







0
摘要
点击率(CTR)预测是在线广告和推荐系统等Web应用中的一项重要任务,其特征通常是多字段形式。该任务的关键是对不同特征域之间的特征交互进行建模。
最近提出的基于深度学习的模型遵循一种通用范式:原始稀疏输入多场特征首先被映射到密集场嵌入向量,然后简单地级联在一起,
以馈入深度神经网络(DNN)或其他专门设计的网络,从而学习高阶特征交互。
然而,特征场的简单非结构化组合将不可避免地限制以足够灵活和明确的方式对不同场之间的复杂交互进行建模的能力。
1
1引言
点击率预测的目标是预测用户点击广告或项目的概率,这对许多Web应用(如在线广告和推荐系统)至关重要。
对复杂的特征交互进行建模在CTR预测的成功中起着核心作用。与图像和音频中自然存在的连续特征不同,Web应用程序的特征大多是多领域分类形式。
例如,电影的四字段分类特征可以是:(1)语言= {英语、汉语、日语、.},(2)类型= {动作,小说,.},(3)导演= {李安,克里斯托弗·诺兰,.},
和(4)主演= {布鲁斯李,列奥纳多迪卡普里奥,.}(注意,在真实的应用程序中有多得多的特征字段)。
这些多领域的分类特征通常被转换为稀疏的独热编码向量,然后嵌入到密集的实值向量,可以用来建模特征的相互作用。
因式分解机(FM)[23]是一种众所周知的模型,用于从向量内积中学习二阶特征交互。
场感知因子分解机(FFM)[9]进一步考虑了场信息并引入了场感知嵌入。遗憾的是,这些基于FM的模型只能模拟二阶相互作用和线性建模限制了其代表性的权力。
最近,已经提出了许多基于深度学习的模型来学习高阶特征交互,这些模型遵循一个通用的范式:简单地将字段嵌入向量连接在一起,并将它们馈送到DNN或其他专门设计的模型中以学习交互。
例如,因子分解机器支持的神经网络(FNN)[35],神经因子分解机器(NFM)[8],Wide&Deep [2]和DeepFM [6]利用DNN来建模交互。
然而,这些基于DNN的模型以逐位、隐式的方式学习高阶特征交互,缺乏良好的模型解释。一些模型试图通过引入专门设计的网络来明确地学习高阶相互作用。
例如,Deep&Cross [31]引入了交叉网络(CrossNet),xDeepFM [15]引入了压缩交互网络(CIN)。
尽管如此,我们认为,他们仍然是不够有效和明确的,因为他们仍然遵循的一般范式相结合的功能字段在一起,以模拟他们的相互作用。
简单的非结构化组合将不可避免地限制以灵活和明确的方式对不同特征字段之间的复杂交互进行建模的能力。
在这项工作中,我们考虑了多场特征的结构。具体地说,我们将多域特征表示为一个图结构--特征图。
直观地,图中的每个节点对应于一个特征场,并且不同的场可以通过边相互作用。
因此,对特征域之间的复杂交互进行建模的任务可以转化为对特征图上的节点交互进行建模。
为此,本文在图神经网络(GNN)的基础上,设计了一种新的特征交互图神经网络模型(Fi-GNN),
它能够以一种灵活、明确的方式对复杂的节点(特征)交互进行建模。
在Fi-GNN中,节点将通过与邻居通信节点状态来交互,并且以循环方式更新自身。在每一个时间步,模型都与更深一跳的邻居进行交互。
因此,交互步骤的数量等于特征交互的顺序.此外,Fi-GNN还可以学习到反映不同特征交互重要性的边权值和反映每个特征场对最终CTR预测重要性的节点权值,
从而提供了很好的解释.总体而言,我们提出的模型能够以明确、灵活的方式对复杂的特征交互进行建模,并且还提供了良好的模型解释。
我们的贡献可以归纳为三个方面:
·指出了现有工作中将多场特征看作特征场的非结构化组合的局限性。为此,我们首次提出了用图结构表示多场特征的方法。
·设计了一种新的特征交互图神经网络(Feature Interaction Graph Neural Networks,Fi-GNN)模型,以更加灵活和明确的方式对图结构特征上的特征场之间的复杂交互进行建模。
·在两个现实数据集的大量实验表明,本文设计的方法不仅能够获得更好的分类效果,还能提供更好的模型解释。
