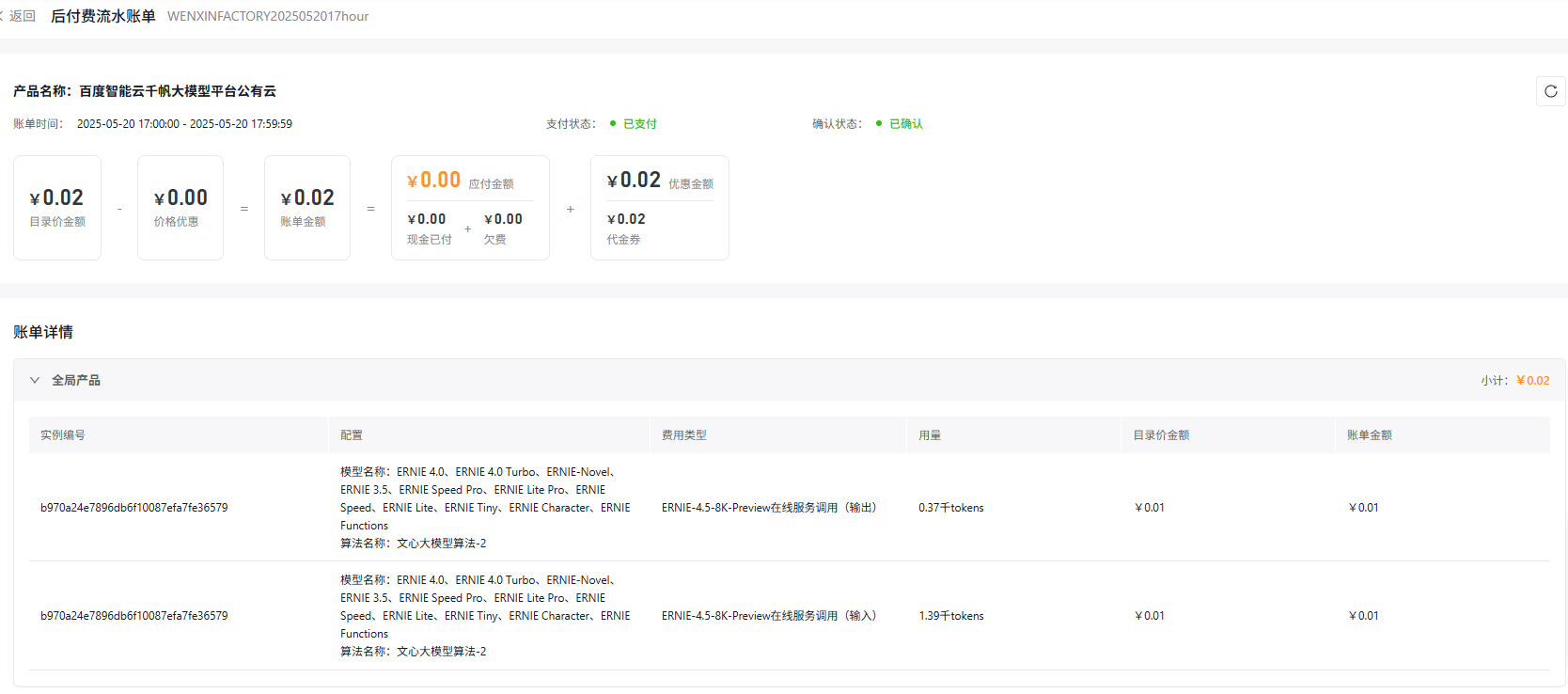
<dependency>
<groupId>com.openai</groupId>
<artifactId>openai-java</artifactId>
<version>1.6.1</version>
</dependency>
测试代码
package com.example.demo;
import com.openai.client.OpenAIClient;
import com.openai.client.okhttp.OpenAIOkHttpClient;
import com.openai.core.JsonValue;
import com.openai.models.chat.completions.ChatCompletion;
import com.openai.models.chat.completions.ChatCompletionCreateParams;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.File;
import java.io.IOException;
import java.nio.file.Files;
import java.util.*;
@SpringBootTest
class DemoApplicationTests {
@Test
void contextLoads() {
}
@Test
public void testImageUnderstanding() {
// 1. 构建客户端
OpenAIClient client = OpenAIOkHttpClient.builder()
.apiKey("bce-v3/ALTAK-xxx")
.baseUrl("https://qianfan.baidubce.com/v2/")
.build();
try {
// 2. 读取图片文件并转换为Base64
File imageFile = new File("D:\\java_project\\ocr\\demo\\src\\main\\resources\\fptest2.jpeg");
byte[] imageBytes = Files.readAllBytes(imageFile.toPath());
String base64Image = Base64.getEncoder().encodeToString(imageBytes);
// 3. 构造消息内容
List<Map<String, Object>> contents = new ArrayList<>();
// 添加图片内容
Map<String, Object> imageUrlMap = new HashMap<>();
imageUrlMap.put("url", base64Image);
Map<String, Object> imageContent = new HashMap<>();
imageContent.put("type", "image_url");
imageContent.put("image_url", imageUrlMap);
contents.add(imageContent);
// 添加文本内容
Map<String, Object> textContent = new HashMap<>();
textContent.put("type", "text");
textContent.put("text", "请分析这张发票的内容,并以JSON格式仅返回以下字段信息:\n" +
"- invoiceCode: 发票代码\n" +
"- invoiceNumber: 发票号码\n" +
"- issueDate: 开票日期\n" +
"- totalAmount: 合计金额(不含税)\n" +
"- taxAmount: 税额\n" +
"- totalWithTax: 价税合计\n" +
"- purchaserName: 购买方名称\n" +
"- purchaserTaxNumber: 购买方纳税人识别号\n" +
"- sellerName: 销售方名称\n" +
"- sellerTaxNumber: 销售方纳税人识别号\n" +
"请确保返回的JSON格式正确,所有字段名称必须完全匹配。");
contents.add(textContent);
// 4. 构造消息
Map<String, Object> message = new HashMap<>();
message.put("role", "user");
message.put("content", contents);
// 5. 构造请求参数
ChatCompletionCreateParams params = ChatCompletionCreateParams.builder()
