







内存淘汰策略(最大内存策略)是什么?
当Redis达到最大内存时,Redis 选择要删除内容的策略。
在Redis配置文件中,最大内存策略默认配置为 maxmemory-policy noeviction。
noeviction:不删除任何的key,但再次写入会报错。volatile-lru:对设置了过期时间的key使用LRU算法删除。allkeys-lru:对所有的key使用LRU算法删除。volatile-lfu:对设置了过期时间的key使用LFU算法删除。allkeys-lfu:对所有的key使用LFU算法删除。volatile-random:对设置了过期时间的key进行随机删除。allkeys-random:对所有的key进行随机删除。volatile-ttl:删除马上要过期的key。
LRU(Least Recently Used)最近最少使用
LRU算法的基本思想是,当缓存空间已满时,优先淘汰最近最少使用的数据。
以下是LRU算法的简要描述和实现思路:
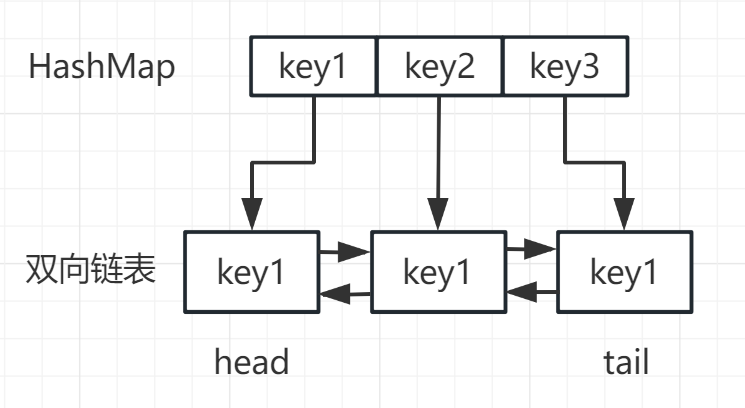
- 维护一个缓存空间(哈希表),以及一个记录元素访问顺序的数据结构(双向链表)。
- 当需要访问一个元素时,首先在缓存空间中查找该元素:
- 如果元素存在于缓存中,将其移动到数据结构的最前端,表示最近使用过。
- 如果元素不存在于缓存中,需要将其添加到缓存中:
- 如果缓存已满,移除数据结构最末尾的元素(表示最久未使用),然后将新元素添加到缓存和数据结构的最前端。
- 如果缓存未满,直接将新元素添加到缓存和数据结构的最前端。
- 重复步骤2,直到所有元素访问完毕。
对应的LeetCode题目:146. LRU 缓存
使用java.util.LinkedHashMap
class LRUCache extends LinkedHashMap<Integer, Integer> {
private int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75f, true);
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key, -1);
}
public void put(int key, int value) {
super.put(key, value);
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return super.size() > capacity;
}
}
哈希表 + 双向链表
class LRUCache {
private int capacity;
private final Map<Integer, DoubleLinkedList.Node> map = new HashMap<>();
private final DoubleLinkedList list = new DoubleLinkedList();
public LRUCache(int capacity) {
this.capacity = capacity;
}
public int get(int key) {
DoubleLinkedList.Node node = map.get(key);
// 没找到返回-1
if (node == null) {
return -1;
}
// 将使用到的节点移动到队头
list.remove(node);
list.addHead(node);
return node.value;
}
public void put(int key, int value) {
DoubleLinkedList.Node node = map.get(key);
// key已经存在,更新value
if (node != null) {
node.value = value;
list.remove(node);
list.addHead(node);
return;
}
// 空间不足,淘汰最后一个
if (map.size() >= capacity) {
DoubleLinkedList.Node last = list.getLast();
map.remove(last.key);
list.remove(last);
}
// 将新节点放入
DoubleLinkedList.Node newKNode = new DoubleLinkedList.Node(key, value);
map.put(key, newKNode);
list.addHead(newKNode);
}
static class DoubleLinkedList {
Node head;
Node tail;
public DoubleLinkedList() {
// 创建虚拟的头尾节点
this.head = new Node();
this.tail = new Node();
this.head.next = this.tail;
this.tail.prev = this.head;
}
// 将元素添加到头结点后
public void addHead(Node node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
// 删除结点
public void remove(Node node) {
node.next.prev = node.prev;
node.prev.next = node.next;
node.prev = null;
node.next = null;
}
public Node getLast() {
return tail.prev;
}
static class Node {
int key;
int value;
Node prev;
Node next;
public Node() {
this.prev = null;
this.next = null;
}
public Node(int key, int value) {
this.key = key;
this.value = value;
this.prev = null;
this.next = null;
}
}
}
}
LFU(Least Frequently Used)最不经常使用
LFU算法的基本思想是,当缓存空间已满时,优先淘汰最不经常使用的数据。
以下是LFU算法的简要描述和实现思路:
维护一个缓存空间(可以是数组、链表或哈希表),以及一个记录元素访问频率的计数器。
每次访问一个元素时,首先在缓存空间中查找该元素:
- 如果元素存在于缓存中,将其访问频率加一。
- 如果元素不存在于缓存中,需要将其添加到缓存中:
- 如果缓存已满,找到访问频率最低的元素,如果有多个元素的访问频率相同,则选择最早加入缓存的元素进行淘汰。
- 如果缓存未满,直接将新元素添加到缓存,并将其访问频率设置为1。
- 重复步骤2,直到所有元素访问完毕。
对应的LeetCode题目:460. LFU 缓存
多个哈希表
class LFUCache {
private int capacity;
private int minFrequency;
private Map<Integer, Integer> keyToValue;
// key->使用频率
private Map<Integer, Integer> keyToFrequency;
