





Threshold BBS+ Signatures for Distributed Anonymous Credential Issuance
摘要: 我们提出了一种针对 BBS+ 签名方案的安全多方签名协议;换句话说,这是一种具有门限发行功能的匿名凭证方案。我们证明,由于 BBS+ 签名的结构,仅需验证由一个半诚实协议生成的签名即可实现针对恶意攻击者的可组合安全性。因此,我们的协议极其简单高效:它涉及客户端(需要签名)向签名方的单个请求、签名方之间的两次消息交换,最后是签名方对客户端的一次响应;在某些部署场景下,具体的瓶颈可能是客户端对其接收到的签名进行本地验证的计算开销。此外,我们的协议可以扩展为支持盲签名的最强形式,并可作为 Dodis-Yampolskiy Oblivious VRF 的分布式评估协议使用。我们通过实现和基准测试验证了我们协议的效率主张。
1.引言
匿名凭证(anonymous credential) 允许发行方将权限委托给某个特定的个体,使得该个体可以在不暴露自身身份的情况下使用发行方委托的权限。这个概念最初由 Chaum[1]提出,并在后续的众多研究中[2,3,4,5,6,7,8]得到了改进和完善。匿名凭证满足两个基本的安全特性:
第一个是不可关联性(unlinkability),它保证即使在任意串通的情况下,没有验证者可以将同一凭证的多次使用关联起来
第二个是不可伪造性(unforgeability),它保证未经发行方同意,无法生成有效的凭证。
这些特性是核心的,但还有许多其他属性被定义并实现,例如密钥可验证性(keyed-verifiability)[9,10]和可委托性(delegatability)[11,12,13]。
一种常见且概念上简单的构建匿名凭证方案的方法是将签名方案与满足某些谓词的签名零知识证明相结合[5][14]。凭证本身是发行方的公钥对一条指示授权内容的消息生成的签名,接收凭证的用户通过零知识证明向他人进行认证,而不透露关于凭证的任何信息,仅证明其满足某些谓词。这种基本配置使得凭证持有者相对于凭证验证者是匿名的,但无法在凭证签发过程中实现匿名性。通过使用盲签名协议可以实现签发过程中的匿名性。 为了支持高效的签名零知识证明和盲签名协议,许多研究致力于开发高效的签名方案。
凭证发行方作为单点故障的问题
传统匿名凭证系统中的薄弱点是发行方,因为发行方必须持有用于基础签名方案的密钥。如果发行方被攻破且密钥泄露给攻击者,那么攻击者就能够根据自己的需要生成具有任意属性的有效凭证。由于匿名凭证的特性,这种凭证在使用中通常难以撤销,加之匿名凭证在访问控制和授权管理中的主要用途,其泄露的后果往往极其严重。这种风险可以通过将签发权限安全地分布在多个服务器上来缓解(这些服务器可以由一个实体控制,也可以由多个实体控制),并且必须让许多或所有签发服务器都被攻破,攻击者才能获得伪造的能力。
当一个匿名凭证包含签名方案和签名知识的零知识证明时,分发颁发机构的方法很简单,即通过将颁发者及其签名功能替换为理想功能,该功能在被服务器查询时计算相同的签名函数,服务器之间可以委托颁发机构。 如果这种理想功能通过具有门限 t t t 的门限签名协议实现,并能在组合安全性下对抗恶意攻击者,那么可以确保当最多 t − 1 t-1 t−1 个发行方被攻破时,生成的签名与单一发行方诚实时的签名具有完全相同的安全特性。由于签名协议的可组合性,凭证的任何属性都无需重新证明;签名协议可以简单地被嵌入到任何使用相同类型签名的现有匿名凭证方案中。因此,本文的重点是:以可组合的方式对匿名凭证基础上的签名方案进行阈值化。具体而言,我们选择了著名的BBS+签名方案。
BBS+ 签名。 BBS+ 签名方案由 Au、Susilo 和 Mu [15] 提出,其名称来源于 Boneh、Boyen 和 Shacham [16] 提出的群签名方案,该方案为 BBS+ 的灵感来源。BBS+ 允许一次签署多个消息向量,生成的签名大小取决于安全参数,而与签署的消息数量无关。该方案还支持高效的零知识证明,能够选择性地揭示消息向量中的某些元素;这一特性使其能够作为灵活的匿名凭证。
除此之外,BBS+签名还成为了许多其他隐私保护协议的基础,例如直接匿名证明(Direct Anonymous Attestation,DAA)[17,18],k次匿名认证[15],以及可列入黑名单的匿名凭证[19]。特别值得注意的是由Brickell和Li提出的增强隐私ID(Enhanced Privacy ID,EPID)[17],该方案已部署在Intel的SGX框架中。此外,互联网研究任务组(IRTF)目前正努力将BBS+标准化[20],这一过程得到了去中心化身份基金会(Decentralized Identity Foundation)等行业联盟的广泛支持。
主要困难: BBS+ 方案使用双线性配对来验证指数中的简单关系。签名操作需要计算以下群元素(使用加法椭圆曲线符号表示):
A
:
=
G
1
+
s
⋅
H
1
+
∑
i
∈
[
l
]
m
i
⋅
H
i
+
1
x
+
e
A := \frac{G_1 + s \cdot H_1 + \sum_{i \in [l]} m_i \cdot H_{i+1}}{x + e}
A:=x+eG1+s⋅H1+∑i∈[l]mi⋅Hi+1
其中,
x
x
x 是秘密签名密钥,