.addSystemMessage("你是一个专业的发票识别助手。请严格按照要求的字段名称返回JSON格式的发票信息,确保每个字段的名称完全匹配,不要添加额外的字段。如果某个字段的信息无法识别,将其值设置为空字符串。")
.putAdditionalBodyProperty("messages", JsonValue.from(List.of(message)))
.model("ernie-4.5-8k-preview")
.temperature(0.7)
.maxTokens(1000)
.build();
// System.out.println(params);
// 6. 发送请求并处理响应
ChatCompletion chatCompletion = client.chat().completions().create(params);
String result = String.valueOf(chatCompletion.choices().get(0).message().content());
System.out.println("发票识别结果:");
System.out.println(result);
} catch (IOException e) {
System.err.println("图片读取失败:" + e.getMessage());
e.printStackTrace();
} catch (Exception e) {
System.err.println("API调用失败:" + e.getMessage());
e.printStackTrace();
}
}
}
识别结果1:
{
"invoiceCode": "2391200000004155751",
"invoiceNumber": "",
"issueDate": "2023年06月19日",
"totalAmount": "350.94",
"taxAmount": "21.06",
"totalWithTax": "372.00",
"purchaserName": "百望股份有限公司",
"purchaserTaxNumber": "91110108339805094M",
"sellerName": "华佳酒店管理有限公司大连分公司",
"sellerTaxNumber": "91210202071550843F"
}
识别结果2:


4. 飞桨PaddleOCR
https://gitee.com/paddlepaddle/PaddleOCR
云服务器购买
linux安装conda
环境测试
废弃方案:在云服务器上使用paddlepaddle配置ocr,失败原因:必须要有nvidia显卡环境。
测试可行方案:使用paddlex调用产品线,即可使用cpu运行。
- 根据paddlex安装在linux上安装paddlex,建议使用docker(docker安装教程及镜像加速器)。
- 根据教程,对安装命令进行了分解:
# 1. 创建并启动容器(添加端口映射 -p 8080:8080)
docker create \
--name paddlex \
-v "$PWD":/paddle \
-p 8080:8080 \ # 添加端口映射
--shm-size=8g \
--network=host \
-it \
ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/paddlex:paddlex3.0.0rc1-paddlepaddle3.0.0-cpu \
/bin/bash
# 2. 启动容器
docker start paddlex
# 3. 进入容器
docker exec -it paddlex /bin/bash
# 4. 安装 OCR 依赖(如果尚未安装)
pip install "paddlex[ocr]"
# 5. 验证挂载目录
ls -l /paddle
# 6. 上传测试文件,切换到paddle目录,运行以下命令
paddlex --pipeline OCR --input general_ocr_002.png --device cpu
更多使用方式参照官方链接
将ocr进行服务化部署:
# 1. 创建并启动容器(添加端口映射 -p 8080:8080)
docker create \
--name paddlex \
-v "$PWD":/paddle \
-p 8080:8080 \ # 添加端口映射
--shm-size=8g \
--network=host \
-it \
ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/paddlex:paddlex3.0.0rc1-paddlepaddle3.0.0-cpu \
/bin/bash
