






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
本文用于实现认知无线电网络研究。随着终端用户质量测量在无线通信向5G时代发展的过程中扮演着越来越重要的角色,平均意见得分(Mean Opinion Score,MOS)已成为一种广泛使用的指标。这不仅因为它反映了终端用户的主观质量体验,还因为它为不同类型流量提供了通用的质量评估指标。
本文提出了一种基于MOS的分布式底层动态频谱接入(Dynamic Spectrum Access,DSA)方案,该方案对具有不同特征的流量(实时视频和数据流量)进行集成流量管理和资源分配。该方案通过强化学习最大化整体MOS,适用于主用户与次用户共享同一频段的系统,同时满足对主用户的总干扰约束。使用MOS作为通用指标,允许携带不同类型流量的节点之间进行学习,而不会降低性能。因此,本文将“指导性范式”应用于所提出的方案,研究不同指导场景对整体MOS的影响,其中新节点由携带相似和不同流量的资深节点进行指导。
摘要:随着终端用户质量测量在无线通信向5G时代发展的过程中扮演着越来越重要的角色,平均意见得分(MOS)已成为一种广泛使用的指标,这不仅因为它反映了终端用户的主观质量体验,还因为它为不同类型流量提供了通用的质量评估指标。本文提出了一种基于MOS的分布式底层动态频谱接入(DSA)方案,该方案对具有不同特征的流量(实时视频和数据流量)进行集成流量管理和资源分配。该方案通过强化学习最大化整体MOS,适用于主用户与次用户共享同一频段的系统,同时满足对主用户的总干扰约束。使用MOS作为通用指标,允许携带不同类型流量的节点之间进行学习,而不会降低性能。因此,本文将“指导性范式”应用于所提出的方案,研究不同指导场景对整体MOS的影响,其中新节点由携带相似和不同流量的资深节点进行指导。仿真结果表明,指导可以将收敛所需的迭代次数减少约65%,同时在不同次网络负载下保持整体MOS高于可接受水平(MOS >3)。在对携带相似和不同流量的节点应用指导方面,仿真结果表明,所有不同的指导场景在MOS性能方面表现一致。