m
i
m_i
mi 是输入消息的一部分,
e
e
e 和
s
s
s 是签名随机数。为了对 BBS+ 进行阈值化,必须在
x
x
x 的秘密共享的情况下计算此方程。主要的难点在于签名操作涉及计算
1
(
x
+
e
)
\frac{1}{(x+e)}
(x+e)1:即一个秘密值的逆元,模双线性群的阶。这一操作必须完成,然后计算最终签名,同时保证在对抗恶意对手时的安全性。
1.1. 安全地分发匿名凭证
我们可以将匿名凭证的分发任务视为安全多方计算的实例,并在精心选择的交互性和状态性的约束下进行。我们的系统将包括固定数量的签名服务器(即发行者),它们之间共享密钥,以及许多客户端(可能伪装成服务器),向他们颁发证书。需要注意的是,客户端是短暂的。也就是说,它们不是协议的固定成员,预计只会最小限度地互动(且永远不会相互交流),消耗很少的计算或网络资源,并且在签署会话之间(或者在可能的范围内,甚至在签署会话内部)不保留任何状态。此外,与个人规模的去中心化(如相关于加密货币托管)不同,人们可能会想要隐藏从外部观察者那里签名的分布式事实,而在凭证发行的设置中,完全透明度是可取的,所以我们假设客户端能够单独连接到发行服务器。
客户端通过向服务器发送一个消息向量作为其输入来发起签名请求,服务器在他们之间运行多方计算,并向客户端返回输出。我们希望最大化服务器的吞吐量,因为它们可能同时向许多客户端颁发证书。这一目标往往与最小化服务器响应延迟相一致,从客户端的角度来看。为了实现这一点,我们(指代发行者服务器) 愿意承担客户端侧的计算成本,只要客户端观察到的总发行延迟保持合理具体即可。
理想情况下,我们希望避免复杂的有状态协议,而是将服务器之间的交互限制为两轮消息交换。具体而言,每个服务器向其他所有服务器发送一条消息,然后每个服务器对其收到的消息进行回复。我们将这种模式称为一次“往返通信”,并认为每颁发一个凭证仅进行一次往返通信是合理的,因为这也是支持安全计算的物流信息所需的通信量。例如,协调会话ID(在通用可组合性框架[21]中非常重要)、随机预言机前缀、已颁发凭证的日志记录,以及就是否应向客户端颁发凭证达成共识,这些都需要一次往返通信。我们的通信模型如图1所示。
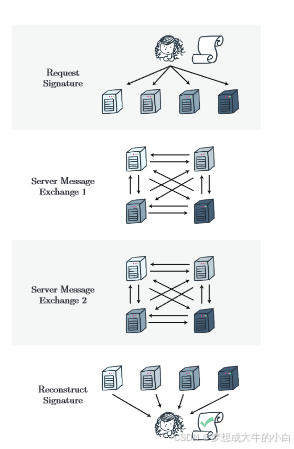
图1:我们考虑一个客户端(即用户)从一个签名服务器组(即凭证发行者)请求签名。服务器执行一个协议,该协议需要两次消息交换,然后才能向客户端发送响应。客户端能够从这些响应中重建一个签名。
我们同样希望避免使用所谓的预处理模型 [22],即在离线阶段生成有限的相关状态并在在线阶段消耗。预处理模型存在状态重用的风险,并且需要定期补充相关状态。
采用哪种安全计算范式? 安全计算的常见技术大致分为以下几种范式:基于加密电路的常数轮协议 [23],[24],[25],算术多方计算(MPC)系统,其轮数复杂度取决于电路的乘法深度 [26],[27],[28],以及最近提出的基于伪随机相关性的方案 [29],[30]。BBS+方案定义在一个大有限域上。对于大有限域上的算术电路,基于加密电路的方法会带来显著的开销,因此我们不进一步采用该方法。尽管伪随机相关性范式前景广阔,但已知的构造要么是在预处理模型中 [29],要么需要非标准的假设或复杂的工具 [30]。算术MPC方法已被证明在大有限域上的计算和带宽效率较高 [28],并且在我们的场景中不会引入过多的交互轮次,因为BBS+签名算法的乘法深度为1。 与大多数算术范式中的协议一样,本文的协议基于线性秘密共享。
当使用线性秘密共享方案时,对秘密数据进行非线性操作的安全计算通常成本较高。在我们的场景中,每次签名都必须对秘密密钥的某个函数求逆 (求逆操作不是线性的)。Bar-Ilan 和 Beaver [31] 提出了一个简洁的模板来解决这一问题,该方法仅需对秘密输入进行一次安全乘法。然而,要在大多数参与方被恶意攻击者破坏的情况下实现安全性并非易事。
来自阈值ECDSA的经验教训。 ECDSA签名算法具有类似于BBS+签名算法的非线性结构。特别地,这两种算法都在类似大小的椭圆曲线群上运行,并且它们的非线性可以追溯到对一个秘密值的逆元。最近,基于密钥管理问题的关注,阈值ECDSA签名协议引起了广泛的兴趣。我们推荐读者参考Aumasson等人[32]的完整阈值ECDSA方案综述,并在此突出一些可以应用于我们问题的关键经验教训:
- 计算资源是瓶颈。 阈值ECDSA所需的最复杂的设备是用于逆元协议的安全乘法[31],通常通过加法同态加密(AHE)[33]、[34]、[35]或不经意传输(OT)[36]、[37]、[38]来实现。两者在具体成本上的权衡大致是,AHE需要较少的带宽,而OT在计算上较轻量。在我们的设置中,假设安全乘法协议由相对良好连接的服务器运行(保守地假设为千兆位连接),因此我们选择了基于OT的方法。Dalskov等人[38]的研究支持了这一决策,他们在DNSSEC的背景下研究了最大化吞吐量的问题。
