







原文:Yipeng Wang, Huijie He, Yingxu Lai, Alex X. Liu.A Two-Phase Approach to Fast and Accurate Classification of Encrypted Traffic. IEEE/ACM Trans. Netw. 31(3): 1071-1086 (2023)




针对前面背景,我们提出了一种两阶段策略来实现高效的早期分类,这里首先我们需要了解易流和难流的概念。
对于加密流量,如果仅使用前几个数据包就可以准确分类,我们称这类流为"易流";否则我们需要考虑更多的数据包进行更细粒度的分析才能实现准确分类的流量,我们称之为"难流。
在本文中的核心是在不牺牲流分类精度的同时要尽力取去减少观察待分类流所花费的时间。
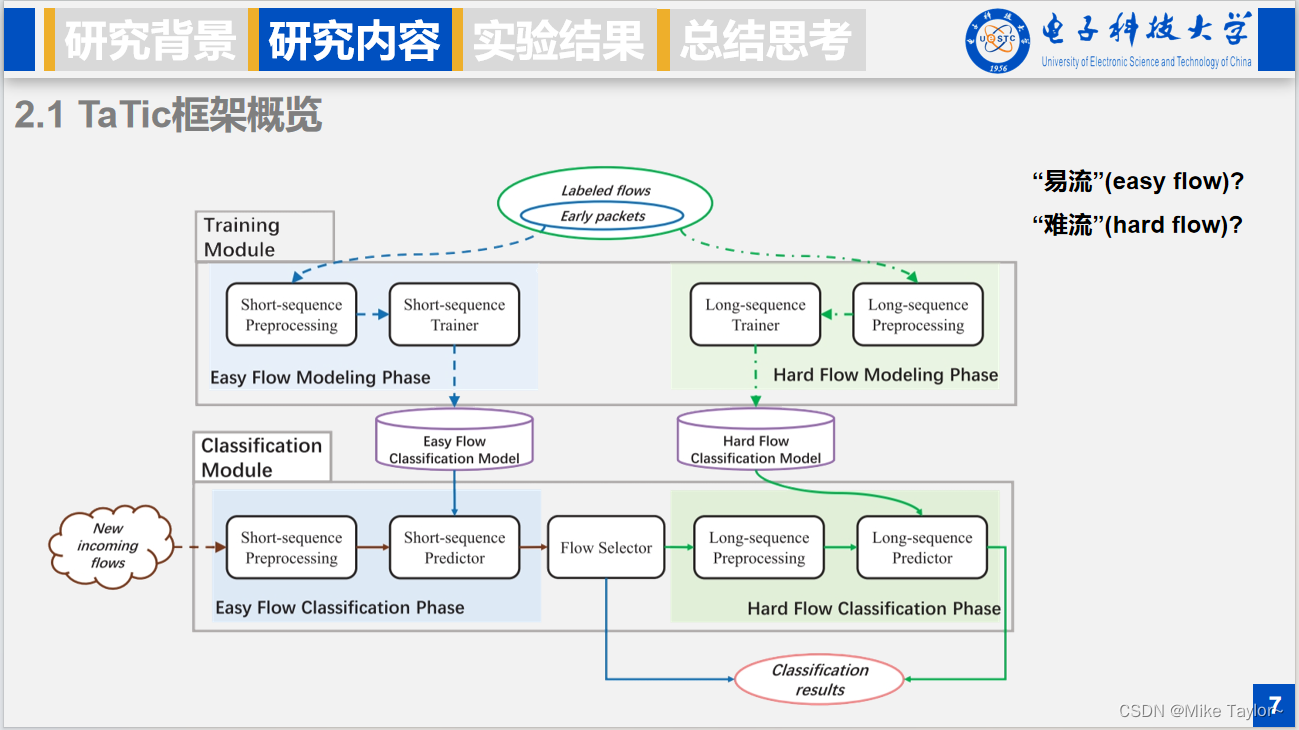
框架包括训练模块和分类模块,训练模块进行易流分类模型和难流分类模型的构建。首先,易流建模阶段用每个标记流的前几个数据包建立一个分类模型,来对“易流”进行分类,这些流可以在其持续时间较早时被正确分类。然后,难流建模阶段,对在易流建模阶段无无法分类的流,使用这些流的更多数据包来建立难流分类模型,该模型可以准确地对早期无法分类的“难流”进行分类。
