







Netty入站和出站的时候一定要对message消息进行解码和编码操作
应用程序往网络冲刷的数据不进行编码处理就不能成功冲刷
Netty入站和出站的时候一定要对message消息进行解码和编码操作,要确保消息从应用程序流入网络的时候被编码成了二进制,以及消息从网络流入应用程序的时候要确保二进制被解码成了正确的类型。
因为我们的数据在网络中一定是通过二进制的形式传输的,因此我们如果仅仅冲刷数据,比如说冲刷一个字符串,那么这个数据是不能被冲刷到网络中的,会冲刷失败,后续我们服务器端是读取不到的。
比如说假如我们的客户端没有写编解码处理器,如下图:
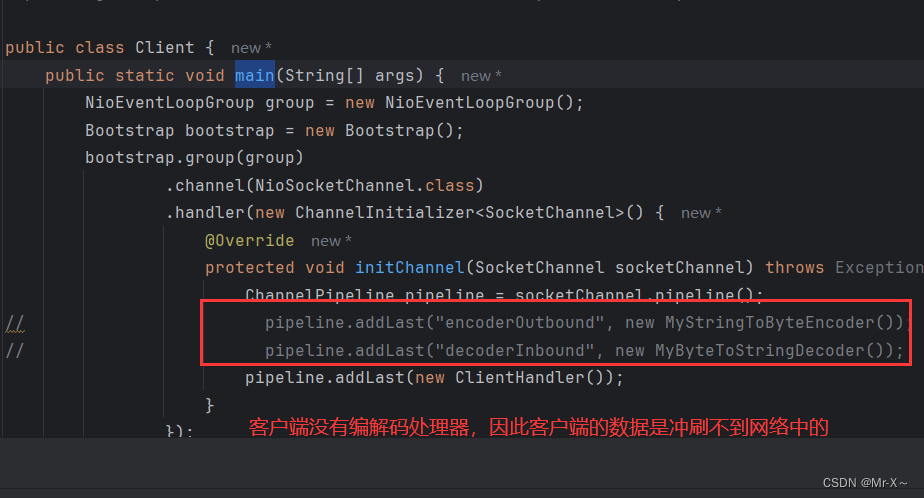
再看下客户端往网络中冲刷的数据,如下图:
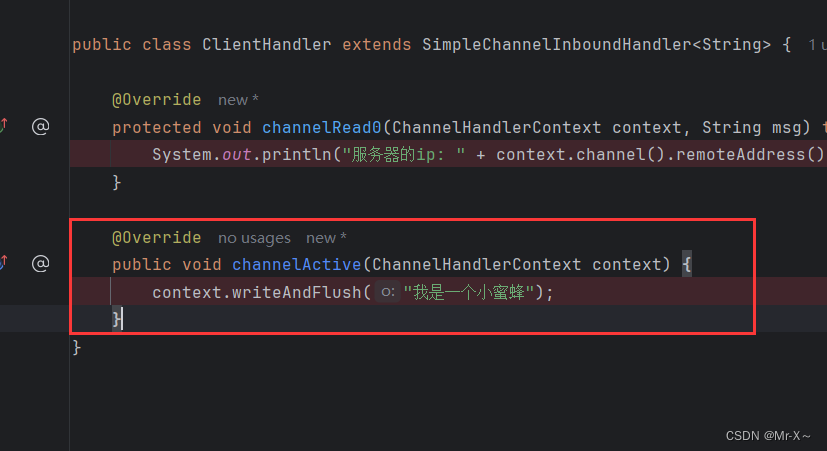
因为客户端往网络中冲刷数据的时候没有进行二进制编码,因此客户端是不能成功的把数据冲刷到网络中。那么也就是说,在我们服务端通过ChannelHandler处理器的channelRead0方法读取数据的时候就读取不到,如下图:
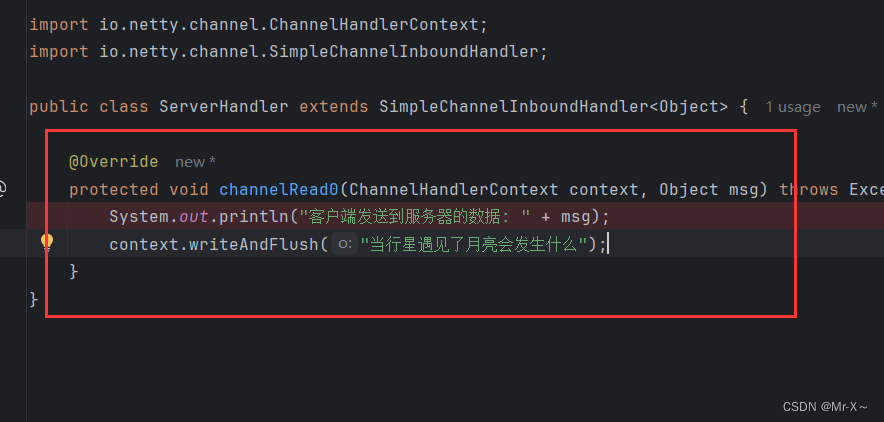
上面的这个方法就进不来。