- 利用问题的结构。 为了实现阈值ECDSA的恶意安全性,需要一个具有恶意安全性的乘法协议,以及一个一致性检查机制,以确保在签名组装过程中,乘法器的各种输入和输出不会被篡改。该机制通常包括零知识证明、SPDZ风格的MACs [39]和ECDSA曲线群中的相等性检查的某种组合。Dalskov等人[38]以及Smart和Alaoui[40]的工作展示了如何在椭圆曲线上实现‘算术黑盒’框架[28]中的任何安全计算的一致性检查。然而,他们的方法涉及相当大的计算和带宽开销,并且需要多轮交互来生成和验证SPDZ风格的MACs。另一方面,Doerner等人[36]、[37]通过检查ECDSA曲线群中的几个关系,避免了通用方法的开销,并证明了篡改这些检查意味着伪造签名或打破同一群体中的标准假设。与Doerner等人一样,我们在本研究中避免了通用方法,研究了如何利用签名本身的结构来验证一致性。
在了解问题的约束和潜在解决方案的基础上,我们现在可以描述我们的方法。
1.2 我们的技术方案
我们采用了Doerner等人[36]开发的单轮往返OT-based乘法器,因为它达到了我们期望的交互复杂度,带来了较低的计算负担,并且可以从BBS+所依赖的相同q-SDH假设中实例化。我们将如何在这个背景下使用Haitner等人[41]的最新OT乘法器作为一个开放问题;他们的构造实现了一个“弱”的乘法功能,可能已经足够,尽管按照他们的描述,他们的协议需要三轮交互。他们实现的完全安全乘法功能在每次调用时会引发数十次椭圆曲线的标量操作,这可能成为计算瓶颈,特别是在使用对偶友好曲线(如BBS+所需的曲线)时。
我们从这个乘法器构建的签名协议不需要额外的轮次,且服务器之间的交互仅需最小化的额外操作。我们在Canetti的通用可组合性框架[21]中证明了我们的协议的安全性,依据的是一个简单的理想功能,该功能在发行者服务器达成一致生成签名时,内部执行BBS+凭证颁发者的算法。由于该功能仅仅执行签名方案,它作为一个直观的替代品,可以取代集中式凭证颁发者。此外,可组合的安全性保证使得凭证请求可以按任意顺序进行,并且生成独立的并发实例。我们将我们的安全性概念形式化为Functionalities 3.1。
协议模板。 一个BBS+签名由三元组 ( A , e , s ) (A,e,s) (A,e,s)组成,其中 A ∈ G 1 A\in \mathbb{G}_1 A∈G1是支持配对的椭圆曲线上的点, e e e和 s s s是从该曲线阶定义的有限域中的值。当客户端向一组服务器发送签名请求时,它们会参与一个协议来生成 e e e和 s s s,并且共享 A A A中的份额 A i A_i Ai。然后这些值通过服务器单独地传达给客户端,客户端从分享中组装 A A A并验证 ( A , e , s ) (A,e,s) (A,e,s)确实是一个有效的签名。虽然 A A A是椭圆曲线上的一个点,但每个共享 A i A_i Ai都包含一个曲线点 R i R_i Ri和一个来自曲线阶域的元素 u i u_i ui,并且 A A A的重构操作定义为 A : = ∑ i R i ∑ i u i A:= \frac{\sum_i R_i}{\sum_i u_i} A:=∑iui∑iRi。为了采样这样的 A A A共享,服务器在曲线阶群中以秘密共享的形式 r i r_i ri均匀抽样 r r r。由此他们计算初 u = r ⋅ ( x + e ) u=r\cdot(x+e) u=r⋅(x+e)的秘密份额 u i u_i ui。如果 B B B是服务器和客户端都可以从消息和 s s s派生的公共值,那么设置 R i = r i ⋅ B R_i=r_i\cdot B Ri=ri⋅B会产生如上定义的值 A A A的份额 A i = ( R i , u i ) A_i=(R_i,u_i) Ai=(Ri,ui)。这基本上是Bar-Ilan和Beaver安全求逆技术的一个版本[31]。创新性和难点在于确保在这个框架中没有恶意对手作弊。
验证一致性。 假设乘数是理想的安全的(正式地,在
F
M
u
l
2
P
F_{Mul2P}
FMul2P混合模型中),我们表明要实现对恶意对手的安全性,客户端只需检查
(
A
,
e
,
s
)
(A,e,s)
(A,e,s)值是否确实为有效凭证即可。虽然人们普遍认为多方计算协议的一致性可以通过检查数字签名等“自验证”对象来简单地验证,但证明在出现错误签名的情势下没有信息泄露是微妙的。特别是,这类民间传说论点往往忽略了选择性失败攻击的可能性,在这种攻击中,作弊对手可以慢慢地通过诱导与其它方秘密相关的失败来了解其他方的密钥。防御此类攻击通常需要复杂的零知识证明技术。
相比之下,从高层次来看,我们观察到份额
r
i
r_i
ri充当线性MAC密钥,重建涉及隐含地对
A
A
A进行MAC检查,而
A
A
A由
e
,
s
e,s
e,s和公钥固定。我们表明如果一个服务器作弊并通过了这一正确性检查,那么它实际上伪造了一个签名(但在这种情况下,输出签名是正确的,协议不会终止,并且对手什么也没有学到)。我们将这种隐式MAC与通用MPC方法使用的显式MAC进行了对比——计算显式MAC会引入大约两倍的通信开销,并且验证和使用它来进行正确性检查需要几轮额外的交互。
概念上,这使得我们可以将BBS+签名放在Schnorr和ECDSA之间,在去中心化的复杂度方面。具体来说,Schnorr签名已知即使具有UC安全性也很容易去中心化[42],仅需要承诺和知识证明。ECDSA需要多次调用安全乘法,以及通过隐式MAC进行的尽可能多的伴随一致性检查,其中一些是计算性的[37]。特别是,所有现代的ECDSA阈值协议都需要额外的工作来确保不同乘法器的输入是一致的。我们分散BBS+的协议在ECDSA和Schnorr之间插入中间的去中心化复杂度,因为它只需要一次安全乘法的调用,从而对应于无需额外一致性检查的信息理论隐式MAC检查。
