







跳表是一个空间换时间的一个结构,他会增加很多指针,利用指针来快速定位,解决了链表查询时间是O(N)的难题,跳表平均的查询时O(logN),最坏是O(N),N是跳表的长度,我们来看看他的实现
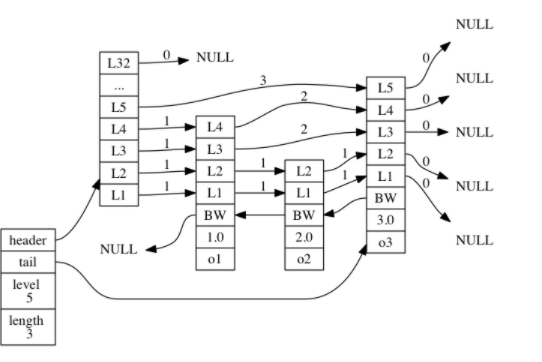
我们可以看到我们的跳表的整体实现结构,最左边的是zskiplist,包含了以下属性
- head:指向跳表的头节点
- tail:指向跳表的尾节点
- level:记录跳表中最大层数
- length:跳表的长度
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;
然后是我们的zskipNode的结构
- level:节点中用L1,L2,L3代表节点的层,每个层都有两个属性,bw(后退指针)和前进指针,跳跃表节点的 level 数组可以包含多个元素, 每个元素都包含一个指向其他节点的指针, 程序可以通过这些层来加快访问其他节点的速度, 一般来说, 层的数量越多, 访问其他节点的速度就越快。每次创建一个新跳跃表节点的时候, 程序都根据幂次定律 (power law,越大的数出现的概率越小) 随机生成一个介于 1 和 32 之间的值作为 level 数组的大小, 这个大小就是层的“高度”。
- backward:后退指针,用于从尾到头进行遍历, 所以每次只能后退至前一个节点。
- 前进指针:迭代程序首先访问跳跃表的第一个节点(表头), 然后从第四层的前进指针移动到表中的第二个节点。在第二个节点时, 程序沿着第二层的前进指针移动到表中的第三个节点。在第三个节点时, 程序同样沿着第二层的前进指针移动到表中的第四个节点。当程序再次沿着第四个节点的前进指针移动时, 它碰到一个 NULL , 程序知道这时已经到达了跳跃表的表尾, 于是结束这次遍历。
- 分值:在跳跃表中,节点按各自所保存的分值从小到大排列。
- 成员对象:节点中保存的对象
- 跨度:用于记录两个节点之间的距离,两个节点之间的跨度越大, 它们相距得就越远。指向 NULL 的所有前进指针的跨度都为 0 , 因为它们没有连向任何节点。
typedef struct zskiplistNode {
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;















 149
149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









