







hadoop高可用方案
1.1 hadoop高可用集群
1.1.1 高可用原理
- NameNode 高可用
- 想实现 Hadoop 高可用就必须实现 NameNode 的高可用,NameNode 是HDFS的核心,HDFS 又是 Hadoop 核心组件,NameNode 在 Hadoop 集群中至关重要;
- NameNode 宕机,将导致集群不可用,如果NameNode数据丢失将导致整个集群的数据丢失,而 NameNode 的数据更新又比较频繁,实现 NameNode 高可用势在必行;
1.1.2 解决方案
- HDFS + NFS
- HDFS + QJM
NFS和QJM解决方案的不同点: #数据存储方式不同
1》NFS解决方案: 数据存储方式为 NFS
2》QJM解决方案: 数据存储方式为 JournalNode
1.1.3 方案对比
- 都能实现热备;
- 都是一个 Active 和一个 Standby;
- 都使用 Zookeeper 和 ZKFC 来实现高可用
- NFS 方案:把数据存储在共享存储里,还需要考虑NFS的高可用设计;
- QJM 方案:不需要共享存储,但需要让每一个 DN都知道两个 NameNode的位置,并把块信息和心跳包发送给 Active 和 Standby 这两个 NameNode;
- datanode存储完数据后,需要向两台NameNode发送消息;
1.1.3.1 QJM方案解析
- 为 HDFS 配置两个 NameNode, 一个处于 Active 状态,另一个处于Standby状态。Active NameNode 对外提供服务,而 Standby 则仅同步 Active 的状态,以便能够在它失败时进行切换;
- 两台NameNode 会被配置在两台独立的机器上,在任何时候只能有一个 NameNode 处于活动状态,如果出现两个 Active NameNode,( 这种情况通常称为"split-brain" 脑裂,三节点通讯阻断)会导致集群操作混乱,可能会导致数据丢失或状态异常。
1.1.3.2 fsimage一致性
NameNode 更新很频繁,为了保持主备数据的一致性,为了支持快速Failover, Standby
NameNode 持有集群中 Blocks 的最新位置是非常必要的。为了达到这一目的,DataNodes上需要同时配置这两个 NameNode 的地址,同时和它们都建立心跳连接,并把 block 位置发送给它们
fsimage 一致性: #存放名称空间和块设备的映射信息(数据的位置信息);
1》存储数据时,客户端先切分数据,然后访问NameNode1;
2》NameNode1返回给客户端数据存储的位置信息;
3》客户端将数据存储在对应的DataNode节点上;
4》DataNode完成数据的存储后,将存储成功的信息,发送给NameNode1和NameNode2, NameNode1和NameNode2将数据的位置信息存储在fsimage中;
7.1.3.3 fsedits同步
- 为了让 Standby NameNode与 Active NameNode 保持同步,这两个NameNode都与一组称为 JNS 的互相独立的进程保持通信(Journal Nodes);
- 当Active NameNode 更新了,它将记录修改日志发送给 Journal Node,Standby Node 将会从 Journal Node 中读取这些日志,将日志变更应用在自己的数据中,并持续关注它们对日志的更新;
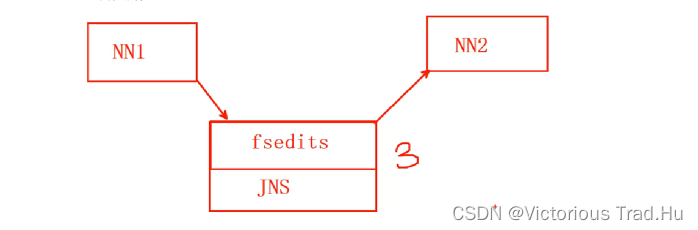
1》Active NameNode 为在HDFS集群中使用的NameNode节点;
2》Standby NameNode 为在HDFS集群中备用的NameNode节点;
3》当修改数据时,Active NameNode将修改的请求写入到fsedits中,为了实现fsedits的高可用,将fsedits存储在JNS上【日志服务器】;
4》Standby NameNode 从JNS上【日志服务器】读取这些更新日志,合并到自己的fsimages中;
1.1.3.4 主备切换
- 当 Failover 发生时,Standby 首先读取 Journal node 中所有的日志,并将它应用到自己的数据中;
- 获取 Journal Node 写权限;对于 Journal node 而言,任何时候只允许一个 NameNode 作为writer; 在 Failover 期间,原来的 Standy NameNode 将会接管 Active 的所有智能,并负责向 Journal node 写入日志记录;
- 提升自己为Active;
1.1.4 高可用架构图
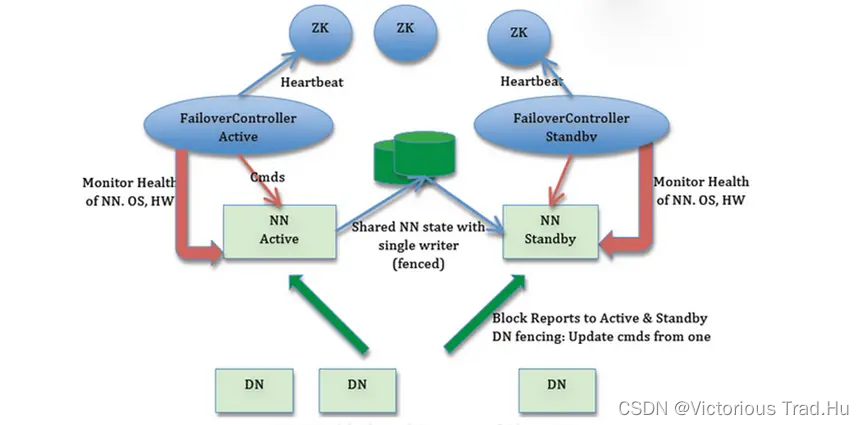
> namenode的高可用是依靠zookeeper的 ZKFC【ZookeeperFailoverController】实现的;
1.2 hadoop高可用集群搭建
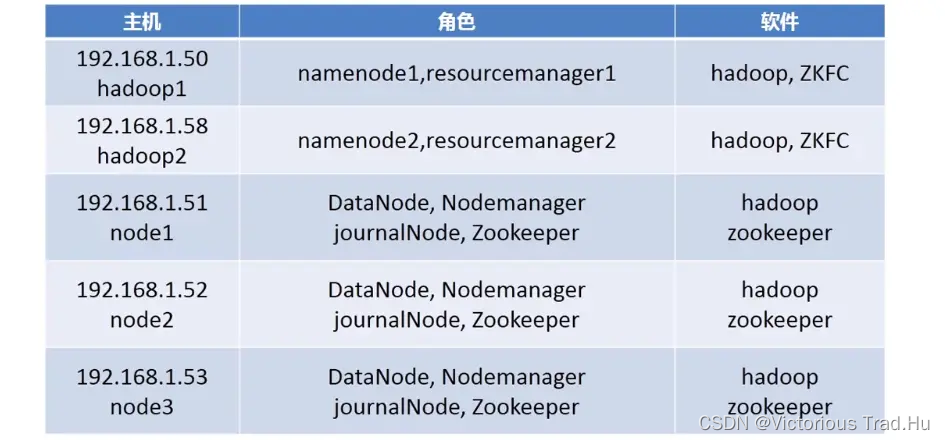
1.2.1 系统规划配置
# 修改主机名
[root@localhost ~]# hostnamectl set-hostname hadoop1 && bash
# 安装javajdk
[root@hadoop1 ~]# yum -y install java-1.8.0-openjdk-devel
# 配置本地域名解析,添加新的节点 hadoop2
[root@hadoop1 ~]# vim /etc/hosts
192.168.1.50 hadoop1
192.168.1.58 hadoop2
192.168.1.51 node1
192.168.1.52 node2
192.168.1.53 node3
##禁用ssh key检测