扩展。 Okamoto的签名方案[43]可以被看作是BBS+的一种变体,因此可以通过我们的方案来实现门限化。正如我们在第5节中所讨论的那样,我们的技术也可以用于分发Dodis和Yampolskiy的可验证随机函数的计算[44]。此外,由于我们的服务器所需维护的状态包括加法秘密密钥份额和乘法器所用的OT扩展[45]的基本OT,我们可以使用Kondi等人[46]的激活方案来刷新系统的状态,并抵御移动攻击者[47]。
1.3. 先前论文作品
Dodis和Yampolskaya [44] 提出了一种可验证的随机函数(VERF)的形式
F
x
(
e
)
→
e
(
G
1
,
G
2
)
/
(
x
+
e
)
F_x(e) \rightarrow e(G_1, G_2)/(x + e)
Fx(e)→e(G1,G2)/(x+e),其中
G
1
G_1
G1和
G
2
G_2
G2是椭圆曲线上的点,
e
e
e是
x
+
e
x + e
x+e的证明形式
π
=
G
1
/
(
x
+
e
)
\pi = G_1/(x + e)
π=G1/(x+e)。这个结构非常类似于BBS+签名方案。Dodis和Yampolskaya自己建议他们的VERF可以通过Bar-Ilan和Beaver [31]的反转技巧来评估;我们的协议可以被视为添加恶意安全性的最简单方式,而且可以在不改变分布式VERF构造的情况下增加恶意安全性。此外,我们的方案还可以扩展到使阈值VERF变得不可知。我们将在第5节进一步讨论这一点。
BBS+签名方案的阈值化问题先前由Goldfeder、Gennaro和Ithurburn[48]提出。这个解决方案,就像我们的方案(以及DodisYampolskiy方案)一样,从Bar-Ilan和Beaver的反演协议开始。然而,我们的方案在几个重要方面是不同的。这项工作提供了独立安全性的整体证明,而我们在UC范式中提供了可组合安全性的完整模块化证明。特别是,我们的方案基于理想的乘法功能,根据与BBS+签名方案相同的假设,可以在两轮内实现。另一方面,他们的方法则是硬编码一种基于Paillier加密的乘法策略。这可能会降低效率,因为尚不清楚他们的方案是否可以像我们的方案一样只需要一次往返通信,并且因为保护基于pailer的乘法器需要零知识范围证明,这比协议的任何其他组件都要昂贵得多。这也降低了安全性,因为这意味着他们的协议依赖于强RSA假设(与底层签名方案完全无关)。更麻烦的是,[48]中使用的乘法技术在阈值ECDSA签名[49],[50];这对BBS+协议的影响目前尚不清楚。最后,与[48]方案不同,我们的方案不需要向模拟器透露A,以便在客户端是诚实的情况下模拟协议。实现这一点需要一些微妙的分析,但它为完全盲签名扩展打开了大门,并将我们的协议应用于前面提到的阈值无关的VRF问题。由于所有这些原因和我们协议的简单性,我们还能够在第7节中提供具有具体基准的实现。
Sonnino、Al-Bassam、Bano、Meiklejohn和Danezis[51]也给出了支持阈值发放的匿名凭证方案。这个方案Coconut主要基于Pointcheval和Sanders [52] (PS签名)的签名方案,它们的安全性基于与LRSW[4]类似但不等同于LRSW[4]的交互假设。在凭证显示效率方面,Coconut和我们的工作相似,因为它们都需要证明和验证一个2条款的非交互式零知识知识证明。然而,Rial和Piotrowska [53] (RP-Coconut)的后续论文通过Sonnino等人的证明草图识别了安全问题,并提供了一个补丁。为了证明不可伪造性,RP-Coconut需要增加公钥的大小,增加到l个 G 1 G_1 G1元素加上 l + 1 l+1 l+1个 G 2 G_2 G2元素。这几乎是Coconut公钥大小的两倍,后者需要 l + 1 l+1 l+1个 G 2 G_2 G2元素。相比之下,我们的方案只需要一个 G 1 G_1 G1和一个 G 2 G_2 G2元素。此外,BBS+签名与所有组类型兼容,而PS签名则专门需要3型配对。正如Pointcheval和Sanders[52]所写的那样,存在一个有效的同构关系在 G 1 G_1 G1和 G 2 G_2 G2之间将使他们的签名方案“完全不安全”。最后,值得注意的是Rial和Piotrowska为RP-Coconut提供了一个顺序安全的模拟基础证明。与UC模型的证明不同,顺序安全性不能保证协议的同时或并行执行。
2. 预备知识
符号。我们使用λ表示(计算的)安全参数,n表示参与方的数量。符号 ≈ c \approx_c ≈c和 ≈ s \approx_s ≈s分别表示关于λ的计算和统计不可区分性。 G 1 \mathbb{G}_{1} G1、 G 2 \mathbb{G}_{2} G2和 G T \mathbb{G}_{T} GT表示三个素数阶p的群,其中 ∣ p ∣ = κ |p|=κ ∣p∣=κ,并且我们对这些群的运算采用加法表示。按照约定,代表群元素的变量是大写的, G 1 \mathbb{G}_{1} G1和 G 2 \mathbb{G}_{2} G2的生成元分别是 G 1 G_{1} G1和 G 2 G_{2} G2。单个字母变量用斜体字表示,多字母变量和函数名称用无衬线字体表示,字符串文字用粗体无衬线字体表示。粗体表示向量。