关键词:体验质量测量、干扰、资源管理、信噪比、5G移动通信、质量评估
一、动态频谱接入(DSA)的基本原理与挑战
1. DSA的核心机制
DSA允许次级用户(SU)动态利用主用户(PU)未占用的频谱“空隙”(白空间),其核心技术包括:
- 频谱感知:通过能量检测、循环平稳特征检测等技术实时监测频谱占用情况。
- 动态决策:基于感知结果选择可用信道,并通过自适应调制、功率控制等参数调整避免对PU的干扰。
- 频谱共享:在多用户场景中协调资源分配,保障公平性和效率。
2. 关键挑战
- 干扰管理:需同时避免SU对PU的干扰和SU间的信道竞争。
- 动态环境适配:信道状态、PU行为及网络拓扑的快速变化要求实时响应。
- 高维优化问题:频谱分配需平衡吞吐量、延迟、能耗等多目标,属于NP难问题。
二、Q-Learning在DSA资源分配中的应用框架
1. 算法原理
Q-Learning是一种无模型强化学习算法,通过迭代更新Q值表(状态-动作对的价值)寻找最优策略:
-
状态(State) :包括当前信道占用情况、SU的信道质量(如SINR)、网络负载等。
-
动作(Action) :选择接入的频段、调整发射功率或切换信道。
-
奖励(Reward) :设计需兼顾频谱利用率(如吞吐量)、干扰惩罚(如PU活动检测)、能耗等。
-
更新规则:
Q(s,a)←Q(s,a)+η[r+γmaxa′Q(s′,a′)−Q(s,a)]Q(s,a)←Q(s,a)+η[r+γa′maxQ(s′,a′)−Q(s,a)]
其中,ηη为学习率,γγ为折扣因子。
2. 典型应用场景
- 单用户动态接入:SU独立学习最优信道选择策略,适用于分散式网络。
- 多用户协作分配:通过多智能体Q-Learning协调SU间的频谱竞争,降低冲突概率。
- 能量效率优化:结合能量收集技术,在频谱接入决策中平衡吞吐量与能耗。
三、关键参数与模型设计
1. 状态空间定义
- 频谱感知数据:包括信道占用状态、信噪比(SNR)、干扰水平等。
- 网络上下文信息:如SU位置、业务类型(实时/非实时)、QoS需求。
2. 动作空间设计
- 离散动作:选择特定频段或功率等级,适用于低复杂度场景。