##添加 StrictHostKeyChecking no 即可
[root@hadoop1 ~]# vim /etc/ssh/ssh_config
Host *
GSSAPIAuthentication yes
####禁用 ssh key 检测
StrictHostKeyChecking no
# 修改配置文件,在linux上启动hadoop命令的脚本配置文件
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
# 修改环境变量
export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre"
# 指定hadoop配置文件所在的路径
export HADOOP_CONF_DIR="/usr/local/hadoop/etc/hadoop"
# 配置slaves,让node1,node2,node3都运行datanode守护进程
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/slaves
node1
node2
node3
1.2.2 高可用配置
1.2.2.1 core-site.xml
- core-site.xml配置
-
- fs.defaultFS: 文件系统配置参数
#声明namenode服务的地址, 因为namenode有两个,不能要写组名称,这里定义两个namenode节点都在mycluster组中,此处只是声明,后面会具体定义
<name>fs.defaultFS</name>
<value>hdfs://{服务名}</value>
-
- hadoop.tmp.dir:数据目录配置参数
<name>hadoop.tmp.dir</name>
<value>/var/hadoop</value>
修改hadoop1 core-site.xml配置参数
#fs.defaultFS 声明namenode服务的地址, 因为namenode有两个,不能要写组名称,这里定义两个namenode节点都在mycluster组中,此处只是声明,后面会具体定义
#hadoop.tmp.dir 声明hadoop数据的存放路径
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
<description>hdfs file system</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop</value>
</property>
</configuration>
- core-site.xml 配置-2
-
- ha.zookeeper.quarum: zookeeper 服务地址
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
-
- 同时配置多个主机防止单点故障
######### 修改core-site.xml文件,在hadoop1主机上操作 #############
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
<description>hdfs file system</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop</value>
</property>
###### ha.zookeeper.quorum 指定zookeeper服务,新增配置 ########
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
</configuration>
1.2.2.2 hdfs-site.xml
- hdfs-site.xml配置-1
-
- dfs.nameservices: 服务名
# namenode是一个组,指定namenode的组名称,自己可以定义
<name>dfs.nameservices</name>
<value>服务名</value>
-
- dfs.ha.namenodes.{服务名}: 定义服务中的角色
# 指定namenode组的成员
<name>dfs.ha.namenodes.{服务名}</name>
<value>nn1,nn2</value>
#删除dfs.namenode.http-address的属性配置
#删除dfs.namenode.secondary.http-address的属性配置
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
#dfs.nameservices 指定namenode的组名称,自己可以定义
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
#dfs.ha.namenodes.mycluster 指定namenode组mycluster的成员为nn1和nn2
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
</configuration>
- hdfs-site.xml配置-2
-
- 角色1 的rpc 地址及端口号
<name>dfs.namenode.rpc-address.{服务名}.nn1</name>
<value>hadoop1:8020</value>
-
- 角色2 的rpc 地址及端口号
<name>dfs.namenode.rpc-address.{服务名}.nn2</name>
<value>hadoop2:8020</value>
修改hadoop1 hdfs-site.xml配置参数
# 配置nn1和nn2的rpc地址和端口号
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
