







八股王的冒险
前言
索引能够使数据库的查询性能变快,这是大部分人都知道的。但是,为什么能索引使数据库的查询性能变快?最简单的理解就是我们看一本书,如何快速定位到我们想要看到的知识点呢?对了,那就是书的目录,通过查询书的目录可以快速的找到知识点所在的页面。为什么能通过目录就能提高查询的速度呢?我们往下继续看。
一、索引是什么?
索引通过建立额外的数据结构(例如B+树),来存储数据库中数据的一部分信息,这样当你查询数据时,数据库可以使用索引直接定位到数据的存储位置,而不需要逐行扫描整个表,从而大大提高查询效率。
二、B+tree树
一般的,企业里使用的MySQL索引底层都是用的B+tree树来实现的。
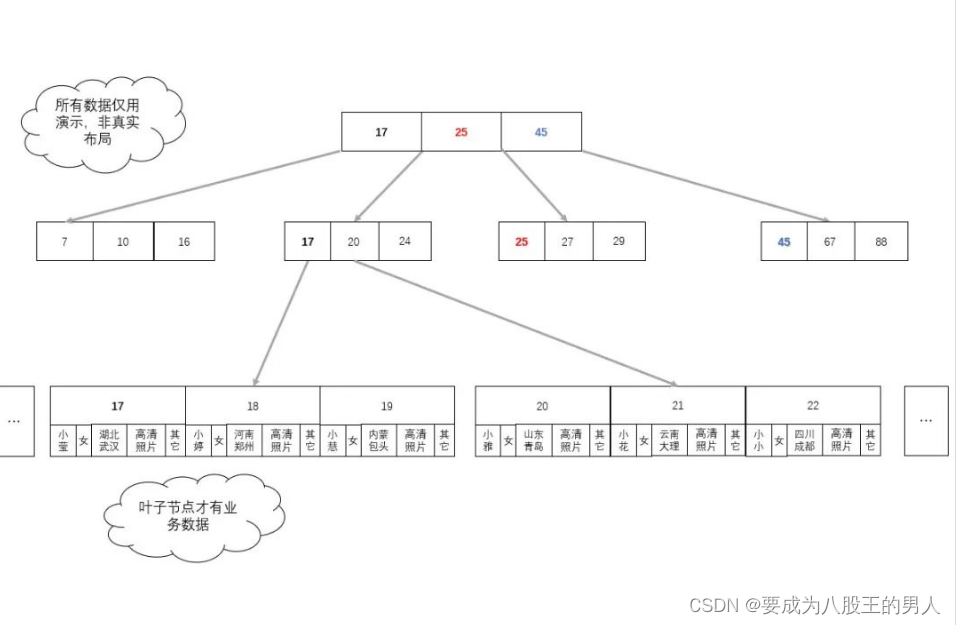
B+树就是为了拆分索引数据与业务数据的平衡二叉树。我们可以发现B+ 树中,非叶子节点只保存索引数据,叶子节点保存索引数据与业务数据。这样即保证了叶子节点的简约干净,数据量大大减小,又保证了最终能查到对应的业务数。但是,在数据中索引与数据是分离的,不像示例那样的?
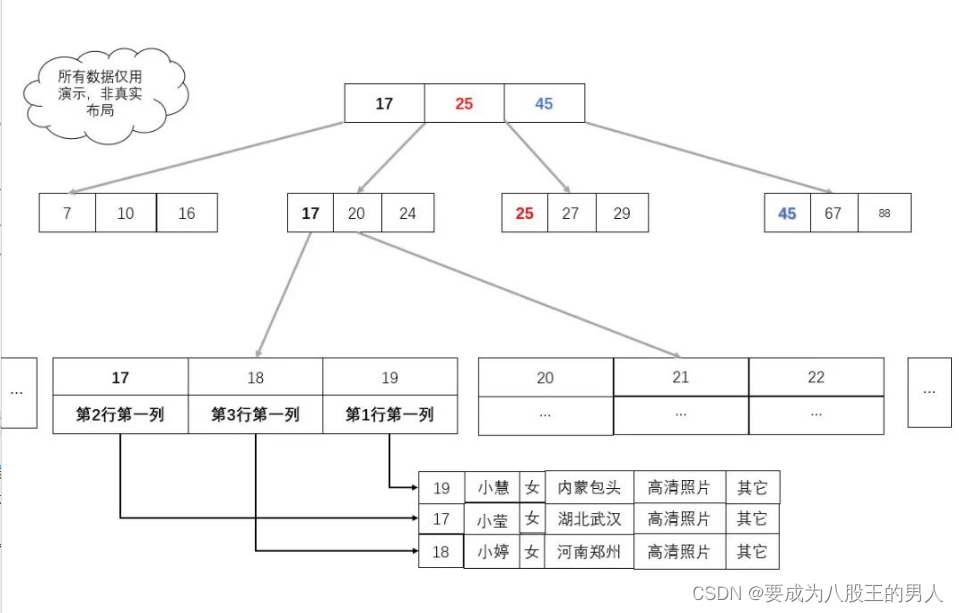
如图:我们只需要把真实的业务数据,换成数据所在地址就可以了,此时,业务数据所在的地址在 B+ 树中充当业务数据。
总结
-
数据存储在磁盘( SSD 跟 CPU 性能也不在一个量级),而磁盘处理数据很慢;
-
提高磁盘性能主要通过减少 I/O 次数,以及单次 I/O 有效数据量;
-
索引通过多阶(一个节点保存多个数据,指向多个子节点)使树的结构更矮胖,从而减少 I/O 次数;
-
索引通过 B+ 树,把业务数据与索引数据分离,来提高单次 I/O 有效数据量,从而减少 I/O 次数;
-
索引通过树数据的有序和「二分查找」(多阶树可以假设为多分查找),大大缩小查询范围;
-
索引针对的是单个字段或部分字段,数据量本身比一条记录的数据量要少的多,这样即使通过扫描的方式查询索引也比扫描数据库表本身快的多;















 105
105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