在分类阶段,对新的流,易流分类阶段区分它是“易流”还是“难流”,如果流是“易流”,则该易流分类阶段将直接输出其相应的应用标签。如果流是“难流”,还需要使用后续的难流分类模型输出对应标签。

下我们介绍训练模块,首先是“易流”建模阶段,利用每个已标记流的前几个数据包构建“易流”分类模型,从而更早地对多个流进行准确分类。这个阶段包括短序列预处理和短序列分类模型训练两个步骤。在预处理阶段,对于输入的流,截取流的前h个数据包,并从数据包中提取有效载荷长度、TCP窗口大小、时间戳三个特征,而时间戳需要转换为时间间隔才能用于分类任务,另外还需要使用阶梯函数变换时间间隔,目的是把连续值映射为离散值,最终得到一个流的前h个数据包的特征序列,多个流处理汇总后得到预处理后的数据集。
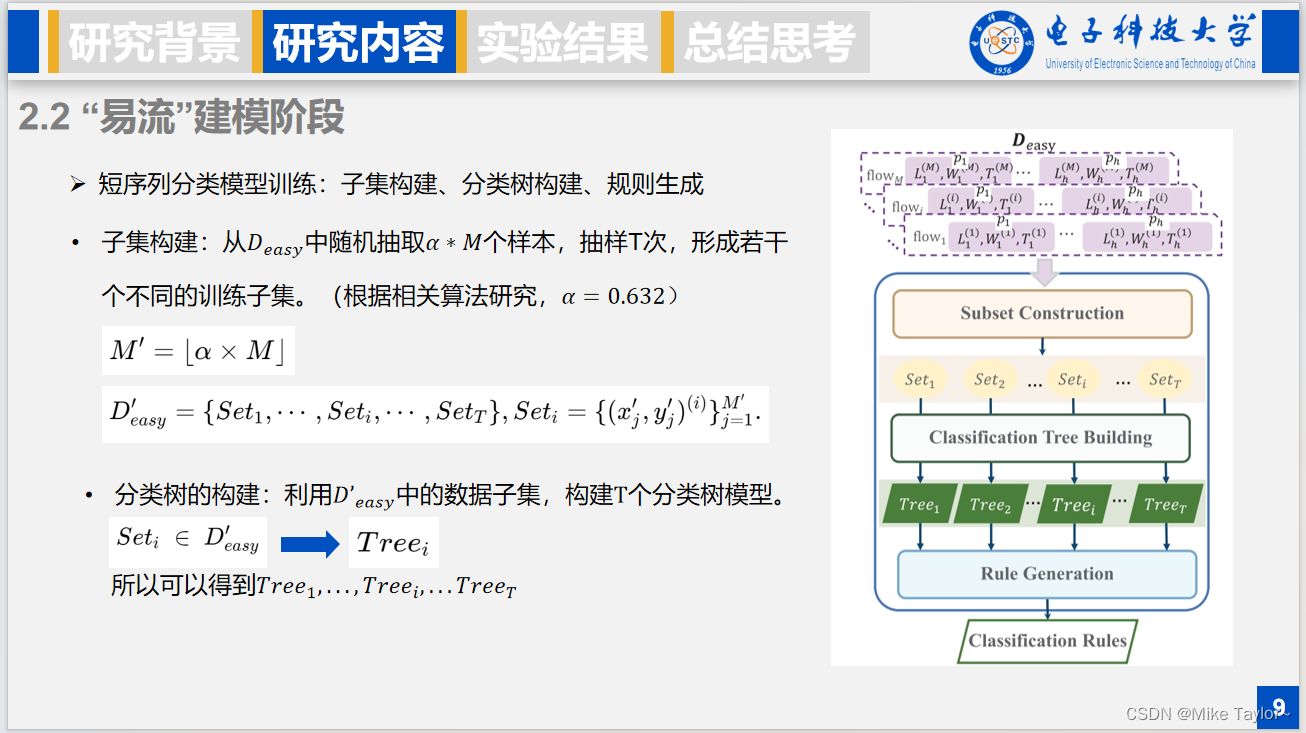
然后进行短序列分类模型训练,这个过程借鉴了bagging算法的思想,具体包括子集构建、分类树构建、规则生成三步,子集构建是指从前面预处理后的数据集中随机抽取α∗M个样本,M表示样本流的总数,抽样T次,可以形成T个不同的训练子集。(根据相关算法研究,α=0.632)。然后对于T次抽样得到的T个子集,需要构建各自的分类树,总共T棵树。
