








亲爱的读者们👋
欢迎加入【30天精通Prometheus】专栏!📚 在这里,我们将探索Prometheus的强大功能,并将其应用于实际监控中。这个专栏都将为你提供宝贵的实战经验。🚀
Prometheus是云原生和DevOps的核心监控工具,我们将从基础概念开始,逐步涵盖配置、查询、告警和可视化。💪
在接下来的30天里,我们将解锁Prometheus的实战技巧,通过案例和分享,助你深入理解其工作原理。📆
目标:30天后,你将熟练掌握Prometheus,为未来的项目挑战做好准备!💯
这是一段精彩旅程,期待你的加入!🎉
- 【30天精通Prometheus:一站式监控实战指南】第1天:深入探索Prometheus:30天一站式监控实战指南的开篇之旅
- 【30天精通Prometheus:一站式监控实战指南】第2天:Prometheus从入门到实战:安装、配置详解与生产环境搭建指南
- 【30天精通Prometheus:一站式监控实战指南】第3天:Alertmanager从入门到实战:安装、配置详解与生产环境搭建指南
- 【30天精通Prometheus:一站式监控实战指南】第4天:node_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第5天:kafka_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第6天:mysqld_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第7天:postgres_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第8天:redis_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第9天:elasticsearch_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第10天:blackbox_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第11天:consul_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第12天:windows_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第13天:graphite_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第14天:jmx_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第15天:ipmi_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第16天:snmp_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第17天:nginx-prometheus-exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第18天:apache_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第19天:haproxy_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第20天:dcgm-exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
- 【30天精通Prometheus:一站式监控实战指南】第21天:深入解析PromQL(Prometheus Query Language)的高级用法,解锁监控数据的无限可能,释放监控数据潜能
- 【30天精通Prometheus:一站式监控实战指南】第22天:如何将Prometheus与Grafana集成,通过可视化的方式展示监控数据,提高监控效率
- 【30天精通Prometheus:一站式监控实战指南】第23天:如何搭建高可用的Prometheus集群,以应对大规模监控场景和单点故障问题,确保监控服务的稳定性
- 【30天精通Prometheus:一站式监控实战指南】第24天:Prometheus数据存储与性能调优攻略,通过优化存储和查询性能来提升监控系统的整体效率
- 【30天精通Prometheus:一站式监控实战指南】第25天:微服务架构下的Prometheus实战,Kubernetes与Prometheus集成:集群监控实战
- 【30天精通Prometheus:一站式监控实战指南】第26天:构建健壮的高可用Prometheus集群,以应对大规模监控挑战与单点故障风险
- 【30天精通Prometheus:一站式监控实战指南】第27天:Prometheus与第三方工具集成:提升监控能力
- 【30天精通Prometheus:一站式监控实战指南】第28天:故障排查与告警分析实战案例分享
- 【30天精通Prometheus:一站式监控实战指南】第29天:Prometheus监控策略与最佳实践指南
- 【30天精通Prometheus:一站式监控实战指南】第30天:Prometheus监控技术回顾与未来展望
一、引言
1.1 Prometheus数据存储的重要性
Prometheus作为云原生监控领域的核心组件,其数据存储机制直接影响监控系统的稳定性、查询效率和资源利用率。时间序列数据的高效存储能够支持实时告警、多维度数据聚合和大规模历史数据分析,是保障业务可观测性的基石。随着监控指标数量和采样频率的增加,存储性能可能成为系统瓶颈,直接影响查询延迟和资源消耗。
1.2 性能调优的意义
在千万级时间序列的生产环境中,未经优化的存储配置可能导致磁盘IO饱和、内存溢出或查询超时等问题。性能调优的目标在于:
- 降低资源占用(CPU/内存/磁盘)
- 提升查询响应速度(P99延迟优化)
- 提高数据存储密度(压缩率提升)
- 延长历史数据保留周期(成本优化)
二、Prometheus数据存储机制详解
2.1 存储结构概览
2.1.1 时间序列数据库(TSDB)介绍
Prometheus TSDB采用列式存储结构,将时间序列数据按指标名称和标签分片。每个时间序列对应一个独立的seriesID,数据块(Block)按固定时间窗口(默认2小时)划分,包含索引文件(index)、块文件(chunks)和元数据(meta.json)。这种设计使得范围查询(range query)可通过跳跃读取(jump read)快速定位数据。
2.1.2 内存中的样本数据