本文其余部分的组织结构如下。第二节对相关工作进行了总结。第3节详细描述了我们提出的方法。广泛的实验和详细的分析在第4节中给出,然后在第5节中给出结论。
2
2相关工作
在本节中,我们简要回顾了现有的模型,这些模型为CTR预测和图神经网络建模特征交互。
2.1 CTR预测中的特征交互
建模特征交互是CTR预测成功的关键,因此在文献中被广泛研究。LR是一种线性方法,它只能对单个特征的线性组合上的一阶相互作用进行建模。
FM [23]从向量内积中学习二阶特征交互。之后,提出了FM的不同变体。场感知因子分解机(FFM)[9]考虑了场信息并引入了场感知嵌入。
AFM [34]考虑了不同二阶特征相互作用的权重。然而,这些方法只能模拟二阶相互作用是不够的。
随着DNN在各个领域的成功,研究人员开始使用它来学习高阶特征相互作用,因为它具有更深的结构和非线性激活函数。
一般的范例是将字段嵌入向量连接在一起,并将它们馈送到DNN中以学习高阶特征交互。[16]利用卷积网络对特征交互进行建模。
因子分解机器支持的神经网络(FNN)[35]在应用DNN之前使用预先训练的因子分解机器进行字段嵌入。
乘积型神经网络(PNN)[21]通过在场嵌入层和DNN层之间引入乘积层来对二阶和高阶相互作用进行建模。
类似地,神经因子分解机(NFM)[8]在嵌入层和DNN层之间有一个双向交互池层来模拟二阶交互,但随后的操作是求和而不是PNN中的级联。
另一方面,一些工作试图通过混合体系结构来联合模拟二阶和高阶相互作用。
Wide&Deep [2]和DeepFM [6]包含用于模拟低阶相互作用的宽部分和用于模拟高阶相互作用的深部分。
然而,所有这些利用DNN的方法都以隐式的、逐位的方式学习高阶特征交互,因此缺乏良好的模型可解释性。
最近,一些工作试图通过专门设计的网络以明确的方式学习特征交互。Deep&Cross [31]引入了CrossNet,它在位级别获取特征的外积。
相反,xDeepFM [15]引入了一个CIN来在向量级别上取外积。然而,它们仍然没有解决最基本的问题,即将字段嵌入向量连接在一起。
简单的非结构化特征字段组合将不可避免地限制以灵活和明确的方式对不同字段之间的复杂交互进行建模的能力。
为此,我们提出了一个图结构,其中每个节点代表一个字段和不同的特征字段可以通过边进行交互表示的多字段的功能。
相应地,我们可以在图上对不同特征字段之间的灵活交互进行建模。
2.2图神经网络
图是一种数据结构,它对一组对象(节点)及其关系(边)进行建模。近年来,由于图具有很强的代表性,利用机器学习分析图的研究受到了越来越多的关注。
早期的工作通常是将图结构的数据转换成序列结构的数据来处理。
在word2vec [18]的启发下,[19]提出了一种基于随机游走的无监督DeepWalk算法来学习图中的节点嵌入。
在此基础上,[27]提出了一种网络嵌入算法LINE,该算法保留了网络的一阶和二阶结构信息。[5]提出了引入有偏随机游动的node2vec。
然而,这些方法可能在计算上是昂贵的,并且对于大的图不是最优的。
图神经网络(Graph neural networks,GNN)是一种基于深度学习的、在图域上运行的方法,旨在解决这些问题。
GNN的概念是由[24]首次提出的。一般来说,GNN中的节点通过聚集来自邻域的信息并更新其隐藏状态来与邻居交互。
目前,已经有许多GNN的变体,其中包括各种各样的聚合器和更新器。这里我们只介绍一些有代表性的经典方法。
门控图神经网络(GGNN)[12]使用GRU [3]作为更新器。图卷积网络(GCN)[10]考虑了图的谱结构并利用卷积聚合器。
GraphSAGE [7]考虑了空间信息。介绍了三种聚合器:均值聚合器、LSTM聚合器和Pooling聚合器。
图注意力网络(GAT)[30]将注意力机制并入传播步骤。有一些调查[33,36]对各种GNN模型进行了更详细的介绍。
GNN由于其令人信服的性能和较高的可解释性,已成为一种广泛应用的图分析方法。