dfs.ha.namenodes.mycluster.nn1 指定nn1对应的rpc服务地址和端口
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop1:8020</value>
</property>
##dfs.ha.namenodes.mycluster.nn2 指定nn2对应的rpc服务地址和端口
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop2:8020</value>
</property>
- hdfs-site.xml配置-3
-
- Namenode 1 的地址及端口号
<name>dfs.namenode.http-address.{服务名}.nn1</name>
<value>hadoop1:50070</value>
-
- Namenode 2 的地址及端口号
<name>dfs.namenode.http-address.{服务名}.nn2</name>
<value>hadoop2:50070</value>
修改hadoop1 hdfs-site.xml配置参数
###配置namenode1和namenode2的地址及端口号
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
# 指定namenode1的服务地址和端口号
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop1:50070</value>
</property>
###指定namenode1的服务地址和端口号
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop2:50070</value>
</property>
- hdfs-site.xml配置-4
-
- JournalNode 的地址及端口号
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/{服务名}</value>
-
- JournalNode 的数据存放地址
<name>dfs.journalnode.edits.dir</name>
<value>/var/hadoop/journal</value>
修改hadoop1 hdfs-site.xml配置参数
#配置JournalNode的地址和端口号,以及JournalNode的数据存放地址
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
指定JournalNode 的地址及端口号,JournalNode将被安装在node{1,2,3}上
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value>
</property>
指定JournalNode的日志数据存放地址
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/hadoop/journal</value>
</property>
- hdfs-site.xml配置-5
-
- Failover 类服务名
<name>dfs.client.failover.proxy.provider.{服务名}</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
-
- 远程管理方式,sshfence 使用 ssh 远程管理
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
修改hadoop1 hdfs-site.xml配置参数
# 指定failover 类服务名和远程管理方式【ssh】
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
# 指定Failover的类服务名
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
# 指定远程管理方式,sshfence 使用 ssh 远程管理
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
- hdfs-site.xml配置-6
-
- ssh 私钥的位置
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
-
- 自动实现故障切换
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
修改hadoop1 hdfs-site.xml配置参数
# 指定ssh 私钥的位置,配置自动故障切换
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
# 指定 ssh 私钥的位置
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
# 配置自动故障切换,true【自动故障切换】,false【手动故障切换】
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
- hdfs-site.xml配置-7
-
- 文件副本数量
<name>dfs.replication</name>
<value>2</value>
-
- 排除主机列表
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/exclude</value>
修改hadoop1 hdfs-site.xml配置参数