最新数据首先写入内存中的head block,通过memSeries结构维护活跃时间序列。内存采用分片锁机制(shard lock),每个分片管理一组时间序列,减少写操作竞争。默认每2小时将内存数据持久化为磁盘块文件。
内存存储核心结构
- 功能定位:Head Block 是内存中的活跃数据块,负责管理最近2小时(默认)的时间序列数据。
- 组成元素:
- memSeries:每个时间序列对应一个 memSeries 对象,存储当前时间窗口内的样本数据。
- 索引映射:通过 seriesHash → memSeries 的哈希表快速定位时间序列。
- 分片管理:将 memSeries 分散到多个分片(Shard)中,降低锁竞争。
分片锁机制
- 分片数量:默认 2^14 (16384) 个分片,可通过 --storage.tsdb.mem-series-shards 调整。
- 并发控制:每个分片独立维护锁(sync.RWMutex),写入时仅需锁定单个分片。
- 性能影响:分片过少会导致锁竞争激烈,过多则增加内存开销。
2.1.3 数据写入与内存管理
写入流程
1. 接收样本:通过 /api/v1/write 接收数据,解析为 []sample 结构。
2. 标签处理:规范化标签(排序、去重),生成唯一 seriesHash。
3. 分片路由:根据 seriesHash % shard_count 确定目标分片。
4. 写入内存
○ 新Series:创建 memSeries 对象并注册到哈希表。
○ 现有Series:追加样本到 memSeries.data 数组尾部。
5. WAL记录:写入前先追加到 Write-Ahead Log(WAL)保证持久性。
内存回收策略
- LRU清理:当总Series数超过 --storage.tsdb.max-series(默认0,无限制)时,淘汰最久未访问的Series。
- 块切割(Cutting Block):
- 每2小时将Head Block转为持久化块(Persistent Block)。
- 触发全量索引重建,释放已持久化数据的内存。
- 手动干预:通过 TSDB Admin API 强制清理异常Series。
乱序数据处理
- 乱序容忍:从 v2.39 开始支持 --storage.tsdb.max-out-of-order-time(默认0,禁用)。
- 允许时间戳乱序范围(如设置为 5m 可接受5分钟内的乱序样本)。
- 内存缓存:乱序样本暂存于独立缓冲区,定期合并到主存储。
2.1.3 磁盘上的持久化存储
磁盘存储采用多层目录结构:
data/
├── 01BKGTZQ1SYQJTR4PB3C8PD984 # Block ID
│ ├── chunks # 原始数据(压缩后)
│ │ └── 000001
│ ├── index # 倒排索引
│ └── meta.json # 元信息
└── wal # 写前日志
├── 000000002
└── checkpoint.000000001
2.2 数据写入流程解析
2.2.1 样本接收与预处理
2.2.1.1 样本接收机制
入口处理
- HTTP API接收:通过/api/v1/write端点接收远程写入请求,支持protobuf和JSON格式
- 流式解析:采用零拷贝(zero-copy)技术直接解析请求体,避免内存复制开销
- 并发控制:通过–storage.remote.write-concurrency参数控制写入协程数量(默认4)
# 典型写入请求格式
curl -X POST http://localhost:9090/api/v1/write \
-H "Content-Type: application/x-protobuf" \
--data-binary @metrics.prom
2.2.1.2 预处理关键步骤
1. 标签规范化(Label Normalization)
- 标签排序:强制将标签按字典序排列(例如{zone=“a”,app=“web”}转为app=“web”,zone=“a”)
- 去重处理:自动合并重复标签(如{app=“web”,app=“db”}视为非法样本)
- 保留标签过滤:根据honor_labels配置决定是否保留exporter原始标签
2. 计算series hash生成唯一seriesID
- 单调性检查:拒绝时间戳早于内存中同series最新样本的数据
- 时钟漂移容错:通过–storage.tsdb.max-out-of-order-time参数允许有限乱序(默认0,v2.39+支持)
3. 验证时间戳单调递增(避免乱序写入)
- 自动将非标准数值(如+Inf、-Inf、NaN)转换为IEEE 754特殊编码
2.2.2 块文件格式及组织方式
Prometheus的TSDB(时间序列数据库)通过**块(Block)**的形式组织磁盘上的持久化数据。每个块代表一个固定时间窗口内的监控数据,采用紧凑的列式存储结构,支持高效的范围查询和数据压缩。以下是块文件的详细组织方式及技术实现:
1. 块的基本概念
- 时间窗口:每个块对应一个连续的时间范围,默认窗口为2小时(可通过–storage.tsdb.min-block-duration和max-block-duration调整)。
- 不可变性:块一旦写入磁盘即为只读,后续通过压缩(Compaction)合并多个块。
- 唯一标识:块目录以ULID(Universally Unique Lexicographically Sortable Identifier)命名,如01FRS6XZ6Z8X1JQZQZQZQZQZQZ,保证全局唯一且按时间排序。
2. 块目录结构
一个完整的块目录包含以下文件:
data/
├── 01FRS6XZ6Z8X1JQZQZQZQZQZQZ # 块ID(ULID)
│ ├── chunks # 原始样本数据(压缩后)
│ │ └── 000001 # 数据分块文件(每个约512MB)
│ ├── index # 倒排索引文件
│ ├── meta.json # 元数据描述文件
│ └── tombstones # 软删除标记(可选)
3. 核心文件解析
-
chunks目录
- 文件格式:每个.chunk文件包含多个压缩后的数据段(Segment),每个段对应一个时间序列的连续样本。
- 压缩算法:采用XOR(异或)压缩算法,对时间戳和值分别压缩:
- 时间戳:通过计算差值后使用Delta-of-Delta编码
- 值:根据数据类型选择XOR或Gorilla压缩
- 分块规则:单个.chunk文件大小默认不超过512MB,避免大文件影响读写性能。
-
index文件
索引文件采用多层结构,支持快速定位时间序列:
1. Symbol Table(符号表):存储所有标签键值对的唯一化字符串,减少重复存储。