近年来,广义神经网络在诸如神经机器翻译[1]、语义分割[20]、图像分类[17]、情景识别[11]、推荐[32]、脚本事件预测[14]、
时尚分析[4,13]等领域有着广泛的应用。GNN本质上适合于对图结构特征上的节点交互进行建模。
本文建立了一个基于广义遗传神经网络(GGNN)的Fi-GNN模型,用于对图结构特征上的特征交互进行建模,并用于CTR预测。
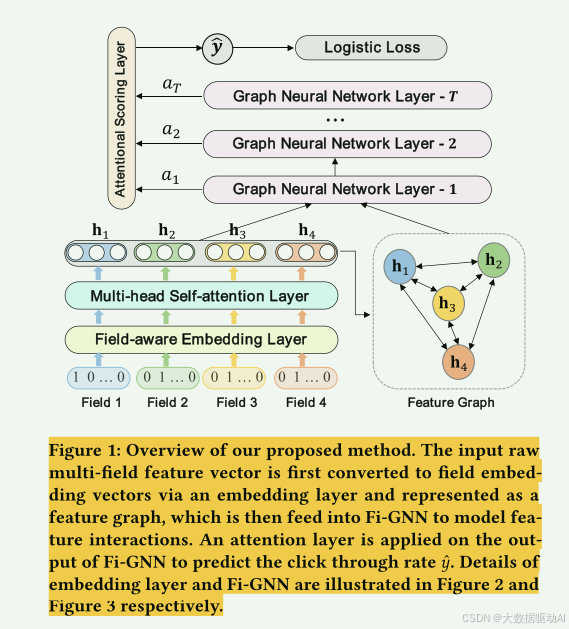
图1:我们提出的方法的概述。首先通过嵌入层将输入的原始多场特征向量转换为场嵌入向量,并表示为特征图,然后将其馈送到Fi-GNN以建模特征交互。在Fi-GNN的输出上应用注意力层来预测点击率y。嵌入层和Fi-GNN的细节分别在图2和图3中示出。
3
第三章 我们提出的方法
我们首先制定的问题,然后介绍我们提出的方法的概述,其次是每个组件的详细说明。
3.1问题公式化
假设训练数据集由m-fields分类特征(m是特征字段的数量)和指示用户点击行为的相关标签y ∈ {0,1}组成。
CTR预测的任务是为输入的m场特征预测y,它估计用户点击的概率。该任务的关键是对不同特征场之间复杂的相互作用进行建模。
3.2概述
图1是我们提出的方法(m=4)的概述。
该算法首先将输入的稀疏m-域特征向量映射为稀疏的单热嵌入向量,然后通过嵌入层和多头自注意层嵌入到稠密域嵌入向量中。
然后将域嵌入向量表示为特征图,其中每个节点对应一个特征域,不同的特征域可以通过边相互作用。
因此,建模交互的任务可以转换为在特征图上建模节点交互。因此,我们将特征图馈入我们所提出的Fi-GNN中以建模节点交互。
在Fi-GNN的输出上应用注意力评分层来估计点击率y。下面,我们将详细介绍我们提出的方法。
3.3嵌入层
多领域分类特征x通常是稀疏的且具有巨大的维数。在前人的工作[6,21,22,31,35]的基础上,
我们将每个域表示为一个单热编码向量,然后将其嵌入到一个稠密向量中,称为域嵌入向量。
让我们考虑第1节中的示例,首先通过one-hot编码将电影
{语言:English,类型:fiction,导演:Christopher Nolan,主演:列奥纳多DiCaprio }转换为高维稀疏特征:

然后,在独热向量上应用字段感知嵌入层,将其嵌入到低维、密集实值字段嵌入向量中,如图??所示。同样,可以获得m场特征的场嵌入向量:
其中ei ∈ Rd表示域i的嵌入向量,d表示域嵌入向量的维数。注意力评分层

3.4多头自注意层
Transformer [29]在NLP中很流行,并且在许多任务中取得了巨大的成功。
在Transformer的核心,多头自注意机制能够在多个语义子空间中建模词对之间的复杂依赖关系。
在CTR预测的文献中,我们利用多头自注意机制来捕获不同语义子空间中特征场对之间的复杂依赖关系,即成对特征相互作用。
在[26]之后,给定特征嵌入E,我们通过缩放点积获得覆盖注意力头i的成对交互的特征的特征表示:
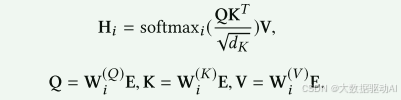
矩阵W(Q)i ∈ Rdi×d,W(K)i ∈ Rdi×d,W(V)i ∈ Rdi×d是注意头i的三个权重参数,di是注意头i的维数,Hi ∈ Rm×di .然后,我们联合收割机组合每个头部的学习特征表示,以保留每个语义子空间中的成对特征交互:

其中,h表示级联操作,h表示关注头的数量。学习的特征表示H1 ∈ Rm×d′用于图神经网络的初始节点状态,其中d′ = n h i=1 di。
3.5特征图谱
与以往的工作不同,我们将场嵌入向量简单地连接在一起,并将它们输入到设计的模型中来学习特征交互,我们将它们表示为图结构。
特别地,我们将每个输入的多域特征表示为特征图G =(N,E),其中每个节点i ∈ N对应于一个特征域i,并且不同的域可以通过边相互作用,
使得|N| = m。由于每两个域都应该相互作用,所以它是一个加权的全连通图,而边的权重反映了不同特征相互作用的重要性。