# 指定文件副本数量,和排除主机列表【已经配置过了】
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
# 指定文件副本数量为2,连同原文件加起来是两份
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
# 指定排除主机列表文件,用于删除节点使用
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/exclude</value>
</property>
</configuration>
1.2.2.3 mapred-site.xml
- mapred-site.xml 配置
-
- 资源管理类
<name>mapreduce.framework.name</name>
<value>yarn</value>
修改hadoop1 mapred-site.xml配置参数
# mapreduce.framework.name 要使用计算框架的必须选项,如果是单机版,值为local;如果是分布式集群,值则为yarn;
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
1.2.2.4 yarn-site.xml
- yarn-site.xml 配置——1
-
- 计算框架
<name>yarn.nodemanager.aux-services</name>
<name>mapreduce_shuffle</name>
修改hadoop1 yarn-site.xml配置参数
# yarn.nodemanager.aux-services 指定要使用的分布式计算框架,可以使用开发人员写的计算框架,这里采用的是官方提供的模板计算框架;
# 删除 yarn.resourcemanager.hostname 的属性配置
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
# yarn.nodemanager.aux-services 指定要使用的分布式计算框架
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Site specific YARN configuration properties -->
<configuration>
- yarn-site.xml 配置——2
-
- 激活HA 配置
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
-
- 管理节点状态自动恢复
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
修改hadoop1 yarn-site.xml配置参数
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
**激活HA配置**
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
**配置管理节点状态自动恢复**
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
- yarn-site.xml 配置——3
-
- 数据状态保持介质
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
-
- zookeeper 服务器地址
<name>yarn.resourcemanager.zk-address</name>
<value>node1:2181,node2:2181,node3:2181</value>
修改hadoop1 yarn-site.xml配置参数
# 修改yarn-site.xml配置文件
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
# 定义数据状态保持介质
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
# 指定zookeeper的服务地址,为了防止单节点故障,指定三个节点
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
- yarn-site.xml 配置——4
-
- 集群 ID
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-ha</value>
-
- 定义两个 resourcemanager 角色
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
修改hadoop1 yarn-site.xml配置参数
# 修改yarn-site.xml配置文件
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
# 指定集群ID
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-ha</value>
</property>
# 定义两个 resourcemanager 角色: rm1和rm2
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
- yarn-site.xml 配置——5
-
- 角色1 对应主机地址
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop1</value>
-
- 角色2 对应主机地址
<name>yarn.resourcemanager..hostname.rm2</name>
<value>hadoop2</value>
修改hadoop1 yarn-site.xml配置参数