2. Postings(倒排列表):记录每个标签键值对对应的Series ID列表。

3. Series Metadata(元数据):存储每个Series的标签集合及其对应的Chunk位置。

4. TOC(Table of Contents):记录各段数据的起始偏移量,用于快速定位索引内容。 -
meta.json文件
描述块的基础信息,JSON格式:
{
"ulid": "01FRS6XZ6Z8X1JQZQZQZQZQZQZ",
"minTime": 1625000000, // 块起始时间(Unix秒)
"maxTime": 1625007200, // 块结束时间
"stats": {
"numSamples": 1052345, // 总样本数
"numSeries": 4231, // 时间序列数
"numChunks": 892 // Chunk总数
},
"compaction": {
"level": 1, // 压缩层级(越大表示合并次数越多)
"sources": ["01FRS..."] // 原始块ULID(合并时记录来源)
}
}
- 数据组织策略
- 时间分片(Time Sharding)
- 按固定窗口(默认2小时)切分数据,保证查询时仅需加载相关时间范围的块。
- 窗口大小权衡:
- 小窗口:加速数据过期删除,但增加块数量(影响查询效率)
- 大窗口:减少文件数,但单文件体积增大(影响压缩效率)
- 列式存储(Column-Oriented)
- 相同时间窗口的样本按时间序列聚合存储,提升范围查询效率。
- 查询rate(http_requests_total[5m])时只需读取少量Chunk文件。
- 压缩与合并(Compaction)
- 垂直压缩(Vertical Compaction):合并多个小块为更大时间窗口的块(如将8个2小时块合并为1个16小时块),减少文件数。

- 水平压缩(Horizontal Compaction):合并同一时间窗口内的小块,优化存储布局。
- 垂直压缩(Vertical Compaction):合并多个小块为更大时间窗口的块(如将8个2小时块合并为1个16小时块),减少文件数。
- 时间分片(Time Sharding)
- 块创建流程
1. 内存数据冻结:Head Block达到2小时后停止写入
2. 持久化写入:将内存中的memSeries转换为Chunk文件
3. 构建倒排索引并写入index文件
4. 生成元数据:计算统计信息并写入meta.json
5. WAL清理:删除已持久化的WAL日志段
2.2.3 写前日志(WAL)的作用
WAL通过顺序追加写入(append-only)保证数据持久化:
- 每个样本写入前先记录到WAL
- 定期创建检查点(checkpoint)减少恢复时间
- 宕机后通过重放WAL恢复未落盘数据
2.3 数据读取流程解析
2.3.1 查询执行计划生成
1. 逻辑计划构建
PromQL 查询首先被解析为抽象语法树(AST),随后转换为由操作符组成的逻辑执行计划树。例如,查询 sum(rate(http_requests_total{job=“web”}[5m])) by (instance) 将被分解为:

2. 优化器策略
- 谓词下推(Predicate Pushdown):将标签过滤条件(如 {job=“web”})下推到存储层,减少数据传输量。
- 数据源选择:根据时间范围自动选择 Head Block(内存)、本地持久化块或远程存储(如 Thanos)。
3. 物理计划生成
将逻辑计划转换为物理操作,确定执行顺序与资源分配:
- 操作符优先级:先执行高基数过滤(如标签匹配),后执行计算密集型操作(如聚合)。
- 资源预估:根据 --query.max-samples 限制内存使用,避免 OOM。
2.3.2 并行查询处理
1. 任务分片策略
- 按时间范围分片(sharding):将大范围查询按时间窗口拆分为子任务。例如,查询 [12h] 可能被拆分为6个 [2h] 的子查询。