因此,对特征交互建模的任务可以转换为对特征图上的节点交互建模。
3.6特征交互图神经网络
Fi-GNN是在GGNN [12]的基础上设计的一种特征图上的节点交互建模方法。它能够以灵活和明确的方式对交互进行建模。预备工作。在Fi-GNN中,每个节点i都与一个隐状态向量ht i相关联,图的状态由这些节点状态组成
其中t表示交互作用步骤。通过多头自注意层学习的特征表示被用于它们的初始节点状态H1。如图2所示,节点以循环的方式进行交互并更新其状态。在每一次交互中,节点与邻居节点进行状态信息的聚合,并根据聚合信息和历史信息,通过GRU和剩余连接更新节点状态。接下来,我们将详细介绍Fi-GNN的具体内容。
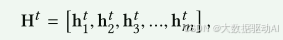
状态汇总。在交互步骤t,每个节点将聚集来自邻居的状态信息。形式上,节点ni的聚合信息是其邻居的变换后的状态信息的和,其中Wp是变换函数。A ∈ Rm×m是包含边权重的邻接矩阵。例如,A[nj,ni ]是从节点nj到ni的边的权值,它可以反映它们相互作用的重要性。显然,变换函数和邻接矩阵决定了节点间的相互作用。由于每条边上的相互作用应该不同,我们的目标是实现逐边的相互作用,这要求每条边都有唯一的权重和变换函数。
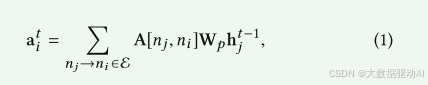
(1)注意力边权重。传统GNN模型中的邻接矩阵通常是二进制形式的,只包含0和1。它只能反映节点之间的连接关系,而不能反映节点之间关系的重要性。
为了推断不同节点之间交互的重要性,我们提出通过注意机制学习边权重。特别地,从节点ni到节点nj的边的权重是利用它们的初始节点状态来计算的,
即,相应的场嵌入向量。从形式上讲,
其中Ww ∈ R2d′是权重矩阵,||是串连运算。softmax函数用于在不同节点之间轻松比较权重。
因此,邻接矩阵是,由于边权重反映了不同交互的重要性,Fi-GNN可以很好地解释输入实例的不同特征字段之间的关系,这将在第4.5节中进一步讨论。
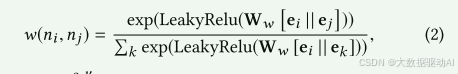

(2)逐边变换。如前所述,所有边上的固定变换函数不能模拟柔性相互作用,并且每个边上的唯一变换是必要的。
然而,我们的图是具有大量边的完备图。简单地为每条边分配唯一的变换权重将消耗太多的参数空间和运行时间。
为了降低时间和空间复杂度并且还实现逐边变换,类似于[4],我们将输出矩阵Wi out和输入矩阵Wi in分配给每个节点ni。
如图2所示,当节点ni向节点nj发送其状态信息时,在nj接收到该状态信息之前,该状态信息将首先由其输出矩阵Wi out进行变换,
然后由节点nj的输入矩阵Wj in进行变换。因此,从节点ni到节点nj的边ni → nj的变换函数可写为:

这样,参数的个数与节点数成正比,而不是与众多边成正比,大大降低了空间和时间复杂度,同时实现了边交互.状态更新。
在聚合状态信息后,节点将通过GRU和剩余连接更新状态向量。
(1)通过GRU进行状态更新。在传统的GGNN中,节点ni的状态向量由GRU根据i处的聚合状态信息和其上一步的状态进行更新。从形式上讲,
其中,Wz,Wr,Wh,bz,br,bh是更新函数门控递归单元(GRU)的权重和偏差[12]。zti和rt i分别是更新门向量和复位门向量。

(2)通过剩余连接进行状态更新。前人的工作[2,25,26]已经证明了将低阶相互作用和高阶相互作用联合收割机结合起来是有效的。
因此,我们引入额外的残差连接来更新音符状态沿着GRU,这可以促进低阶特征重用和梯度反向传播。因此,方程(7)可以被重写为,
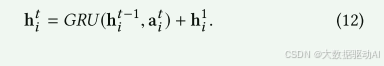
3.7注意力评分层
经过T个传播步后,我们可以得到节点状态HT = hT1,hT2,.,hT m .(高温分钟)由于节点已经与它们的T阶邻居进行了交互,