# 2. 启动容器
docker start paddlex
# 3. 进入容器
docker exec -it paddlex /bin/bash
# 4. 安装 OCR 依赖(如果尚未安装)
pip install "paddlex[ocr]"
paddlex --install serving
# 5. 验证挂载目录
ls -l /paddle
# 6. 运行 OCR 服务(绑定到 0.0.0.0)
paddlex --serve --pipeline ocr --host 0.0.0.0 --port 8080
验证步骤
检查容器状态:
docker ps -a
确认端口映射:
docker port paddlex
构建自定义镜像(长期使用建议):
目录结构:
paddlex-ocr/
├── Dockerfile # 镜像构建指令
├── models/ # (可选)预下载的模型文件
└── requirements.txt # (可选)额外的 Python 依赖
创建一个专门用于存放镜像构建文件的目录:
mkdir paddlex-ocr && cd paddlex-ocr
在该目录下创建 Dockerfile
FROM ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/paddlex:paddlex3.0.0rc1-paddlepaddle3.0.0-cpu
# 预先安装 OCR 依赖
RUN pip install "paddlex[ocr]"
# 安装 PaddleX Serving 组件
RUN paddlex --install serving
# 设置工作目录
WORKDIR /paddle
# 暴露服务端口
EXPOSE 8080
# 保持容器运行并进入 bash
ENTRYPOINT ["/bin/bash"]
在 paddlex-ocr 目录下执行构建命令,构建并运行:
docker build -t paddlex-ocr .
# 选项说明:
# -t paddlex-ocr:指定镜像名称为 paddlex-ocr
# .:指定构建上下文为当前目录(即 paddlex-ocr/)
docker run -it --name paddlex -p 8080:8080 -v "$PWD":/paddle paddlex-ocr
# 选项说明:
# 使用 -it 选项确保容器以交互模式运行
# -p 8080:8080:将容器的 8080 端口映射到主机的 8080 端口
# -v "$PWD":/paddle:将当前目录挂载到容器的 /paddle 目录
# 在容器内执行
# paddlex --serve --pipeline {产线名称或产线配置文件路径} [{其他命令行选项}]
paddlex --serve --pipeline OCR --host 0.0.0.0 --port 8080
# 启动容器
docker start paddlex
# 进入容器
docker exec -it paddlex /bin/bash
使用python调用OCR服务:
import base64
import requests
API_URL = "http://47.108.66.45:8080/ocr"
file_path = "./fptest1.png"
with open(file_path, "rb") as file:
file_bytes = file.read()
file_data = base64.b64encode(file_bytes).decode("ascii")
payload = {"file": file_data, "fileType": 1}
response = requests.post(API_URL, json=payload)
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["ocrResults"]):
print(res["prunedResult"])
ocr_img_path = f"ocr_{i}.jpg"
with open(ocr_img_path, "wb") as f:
f.write(base64.b64decode(res["ocrImage"]))
print(f"Output image saved at {ocr_img_path}")
fptest1.png:

使用ocr得到的识别结果为:
['电子发票', '(增值税专用发票)', '发票号码:23912000000004155751', '开票日期:2023年06月19日', '共进市税务局', '购买方信', '名称:百望股份有限公司', '名称:华住酒店管理有限公司大连分公司', '方', '社会信用代码/纳税人试别号:91110108339805094M',