双线性群。 一个双线性群(或配对群)是由三组群 ( G 1 , G 2 , G T ) (\mathbb{G}_1, \mathbb{G}_2, \mathbb{G}_T) (G1,G2,GT)组成的三重奏,它有一个高效的映射(或配对)操作 e : G 1 × G 2 → G T e: \mathbb{G}_1 \times \mathbb{G}_2 \rightarrow \mathbb{G}_T e:G1×G2→GT,使得对于任何 x , y ∈ Z p x,y \in \mathbb{Z}_p x,y∈Zp,都有 e ( x ⋅ G 1 , y ⋅ G 2 ) = x ⋅ y ⋅ e ( G 1 , G 2 ) e(x \cdot G_1, y \cdot G_2) = x \cdot y \cdot e(G_1, G_2) e(x⋅G1,y⋅G2)=x⋅y⋅e(G1,G2)。我们将BilinGen定义为一个高效算法 ( G 1 , G 2 , G 1 , G 2 , p ) = G ← B i l i n G e n ( λ ) (\mathbb{G}_1, \mathbb{G}_2, G_1, G_2, p)=\mathcal{G} \leftarrow BilinGen(\lambda) (G1,G2,G1,G2,p)=G←BilinGen(λ),它采样了一个群 G \mathcal{G} G的描述(具有λ位的安全性)。有三种种类的配对[54]: type-1,在这种情况下 G 1 = G 2 \mathbb{G}_1=\mathbb{G}_2 G1=G2;type-2,在这种情况下 G 1 ≠ G 2 \mathbb{G}_1 \neq \mathbb{G}_2 G1=G2且存在一个高效的同构 ψ : G 2 → G 1 \psi:\mathbb{G}_2 \rightarrow \mathbb{G}_1 ψ:G2→G1;以及type-3,在这种情况下 G 1 ≠ G 2 \mathbb{G}_1 \neq \mathbb{G}_2 G1=G2且不存在一个高效的同构 ψ \psi ψ。
2.1.BBS+签名方案
BBS+签名方案使用双线性群为长度为的消息向量产生一个签名。它的算法如下所示。
算法2.1.BBS+Gen(G,ℓ)
1.令(
G
1
,
G
2
,
G
1
,
G
2
,
p
G_1,G_2,G_1,G_2,p
G1,G2,G1,G2,p):=G。
2.从
G
ℓ
+
1
G_{\ell+1}
Gℓ+1中抽取一个长度为ℓ+1的随机群元素向量H。
3.均匀选择秘密密钥
x
←
Z
p
∗
x \leftarrow Z_p^*
x←Zp∗ 。
4.计算
X
:
=
x
⋅
G
2
X:=x·G_2
X:=x⋅G2。
5.设
s
k
=
(
H
,
x
)
sk=(H,x)
sk=(H,x)和
p
k
=
(
H
,
X
)
pk=(H,X)
pk=(H,X)。
6.输出
(
s
k
,
p
k
)
(sk,pk)
(sk,pk)。
算法2.2.BBS+Sign(sk,m∈
Z
p
ℓ
Z_p^\ell
Zpℓ)
1.解析sk为
(
H
,
x
)
(H,x)
(H,x)。
2.均匀抽样单次
e
←
Z
p
e←Z_p
e←Zp和
s
←
Z
p
s←Z_p
s←Zp。
3.计算
A
=
G
1
+
s
⋅
H
1
+
∑
k
∈
[
ℓ
]
m
k
⋅
H
k
+
1
x
+
e
A=\frac{G_1+s\cdot H_1+\sum_{k\in[\ell]}m_k\cdot H_{k+1}}{x+e}
A=x+eG1+s⋅H1+∑k∈[ℓ]mk⋅Hk+1
4.输出签名σ≔(A,e,s)。
算法2.3.BBS+Verify(pk,m,σ)
1.解析pk为(H,X)和σ为(A,e,s)。
2.检查以下等式是否成立:
e
(
A
,
X
+
e
⋅
G
2
)
=
e
(
G
1
+
s
⋅
H
1
+
∑
k
∈
[
ℓ
]
m
k
⋅
H
k
+
1
,
G
2
)
e(A,X+e\cdot G_2)=e(G_1+s\cdot H_1+\sum_{k\in[\ell]}m_k\cdot H_{k+1},G_2)
e(A,X+e⋅G2)=e(G1+s⋅H1+k∈[ℓ]∑mk⋅Hk+1,G2)
仅在等式成立时输出1。
Au等人[15]介绍了BBS+,并证明了它在类型-1和类型-2配对下是安全的,使用了原始的“会议版”qSDH假设[55]。
引理 2.4 ([15])。 BBS + 签名方案在适应性选择的消息下,在type - 1 和type - 2 配对下的 q-SDH 假设的会议版本下,是存在性的不可伪造的。
后来Camenisch等人在更新了qSDH假设[56]的“期刊版本”下,证明了BBS+的安全性,而不需要对3型配对的同构存在(或不存在)任何假设。
引理2.5 ([18])。 在期刊版本的q-SDH假设下,针对类型3对的自适应选择消息,BBS+签名方案存在不可伪造性。
请注意,虽然BBS+签名方案需要q-SDH假设来实现不可伪造性,并且在相同的假设下也可以安全地实例化遗忘传输,但我们的协议在“OT-hybrid model”中是安全的,因此不特别需要q-SDH或任何计算假设。