因此对T阶特征交互进行了建模。我们需要一个图形级的输出来预测CTR。
注意节点权重每个字段节点的最终状态已捕获全局信息。换句话说,这些现场节点是邻居感知的。
在这里,我们分别预测每个领域的最终状态的得分,并使用注意机制将它们相加,该机制测量它们对总体预测的影响。
形式上,每个节点ni的预测得分及其注意力节点权重可以分别经由两个多层感知来估计为,
整体预测是所有节点的总和:y = m i=1 ai yi。(15)注意,它实际上与工作相同[12]。直观地,MLP1用于对知道全局信息的每个字段的预测分数进行建模,并且MLP2用于对每个字段的权重进行建模(即,场对整体预测的影响的重要性)。

3.8 Training
我们的损失函数是Log loss,定义如下:L = − 1 N N i=1(yilo(yi)+(1 −yi)lo(1 − yi)),(16)其中N是训练样本的总数,i是训练样本的索引。
通过使用RMSProp [28]最小化日志丢失来更新参数。大多数CTR数据集的阳性样本和阴性样本比例不平衡,会导致预测结果的不准确。
为了平衡这一比例,在训练过程中,我们在每一批中随机选取相等数量的阳性和阴性样本。
3.8.1参数空间。需要学习的参数主要包括与注意机制中的节点和感知网络相关的参数。
对于每个节点ni,我们有一个输入矩阵Wi in和一个输出矩阵Wi out来变换状态信息。
我们总共有2m个矩阵,它们与节点数m成比例。此外,对于每个头,多头自注意层包含以下权重矩阵n W(Q)i,W(K)i,W(V)i,
并且整个层的参数的数目是(3dd′ + hdd′)。此外,我们在自我注意机制中有两个感知网络矩阵,在GRU中也有参数。
总的来说,有O(2m + hdd′)个矩阵。
3.9模型分析
3.9.1与先前CTR模型的比较。
如前所述,先前基于深度学习的CTR模型以一般范式对高阶交互进行建模:原始稀疏输入多场特征首先被映射到密集场嵌入向量,
然后简单地连接在一起,并馈送到深度神经网络(DNN)或其他专门设计的网络中,以学习高阶特征交互。
简单的非结构化特征字段组合不可避免地限制了以足够灵活和明确的方式对不同字段之间的复杂交互进行建模的能力。
通过这种方式,不同领域之间的交互以固定的方式进行,无论所使用的网络多么复杂。此外,它们缺乏良好的模型解释。
由于我们在图结构中表示多领域特征,因此我们提出的模型Fi-GNN能够以节点交互的形式对不同领域之间的交互进行建模。
与以往的CTR模型相比,Fi-GNN通过灵活的边方向交互函数,能够更有效、更直观地描述复杂的特征交互。
此外,可以在Fi-GNN中学习反映不同相互作用重要性的边权重,这为CTR预测提供了很好的模型解释。
事实上,如果边的权重都是1,并且每条边上的变换矩阵都是相同的,那么我们的模型Fi-GNN会崩溃为FM。
利用GNN的强大功能,我们可以在不同的特征字段上应用灵活的交互。
3.9.2与先前GNN模型的比较。
我们提出的模型Fi-GNN是基于GGNN设计的,主要做了两个改进:
(1)通过注意边权重和边变换实现边交互;
(2)在GRU中引入额外的残差连接沿着来更新状态,这有助于恢复低阶信息。
如前所述,GNN中每条边上的节点交互取决于边的权重和变换函数。
传统的广义高斯神经网络使用二进制边权值,不能反映关系的重要性,并在所有边上使用固定的变换函数。
相比之下,我们提出的Fi-GNN可以通过注意力边权重和边变换函数来对边交互进行建模。
当相互作用阶数高时,节点状态趋于平滑,即,所有节点的状态趋于相似。剩余连接可以通过添加初始节点状态来帮助标识节点。

图2:Fi-GNN的框架。节点与邻居交互,并以循环的方式更新它们的状态。在每个交互步骤中,每个节点将首先聚集来自邻居的转换的状态信息,然后根据聚集的信息和历史通过GRU和剩余连接更新其状态。
4
4 实验
在本节中,我们进行了大量的实验来回答以下问题:
RQ 1与最先进的模型相比,我们提出的Fi-GNN在建模高阶特征交互方面表现如何?