- 按标签哈希分区(partitioning):根据 series_hash 将查询分发到不同线程,每个线程处理特定哈希范围的时间序列。
2. 并发读取不同块文件
- 线程池管理:通过 --query.max-concurrency(默认20)控制并行度。
- 动态负载均衡:各线程从共享队列中获取任务,避免某一线程过载。
3. 数据加载优化
- 块预取(Block Prefetching):根据查询模式预测并预加载下一个可能访问的数据块。
- 零拷贝读取:使用内存映射(mmap)直接访问磁盘数据,减少内存复制开销。
2.3.3 结果合并与返回
1.结果集合并
- 时间对齐(time alignment):将来自不同分片的样本按时间戳对齐,填补缺失点(如 step=15s 时插值处理)。

- 流式聚合(Streaming Aggregation):对 sum、avg 等操作进行增量计算,避免全量数据驻留内存。
2. 数据去重(deduplication)
- 去重机制:同一时间序列可能因分片重叠或远程存储冗余出现重复样本,合并时仅保留最新值。

3. 响应格式生成- 协议转换:将内部存储格式转换为 HTTP API 响应(JSON/Protobuf)。
- 分页控制:若结果超过 --query.max-samples(默认5000万),返回错误 exceeded maximum resolution。
三、影响性能的因素分析
3.1 软件配置参数
3.1.1 配置文件关键参数解读
global:
scrape_interval: 15s # 抓取周期(过短会增加负载)
evaluation_interval: 15s # 规则评估周期
scrape_configs:
- job_name: 'node'
sample_limit: 5000 # 单次抓取样本上限(防OOM)
target_limit: 200 # 目标实例数上限
storage:
tsdb:
retention: 15d # 数据保留周期(直接影响磁盘占用)
max_block_duration: 2h # 内存块持久化周期
3.1.2 默认值与最佳实践对比
| 参数 | 默认值 | 推荐值 | 优化目标 |
|---|---|---|---|
| scrape_interval | 1m | 15s-2m* | 监控粒度 vs 负载 |
| retention | 15d | 30d+对象存储 | 根据存储容量调整 |
| max-block-duration | 2h | 4h-8h | 减少IO频率 |
| wal-compression | 0(无限制) | 5000-10000 | 防止内存溢出 |
3.2 监控指标选择的影响
3.2.1 指标数量对性能的影响
- 存储成本:单指标约占用 1-2 bytes/s(TSDB压缩后)
- 查询延迟:万级指标下 P99 查询延迟可能超 1s
- 内存压力:活跃时序数据常驻内存(每时序约 2KB)
时间序列基数(cardinality)与内存消耗呈线性关系:
内存占用 ≈ 活跃series数 × 每个series内存开销(约3KB)
高基数场景(如未聚合的用户ID标签)可能引发OOM。
3.2.2 指标采集优化策略
- 1. 维度裁剪:通过 metric_relabel_configs 过滤无用标签

