






需求是一个导出的接口,但生成excel并不是在当前服务,而是需要将数据传给文件服务,由文件服务来生成文件。
feign接口大概长这样:
@PostMapping({"/xxx"})
Resp<Object> 方法名(@RequestBody Req req);
该接口是一个多sheet导出接口,入参中包含如下代码用来存储每个sheet的数据:
@ApiModelProperty("数据")
private Map<Integer, List<Map<String, Object>>> mapData = Maps.newHashMap();
测试环境是十五万条数据的时候,就会出问题了。单节点JVM配置是 -Xmx1433m -Xms1433m -Xmn530m。
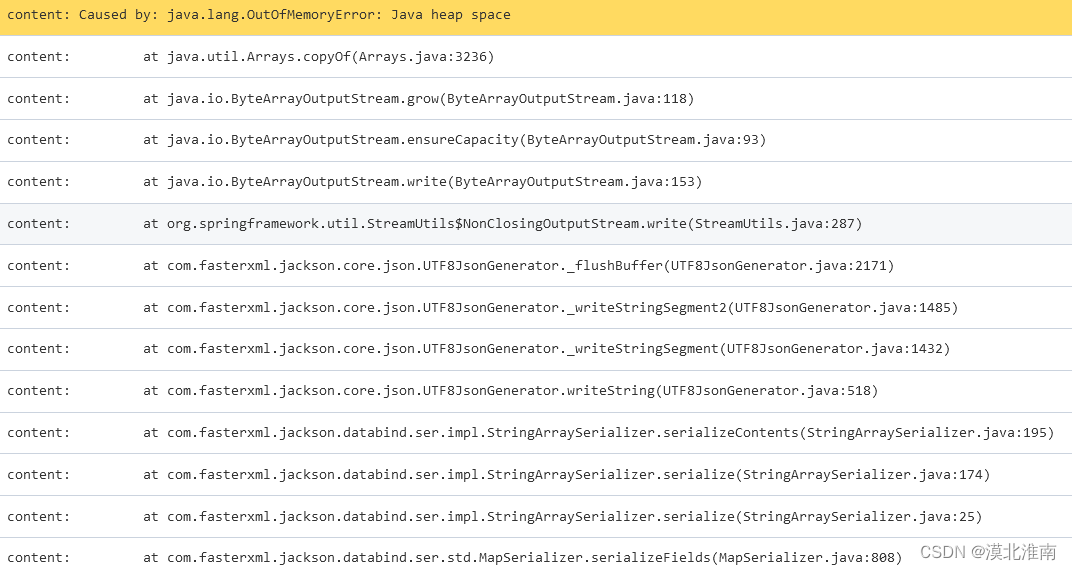 暂时想到的解决办法如下:
暂时想到的解决办法如下:
1.增大JVM配置。(治标不治本)
2.和产品以及业务沟通,看能否接受分批导出。本来是生成一个excel文件,其中三个sheet页-》三个excel文件三个sheet页。
3.文件服务提供新的接口,能够支持续传功能(类似断点续传),即通过添加标识位等方式,能够将多次调feign接口的数据生成为一个excel文件。
4.不再调用文件服务生成excel,而是由当前服务生成excel后,以文件的形式传给文件服务(由文件服务上传oss,并在下载中心显示)
OOM原因猜测:(因为菜,分析不出来具体原因哈哈)
1.序列化Map好像是会在内存中分配一串连续的空间。(之前不记得看的哪个文章说的,不确定正确性)
2.@RequestBody 会调用System.arraycopy()方法,导致占用内存翻倍。
好希望有大佬指点一下,根本原因是啥。
····································································分割线···············································································
解决问题了。凭借我的聪明智慧,在不增加任何接口和需求的情况下,解决了该问题。当然错误原因全靠猜,如果不对请佬们指点指点。
猜测原因出现在接口入参的数据结构上。也就是:
Map<Integer, List<Map<String, Object>>> mapData = Maps.newHashMap();
看着很合理,翻译一下Map<sheet的序号, sheet中的数据<Map<某一列, 某个值>>> mapData = Maps.newHashMap();
然后开发的小伙伴对于sheet的数据赋值Map<String, Object>是这么写的,
private static <T> Map<String, Object> getObjectMap(T t, Class<?> cls) {
Map<String, Object> objectMap = new HashMap<>();
Field[] fields = cls.getDeclaredFields();
try {
for (Field field : fields) {
ReflectionUtils.makeAccessible(field);
objectMap.put(field.getName(), field.get(t));
}
} catch (IllegalAccessException ignored) {
log.error("属性获取值错误" + ignored);
}
return objectMap;
}
有什么问题呢,乍一看没有问题。但如果我的field字段是一个数组,它会变成什么样呢-》
Map<sheet的序号, sheet中的数据List<Map<某一列, arr[]>>>
众所周知,导出通常都是几万几十万甚至上百万。这个arr[]是不是有点太勉强jvm了。还是那句话,数组会要求内存中连续的空间来存储(不记得从哪里看的了)。要求太高了,一下把jvm干蒙了。
当我尝试将数组toString一下再放进去就发现没有问题了。
诶就很奈斯,当然,即使换成字符串仍然很极限,因为当我用StringUtils.join去转字符串的时候,他还是溢出了。这个没得办法,只能减小数据量了。
其次我干了第二个操作,这个Field[],我不确定是不是每次调用都会创建新的Field对象(查百度有的说会,有的不提),但不管会不会新建field对象,我认为都应该将它缓存起来。而不是每次都重新获取一遍这个class的所有field。
最后的解决方式总结:如果入参的结构套了太多层,能不用数组和集合的就转一下。用反射的时候,要注意避免多次加载同一个类的内容,本来反射性能就低,咱就别霍霍JVM了。















 1628
1628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