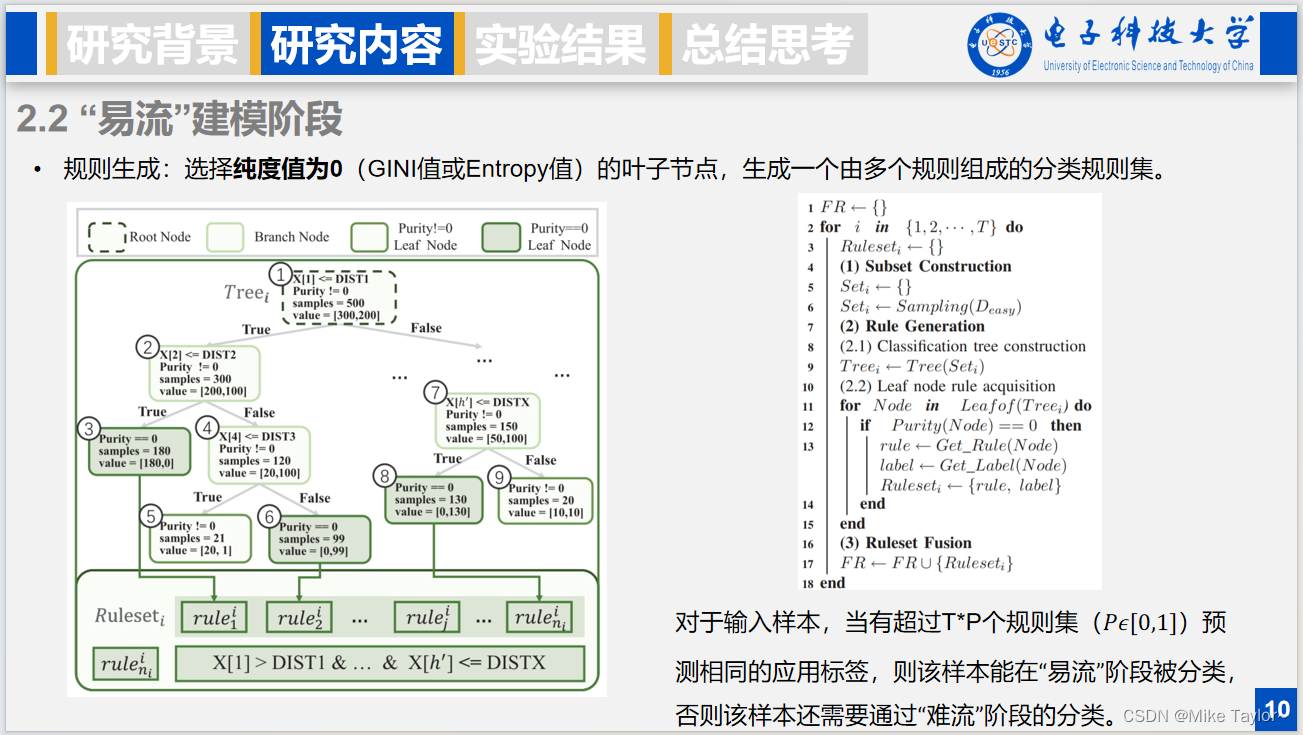
在规则生成阶段,对于一个规则,会对应一个纯度为0的叶节点,纯度值计算可以使用GINI值或者信息熵值,而一个规则就是从根节点到该叶子结点的分裂规则的交。比如下面图中的结点3、结点6和结点8,会生成各自的规则,而一个规则的组成就是这样,其实就是各个划分条件的并。
这里伪代码展示了模型训练的整个过程:首先抽样,然后对抽样后的样本构建分类树,然后遍历所有叶节点,挑选纯度为0的结点,生成对应的规则,最后将规则汇总,然后这过程重复T次。
对于易流的区分,采取投票的策略。对于输入样本,当有超过TxP个规则集预测相同的标签,也就是超过TxP颗决策树得到相同的标签,那么说明样本可以在“易流”阶段被分类,否则进入后续的“难流”分类。P就是需要的投票比例临界值。
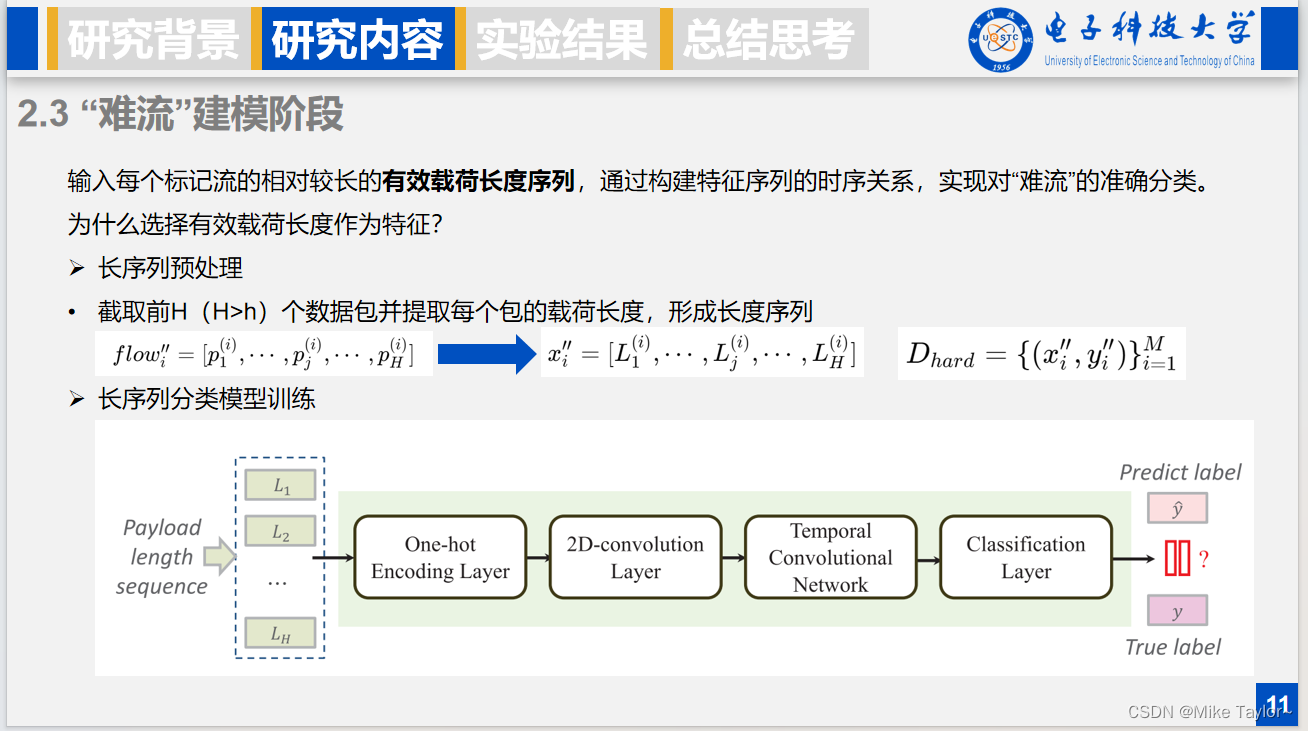