- 基数控制:避免高基数标签(如IP、UID等)
- 指标聚合:使用 Recording Rules 预聚合高频指标
四、性能调优方法论
4.1 软件配置优化
4.1.1 关键配置项调整
核心参数优化策略
# prometheus.yml 性能关键配置
global:
scrape_interval: 30s # 根据监控敏感度调节(15s-5m)
evaluation_interval: 30s # 规则计算间隔
external_labels:
cluster: "prod" # 集群标识符(联邦集群必需)
storage:
tsdb:
retention: 30d # 本地存储周期(SSD建议30-90d)
max_block_duration: 4h # 内存块持久化间隔(降低IO压力)
min_block_duration: 2h # 最小合并间隔
max_block_chunk_segment_size: 512MB # 块分段大小
query:
lookback-delta: 5m # 查询时数据回溯窗口
max-concurrency: 32 # 并发查询数(建议CPU核心数*2)
timeout: 3m # 查询超时阈值
启动参数调优
# 推荐启动参数模板
--storage.tsdb.retention.time=30d \
--storage.tsdb.max-block-duration=4h \
--storage.tsdb.min-block-duration=2h \
--storage.tsdb.path=/opt/prometheus/tsdb \
--query.max-concurrency=32 \
--query.max-samples=50000000 \ # 单查询最大样本量
--web.max-connections=512 \ # 最大HTTP连接数
--storage.tsdb.memory-chunks=2097152 # 内存块数(默认524288)
4.1.2 外部存储解决方案集成
| 方案 | 核心能力 | 适用场景 | 性能损耗 |
|---|---|---|---|
| Thanos | 全局查询层 + 对象存储 | 多集群聚合/长期存储 | 10~15% |
| Cortex | 水平扩展 + 多租户 | 大规模SaaS环境 | 20~25% |
Thanos 集成配置示例:
remote_write:
- url: "http://thanos-receive:10908/api/v1/receive"
queue_config:
capacity: 10000 # 发送队列大小
max_samples_per_send: 2000
max_shards: 50 # 并行发送分片数
write_relabel_configs:
- action: keep # 过滤关键指标
regex: '(up|node_.*|container_.*)'
source_labels: [__name__]
4.2 数据管理优化
4.2.1 数据压缩技术应用
压缩策略对比实施:
# 使用 Zstandard 压缩归档数据(需Thanos组件支持)
thanos compact \
--objstore.config-file=thanos-s3.yml \
--compact.concurrency=4 \
--downsampling.disable \
--wait --retention.resolution-raw=30d \
--retention.resolution-5m=180d \
--retention.resolution-1h=0d \
--compaction.leveled-compactor.compression-level=3 \
--compaction.leveled-compactor.block-upload-compression=zstd
4.2.2 数据降采样策略实施
通过规则引擎生成低精度历史数据:
# 分层规则配置示例(rules/aggregation.yml)
groups:
- name: cpu_agg_5m
interval: 5m
rules:
- record: instance:node_cpu:rate5m
expr: avg(rate(node_cpu_seconds_total[5m])) by (instance, mode)
- name: cpu_agg_1h
interval: 1h
rules:
- record: cluster:node_cpu:rate1h
expr: avg(rate(node_cpu_seconds_total[1h])) by (cluster, mode)
降采样效果对比
| 原始指标量级 | 采样间隔 | 存储减少 | 精度损失 |
|---|---|---|---|
| 10万/s | 15s ——> 5m | 95% | < 3% |
| 50万/s | 30s ——> 1h | 98% | < 8% |
4.2.3 数据过期删除机制设置
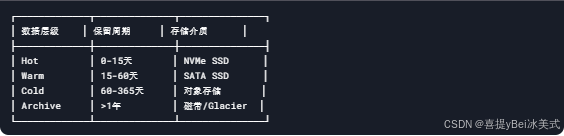
分层存储策略配置示例:
- 原始数据保留15天(本地SSD)
- 1小时精度数据保留30天(对象存储)
- 1天精度数据保留5年(冷存储)
# 多级保留策略(结合本地与对象存储)
storage:
tsdb:
retention: 15d # 本地热数据(SSD)
remote_write:
- url: "http://thanos:10908/api/v1/receive"
write_relabel_configs:
- action: keep
regex: '(ALERTS|up|process_.*)'
retention: 180d # 冷数据长期保留(对象存储)
数据生命周期策略
五、调优效果验证方法
5.1 压力测试
5.1.1 压力测试工具
# 使用 prometheus-benchmark 工具
./prometheus-benchmark \
--scrape-rate=5000 \ # 模拟样本量/秒
--scrape-interval=15s \
--query.parallel=50 \ # 并发查询数
--query.range=1h \
--duration=24h
5.1.2 关键性能指标
# 存储性能
rate(prometheus_tsdb_compactions_total[1h]) # 压缩频率
prometheus_tsdb_storage_blocks_bytes # 块存储量
# 查询性能
histogram_quantile(0.95, rate(prometheus_engine_query_duration_seconds_bucket[1h]))
# 资源利用率
process_resident_memory_bytes / 1e6 # 内存占用(MB)
rate(process_cpu_seconds_total[5m]) * 100 # CPU使用率(%)
5.2 调优实践原则
1. 渐进式优化:
- 每次只调整1-2个参数
- 使用A/B测试对比效果(新旧配置并行运行)
2. 容量规划公示:

3.故障熔断机制:
# 配置应急熔断规则
alert: PrometheusOverload
expr: |
process_resident_memory_bytes > 0.8 * 机器内存 or
rate(prometheus_tsdb_head_samples_appended_total[5m]) > 50000
for: 5m
labels:
severity: critical
annotations:
summary: "Prometheus实例过载"
action: "立即启用备用实例,停止非关键任务抓取"




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