既便客户端冲刷数据的时候使用了编码处理器,如果服务器解码的时候解码生成的对象类型和channelRead0方法里的对象类型不一致,那么channelRead0方法也进不来
比如现在给客户端加上一个编码处理器如下图:
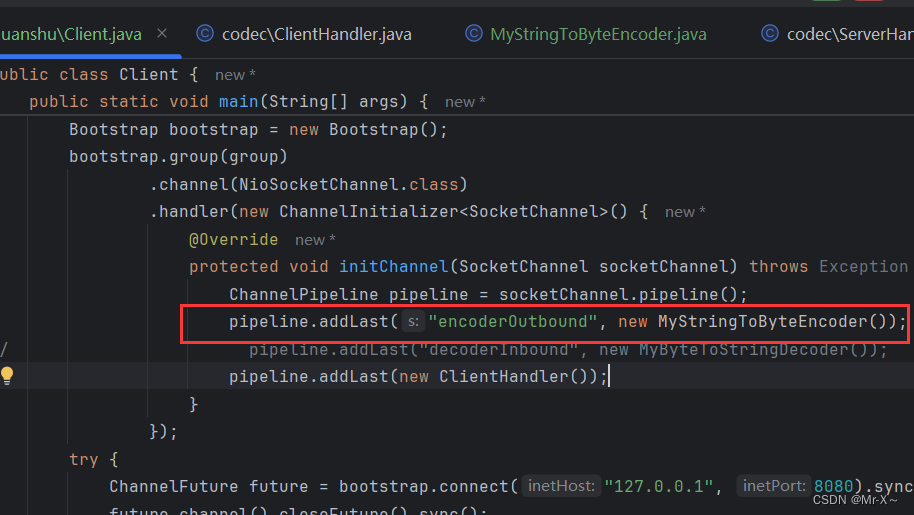
然后编码处理器是把String字符串类型转换为二进制 如下图:
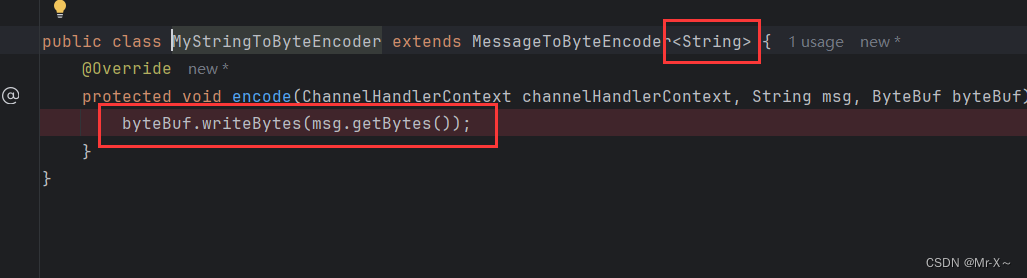
这样能保证客户端的字符串数据能够成功的冲刷到网络中,因为冲刷之前客户端把数据转换成了二进制的形式;
然后再在服务器端加一个解码处理器,这个处理器可以把从网络中读取的二进制数据转换成字符串数据,如下图:
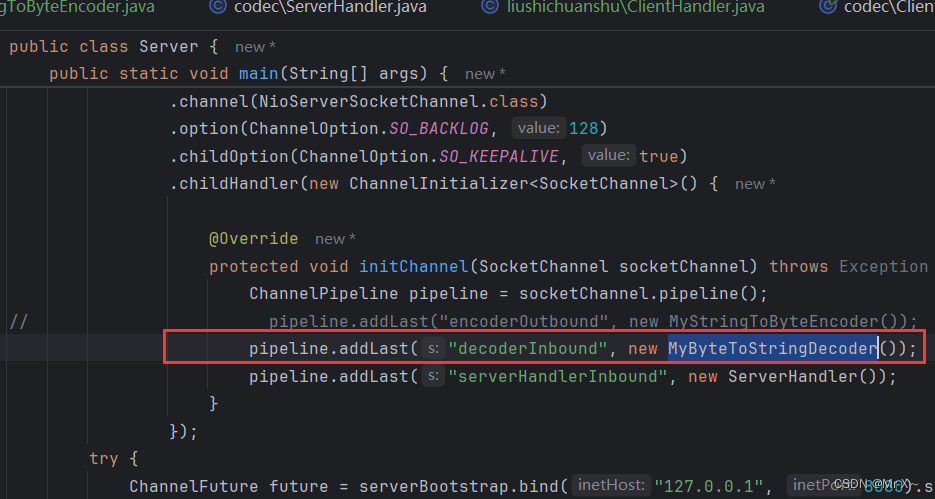
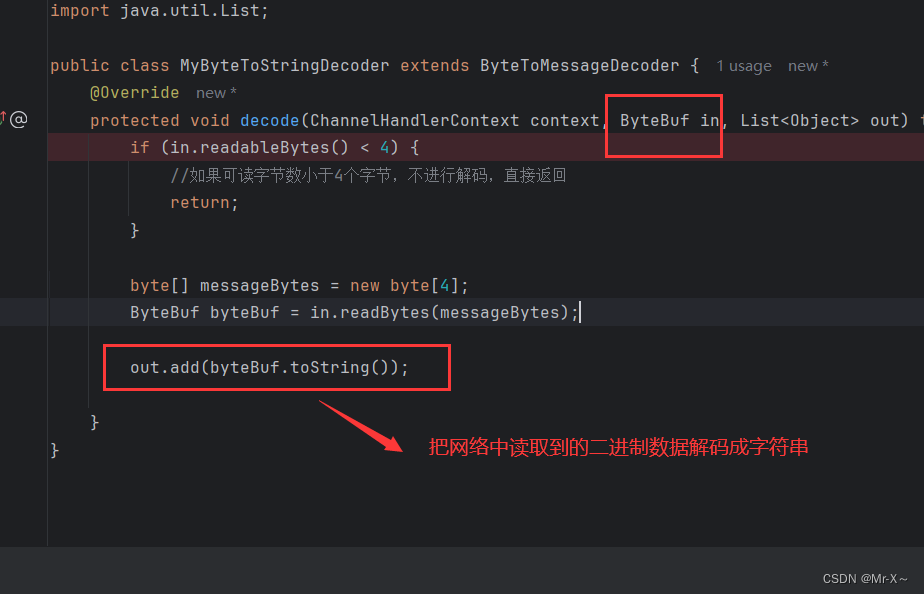
按道理来说,我在服务器端已经把网络中读取来的数据解码成了字符串,所以应该可以成功的被责任链中的后续节点ChannelHandler中的处理器的channelRead0方法读取到了,但是真的未必,如果解码处理器的解码对象类型,和channelRead0中的对象类型不一致的话,比如服务器的解码处理器是把网络中的二进制数据转换成了String类型,但是此时后续责任链中的ChannelHandler