- 连续动作:通过参数化策略(如Actor-Critic框架)调整功率或频段,需结合深度学习。
3. 奖励函数设计
- 正向激励:成功传输数据包的吞吐量增益、频谱利用率提升。
- 负向惩罚:检测到PU活动的干扰惩罚、信道切换导致的延迟。
- 多目标权衡:采用加权求和或分层优先级整合多个优化目标。
四、研究进展与优化方法
1. 经典Q-Learning的改进
- 深度Q网络(DQN) :用神经网络替代Q值表,解决高维状态空间问题,引入经验回放和双重网络提升稳定性。
- 协作学习:多智能体共享Q值或策略,减少冲突并加速收敛(如分布式Q-Learning)。
- 迁移学习:将历史环境中的策略迁移至新场景,降低训练成本。
2. 性能对比
- 与传统算法对比:Q-Learning在动态环境中优于静态分配(如FSA)和启发式算法(如遗传算法),但计算复杂度较高。
- 与其他RL算法对比:DQN在复杂场景中表现优于SARSA,但需要更多训练数据。
3. 典型研究成果
- 动态频谱接入与能量收集:结合DQN与休眠机制,在保障吞吐量的同时降低能耗30%以上。
- 多信道MAC协议优化:通过Q-Learning实现控制信道瓶颈的缓解,提升网络吞吐量20%。
- 车辆网络中的应用:在移动车辆网络中,Q-Learning动态分配信道,减少切换延迟并提高链路稳定性。
五、挑战与未来方向
1. 现有问题
- 探索与利用的平衡:ε-贪婪策略可能导致收敛速度慢或局部最优。
- 部分可观测性:SU可能无法获取全局状态信息,需结合部分观测马尔可夫决策过程(POMDP)。
- 安全与隐私:需防御主用户仿冒攻击(PUEA)等安全威胁。
2. 未来研究方向
- 异构网络融合:在6G智能内生网络中集成DSA与边缘计算、智能反射面(IRS)等技术。
- 联邦强化学习:通过分布式训练保护隐私并提升模型泛化能力。
- 量子强化学习:利用量子计算加速Q值更新,解决超大规模网络优化问题。
六、结论
Q-Learning为动态频谱接入提供了一种自适应、低先验依赖的解决方案,尤其在复杂动态环境中展现出显著优势。未来研究需进一步结合深度学习、多智能体协作及新型网络架构,推动DSA在6G、物联网等场景中的实际部署。