RQ 2我们提出的Fi-GNN在建模高阶特征交互方面是否比原始GGNN表现更好?
RQ 3不同型号配置的影响是什么?
RQ 4不同领域的特征之间有什么关系?我们提出的模型可以解释吗?
在回答这些问题之前,我们首先介绍一些基本的实验设置。
4.1实验装置
4.1.1数据集。
我们在以下两个数据集上评估了我们提出的模型,其统计数据总结在表1中。
1.标准1。这是一个著名的CTR预测行业基准数据集,在显示的广告上的39个匿名特征字段中有4500万用户的点击记录。
给定一个用户和他正在访问的页面,目标是预测他将点击给定广告的概率。
2.阿瓦祖2号。此数据集包含用户在显示的移动的广告上的点击行为。
共有23个功能字段,包括用户/设备功能和广告属性。字段是部分匿名的。
对于这两个数据集,我们分别去除了出现次数少于10次和5次的不频繁特征,并将它们作为单个特征处理<unknown>。
由于数值特征可能具有很大的方差,我们通过将z > 2的值转换为lo 2(z)来归一化数值,这是由Criteo Competition3的赢家提出的。
这些实例以8:1:1的比例随机分配,用于训练、验证和测试。
4.1.2评估指标。
我们使用以下两个指标进行模型评价:AUC(ROC曲线下面积)和Logloss(交叉熵)。
AUC衡量的是一个阳性实例的排名高于随机选择的一个阴性实例的概率。较高的AUC表示较好的性能。
Logloss测量每个实例的预测得分与真实标签之间的距离。较低的Logloss表示较好的性能。相对改善(RI)。
应注意的是,对于真实世界CTR任务,AUC的小幅改善被认为是显著的[2,6,15,31]。
为了估计我们的模型相对于比较模型的相对改善,我们在此测量RI-AUC和RI-Logloss,其可以公式表示为:
这里|X|返回x的绝对值,X可以是AUC或Logloss,model是指我们建议的模型,base是指比较模型。
4.1.3基准线。
如2.1节所述,早期的方法可以分为三种类型:(A)逻辑回归(LR),对一阶交互进行建模;(B)基于因子分解机(FM)的线性模型,对二阶交互进行建模;(C)基于深度学习的模型,对级联场嵌入向量上的高阶交互进行建模。
我们选择了以下三种有代表性的方法与我们的方法进行比较。
LR(A)对原始个体特征的线性组合进行一阶交互建模。
FM [23](B)根据向量内积对二阶特征交互进行建模。
AFM [34](B)是FM的一种扩展,它利用注意机制来考虑不同二阶特征相互作用的权重。它是一个最先进的模型,模拟二阶特征的相互作用。
DeepCrossing [25](C)利用剩余连接的DNN以隐式方式学习高阶特征交互。
NFM [8](C)利用双交互池层来建模二阶交互,然后将级联的二阶组合特征馈送到DNN中来建模高阶交互。
CrossNet(Deep&Cross)[31](C)是Deep&Cross模型的核心,它试图通过在比特级上取级联特征向量的外积来显式地建模特征交互。
CIN(xDeepFM)[15](C)是xDeepFM模型的核心,它在向量级上取堆叠特征矩阵的外积。
4.1.4实施细则。
我们使用Tensorflow 4来实现我们的方法。最优超参数由网格搜索策略确定。基线的实施如下[26]。所有方法的域嵌入向量的维数为16,批量为1024。DeepCrossing有四个前馈层,每个层有100个隐藏单元。NFM在Bi-Interaction层的顶部有一个尺寸为200的隐藏层,如论文[8]中所建议的。CrossNet和CIN都有三个交互层。所有实验均在配备8个NVIDIA Titan X GPU的服务器上进行。
4.2模型比较(RQ 1)
不同方法的性能总结在表2中,从中我们可以得到以下观察结果:
(1)LR在这些基线中实现了最差的性能,这证明了单个特征在CTR预测中的不足。
(2)FM和AFM,这模型的二阶特征的相互作用,优于LR在所有的数据集上,这表明它是有效的模型之间的特征字段的成对的相互作用。另外,AFM比FM具有更好的性能,证明了注意力对不同交互的有效性.