对于剩下的无法被标记的“难流”,输入这些流更长的有效载荷长度序列,通过构建时序关系,从而实现对“难流”的准确分类。那么为什么选择有效载荷长度作为特征?首先有效载荷长度序列能精确地描述每一种流。而且前面使用的window size窗口大小特征,对于一个方向的不同数据包通常是相同的,所以能使用窗口进行分类的流量,在“易流”分类阶段就已经被成功分类了,所以我们这里不用它。
“难流”建模阶段同样分为类似的长序列预处理和长序列分类模型训练两个阶段,预处理时,截取前H个数据包并提取每个包的载荷长度,形成长度序列,H显然要大于h。分类模型训练以预处理得到的长度序列作为输入,经过one-hot编码层、二维卷积层、时间卷积网络层、分类层后输出预测标签。
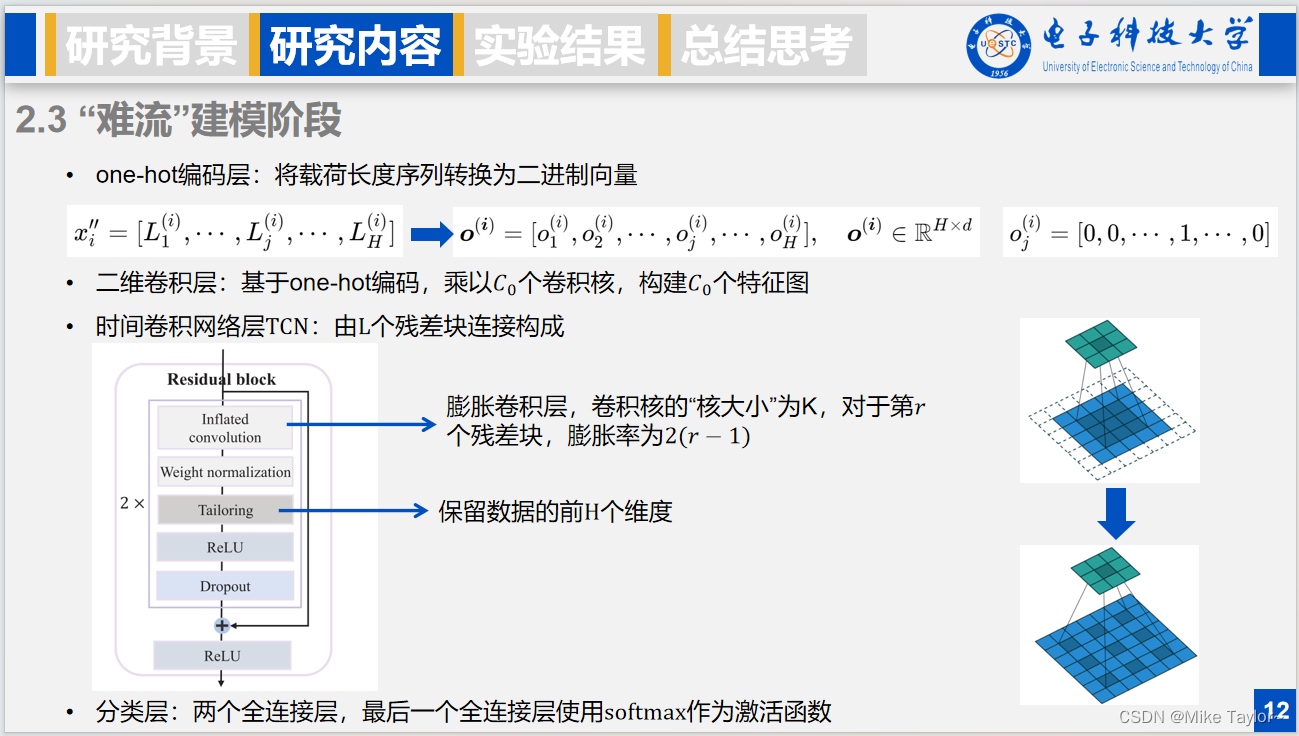
one-hot编码层负责将载荷长度序列转换为二进制向量,对于一个one-hot向量,它有且只有一个维度的值是1,其他维度都是0。
二维卷积层基于one-hot编码,乘上C0个卷积核,构建C0个特征图。
时间卷积网络层使用特征图作为输入,它由L个残差块串联构成,一个残差块的结构如图所示。首先对于膨胀卷积层,卷积核的“核大小”为K,对于第r个残差块,膨胀率为2(r−1),它是时间卷积网络的核心,右边可以看到膨胀卷积核和普通卷积核的区别,裁剪层用于保留经过膨胀卷积操作后得到的数据的前H个维度。