对比Okamoto Signatures。 Okamoto的签名方案[43]最初是在构造盲签名的背景下提出的。正如Au等人之前所观察到的,BBS+可以被看作是Okamoto签名的扩展,用于对消息块进行签名。除了签署的消息数量不同外,方案的主要区别在于其安全性证明。Okamoto论文的原始会议版本引入了2个变量强DiffieHellman (2SDH)假设,并证明了该假设的一种变体下的安全性。后来的论文[57]版本修改了证明,在会议版本的q-SDH下实现了安全性。这个证明的两个版本都依赖于群之间的同构。已知Okamoto签名是强存在不可伪造的,而Au等人[15]和Camenisch等人[18]则声称BBS+仅具有标准不可伪造性。我们的技术可以很容易地适应Okamoto方案的阈值化。
2.2盲签名。
一个盲签名协议允许拥有私钥的签名者对一个属于其他方的消息进行签名,而不了解消息的内容。在弱盲签名方案中,只有消息是被隐藏的,而在强盲签名方案中,生成的签名也是对签名者隐藏的,这样它就不能用来以后识别客户。在这项工作中,我们实现了弱部分盲签名。这是一种弱盲签名的变体,在这种变体中,消息对签名者是隐藏的,但是签名者接收到了一个证明,这个证明表明消息满足某些谓词。通过这种方式,即使签名者是盲目地签名,也可以强制执行任意的签名策略。在阈值上下文中,我们将允许客户端(请求和接收签名的人)向每个签名者证明不同的谓词。注意,弱部分盲性意味着弱盲性:客户端只需要省略谓词。
2.3通用可组合性
我们将协议形式化,并使用标准的UC符号在通用可组合性(UC)框架中证明它们的安全性。我们建议读者参考Canetti[21]了解该模型的完整描述,并在此处进行简要概述。
在UC框架中,现实世界的实验涉及n个方 P 1 , ⋯ , P n P_{1}, \cdots, P_{n} P1,⋯,Pn,它们执行一个协议 π \pi π,一个可以破坏一组方的对手 A A A,以及一个初始化了建议串 z z z的环境 Z Z Z。所有实体都使用安全参数 λ \lambda λ和一个随机磁带进行初始化。环境激活参与 π \pi π的各方,选择它们的输入并接收输出,并与可能指示被破坏的各方任意偏离 π \pi π的对手 A A A通信。在本工作中,我们只考虑静态对手,他们在实验开始时宣布他们的破坏行为。当 Z Z Z停止激活各方并输出一个决策位时,现实世界实验完成。令REAL π , A , Z ( λ , z ) _{\pi,A,Z}(\lambda,z) π,A,Z(λ,z)表示代表实验输出的随机变量。
理想世界实验涉及
n
n
n 个虚拟方
P
1
,
…
,
P
n
P_1, \ldots, P_n
P1,…,Pn、一个理想功能
F
\mathcal{F}
F、一个理想世界敌手
S
S
S(模拟器)和一个环境
Z
\mathcal{Z}
Z。这些虚拟方将从
Z
\mathcal{Z}
Z 收到的任何消息转发到
F
\mathcal{F}
F,反之亦然。模拟器可以选择性地破坏虚拟方子集,并在其 behalf 上与
F
\mathcal{F}
F 交互;此外,
S
S
S 可以直接根据规范与
F
\mathcal{F}
F 进行通信。环境和模拟器在整个实验过程中都可以相互交互,模拟器的目标是欺骗环境使其相信自己在运行真实实验。当
Z
\mathcal{Z}
Z 停止激活各方并输出一个决策比特时,理想世界实验结束。设 IDEAL
F
,
S
,
Z
(
λ
,
z
)
_{\mathcal{F}, S, \mathcal{Z}} (\lambda, z)
F,S,Z(λ,z) 表示实验输出的随机变量。
一个协议
π
\pi
π 实现(UC-realizes)一个功能
F
\mathcal{F}
F 当且仅当对于每一个概率多项式时间(PPT)敌手
A
A
A 存在一个 PPT 模拟器
S
S
S 使得对于每一个 PPT 环境
z
z
z,
{
R
E
A
L
π
,
A
,
Z
(
λ
,
z
)
}
λ
∈
N
+
,
z
∈
0
,
1
p
o
l
y
(
λ
)
≈
c
{
I
D
E
A
L
F
,
S
,
Z
(
λ
,
z
)
}
λ
∈
N
+
,
z
∈
0
,
1
p
o
l
y
(
λ
)
\{ REAL_{\pi, A, Z} (\lambda, z)\}_{\lambda \in \mathbb{N}^+, z \in {0, 1}^{poly(\lambda)}} \approx_c \{ IDEAL_{\mathcal{F}, S, \mathcal{Z}} (\lambda, z) \}_{\lambda \in \mathbb{N}^+, z \in {0, 1}^{poly(\lambda)}}
{REALπ,A,Z(λ,z)}λ∈N+,z∈0,1poly(λ)≈c{IDEALF,S,Z(λ,z)}λ∈N+,z∈0,1poly(λ)
3.Functionalities(函数)
我们给出了我们希望协议实现的理想功能。
功能性3.1.
F
B
B
S
+
(
n
,
t
,
G
)
\mathscr{F}_{BBS+}(n,t,\mathcal{G})
FBBS+(n,t,G)
该功能性与
n
n
n个固定参与者进行交互,这些参与者分别表示为
P
1
,
.
.
.