# 修改yarn-site.xml配置文件
[root@hadoop1 ~]# vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
# 指定rm1对应的主机地址 hadoop1
<configuration>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop1</value>
</property>
# 指定rm2对应的主机地址 hadoop2
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop2</value>
</property>
</configuration>
1.2.3 初始化集群
1.2.3.1 初始化集群-1
# 使用脚本 zkstats,查看zookeeper的角色
[root@hadoop1 ~]# sh zkstats node{1..3} hadoop1
node1 Mode: follower
node2 Mode: leader
node3 Mode: follower
hadoop1 Mode: observer
# 如果zookeeper服务没有启动,所有节点执行如下启动命令:
[root@localhost ~]# /usr/local/zookeeper/bin/zkServer.sh start
# - 把所有机器删除之前的日志和实验数据
rm -rf /var/hadoop/*
rm -rf /usr/local/hadoop/logs/*
1.2.3.2 初始化集群-2
-
- 同步配置文件到所有集群机器
rsync -av /etc/hosts 集群主机:/etc/
rsync -aXSH --delete /usr/local/hadoop 集群主机:/usr/local/
- 同步配置文件到所有集群机器
-
- NN1: 初始化ZK集群 (NN1指namenode1所在的机器)
/usr/ocal/hadoop/bin/hdfs zkfc -formatZK
- NN1: 初始化ZK集群 (NN1指namenode1所在的机器)
-
- node1,node2,node3: 启动 journalnode 服务
/usr/local/hadoop/sbin/hadoop-daemon.sh start journalnode
- node1,node2,node3: 启动 journalnode 服务
1.2.3.3 初始化集群-3
NN1: 格式化
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs namenode -format
NN2: 数据同步到本地 /var/hadoop/dfs
# 创建目录
[root@hadoop2 ~]# mkdir /var/hadoop
# 将namenode1格式化后的数据【dfs目录】到本地目录/var/hadoop/下
[root@hadoop2 ~]# rsync -aXSH --delete hadoop1:/var/hadoop/dfs /var/hadoop/
# 查看数据同步结果
[root@hadoop2 ~]# ls /var/hadoop/
NN1: 初始化 JNS
# 查看帮助信息,获取初始化参数
[root@hadoop2 ~]# /usr/local/hadoop/bin/hdfs namenode --help
# 执行journalnode的初始化
[root@hadoop2 ~]# /usr/local/hadoop/bin/hdfs namenode -initializeSharedEdits
# 停止journalnode服务
[root@node1 ~]# /usr/local/hadoop/sbin/hadoop-daemon.sh stop journalnode
# 停止journalnode服务
[root@node2 ~]# /usr/local/hadoop/sbin/hadoop-daemon.sh stop journalnode
# 停止journalnode服务
[root@node3 ~]# /usr/local/hadoop/sbin/hadoop-daemon.sh stop journalnode
NN1 启动 HDFS 和 Yarn
# 在namenode1上启动HDFS 和 Yarn
[root@hadoop1 ~]# /usr/local/hadoop/sbin/start-all.sh
NN2 启动 resourcemanager
[root@hadoop2 ~]# /usr/local/hadoop/sbin/yarn-daemon.sh start resourcemanager
1.3 hadoop高可用验证
1.3.1 集群验证-1
获取NameNode状态
/usr/local/hadoop/bin/hdfs haadmin -getServiceState nn1
/usr/local/hadoop/bin/hdfs haadmin -getServiceState nn2
# 查看haadmin的帮助信息
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs haadmin --help
# NameNode1作为master,处于活跃状态
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs haadmin -getServiceState nn1
# NameNode1作为backup, 处于备用状态
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs haadmin -getServiceState nn2
