







Spark SQL_第六章笔记
1.Spark SQL简介
Spark SQL在Hive兼容层面仅依赖HiveQL解析、Hive元数据。从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。
Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责
Spark SQL增加了DataFrame(即带有Schema信息的RDD),使用户可以在Spark SQL中执行SQL语句,数据既可以来自RDD,也可以是Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据
关系型数据库对比Spark SQL
关系型数据库的缺点
1.用户需要从不同数据源执行各种操作,包括结构化、半结构化和非结构化数据
2.用户需要执行高级分析,比如机器学习和图像处理
Spark SQL优点:
1.可以提供DataFrame API,可以对内部和外部各种数据源执行各种关系型操作
2.可以支持大数据中的大量数据源和数据分析算法
Spark SQL可以融合:传统关系数据库的结构化数据管理能力和机器学习算法的数据处理能力
2.DataFrame
DataFrame的推出,让Spark具备了处理大规模结构化数据的能力,不仅比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能。DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息
Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询
2.1DataFrame创建
接口SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并且支持把DataFrame转换成SQLContext自身中的表,然后使用SQL语句来操作数据。SparkSession亦提供了HiveQL以及其他依赖于Hive的功能的支持
创建一个SparkSession对象
scala> import org.apache.spark.sql.SparkSession
scala> val spark=SparkSession.builder().getOrCreate()
在创建DataFrame之前,为了支持RDD转换为DataFrame及后续的SQL操作,需要导入相应的包,启用隐式转换。
import spark.implicits._
spark.read
spark.read.json("people.json"):
spark.read.parquet("people.parquet"):
spark.read.csv("people.csv"):
读取一个文件
//创建一个SparkSession对象
import org.apache.spark.sql.SparkSession
val spark=SparkSession.builder().getOrCreate()
//启用隐式转换
import spark.implicits._
val df = spark.read.json("file:///usr/local/spark/examples/src/main/resources/people.json")
df.show()
2.2DataFrame保存
spark.write操作,把一个DataFrame保存成不同格式的文件
df.write.json("people.json“)
df.write.parquet("people.parquet“)
df.write.csv("people.csv")
scala> val peopleDF = spark.read.format("json").load("file:///usr/local/spark/examples/src/main/resources/people.json")
scala> peopleDF.select("name", "age").write.format("csv").save("file:///usr/local/spark/mycode/sql/newpeople.csv")
2.3DataFrame常用操作
//打印模式信息
dt.printSchema()
//选择多列
df.select(df("name"),df("age")+1).show()
//条件过滤
df.filter(df("age")>20).show()
//分组聚合
df.grouBy("age").count().show()
//排序
df.sort(df("age").desc).show()
//多列排序 desc降序 asc升序
df.sort(df("age").desc,de("name").asc).show()
//对列进行重命名
df.select(df("name").as("username"),df("age")).show()
2.4从RDD转换得到DataFrame
2.4.1利用反射机制推断RDD模式
在利用反射机制推断RDD模式时,需要首先定义一个case class,因为,只有case class才能被Spark隐式地转换为DataFrame
import org.apache.spark.sql.catalyst.encoders.ExpressionEncoder
import org.apache.spark.sql.Encoder
import spark.implicits._ //导入包,支持把一个RDD隐式转换为一个DataFrame
case class Person(name: String, age: Long)//定义一个case class
val peopleDF = spark.sparkContext.textFile("file:///usr/local/spark/examples/src/main/resources/people.txt").map(_.split(",")).map(attributes => Person(attributes(0),attributes(1).trim.toInt)).toDF()
peopleDF.createOrReplaceTempView("people") //必须注册为临时表才能供下面的查询使用
val personsRDD = spark.sql("select name,age from people where age > 20")//最终生成一个DataFrame,下面是系统执行返回的信息
personsRDD.map(t => "Name: "+t(0)+ ","+"Age: "+t(1)).show()//DataFrame中的每个元素都是一行记录,包含name和age两个字段,分别用t(0)和t(1)来获取值

2.4.2使用编程方式定义RDD模式
当无法提前定义case class时,就需要采用编程方式定义RDD模式
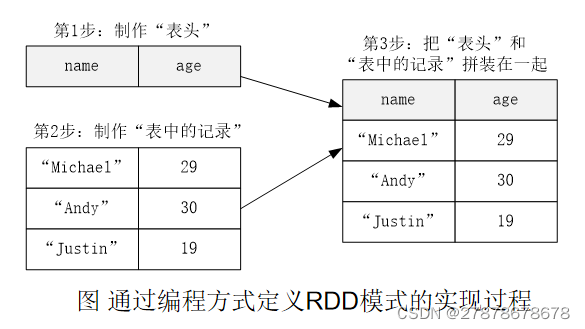
把people.txt加载进来生成DataFrame,并完成SQL查询
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
//生成字段
val fields = Array(StructField("name",StringType,true), StructField("age",IntegerType,true))
val schema = StructType(fields)
//从上面信息可以看出,schema描述了模式信息,模式中包含nam和age两个字段
//shcema就是“表头”
//下面加载文件生成RDD
val peopleRDD = spark.sparkContext.textFile("file:///usr/local/spark/examples/src/main/resources/people.txt")
//对peopleRDD 这个RDD中的每一行元素都进行解析
val rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim.toInt))
//上面得到的rowRDD就是“表中的记录”
//下面把“表头”和“表中的记录”拼装起来
val peopleDF = spark.createDataFrame(rowRDD, schema)
//必须注册为临时表才能供下面查询使用
peopleDF.createOrReplaceTempView("people")
val results = spark.sql("SELECT name,age FROM people")
results.map(attributes => "name: " + attributes(0)+","+"age:"+attributes(1)).show()
3.Spark SQL读写数据库
Spark SQL可以支持Parquet、JSON、Hive等数据源,并且可以通过JDBC连接外部数据源
3.1通过JDBC连接数据库
准备工作
在Linux中启动MySQL数据库
service mysql start
mysql -u root -p
输入SQL语句完成数据库和表的创建
mysql> create database spark;
mysql> use spark;
mysql> create table student (id int(4), name char(20), gender char(4), age int(4));
mysql> insert into student values(1,'Xueqian','F',23);
mysql> insert into student values(2,'Weiliang','M',24);
mysql> select * from student;
读取MySQL数据库中的数据