,
P
n
\mathcal{P}_1,...,\mathcal{P}_n
P1,...,Pn,以及预先未指定的数量的临时客户端,所有这些都表示为
C
\mathcal{C}
C,并与理想的对手
S
S
S一起工作。客户端可以是任何参与者的别名。腐败参与者的集合通过
P
∗
\mathcal{P}^*
P∗索引。该功能还参数化了一个阈值
t
≤
n
t\leq n
t≤n和双线性群
G
\mathcal{G}
G的描述。
Key Generation: 当接收到来自每个方 P i P_i Pi 的 ( k e y − g e n , s i d , ℓ ) (key-gen, sid, \ell) (key−gen,sid,ℓ) 时,对于 i ∈ [ n ] i \in [n] i∈[n],其中 ℓ ∈ N + \ell \in \mathbb{N}^{+} ℓ∈N+ 是已达成一致的,sid 是已达成一致且新鲜的,如果在内存中没有记录形如 ( k e y , s i d , ∗ , ∗ ) (key, sid, *, *) (key,sid,∗,∗) 的记录,则采样 ( s k , p k ) ← B B S + - G e n ( G , ℓ ) (sk, pk) \leftarrow BBS^+\text{-}Gen(\mathcal{G}, \ell) (sk,pk)←BBS+-Gen(G,ℓ),存储 ( k e y , s i d , s k , p k , ℓ ) (key, sid, sk, pk, \ell) (key,sid,sk,pk,ℓ) 到内存中,并发送 ( p u b − k e y , s i d , p k ) (pub-key, sid, pk) (pub−key,sid,pk) 给每个方 P i P_i Pi 对于 i ∈ [ n ] i \in [n] i∈[n] 作为敌手延迟的私有输出。
Signing: 当接收到来自 C C C 的 ( s i g n , s i d , s i g i d , m , J ) (sign, sid, sigid, m, J) (sign,sid,sigid,m,J) 时,其中 m ∈ Z ℓ p m \in \mathbb{Z}_\ell^p m∈Zℓp, J ⊆ [ n ] J \subseteq [n] J⊆[n], ∣ J ∣ = t |J| = t ∣J∣=t,并且 sigid 是新鲜的,如果在内存中有记录形如 ( k e y , s i d , s k , p k , ℓ ) (key, sid, sk, pk, \ell) (key,sid,sk,pk,ℓ) 的记录,则发送 ( s i g − r e q , s i d , s i g i d , m , J ) (sig-req, sid, sigid, m, J) (sig−req,sid,sigid,m,J) 给每个方 P j P_j Pj 对于 j ∈ J j \in J j∈J。当接收到来自每个 P j P_j Pj 的 ( a c c e p t , s i d , s i g i d ) (accept, sid, sigid) (accept,sid,sigid) 对于 j ∈ J j \in J j∈J 时,计算 ( A , e , s ) ← B B S + - S i g n ( s k , m ) (A, e, s) \leftarrow BBS^+\text{-}Sign(sk, m) (A,e,s)←BBS+-Sign(sk,m),发送 ( l e a k a g e , s i d , s i g i d , e , s ) (leakage, sid, sigid, e, s) (leakage,sid,sigid,e,s) 给 S S S 并发送 ( s i g n a t u r e , s i d , s i g i d , ( A , e , s ) , p k , J ) (signature, sid, sigid, (A, e, s), pk, J) (signature,sid,sigid,(A,e,s),pk,J) 给 C C C 作为敌手延迟的私有输出。如果任何 P j P_j Pj 而不是发送 ( r e j e c t , s i d , s i g i d ) (reject, sid, sigid) (reject,sid,sigid),则发送 ( r e j e c t e d , s i d , s i g i d ) (rejected, sid, sigid) (rejected,sid,sigid) 给 C C C 作为敌手延迟的私有输出。
Weak Partially-Blind Signing: 当接收到来自 C C C 的 ( w b − s i g n , s i d , s i g i d , m , J , ϕ ) (wb-sign, sid, sigid, m, J, \phi) (wb−sign,sid,sigid,m,J,ϕ) 时,其中 m ∈ Z ℓ p m \in \mathbb{Z}_\ell^p m∈Zℓp, J ⊆ [ n ] J \subseteq [n] J⊆[n], ϕ \phi ϕ 是关于 m m m 的谓词描述的向量, ∣ J ∣ = ∣ ϕ ∣ = t |J| = |\phi| = t ∣J∣=∣ϕ∣=t,并且 sigid 是新鲜的,如果在内存中有记录形如 ( k e y , s i d , s k , p k , ℓ ) (key, sid, sk, pk, \ell) (key,sid,sk,pk,ℓ) 的记录,并且如果 ϕ j ( m ) = 1 \phi_j(m) = 1 ϕj(m)=1 对于每一个 j ∈ J ∖ P ∗ j \in J \setminus P^* j∈J∖P∗,则发送 ( s i g − r e q , s i d , s i g i d , ϕ j , J ) (sig-req, sid, sigid, \phi_j, J) (sig−req,sid,sigid,ϕj,J) 给每个方 P j P_j Pj 对于 j ∈ J j \in J j∈J。