最后的分类层包括两个全连接层,最后一个全连接层使用softmax作为激活函数。


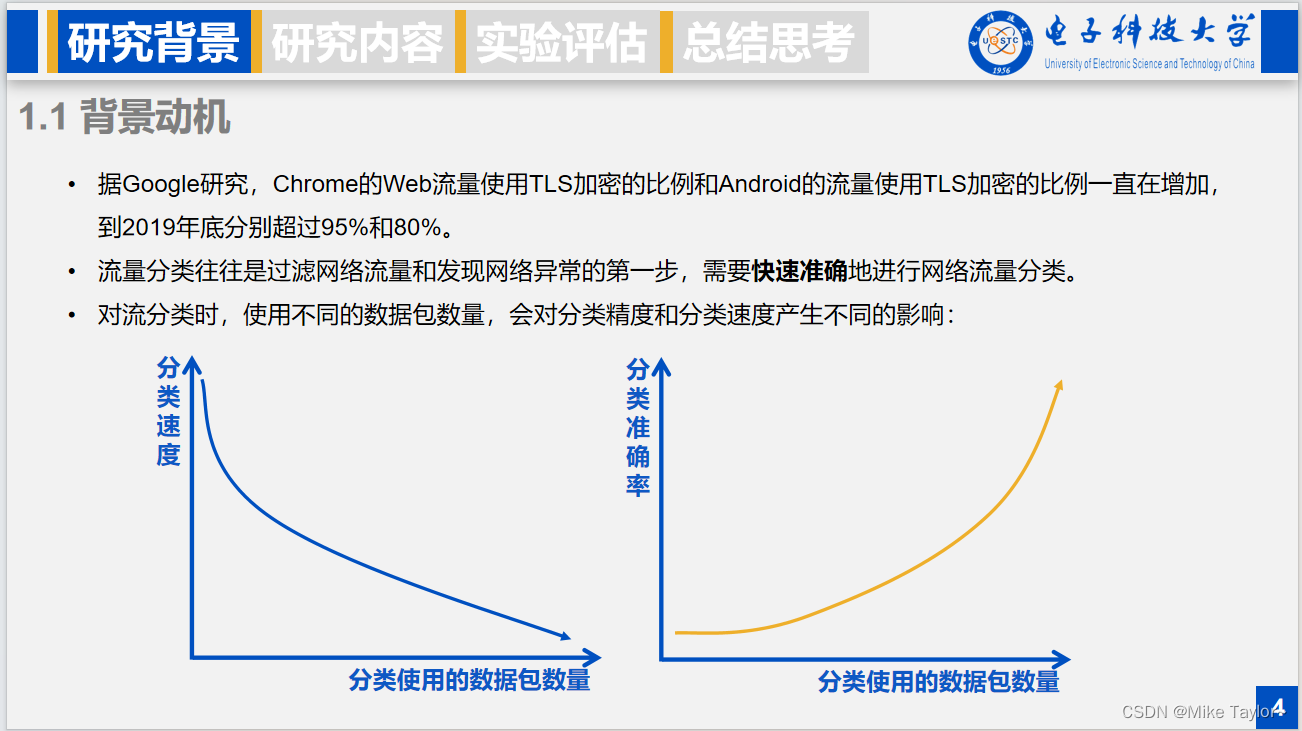
评价指标包括以下三个方面。首先介绍“易流”分类模型的有效性度量,Covr应用覆盖率,表示一类应用中能在易流分类阶段得到预测标签的样本数占该类应用样本总数的比例。AoCr覆盖分类准确率,表示某类应用能在易流分类阶段完成分类且分类结果正确的样本数,占该类应用中能在易流分类阶段完成分类的样本数的比例。平均应用覆盖率和平均覆盖分类准确率是对所有应用类型的应用覆盖率和覆盖分类准确率求和取平均。Fβ是综合考虑易流处理阶段中覆盖率和准确率的评价指标,β用来调节指标中覆盖率和分类准确率的重要性,显然本文中易流阶段的分类准确率比覆盖率更重要,所以β大于1。
所有流分类的有效性度量包括我们熟知的召回率、精确度、F-度量,对召回率取平均得到准确率。