'统一社会信同代码/纳税人识别号:91210202071550843F', '', '项目名称', '规格型号', '住宿服务*住宿费', '团', '开', '童', '单价', '金额', '税率/征收率', '税额', '?', '350. 943396226415', '60098', '49', '21.06', 'R', '1605C', 'TZA', '价税合计(大写)', '叁佰柒拾贰圆整', '(小写)V372.00', '7', '开票人:辛梦娣']
可以发现结果对应较差,可以将上述结果送入大模型进行矫正。收费的方案不再赘述,可参照上述java调用大模型。免费方案为飞桨星河模型部署,可在其中部署一个免费的模型使用(没有多模态模型,因此必须配合ocr使用,没有大模型方案丝滑,但免费)。
# pip install openai
from openai import OpenAI
client = OpenAI(
api_key="3c15041478b648182e4b040839ffb944892a3808",
base_url="https://api-c2l9p9z6j233f2e2.aistudio-app.com/v1"
)
OCR_RES = """['电子发票', '(增值税专用发票)', '发票号码:23912000000004155751', '开票日期:2023年06月19日', '共进市税务局',
'购买方信', '名称:百望股份有限公司', '名称:华住酒店管理有限公司大连分公司', '方',
'社会信用代码/纳税人试别号:91110108339805094M', '统一社会信同代码/纳税人识别号:91210202071550843F', '',
'项目名称', '规格型号', '住宿服务*住宿费', '团', '开', '童', '单价', '金额', '税率/征收率', '税额', '?',
'350. 943396226415', '60098', '49', '21.06', 'R', '1605C', 'TZA', '价税合计(大写)', '叁佰柒拾贰圆整',
'(小写)V372.00', '7', '开票人:辛梦娣']"""
prompt = f"""请分析{OCR_RES}的内容,并以 JSON 格式仅返回以下字段信息:
invoiceCode:发票代码
invoiceNumber:发票号码
issueDate:开票日期
totalAmount:合计金额(不含税)
taxAmount:税额
totalWithTax:价税合计
purchaserName:购买方名称
purchaserTaxNumber:购买方纳税人识别号
sellerName:销售方名称
sellerTaxNumber:销售方纳税人识别号
请确保返回的 JSON 格式正确,所有字段名称必须完全匹配。
"""
completion = client.chat.completions.create(
model="deepseek-r1:70b",
temperature=0.6,
messages=[
{"role": "user", "content": prompt}
],
stream=True
)
for chunk in completion:
if hasattr(chunk.choices[0].delta, "reasoning_content") and chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)
else:
print(chunk.choices[0].delta.content, end="", flush=True)
结果
{
"invoiceCode": "",
"invoiceNumber": "23912000000004155751",
"issueDate": "2023-06-19",
"totalAmount": 350.94,
"taxAmount": 21.06,
"totalWithTax": 372.00,
"purchaserName": "百望股份有限公司",
"purchaserTaxNumber": "91110108339805094M",
"sellerName": "华住酒店管理有限公司大连分公司",
"sellerTaxNumber": "91210202071550843F"
}
更新:使用paddlex文档场景信息抽取v4产线使用教程及PP-ChatOCRv4 产线使用教程整合了ocr+LLM进行识别的功能,并且目前(2025/05/21)是免费。但只能用python环境和代码,可以将其部署为服务,供其他语言调用。项目代码地址


















 1482
1482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