# 获取rm1的ResourceManager的状态信息
[root@hadoop2 ~]# /usr/local/hadoop/bin/yarn rmadmin -getServiceState rm1
# 获取rm2的ResourceManager的状态信息
[root@hadoop2 ~]# /usr/local/hadoop/bin/yarn rmadmin -getServiceState rm2
1.3.2 集群验证-2
1.3.2.1 获取节点信息
/usr/local/hadoop/bin/hdfs dfsadmin -report
/usr/local/hadoop/bin/yarn node -list
# 查看hdfs文件系统的信息
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs dfsadmin -report
# 查看计算节点的信息
[root@hadoop1 ~]# /usr/local/hadoop/bin/yarn node -list
1.3.2.2 访问集群文件
/usr/local/hadoop/bin/hadoop fs -mkdir /input
/usr/local/hadoop/bin/hadoop fs -ls hdfs://{服务名}
# 在hdfs中创建目录/input
[root@hadoop1 ~]# /usr/local/hadoop/bin/hadoop fs -mkdir /input
# 查看数据
[root@hadoop1 ~]# /usr/local/hadoop/bin/hadoop fs -ls /
1.3.2.3 常用命令
- 强制切换角色
/usr/local/hadoop/bin/hdfs haadmin -transitionToActive --forcemanual nn1
/usr/local/hadoop/bin/yarn rmadmin -transitionToStandby --forcemanual rm1 - 退出安全模式
/usr/local/hadoop/bin/hdfs dfsadmin -safemode leave
1.3.2.4 验证集群的高可用
# 进入到hadoop安装目录下
[root@hadoop1 ~]# cd /usr/local/hadoop/
# 上传当前目录下的txt文件到hdfs中
[root@hadoop1 hadoop]# ./bin/hadoop fs -put *.txt /input
# 查看文件是否上传成功
[root@hadoop1 hadoop]# ./bin/hadoop fs -ls /input
# 分析数据,统计hdfs中,/input下数据中单词的数量
[root@hadoop1 hadoop]# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /input /output
# 停止 namenode的服务
[root@hadoop1 ~]# /usr/local/hadoop/sbin/hadoop-daemon.sh stop namenode
# 停止 resourcemanager的服务
[root@hadoop1 ~]# /usr/local/hadoop/sbin/yarn-daemon.sh stop resourcemanager
# 查看数据分析结果,数据分析结果正常
[root@hadoop1 hadoop]# /usr/local/hadoop/bin/hadoop fs -cat /output
# namenode1无法连接
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs haadmin -getServiceState nn1
# namenode2从standby【备用】状态,变为active【主】
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs haadmin -getServiceState nn2
# rm1【resourcemanager】无法连接
[root@hadoop1 ~]# /usr/local/hadoop/bin/yarn rmadmin -getServiceState rm1
# rm2【resourcemanager】从standby【备用】状态,变为active【主】
[root@hadoop1 ~]# /usr/local/hadoop/bin/yarn rmadmin -getServiceState rm2
**恢复hadoop集群的高可用**
# 启动resourcemanager的服务
[root@hadoop1 ~]# /usr/local/hadoop/sbin/yarn-daemon.sh start resourcemanager
# 启动namenode的服务
[root@hadoop1 ~]# /usr/local/hadoop/sbin/hadoop-daemon.sh start namenode
# nn1【namenode】重启启动,变成了standby【备】
[root@hadoop1 ~]# /usr/local/hadoop/bin/hdfs haadmin -getServiceState nn1
# rm1【resourcemanager】重启启动,变成了standby【备】
[root@hadoop1 ~]# /usr/local/hadoop/bin/yarn rmadmin -getServiceState rm1
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