最后是流分类的效率度量,对于一类应用,它的平均等待时间AWT等于易流占比乘上易流等待数据包所用的平均时间加上难流占比乘上难流等待数据包所用的平均时间。对所有类的应用的平均等待时间取平均,得到整体的平均等待时间。容易知道,整体平均等待时间越小,说明分类所需要累积的数据包越少,方法也更加高效。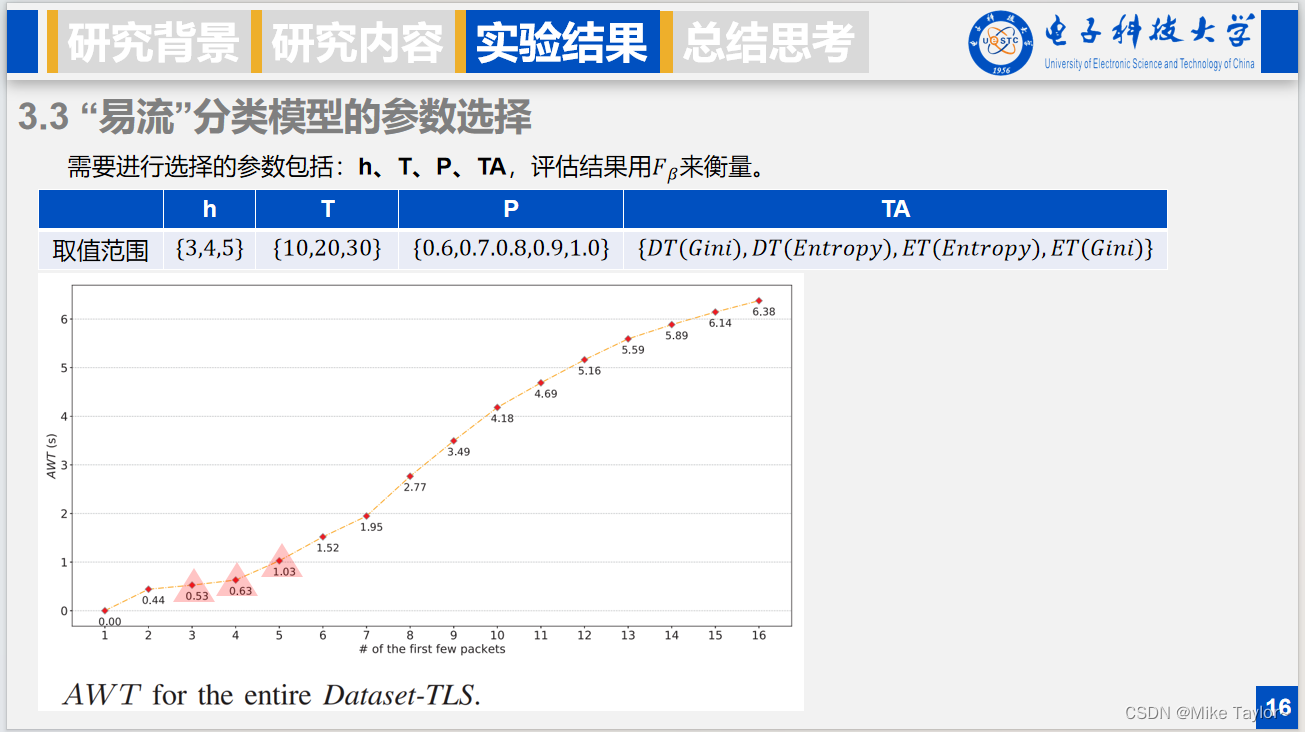
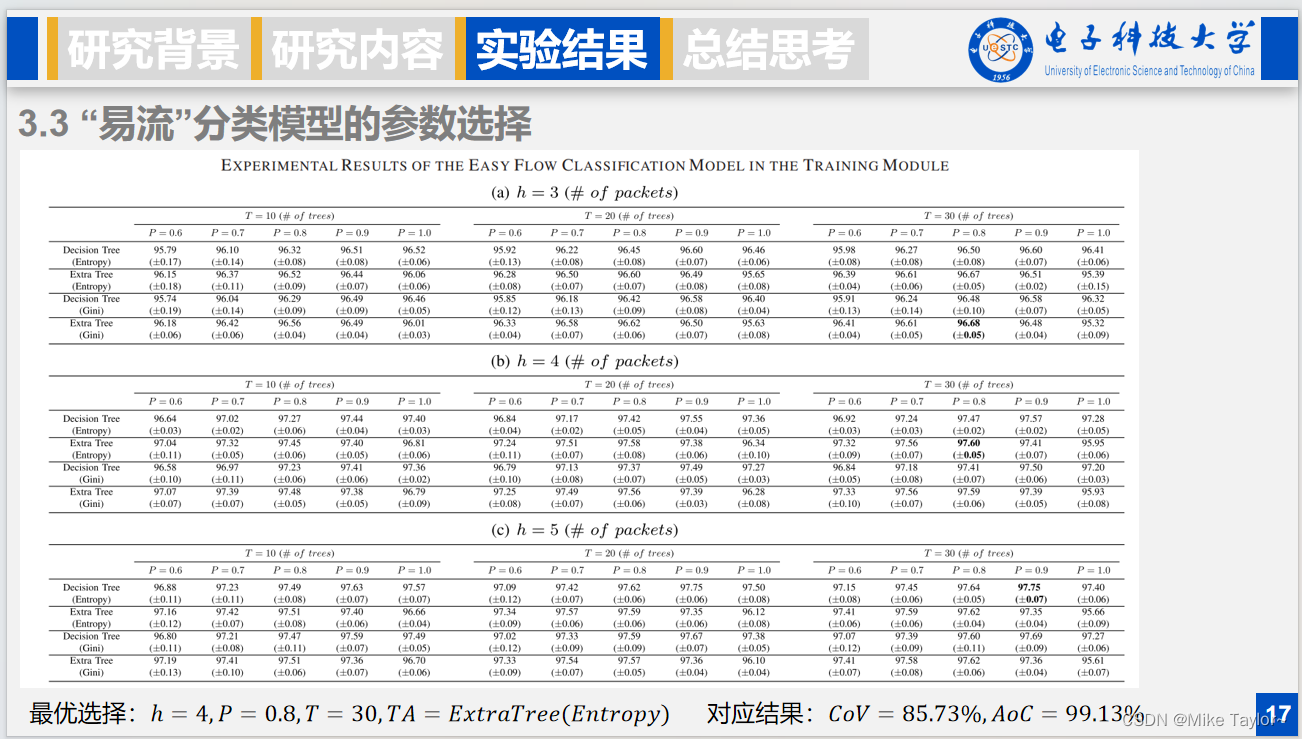
然后我们要探索前面介绍的一些未确定参数的最优选择,首先是易流处理阶段的参数,h表示在这个阶段,对于一个流到底需要考虑前几个数据包,可以取345,T表示抽样的次数或者分类树的数量,P表示前面的投票比例临界值,TA是分类树构建的不同策略,树分为决策树和极端随机树,两者的不同在于决策树每次选择的划分特征都是最优特征,但是极端随机树随机选择特征进行划分。GINI和信息熵是纯度计算的不同方式。
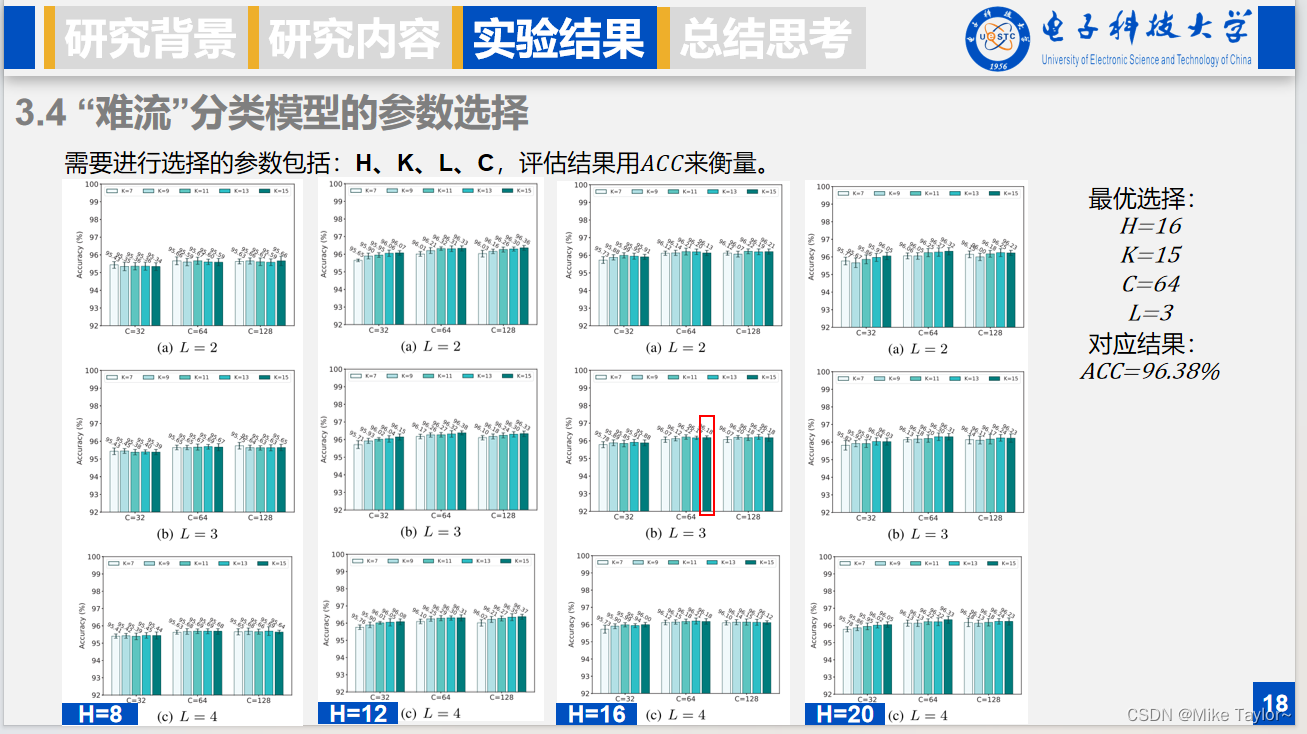
难流处理阶段需要进行选择的参数包括:H、K、L、C,评估结果用准确率来衡量。
H表示难流分类阶段需要考虑的数据包数量,文中包括8.12.16.20四个取值
K表示时间卷积网络中膨胀卷积层的卷积核大小,文中包括7,9,11,13,15五种选择