📚2 运行结果

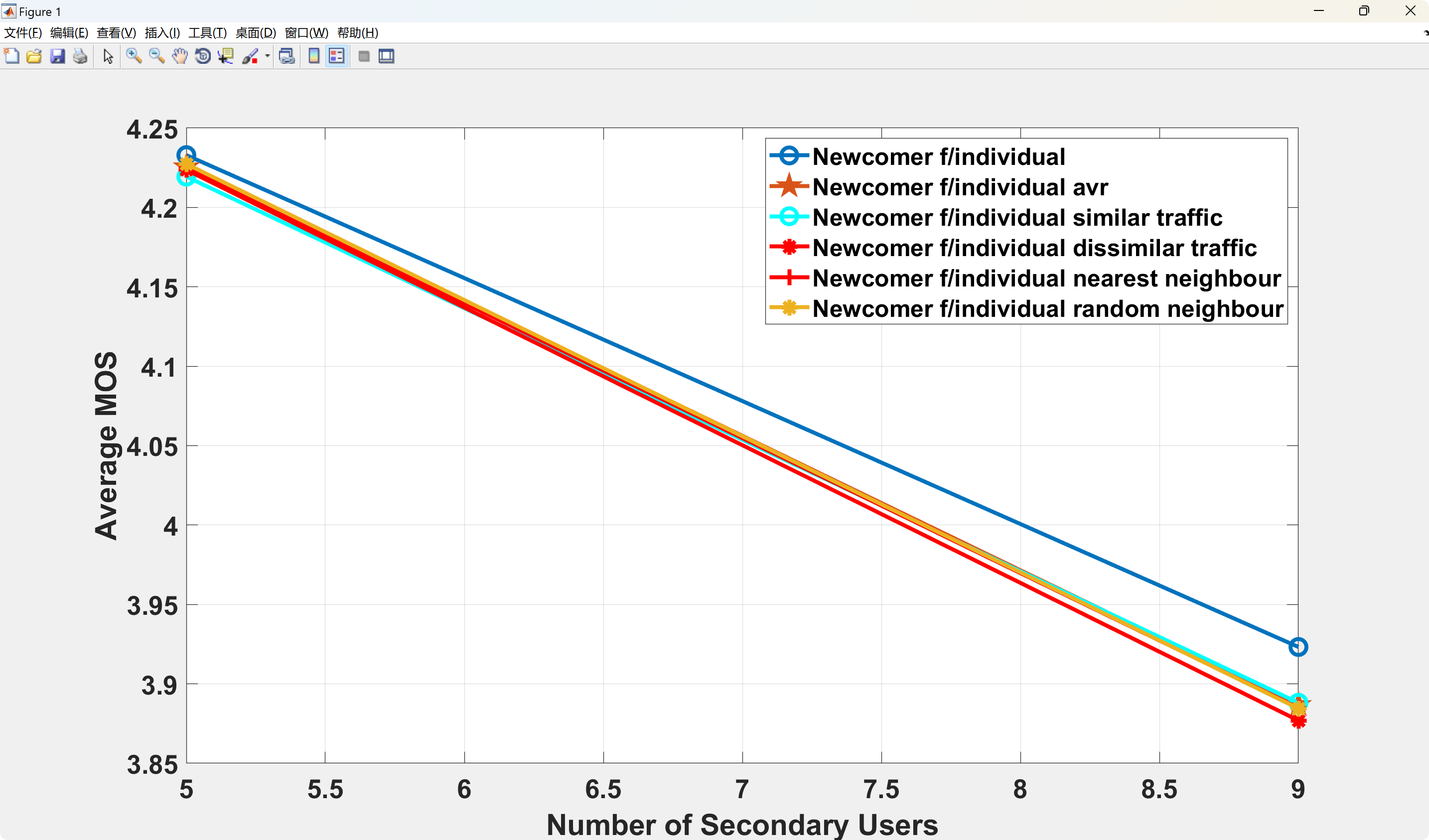
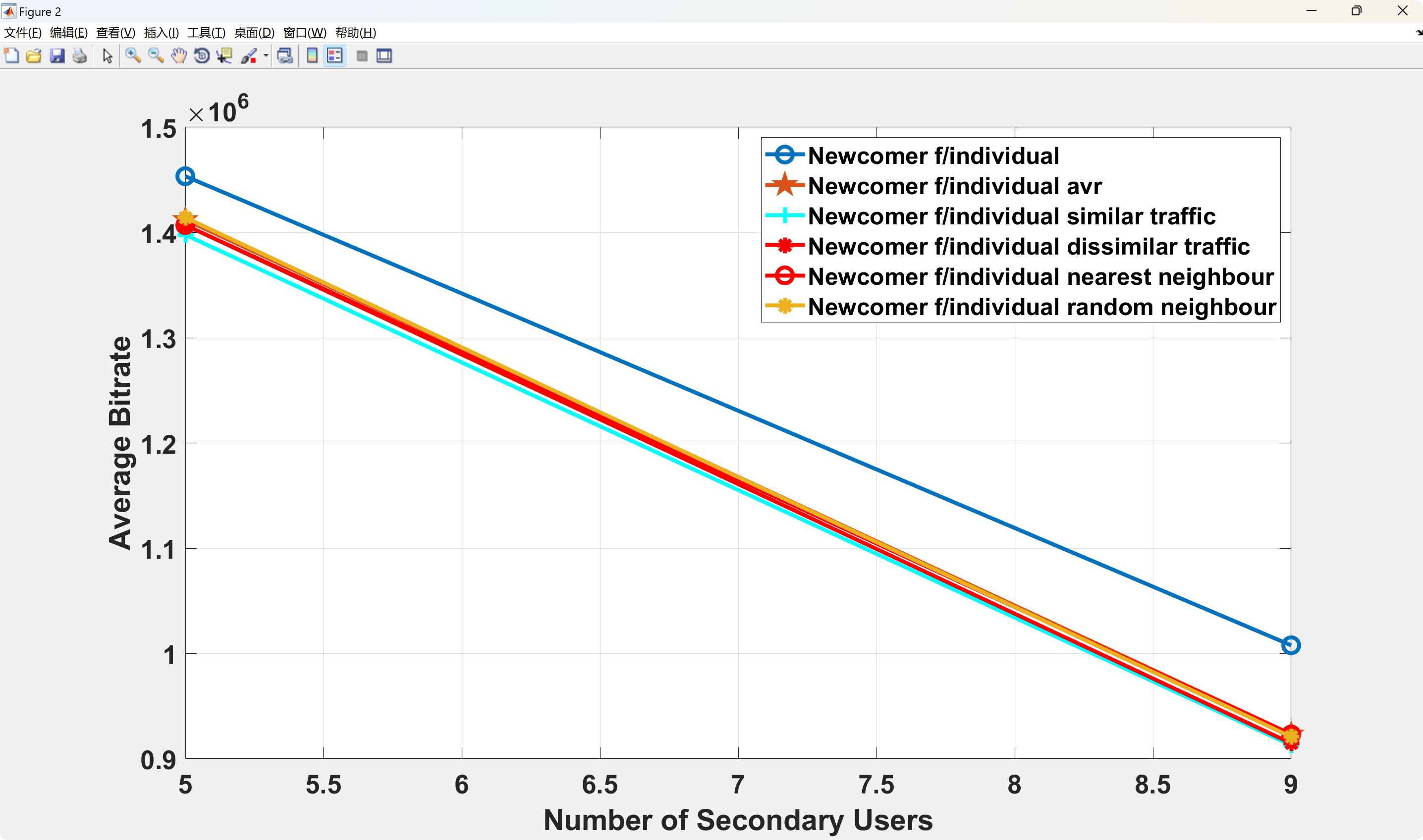
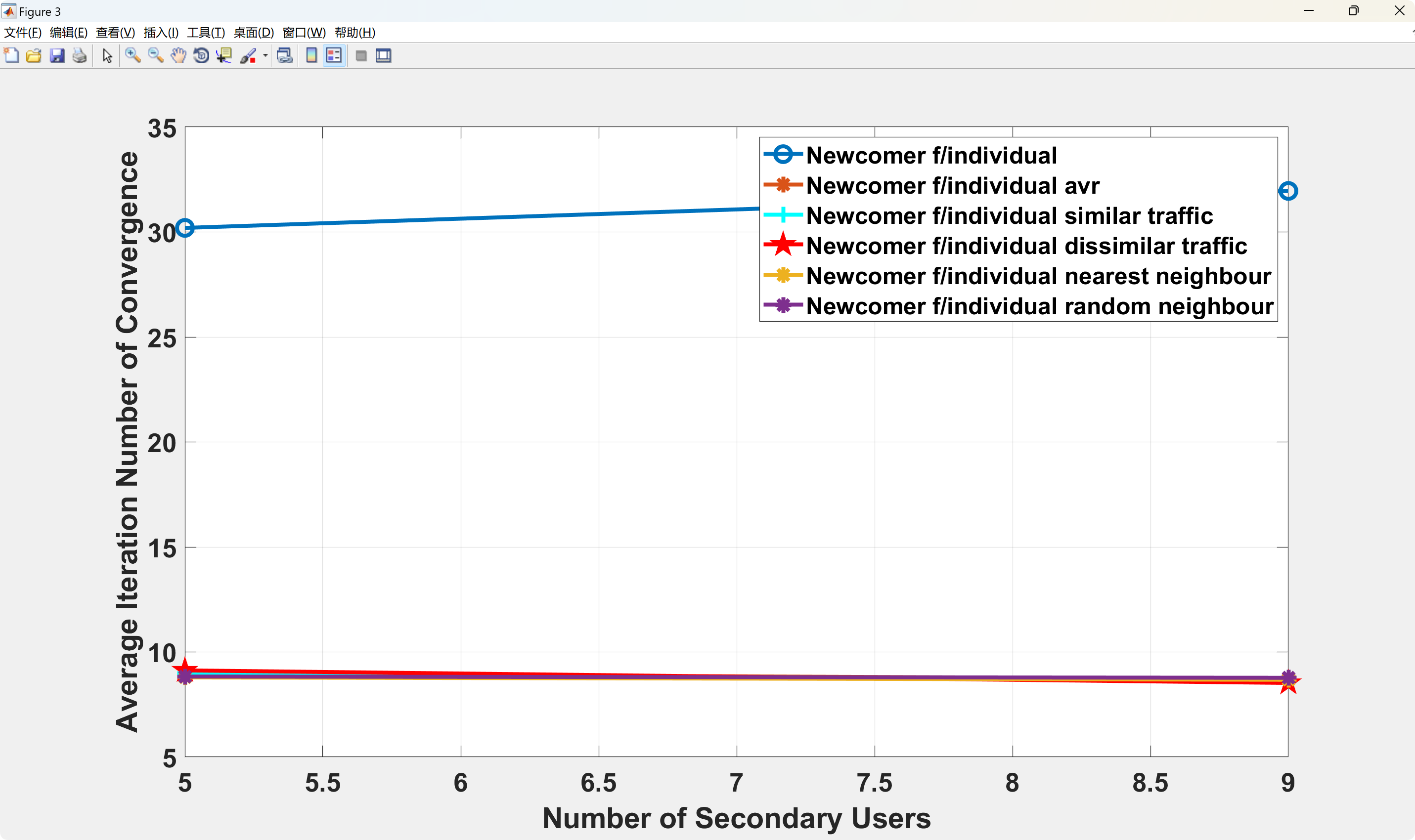
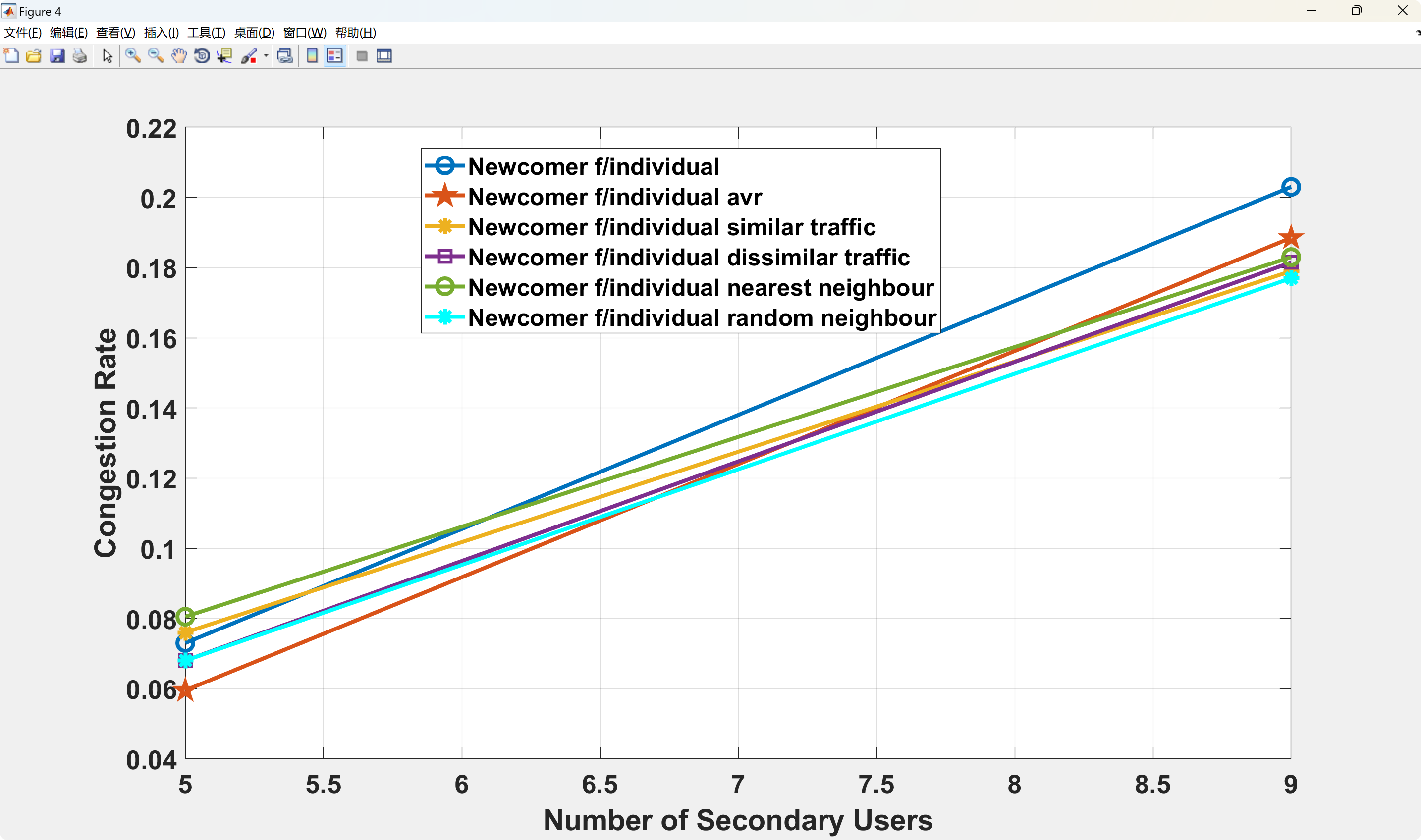
部分代码:
flag_phase1 = 1; % add-one newcomer not learning
flag_phase2= 1; % add-one newcomer learning from/using individual learning
flag_phase3 = 1; % add-one newcomer learning from/using individual learning dissimilar traffic
flag_phase4= 1; % add-one newcomer learning from/using individual learning similar traffic
flag_phase5= 1; % add-one newcomer learning from/using individual learning nearest neighbour
flag_phase6=1; %add-one newcomer learning from/using individual learning random neighbour
% system setupsDistortion_table
% Q-learning setups
learner_setup(1) = 0.01; %delta
learner_setup(2) = 0.8; %epsilon-greedy
learner_setup(3) = 0.4; %discounting factor
learner_setup(4) = 0.1; %learning rate