处理器中的channelRead0方法的参数对象却是Long类型,二者数据类型不一致,那么服务器解码处理器处理之后并不能够传送给下一个ChannelHandler节点处理,那么也就进入不到channelRead0方法了。看下参数类型为Long的channelRead0方法如下图:
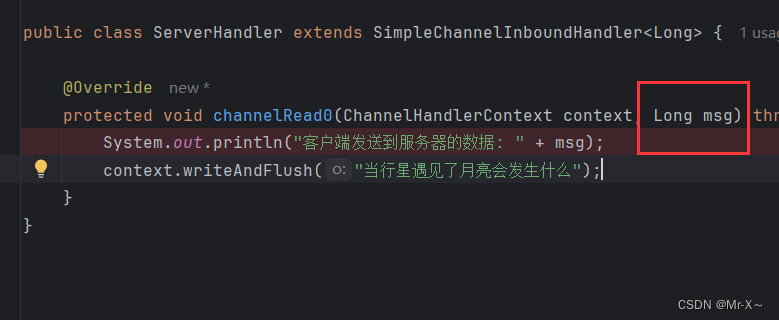
现在一共有两种处理方式,但底层思想其实是一致的,就是要确保解码之后生成的对象类型和我们下一个ChannelHandler节点的channelRead0方法中的参数类型要一直:
- 一种方法是把解码处理器生成的解码对象从String改成Long;
- 另外一种方法是把channelRead0方法中的参数对象从Long改为String;
以后的写作规范
规范1:责任链头部写上编解码处理器
因此以后在应用程序当中,不管是在客户端应用程序,还是在服务端应用程序,写处理器的时候,在责任链的头部首先要写上编码处理器和解码处理器,然后再写业务相关的ChannelHandler处理器,如下图:
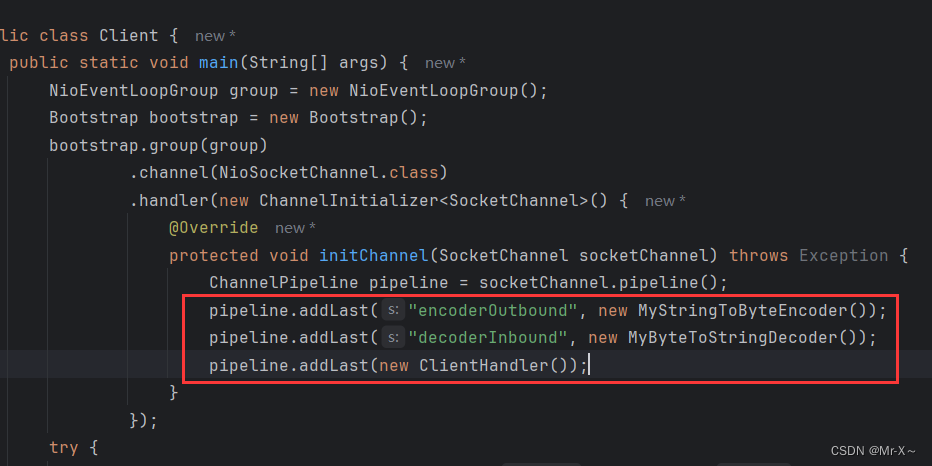
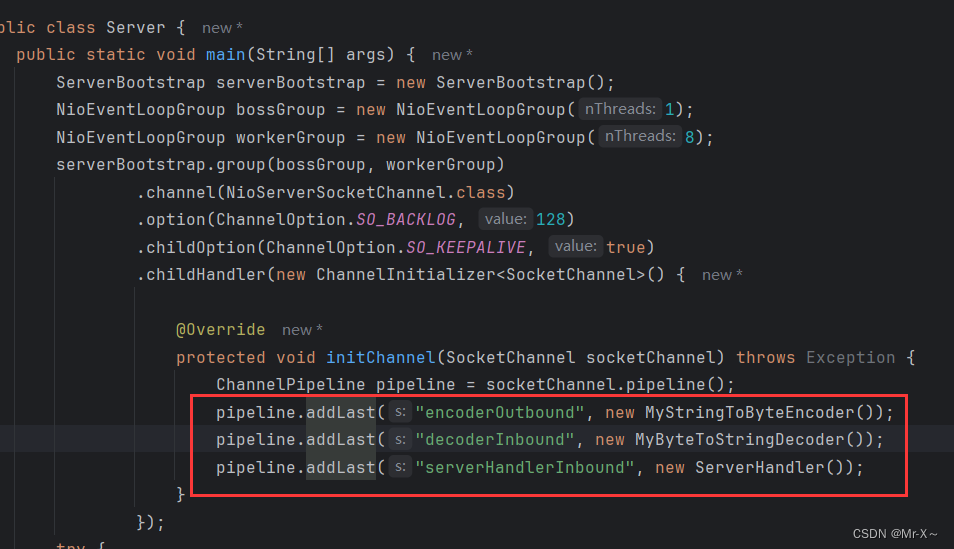