当接收到来自每个 P j P_j Pj 的 ( a c c e p t , s i d , s i g i d ) (accept, sid, sigid) (accept,sid,sigid) 对于 j ∈ J j \in J j∈J 时,计算 ( A , e , s ) ← B B S + - S i g n ( s k , m ) (A, e, s) \leftarrow BBS^+\text{-}Sign(sk, m) (A,e,s)←BBS+-Sign(sk,m),发送 ( l e a k a g e , s i d , s i g i d , e , s ) (leakage, sid, sigid, e, s) (leakage,sid,sigid,e,s) 给 S S S 并发送 ( s i g n a t u r e , s i d , s i g i d , ( A , e , s ) , p k , J ) (signature, sid, sigid, (A, e, s), pk, J) (signature,sid,sigid,(A,e,s),pk,J) 给 C C C 作为敌手延迟的私有输出。如果任何 P j P_j Pj 而不是发送 ( r e j e c t , s i d , s i g i d ) (reject, sid, sigid) (reject,sid,sigid),则发送 ( r e j e c t e d , s i d , s i g i d ) (rejected, sid, sigid) (rejected,sid,sigid) 给 C C C 作为敌手延迟的私有输出。
请注意,前述接口中的弱部分盲签名接口可以通过简单地移除向对手泄露的信息转换为强部分盲签名接口。我们将在第5节讨论如何实现这种修改后的功能。
3.1 Building Blocks(构建块)
我们现在将定义我们协议的基本构建模块。我们从通信模型开始:每对参与者都可以通过认证通道进行通信,我们还假定存在广播通道。形式化地,该协议是在 ( F A u t h , F B C ) (\mathcal{F}_{Auth}, \mathcal{F}_{BC}) (FAuth,FBC)混合模型中定义的(见[21]、[58])。我们在他们的描述中隐含了这一点。由于我们只想实现带有中止的安全性,我们的广播通道可以通过回声广播技术[59]来实现。具体来说,各方乐观地在点到点信道上发送广播消息,最后,每个参与方都会对广播消息的全部转录进行哈希处理,并将摘要发送给所有其他参与方。如果摘要不一致,各方就会中止。
标准功能。 各方使用标准的承诺、零知识及承诺零知识功能;
F
C
o
m
\mathcal{F}{Com}
FCom 、
F
Z
K
\mathcal{F}{ZK}
FZK 和
F
C
o
m
−
Z
K
\mathcal{F}{Com-ZK}
FCom−ZK 分别表示这些功能。我们指定承诺和零知识功能以广播方式工作,但除此之外它们与标准版本类似[58]。各方还使用一种功能
F
Z
e
r
o
\mathcal{F}{Zero}
FZero ,用于产生特定组的零秘密共享。这些功能在附录A中给出。
F
C
o
m
\mathcal{F}{Com}
FCom 和
F
Z
e
r
o
\mathcal{F}{Zero}
FZero 都可以通过简单的民间方法实现。
F
C
o
m
\mathcal{F}{Com}
FCom 通过将待承诺值连同长度为安全参数长度的随机盐一起喂入随机预言机,然后将预言机的输出作为承诺,盐和原始值一起作为打开,在随机预言机模型中实现。
F
Z
e
r
o
\mathcal{F}{Zero}
FZero 可以通过以下方式实现:每一对方彼此承诺和解密一对λ位种子,然后将其相加以形成单个共享种子。当调用
F
Z
e
r
o
\mathcal{F}_{Zero}
FZero 时,每一对方都在他们共享的种子与下一个索引串联的情况下评估随机预言机。然后每个方通过累加随机预言机的输出来为自己计算单个输出份额:它减去自己在较低索引配对中的预言机输出,并为较高索引配对中的预言机输出添加。
零知识和承诺零知识功能将与标准的离散对数关系一起使用:
R
D
L
=
(
X
,
B
)
,
x
:
X
=
x
⋅
B
R_{DL} = {(X,B),x : X=x·B}
RDL=(X,B),x:X=x⋅B
另外,在部分盲签名的背景下,它们还将与任意谓词和累积离散对数的合取一起使用:
R
D
L
∧
φ
=
{
(
X
,
B
1
,
.
.
.
,
B
ℓ
)
,
(
x
1
,
.
.
.
,
x
ℓ
)
:
X
=
∑
i
∈
ℓ
x
i
⋅
B
i
∧
φ
(
x
1
,
.
.
.
,
x
ℓ
)
=
1
}
R_{DL ∧ φ} = \{(X,B_1,...,B_ℓ),(x_1,...,x_ℓ): X=\sum_{i∈ℓ} x_i · B_i ∧ φ(x_1,...,x_ℓ)=1\}
RDL∧φ={(X,B1,...,Bℓ),(x1,...,xℓ):X=i∈ℓ∑xi⋅Bi∧φ(x1,...,xℓ)=1}
F
Z
K
R
D
L
\mathcal{F}_{ZK}^{R_{DL}}
FZKRDL 可以通过Fischlin变换[60]应用于Schnorr协议[61]来实现。
F
Z
K
R
D
L
∧
φ
\mathcal{F}_{ZK}^{{R_{DL∧φ}}}
FZKRDL∧φ的实现取决于谓词
φ
φ
φ ,但在简单情况下,例如有选择地检查与已知值的相等性,成本不超过证明关于
ℓ
ℓ
ℓ 离散对数的知识的成本。
F
C
o
m
−
Z
K
\mathcal{F}_{Com-ZK}
FCom−ZK 可以类似于
F
Z
K
\mathcal{F}_{ZK}
FZK 实现,但增加了通过
F
C
o
m
\mathcal{F}_{Com}
FCom 执行的承诺和解密。
乘法功能: 我们协议的主要构件是两方乘法。具体而言,我们需要一个功能,使得Alice和Bob分别拥有a和b,能够学习到c和d,并且满足c+d=a*b。这个功能在附录A中给出。 文献中有很多多党计算的技巧可以实现乘法功能,但为了达到我们想要的效率目标,我们选择通过Doerner等人[36]提出的两轮协议来实现 F M u l 2 P ( p ) F_{Mul2P}(p) FMul2P(p)。他们的协议基于 Oblivious Transfer (OT) [62],可以看作是经典的Gilboa的半诚实分布式乘法技术的恶意扩展[63]。因为他们的协议是基于OT的,它可以基于许多假设,包括计算Diffie-Hellman问题在 G 1 \mathbb{G}_1 G1中很难的假设,这是由q-SDH假设暗示的,在q-SDH假设下,BBS+本身被证明是安全的。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