(3)高阶相互作用的建模方法大多优于二阶相互作用的建模方法。这表明二阶特征相互作用是不够的。
(4)DeepCrossing优于NFM,证明了剩余连接在CTR预测中的有效性。
(5)我们提出的Fi-GNN在两个数据集上实现了所有这些方法中的最佳性能。考虑到先前关于0.001水平的AUC的改进对于CTR预测任务来说是重要的,我们提出的方法显示出比这些最先进的方法更大的优越性,特别是在Criteo数据集上,这是由于图结构的强大代表性和GNN在建模节点交互方面的有效性。
(6)与这些基线相比,我们的模型在Criteo数据集上实现的相对改进高于Avazu数据集。这可能是由于Criteo数据集中有更多的特征字段,可以更好地利用图结构的代表性。
我们使用Tensorflow 4来实现我们的方法
4.3消融研究(RQ 2)
我们提出的模型Fi-GNN是基于GGNN的,我们主要做了两个改进:
(1)我们通过注意力边权重和边向变换实现边向节点交互;
(2)我们引入额外的剩余连接来更新状态沿着GRU。为了评估这两种改进对建模节点相互作用的有效性,我们进行了消融研究,并比较了Fi-GNN的以下三种变体:
Fi-GNN(-E/R):没有上述两个改进的Fi-GNN:边缘节点交互(E)和剩余连接(R)。
Fi-GNN(-E):没有边缘相互作用的Fi-GNN(E)。
Fi-GNN(-R):没有剩余连接(R)的Fi-GNN,它也是具有边方向相互作用的GGNN。
性能比较如图3(a)所示,从中我们可以得到以下观察结果:
(1)与FiGNN相比,Fi-GNN(-E)的性能下降了很大一部分,这表明对边缘相互作用进行建模至关重要。Fi-GNN(-E)比Fi-GNN(-E/R)具有更好的性能,证明了剩余连接确实可以提供有用的信息。
(2)完整模型Fi-GNN优于三个变体,表明我们所做的两个改进,即,残余连接和边缘交互可以共同提高性能。连接和边缘交互可以共同提高性能。
我们采取两种措施来实现Fi-GNN中的边节点交互:注意边权重(W)和边变换(T)。为了进一步研究巨大的改善来自哪里,我们进行了另一项消融研究,并比较了Fi-GNN的以下三种变体:
Fi-GNN(-W/T):没有自适应邻接矩阵(W)和逐边变换(T)的Fi-GNN,即,使用二进制邻接矩阵(所有边权重为1)和所有边上的共享变换矩阵。它也是Fi-GNN-(E),
Fi-GNN(-W):没有注意力边缘权重的FI-GNN,即,使用二进制邻接矩阵。
Fi-GNN(-T):没有逐边变换的FI-GNN,即,在所有边上使用共享变换。
性能比较如图3(a)所示。我们可以看到Fi-GNN(-T)和Fi-GNN(-W)都优于Fi-GNN(W/T),这证明了它们的有效性。
然而,Fi-GNN(-W)比Fi-GNN(-T)实现了更大的改进,这表明在建模边向交互时,边向变换比注意边权重更有效。
这是非常合理的,因为转换矩阵应该比标量注意力边缘权重对交互有更强的影响。
此外,FiGNN实现了最佳性能,这表明同时采用这两种措施来建模边缘交互至关重要。
4.4超参数研究(RQ 3)
4.4.1不同状态维度的影响。
我们首先研究w.r.t.节点状态的维数d′,也是初始多头自注意层的输出大小。Criteo和Avazu数据集的结果如图4(a)所示。
在Avazu数据集上,当维数达到32时,性能首先增加,然后开始下降,这表明32的状态大小已经表示了足够的信息,当使用太多参数时,模型会过拟合。
然而,在Criteo数据集上,性能在维度大小为64时达到峰值,这是合理的,因为数据集更复杂,需要更大的维度大小来执行足够的信息。
4.4.2不同交互步骤的影响。
我们感兴趣的是什么最佳的最高阶的功能相互作用。我们提出的Fi-GNN可以回答这个问题,因为交互步骤T等于特征交互的最高阶。
因此,我们进行实验,如何性能变化w.r.t.特征交互的最高阶,即,交互步骤T.Criteo和Avazu数据集的结果如图4(B)所示。