L表示时间卷积网络中串联的残差块数量,文中可以取2,3,4
C表示TCN中膨胀卷积层的卷积核个数,可以去32,64,128
我们需要知道,这里的实验结果是只使用“难流”阶段模型进行分类得到的结果。
观察结果可以知道,“难流”阶段分类单独使用也有很高的分类准去率。
而对于带确定的参数,H上升,分类精度先提高后稳定;而且残差块数量L=3/4时的结果大多数情况下好于L=2的结果,但L=3/4没有明显差异;而且似乎卷积核大小越大,精度越高。
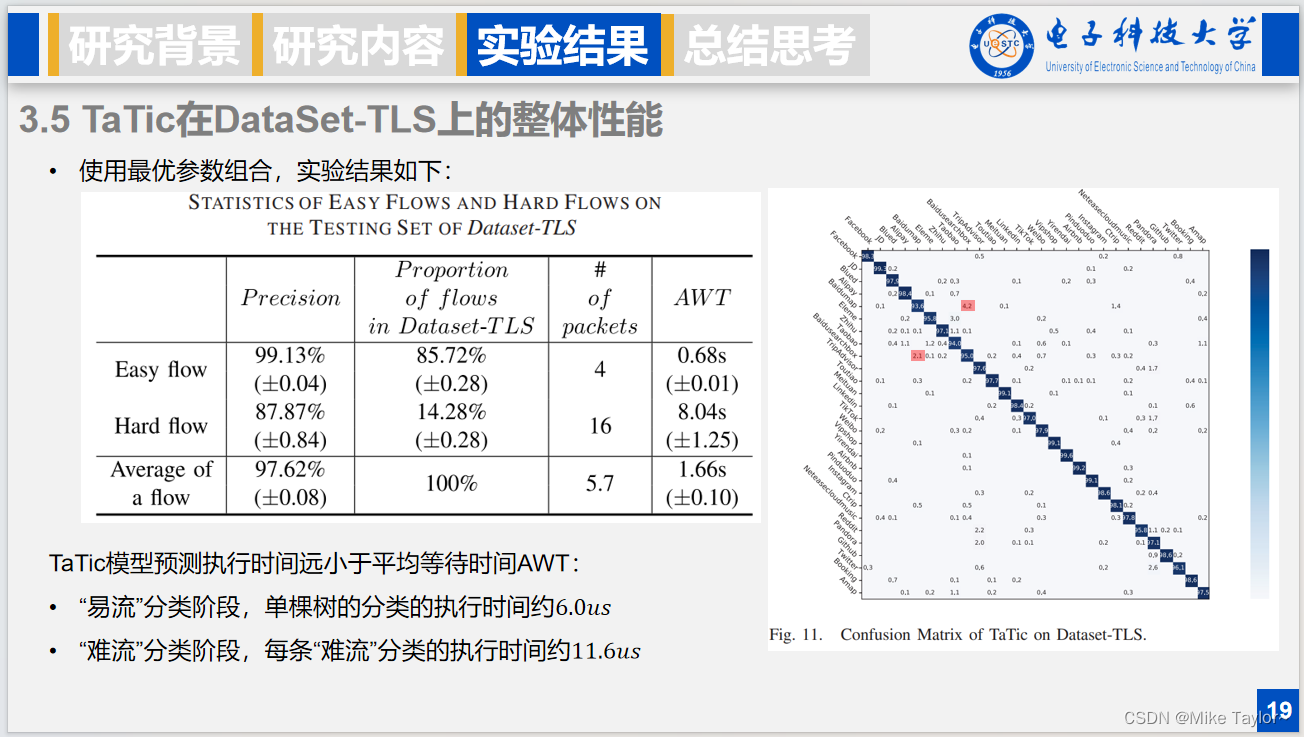
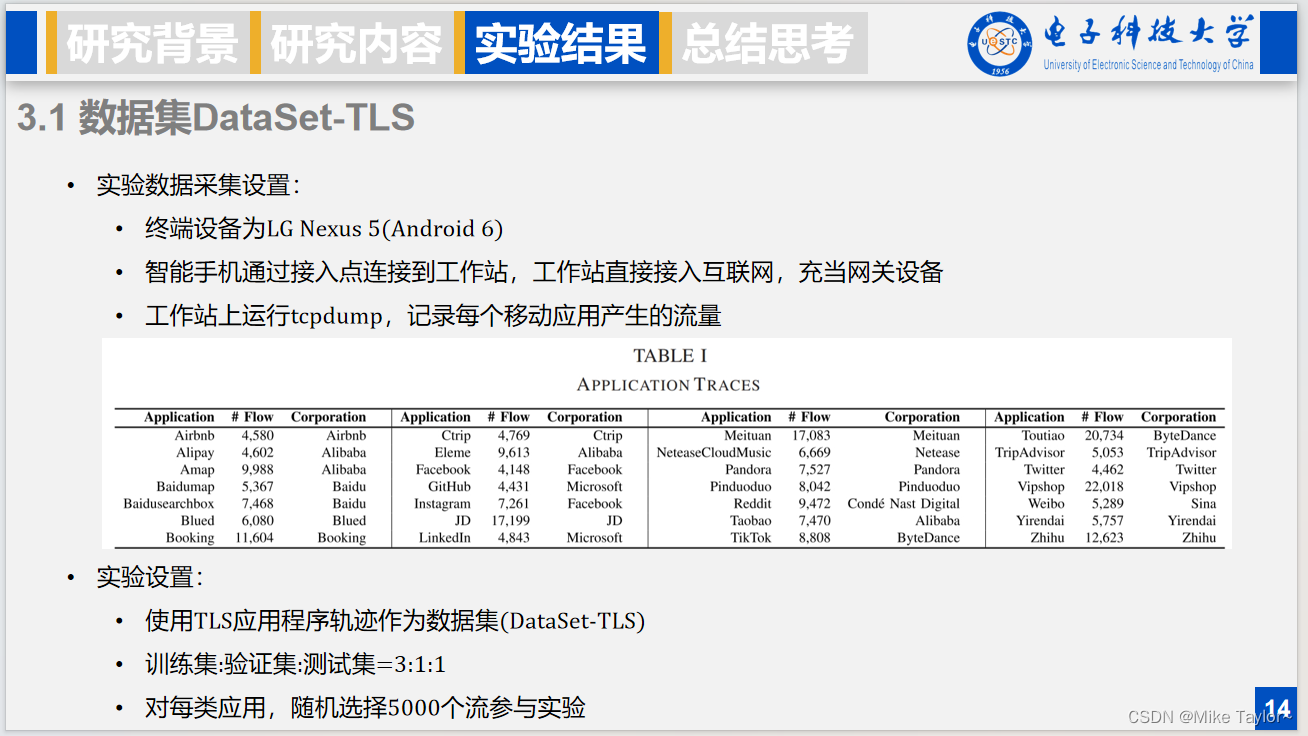
接下来是在DataSet-TLS数据集上的整体性能,实验过程中,易流和难流阶段中的参数都是用前面提到的最优参数选择方案,易流分类考虑前4个数据包,难流分类考虑前16个数据包,平均使用5.7个数据包。易流占数据集的85.72%,难流占数据集的14.28%。
另外模型的预测执行时间远小于平均等待时间,这两部分时间几乎可以忽略不计。