这是一种保证数据能够成功冲刷到网络中的一种规范。如果不写编码处理器,但是你能够保证数据以二进制的方式冲刷到网络中也可以,比如通过下面这种方式,如下图:
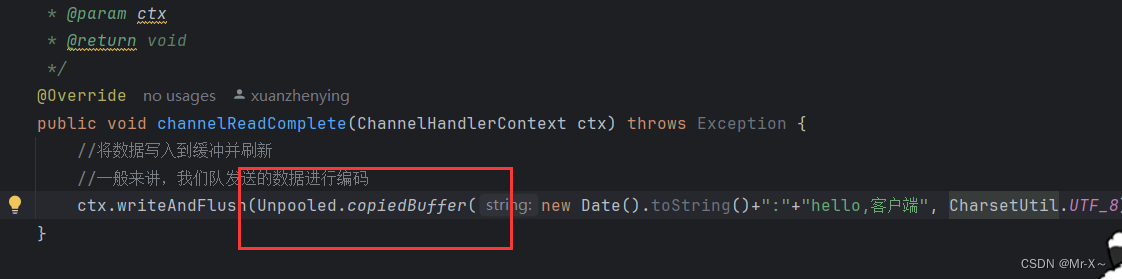
上面的Unpooled.copiedBuffer方法可以把我们的数据转变成网络能接受的二进制数据格式。
虽然说用第二种方式也可以,但是我们还是推荐你使用在应用程序的ChannelPipeline中的责任链的头部加上编码处理器。为什么呢?因为这样可以形成一种操作规范,后期比较方便理解,也比较方便开发。
规范二:确保解码处理器解码生成的对象和后续的入站处理器InboundHandler的channelRead0方法中的参数对象一致
因为虽然你的网络二进制数据被成功解码成了某一个对象,但是如果想要让你的数据能够被后续的ChannelHandler处理,那么必须保证解码之后的生成对象的类型和后续的ChannelHandler处理器中的channelRead0方法中的参数类型一致,否则你的数据就不会流转到后面的ChannelHandler处理。也就无法进行业务处理了。

















 127
127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