在Avazu数据集上,我们可以看到性能随着T的增加而沿着增加,直到T达到2,之后性能开始下降。相比之下,在Criteo数据集上,当T = 3时,性能达到峰值。
这一发现表明,2阶和3阶相互作用分别适用于Avazu和Criteo数据集。这是合理的,因为Avazu和Criteo数据集分别有23个和39个特征字段。
因此,Criteo数据集需要更多的交互步骤,使字段节点与特征图中的其他节点充分交互。
4.5型号说明(RQ4)
在本节中,我们将回答Fi-GNN能否提供解释的问题。
我们将注意力机制应用于特征图中的边和节点,分别得到了注意力边权重和注意力节点权重,可以从不同的角度给出解释。
4.5.1注意边权重。
注意边权重反映了两个连通场节点之间相互作用的重要性,也可以反映两个特征场之间的关系。
权值越大,相关性越强。图5显示了Avazu数据集中所有样本的全局平均邻接矩阵的热图,它可以反映全局水平上不同字段之间的关系。
由于它们是一些匿名的特征字段,我们只显示其余13个具有真实的含义的特征字段。
可以看出,一些特征字段往往与其他特征字段有很强的关系,例如site_category和site_id。
这是有道理的,因为这两个特征字段都对应于展示的网站。它们包含展示的主要上下文信息。
时间是与其他人有密切关系的另一个特征。这是合理的,因为Avazu专注于移动的场景,用户在一天中的任何时间上网冲浪。
冲浪时间对其他广告特征有很强的影响。另一方面,device_ip和device_id似乎与其他特征字段的关系较弱。
这可能是因为它们几乎等同于用户身份,而用户身份相对固定,不易受其他特征的影响。
4.5.2注意节点权重。
注意力节点权重反映了特征场对整体预测得分影响的重要性。图6给出了全局级和案例级注意力节点权重的热图。
最左边的是Avazu数据集中所有样本的全局平均值。其余4个为随机选取,预测得分分别为[0.97,0.12,0.91,0.99],标签分别为[1,0,1,1]。
在全局水平上,我们可以看到特征字段app_category对点击行为的影响最大。这是合理的,因为Avazu专注于移动的场景,其中应用程序是最重要的因素。
在案例级,我们观察到,在大多数情况下,最终的点击行为主要取决于一个关键特征字段。
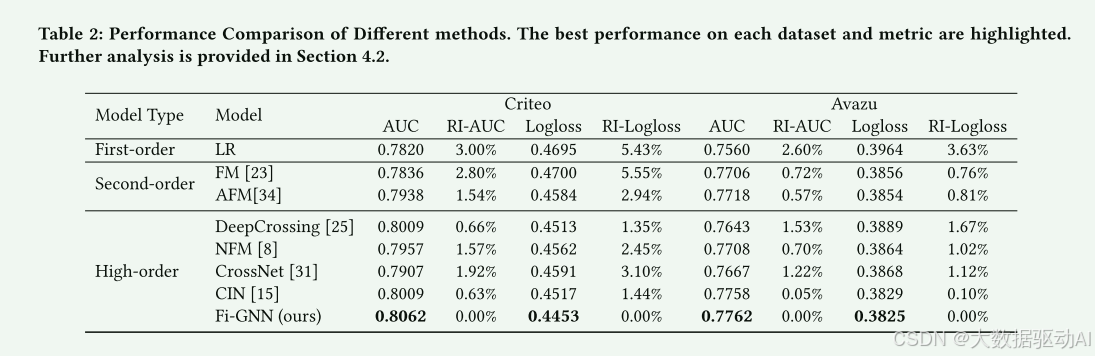
表2:不同方法的性能比较。突出显示每个数据集和指标的最佳性能。进一步分析见第4.2节。
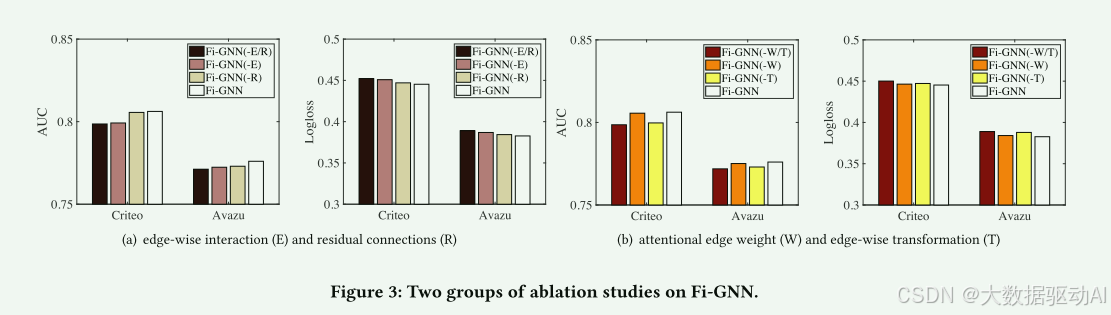
图3:Fi-GNN的两组消融研究。
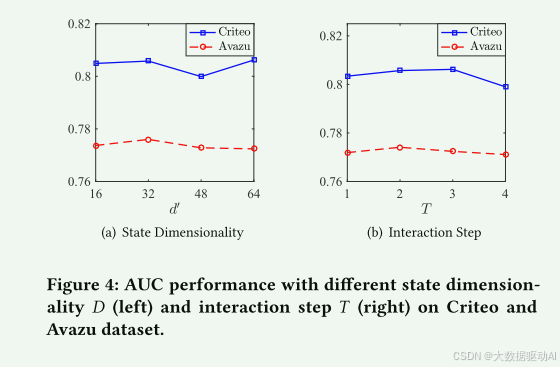
图4:Criteo和Avazu数据集上不同状态维度D(左)和交互步骤T(右)的AUC性能。
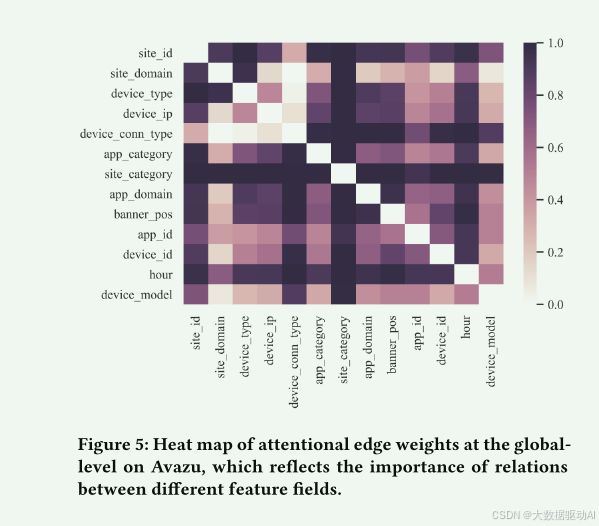
图五:Avazu上全局水平的注意力边缘权重热图,反映了不同特征场之间关系的重要性。
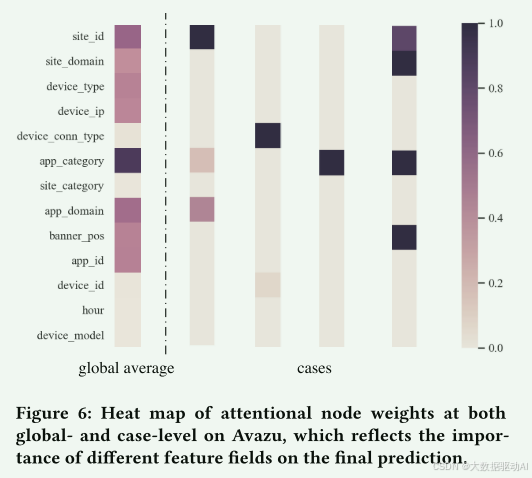
图6:Avazu上全局和案例级别的注意力节点权重热图,反映了不同特征字段对最终预测的重要性。
5
5 结论
首先指出了已有的CTR模型将多场特征看作是特征场的非结构化组合的局限性,并提出了一种新的CTR模型-基于特征场的CTR模型。为了克服这些局限性,
本文首次提出了用图的结构表示多域特征,其中每个节点对应一个特征域,不同的域之间通过边相互作用。因此,可以将建模特征交互转换为图上的建模节点交互。
为此,我们设计了一个新的模型Fi-GNN,它能够以一种灵活和显式的方式对特征场之间复杂的交互进行建模。总之,本文提出了一种新的CTR预测方法:
将多个领域的特征表示在一个图结构中,并将特征间的交互建模转化为图上节点间的交互建模,这将为CTR预测的进一步研究提供参考。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