另外,在DataSet-TLS上的混淆矩阵也表明了本文方法的优异性能,但是这里本文也注意到了一个细节,就是对于来自不同公司的应用具有非常好的分类性能,但是对来自同一公司的一些应用程序进行分类时表现得不够出色,可能是因为同一公司的应用流特征相似性相对较高。这里可以看到百度地图和百度搜索误分率较高。
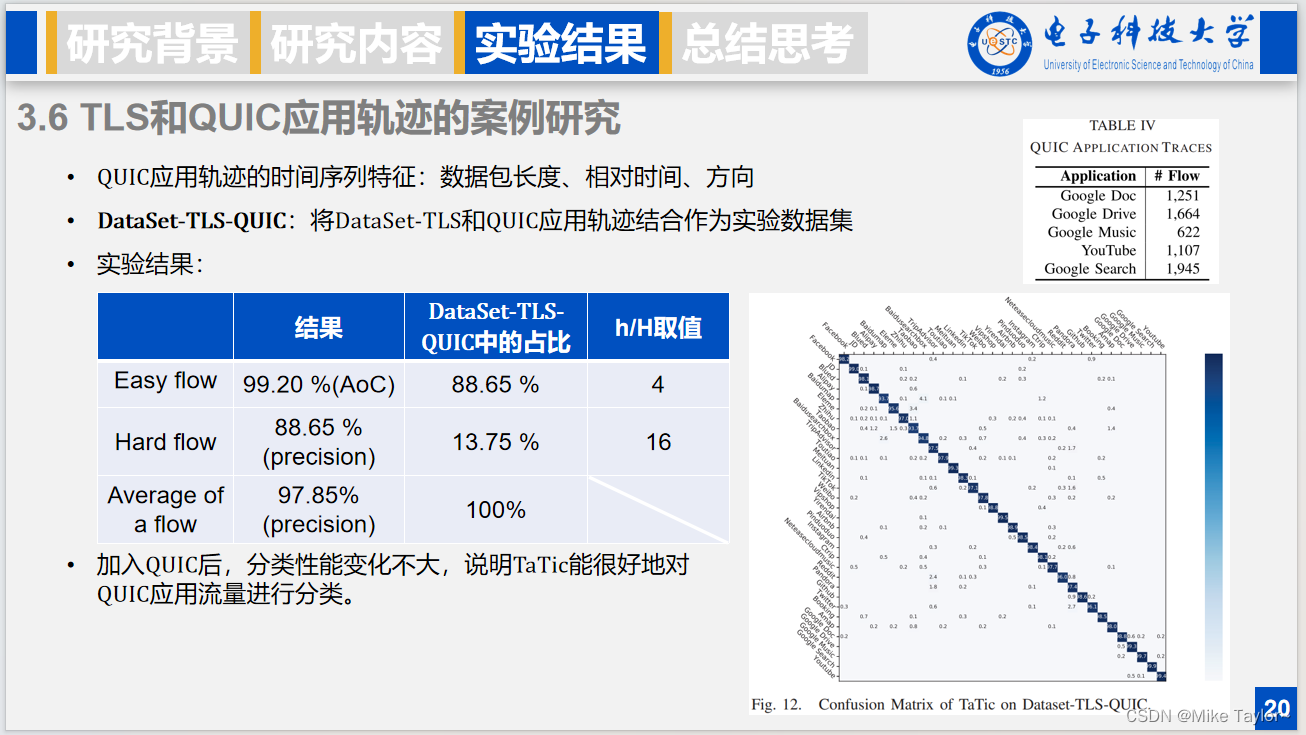
接下来我们验证本文方法在其他协议的表现,具体来说我们考虑基于QUIC协议的流。
QUIC由Google开发的基于UDP的加密传输层协议,本文使用QUIC应用轨迹由5种流行的谷歌应用产生,轨迹包含三个时间序列特征。
在后续实验中,将DataSet-TLS和QUIC应用轨迹结合作为实验数据集,下面是实验结果,可以看到数据集中易流难流占比、分类性能都没有太大变化。
这里结合后数据集上的混淆矩阵,我们可以发现加入QUIC协议流量后,分类性能变化不大,说明本文方法能很好地对不同协议的流量进行分类。

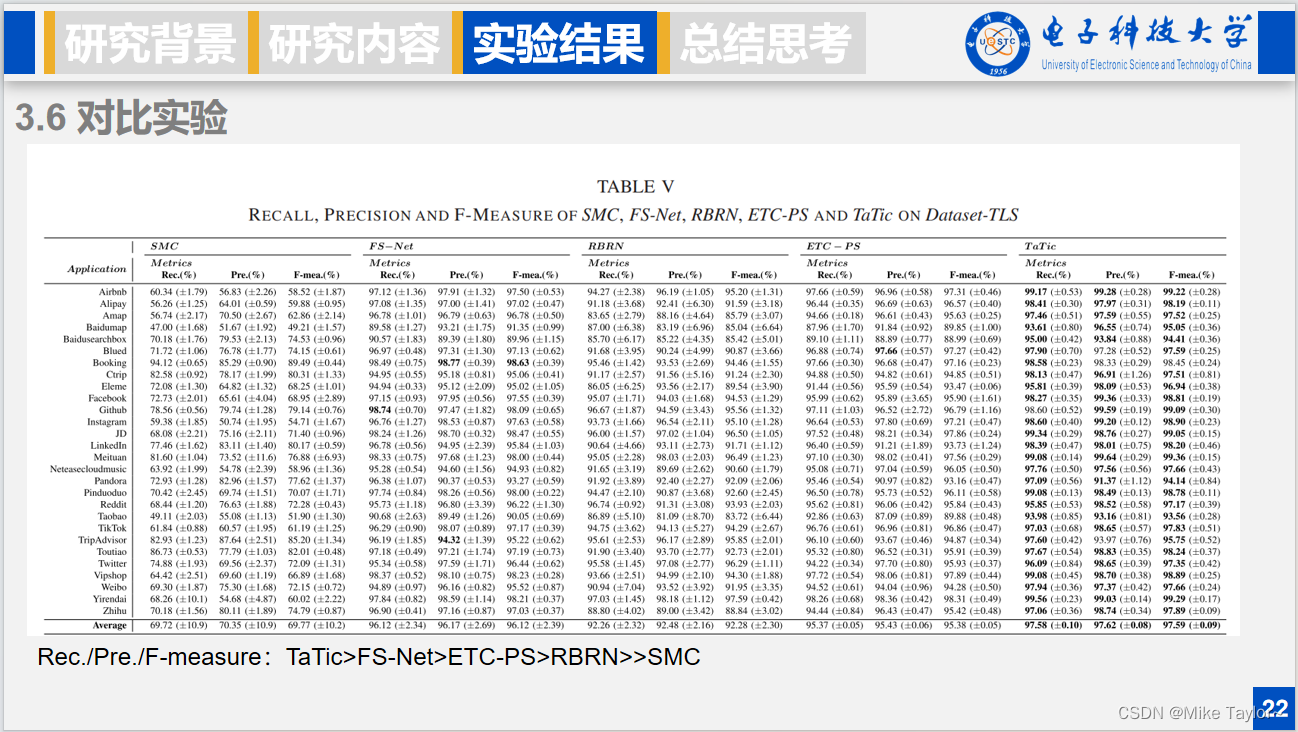

不放了,很多观点很牵强















 2692
2692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