scala> val jdbcDF = spark.read.format("jdbc").
| option("url","jdbc:mysql://localhost:3306/spark").
| option("driver","com.mysql.jdbc.Driver").
| option("dbtable", "student").
| option("user", "root").
| option("password", "hadoop").
| load()
scala> jdbcDF.show()
+---+--------+------+---+
| id| name|gender|age|
+---+--------+------+---+
| 1| Xueqian| F| 23|
| 2|Weiliang| M| 24|
+---+--------+------+---+
向MySQL数据库写入数据
use spark;
select * from student;
在spark-shell中编写程序,往spark.student表中插入两条记录
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
//下面我们设置两条数据表示两个学生信息
val studentRDD = spark.sparkContext.parallelize(Array("3 Rongcheng M 26","4 Guanhua M 27")).map(_.split(" "))
//下面要设置模式信息
val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("gender", StringType, true),StructField("age", IntegerType, true)))
//下面创建Row对象,每个Row对象都是rowRDD中的一行
val rowRDD = studentRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).trim, p(3).toInt))
//建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
val studentDF = spark.createDataFrame(rowRDD, schema)
//下面创建一个prop变量用来保存JDBC连接参数
val prop = new Properties()
prop.put("user", "root") //表示用户名是root
prop.put("password", "hadoop") //表示密码是hadoop
prop.put("driver","com.mysql.jdbc.Driver") //表示驱动程序是com.mysql.jdbc.Driver
//下面就可以连接数据库,采用append模式,表示追加记录到数据库spark的student表中
studentDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/spark", "spark.student", prop)

3.2连接Hive读写数据
1.准备工作
service mysql start
cd /usr/local/hadoop
./sbin/start-all.sh
cd /usr/local/hive
./bin/hive
2.在Hive中创建数据库和表
进入Hive,新建一个数据库sparktest,并在这个数据库下面创建一个表student,并录入两条数据
hive> create database if not exists sparktest;//创建数据库sparktest
hive> show databases; //显示一下是否创建出了sparktest数据库
//下面在数据库sparktest中创建一个表student
hive> create table if not exists sparktest.student(
> id int,
> name string,
> gender string,
> age int);
hive> use sparktest; //切换到sparktest
hive> show tables; //显示sparktest数据库下面有哪些表
hive> insert into student values(1,'Xueqian','F',23); //插入一条记录
hive> insert into student values(2,'Weiliang','M',24); //再插入一条记录
hive> select * from student; //显示student表中的记录
3.连接Hive读写数据
在spark-shell(包含Hive支持)中执行以下命令从Hive中读取数据
Scala> import org.apache.spark.sql.Row
Scala> import org.apache.spark.sql.SparkSession
Scala> case class Record(key: Int, value: String)
// warehouseLocation points to the default location for managed databases and tables
Scala> val warehouseLocation = "spark-warehouse”
Scala> val spark = SparkSession.builder().appName("Spark Hive Example").config("spark.sql.warehouse.dir", warehouseLocation).enableHiveSupport().getOrCreate()
Scala> import spark.implicits._
Scala> import spark.sql
//下面是运行结果
scala> sql("SELECT * FROM sparktest.student").show()
+---+--------+------+---+
| id| name|gender|age|
+---+--------+------+---+
| 1| Xueqian| F| 23|
| 2|Weiliang| M| 24|
+---+--------+------+---+
scala> import java.util.Properties
scala> import org.apache.spark.sql.types._
scala> import org.apache.spark.sql.Row
//下面我们设置两条数据表示两个学生信息
scala> val studentRDD = spark.sparkContext.parallelize(Array("3 Rongcheng M 26","4 Guanhua M 27")).map(_.split(" "))
//下面要设置模式信息
scala> val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("gender", StringType, true),StructField("age", IntegerType, true)))
//下面创建Row对象,每个Row对象都是rowRDD中的一行
scala> val rowRDD = studentRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).trim, p(3).toInt))
//建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
scala> val studentDF = spark.createDataFrame(rowRDD, schema)
//查看studentDF
scala> studentDF.show()
+---+---------+------+---+
| id| name|gender|age|
+---+---------+------+---+
| 3|Rongcheng| M| 26|
| 4| Guanhua| M| 27|
+---+---------+------+---+
//下面注册临时表
scala> studentDF.registerTempTable("tempTable")
scala> sql("insert into sparktest.student select * from tempTable")















 306
306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