// 使用频率->key
private Map<Integer, LinkedHashSet<Integer>> frequencyToKeys;
public LFUCache(int capacity) {
this.capacity = capacity;
this.minFrequency = 0;
this.keyToValue = new HashMap<>();
this.keyToFrequency = new HashMap<>();
this.frequencyToKeys = new HashMap<>();
}
public int get(int key) {
if (!keyToValue.containsKey(key)) {
return -1;
}
int value = keyToValue.get(key);
int frequency = keyToFrequency.get(key);
updateFrequency(key, frequency);
return value;
}
public void put(int key, int value) {
if (capacity <= 0) {
return;
}
if (keyToValue.containsKey(key)) {
keyToValue.put(key, value);
int frequency = keyToFrequency.get(key);
updateFrequency(key, frequency);
} else {
if (keyToValue.size() >= capacity) {
evict();
}
keyToValue.put(key, value);
keyToFrequency.put(key, 1);
frequencyToKeys.computeIfAbsent(1, k -> new LinkedHashSet<>()).add(key);
minFrequency = 1;
}
}
private void updateFrequency(int key, int frequency) {
int newFrequency = frequency + 1;
keyToFrequency.put(key, newFrequency);
frequencyToKeys.get(frequency).remove(key);
if (frequencyToKeys.get(frequency).isEmpty() && frequency == minFrequency) {
minFrequency = newFrequency;
}
frequencyToKeys.computeIfAbsent(newFrequency, k -> new LinkedHashSet<>()).add(key);
}
private void evict() {
LinkedHashSet<Integer> keys = frequencyToKeys.get(minFrequency);
int evictKey = keys.iterator().next();
keys.remove(evictKey);
keyToValue.remove(evictKey);
keyToFrequency.remove(evictKey);
}
}
哈希表 + 平衡二叉树
class LFUCache {
// 缓存容量,时间戳
int capacity, time;
Map<Integer, Node> key_table;
TreeSet<Node> S;
public LFUCache(int capacity) {
this.capacity = capacity;
this.time = 0;
key_table = new HashMap<Integer, Node>();
S = new TreeSet<Node>();
}
public int get(int key) {
if (capacity == 0) {
return -1;
}
// 如果哈希表中没有键 key,返回 -1
if (!key_table.containsKey(key)) {
return -1;
}
// 从哈希表中得到旧的缓存
Node cache = key_table.get(key);
// 从平衡二叉树中删除旧的缓存
S.remove(cache);
// 将旧缓存更新
cache.cnt += 1;
cache.time = ++time;
// 将新缓存重新放入哈希表和平衡二叉树中
S.add(cache);
key_table.put(key, cache);
return cache.value;
}
public void put(int key, int value) {
if (capacity == 0) {
return;
}
if (!key_table.containsKey(key)) {
// 如果到达缓存容量上限
if (key_table.size() == capacity) {
// 从哈希表和平衡二叉树中删除最近最少使用的缓存
key_table.remove(S.first().key);
S.remove(S.first());
}
// 创建新的缓存
Node cache = new Node(1, ++time, key, value);
// 将新缓存放入哈希表和平衡二叉树中
key_table.put(key, cache);
S.add(cache);
} else {
// 这里和 get() 函数类似
Node cache = key_table.get(key);
S.remove(cache);
cache.cnt += 1;
cache.time = ++time;
cache.value = value;
S.add(cache);
key_table.put(key, cache);
}
}
}
class Node implements Comparable<Node> {
int cnt, time, key, value;
Node(int cnt, int time, int key, int value) {
this.cnt = cnt;
this.time = time;
this.key = key;
this.value = value;
}
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof Node) {
Node rhs = (Node) anObject;
return this.cnt == rhs.cnt && this.time == rhs.time;
}
return false;
}
public int compareTo(Node rhs) {
return cnt == rhs.cnt ? time - rhs.time : cnt - rhs.cnt;
}
public int hashCode() {
return cnt * 1000000007 + time;
}
}















 129
129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