learner_setup(5) = 1; %cooperation flag
learner_setup (6)=0;
sys_setup(1) = 1e-9; %noise power 1nW
sys_setup(2) = 1e-2; %transmit power 10mW
sys_setup(3) = 10e6; %Hz
sys_setup(4) = 10^(1/10); %primary user SINR requirement, from 1 dB
%create a set of possible transmit rate
[bitrate_set, beta_set, D_at_beta_br, Psi] = create_state_set(sys_setup(3));
Distortion_table{1} = bitrate_set;
Distortion_table{2} = beta_set;
Distortion_table{3} = D_at_beta_br;
Distortion_table{4} = Psi;
sz_I = 2; %binary set {0,1}
sz_L = 2; %binary set {0,1}
sz_br_set = size(bitrate_set, 2);
sz_beta_set = size(beta_set, 2);
flag_plot = 0;
t_max = 100;%maximum q-learning iterations
avg_time_max = 2000; %maximum q-learning iterations for a single setup
n_su =[4 8]; % No. of SUs
learner_setup_new = learner_setup;
sz_n_su = size(n_su,2);
for i=1:sz_n_su
。。。
%Initialization before iterations
% expt = zeros(1, n_su); %accumulated expertness
c = zeros(1, n_su); % immediate cost function
weight_exp = zeros(1, n_su);
D = zeros(1, n_su); % part of the cost function (distortion)
% Initialize the state-actions, {r, beta, I, L}, I={0,1}, L={0,1};
S = zeros(n_su, 2);
S_new = zeros(n_su, 2);
% A = repmat([beta_set(end)], n_su, 1); %old actions
A_new = zeros(n_su, 1); %new actions
Current_Q = zeros(1, n_su);
% Set the required transmit rate randomly
[tran_rate_level, beta_idx] = set_reqired_trans_rate(bitrate_set, n_su);
A = ([beta_set(beta_idx)]'); %old actions
A = repmat([beta_set(end)], n_su, 1); %old actions
if learner_setup(6)
for ii=1:n_su
[A(ii),Q_max] = argmin_Q(Q_table(ii,:,:,:), S(ii,:),beta_set);%find an action
end
end
%fill up Q-table with the first observation
[I, L, psi_su] = observe_state(BW, A ,bitrate_set,beta_set, delta, coeff_psi); %bitrate_set, beta_set, Psi_set, n_su (obsolete parameters)
S(:,1) = I;
S(:,2) = L;
% for testing purpose TO BE DELETED
