







mysql的聚簇索引和非聚簇索引
1.一个表中只能有一个索引吗?
可以按照需求来创建多个索引,但不要太多。
2.每一个索引是一棵B+树,还是所有的索引共用一棵B+树?
一个索引一棵B+树。
3.如果有多棵B+树的话,那么数据存储几份?
1份。
在innodb存储引擎中,数据在进行插入的时候需要跟某一个索引列绑定在一起,这个索引列如果有主键,那么使用主键,如果 主键,那么用唯一键,如果没有唯一键,那么使用6字节的rowid
innodb:既有聚簇索引也有非聚簇索引。
myisam:只有非聚簇索引。
主键索引和非主键索引的区别?
相同点:都是使用的B+Tree。
不同点:叶子节点存储的数据不同。主键索引的叶子节点存储的是一行完整的数据;而非主键索引的叶子节点存储的是主键值。叶子节点不包含记录的全部数据。
使用主键索引查询:select * from user where id = 1,主键索引的叶子节点存储的是一行完整的数据,所以只需要搜索主键索引的B+Tree就可以轻松找到全部数据。
使用非主键索引查询:select * from user where name = ‘Jack’;非主键索引的叶子节点存储的是主键值,所以MySQL会先查询到name列的索引的B+Tree,搜索得到对应的主键值,然后再去搜索该主键值查询主键索引的B+Tree才可以找到对应的数据。
可以看出来,非主键索引要比主键索引多使用一次B+Tree。多使用的这次B+Tree其实就是回表。
什么叫做回表?
比如说现在有一个表,这个表有几个属性,分别是id,name,age,gender; id是主键,而name是普通索引;
现在我们执行一个查询语句select * from table where name = “zhangsan”;这个查询语句的执行过程是什么呢?先根据name到nameB+树找到对应叶子节点的id值,然后再根据id到idB+树读取整行记录,这种查询方式叫做回表,效率比较低,不推荐使用。
如果有很多回表的话,有时候你虽然是查询的条件为name="zhangsan"的行,但是由于回表原因,导致你的查询效率极低,所以它有可能比你全表查询的效率还要低。
什么叫做索引覆盖?
假设你定义一个联合索引,CREATE INDEX idx_name_age ON user(name,age);查询名称为 liudehua 的年龄:mysql> select name, age from user where name = ‘liudehua’;上述语句中,查找的字段 name 和 age 都包含在联合索引 idx_name_age 的索引树中,这样的查询就是覆盖索引查询。索引覆盖的效率比较高,推荐使用。其实通俗一点讲就是,把我们要查询的所有的字段都放到一个联合索引里面,这样我们我们就需要查询一个索引B+树就行了,就不用再进行回表查询其他的索引B+树了,效率比较高,推荐使用。
什么叫做最左匹配?
就是最左优先,以最左边的为起点,任何连续的索引都能匹配上。同时遇到范围查询(>,<,between,like)就会停止匹配,也就是时说,如果你的联合索引左边的元素使用了范围查询,那么你建立的这个联合索引就是一个无效的索引,因为我们查询数据的时候不再会使用这个联合索引。
因为索引的底层是一颗B+树,联合索引的键值数量不是一个,而是多个。但是构建一棵二叉树只能根据一个值来构建,因此数据库依据联合索引最左的字段来建立B+树。
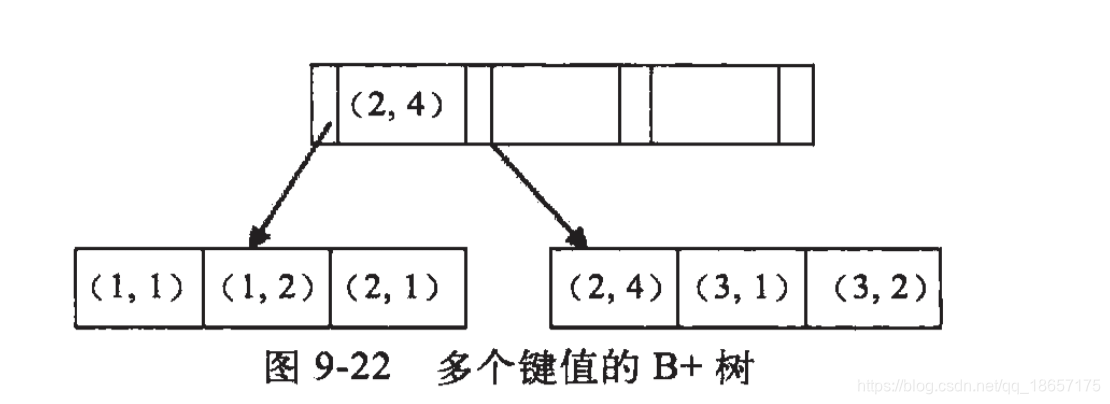
举个例子:假如创建一个(a,b)的联合索引,那么它的索引树是这样的如下图:
可以看到a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。所以b=2这种查询条件没有办法利用索引,因为联合索引首先是按a排序的,b是无序的。
同时我们还可以发现在a值相等的情况下,b值又是按顺序排列的,但是这种顺序是相对的。所以最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。例如a=1 and b=2 a,b字段都可以使用索引,因为在a值确定的情况下b是相对有序的,而a>1 and b=2,a字段可以匹配上索引但是b字段不可以,因为a的值是一个范围,在这个范围中b是无序的。所以这个时候你的联合索引还是用不上的。
因此我们在使用联合索引的时候,一定要使用最左匹配原则,筛选条件先用最左边的字段,并且如果有多个联合索引筛选,最左边的那个筛选字段不要使用范围查询,要不然的话我们的的联合索引就不会被使用到。

















 973
973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











