



 本文介绍了如何使用Python的urllib.request模块配合正则表达式进行网页数据爬取。从设置User-Agent属性避免被识别为机器人,到正则表达式的概念、模式创建以及使用re.findall()函数抓取匹配的字符串,详细阐述了爬虫的基本步骤。
本文介绍了如何使用Python的urllib.request模块配合正则表达式进行网页数据爬取。从设置User-Agent属性避免被识别为机器人,到正则表达式的概念、模式创建以及使用re.findall()函数抓取匹配的字符串,详细阐述了爬虫的基本步骤。
1.使用urllib.request
示例1:直接获取所有数据

【注】在Python3中包urllib2归入了urllib中,所以要导入urllib.request,并且要 把urllib2替换成urllib.request。
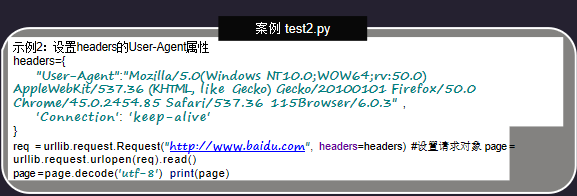
2.设置headers的User-Agent属性
示例2:
设置headers的User-Agent属性
1.利用正则表达式爬取数据
(1)概念:正则表达式是一个特殊的字符序列,作用是检查一个字符串是否与某种模 式匹配。
(2)Python Re模块 Python 自带了re模块,它提供了对正则表达式的支持。主要用到的方法。
3、pattern的创建
举例: pattern = re.compile(r'hello’)
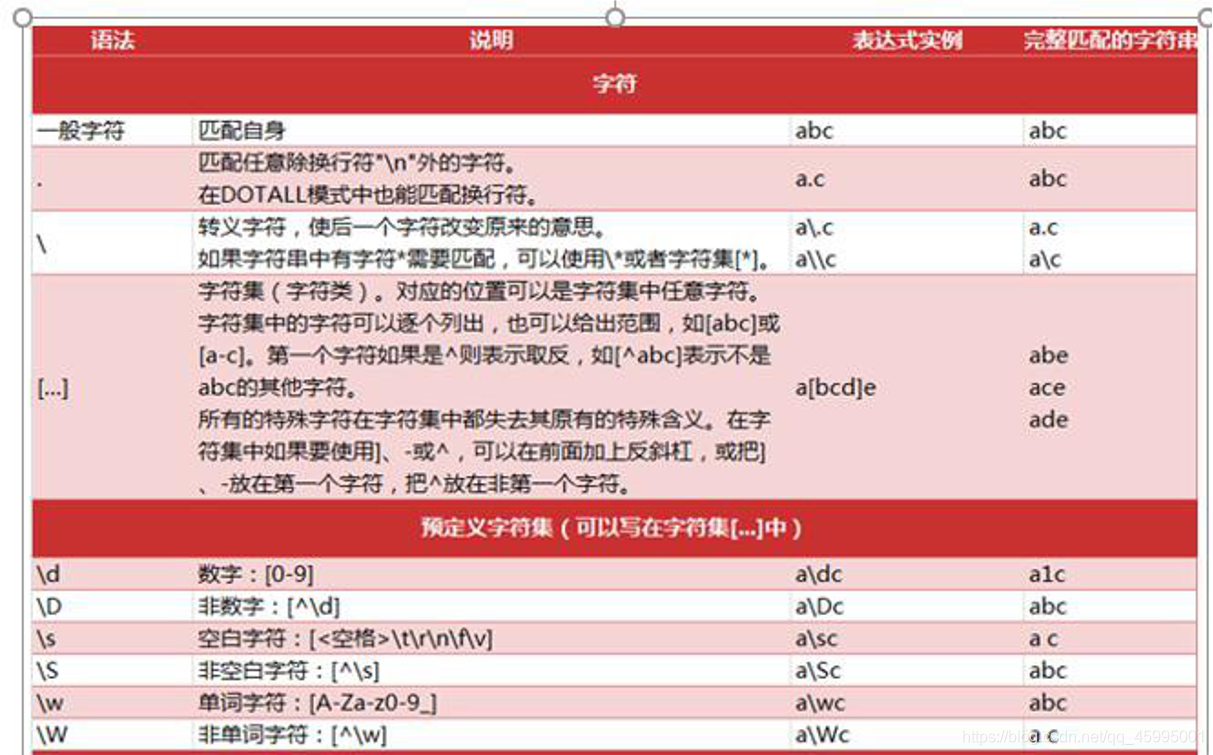
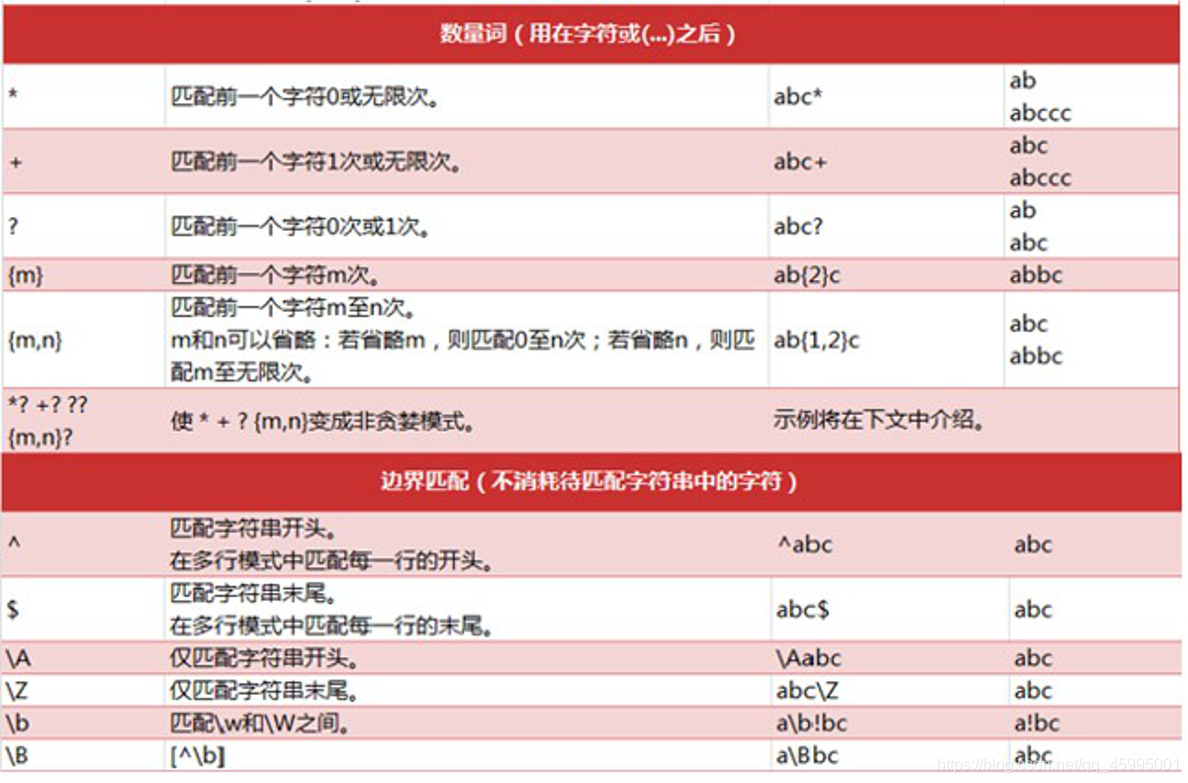
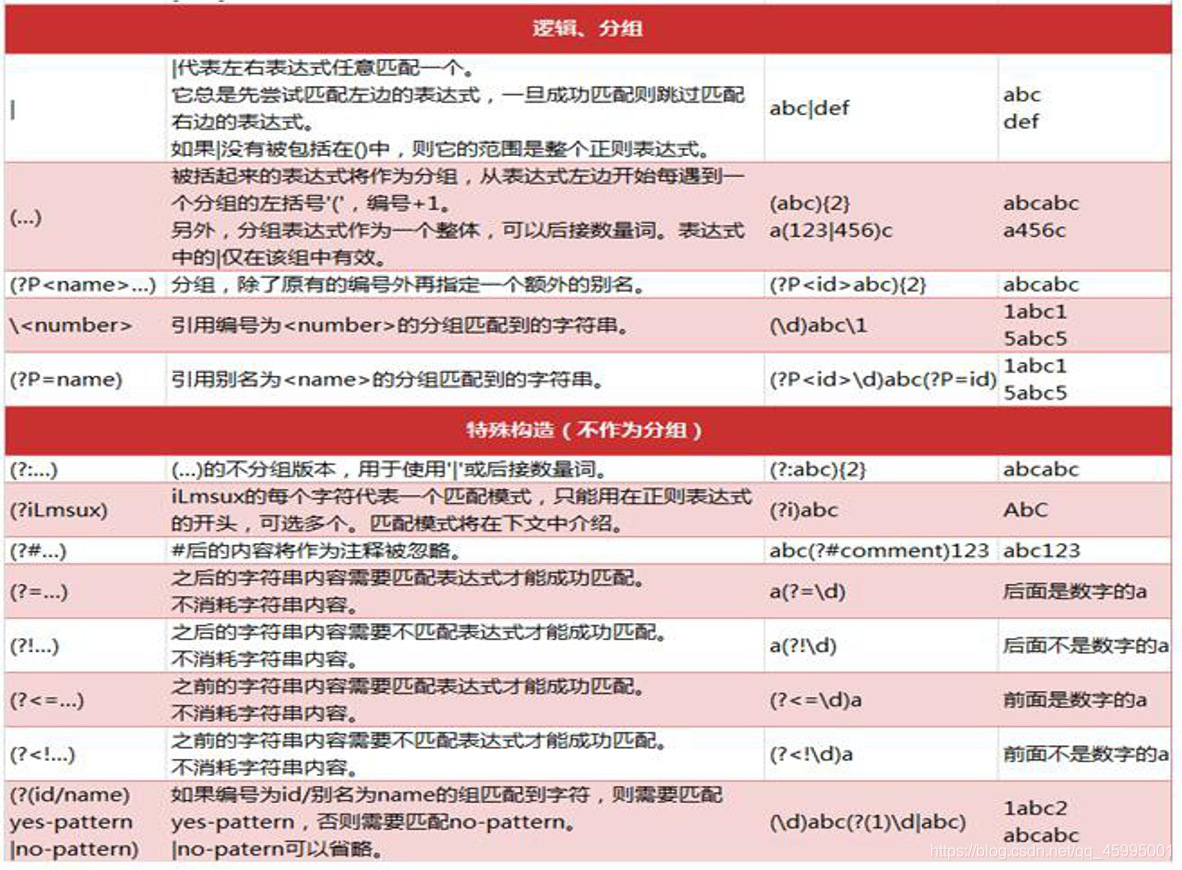
4、正则表达式通常通过特殊的语法来表示。
书写规则如下:
^表示字符串的开始,$表示字符串的末尾,经常省略 字母和数字表示他们自身。一个正则表达式模式中的字母和数字 匹配同样的字符串。
其它模式特殊符号描述如下:
5、 re.findall(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