% beta_idx(:,:)=1;
% Q-learning begin
% Building up Q-table hierarchies for each SU, permutations of state and
% action (initial value = 0), dementionality is:
% #(bit_rate)*#(beta_vector)*#(I)*#(L)
%Q_table = zeros(n_su, sz_br_set, sz_beta_set, sz_I, sz_L);
%set Q_tables elements lower than the minimum transmit rate level to some
%large value
% if ~ learner_setup(6)
% if I+L>=1
% for ii=1:n_su
% if(beta_idx(ii)>1)
% Q_table(ii, 1:beta_idx(ii)-1, :, :) = -1;
% end
% end
% end
% end
if ~ learner_setup(6)🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
[1]蒋卫恒.认知无线电网络动态资源管理与分配算法研究[D].重庆大学[2025-02-18].
[2]黄云霞.基于改进Q学习的认知无线网络动态频谱接入算法研究[D].电子科技大学[2025-02-18].DOI:CNKI:CDMD:2.1012.470964.
[3]李男.认知无线电网络动态频谱接入方案的研究[D].西安电子科技大学,2014.
4]张亚洲,周又玲.基于Q-learning的动态频谱接入算法研究[J].海南大学学报:自然科学版, 2018, 36(1):7.DOI:CNKI:SUN:HNDK.0.2018-01-002.
🌈4 Matlab代码实现
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









