






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
-
MDP(Markov Decision Process)是一种用于建模决策问题的数学框架,而机器人网格是一种常见的环境模型,用于描述机器人在离散的网格世界中移动和执行动作的问题。
在机器人网格中,通常将环境表示为一个二维网格,每个网格单元可以是机器人可以到达的位置。机器人可以根据当前所处的网格位置和执行的动作来决定下一步的移动方向。常见的动作包括向上、向下、向左、向右等。
MDP可以用来描述机器人在网格世界中的决策问题。具体来说,MDP包括以下要素:
-
状态(State):在机器人网格中,状态可以表示机器人所处的网格位置。
-
动作(Action):机器人可以执行的动作,如向上、向下、向左、向右等。
-
转移概率(Transition Probability):给定当前状态和执行的动作,机器人转移到下一个状态的概率。
-
奖励(Reward):在每个状态执行每个动作时,机器人可以获得的奖励。
-
值函数(Value Function):用于评估每个状态的价值,表示从该状态开始,机器人能够获得的期望累积奖励。
-
策略(Policy):决定机器人在每个状态下选择哪个动作的策略。
通过建立MDP模型,可以使用强化学习算法(如值迭代、策略迭代、Q-learning等)来求解最优策略,使机器人在网格世界中能够做出最优的决策。
-
应用值迭代来学习马尔可夫决策过程 (MDP) 的策略 -- 网格世界中的机器人。
世界是自由空间(0)或障碍物(1)。每转一圈,机器人可以向8个方向移动,或保持在原地。奖励函数为一个自由空间,即目标位置提供高奖励。所有其他自由空间都有很小的惩罚,障碍物有很大的负奖励。值迭代用于学习最佳“策略”,该函数将
控制输入分配给每个可能的位置。本文将始终完美执行运动的确定性机器人与随机机器人进行比较,后者与命令移动的概率很小+/-45度。随机机器人的最佳策略是避开狭窄的通道并尝试移动到走廊的中心。
基于应用值迭代的马尔可夫决策过程(MDP)的机器人策略研究
一、MDP与值迭代的理论基础
马尔可夫决策过程(MDP)是强化学习的核心数学框架,用于建模动态环境中的序列决策问题。其核心要素包括:
- 状态空间(S) :机器人可能所处的环境状态集合,例如在导航问题中为坐标位置(如
(x, y))或传感器数据(如障碍物检测结果)。 - 动作空间(A) :机器人可执行的动作集合,如移动方向(前进、左转、右转等)或机械臂操作指令。
- 状态转移概率(P) :执行动作后环境状态变化的概率分布,通常受环境动态性影响(如移动时可能因地面摩擦导致方向偏移)。
- 奖励函数(R) :定义每个状态-动作对的即时奖励,例如到达目标点获得+100奖励,碰撞障碍物则获得-50惩罚。
- 折扣因子(γ) :平衡即时奖励与长期收益的系数(γ∈[0,1]),γ=0时仅关注当前奖励,γ趋近1时更重视未来累积收益。
值迭代算法通过迭代更新状态值函数(V(s))逼近最优策略。其核心公式为贝尔曼最优方程:
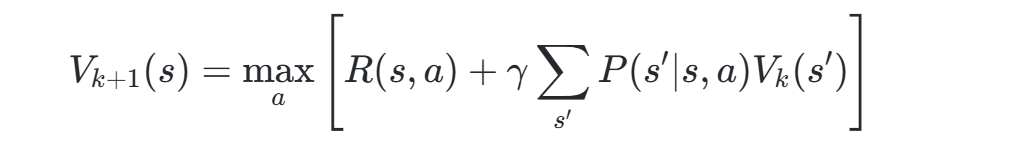
通过多次迭代直至V值收敛,最终提取策略π(s)=argmax_a Q(s,a),其中Q函数表示状态-动作值。
二、值迭代在机器人策略中的实现流程
-
状态与动作建模
- 离散化环境:例如将机器人工作区域划分为网格,每个网格代表一个状态。
- 动作设计:定义基本移动指令(如上下左右),或结合动力学模型生成连续动作(需通过离散化或函数逼近处理)。
- 代码实现示例:
# 状态定义示例(坐标、目标位置、环境状态) state = (x, y, obstacle_detected, goal_pos) # Q函数初始化(字典结构) Q = {s: {a: 0 for a in A} for s in S}
-
奖励函数设计
- 稀疏奖励:仅在关键事件(如到达终点、碰撞)时给予奖励,但需结合启发式函数加速收敛。
- 密集奖励:根据移动距离、能耗等实时反馈设计奖励,需权衡计算复杂度与策略稳定性。
- 动态调整:例如在救护车调度问题中,根据空闲率(r)调整响应时间的奖励权重。
-
算法优化与收敛性
- 异步更新:每次迭代仅更新部分状态的值,减少计算量。
- 终止条件:设定阈值ε,当两次迭代的最大V值变化小于ε时停止计算。
- 参数敏感性:例如折扣因子γ的选择影响长期规划能力,需通过实验调优。
三、机器人领域典型应用案例
-
路径规划与导航
- 仓库机器人:通过值迭代生成避障路径,状态为网格坐标,动作为四方向移动,奖励函数结合距离目标和碰撞惩罚。
- 自动驾驶:在动态交通环境中,MDP用于车道变换和紧急避障决策,需融合传感器数据实时更新状态。
-
柔性制造与装配
- 中兴通讯案例:将机器人控制系统建模为POMDP并转化为MDP,使用SAC算法优化策略,结合预设轨迹规划(ap)与强化学习输出(at)提升控制鲁棒性。
- 机械臂操作:状态包括末端执行器位置、夹持力,动作为关节角度调整,奖励函数基于任务完成精度和耗时。
-
多机器人协作
- 救护车调度:通过值迭代优化车辆分配策略,奖励函数根据响应时间设定(如空闲率r=实际驾驶时间/平均任务时间),平衡区域覆盖与负载均衡。
- 无人机编队:状态包含各无人机位置与任务进度,协作策略通过分布式值迭代实现。
四、挑战与解决方案
-
高维状态空间
- 分层MDP:将复杂任务分解为子任务(如导航→抓取→放置),每层使用独立MDP。
- 特征提取:利用卷积神经网络(CNN)压缩图像状态,再输入值迭代算法。
-
实时性要求
- 并行计算:利用GPU加速Q值更新,例如在Python中使用多进程库(
multiprocessing)。 - 预计算策略:离线生成策略表,在线通过查表快速响应。
- 并行计算:利用GPU加速Q值更新,例如在Python中使用多进程库(
-
部分可观测性(POMDP)
- 信念状态:通过贝叶斯滤波估计环境真实状态,再应用标准MDP算法。
- 深度强化学习:结合LSTM网络记忆历史观测,解决部分可观测性问题。
五、未来研究方向
-
与深度学习的融合
- 深度值网络(DQN) :用神经网络拟合Q函数,解决高维状态下的值迭代维数灾难。
- 元学习框架:训练通用策略适应多种任务,减少重新训练成本。
-
多模态感知集成
- 视觉-力觉融合:在装配任务中,结合摄像头图像与力传感器数据构建复合状态。
- 语义信息增强:利用自然语言处理(NLP)解析任务指令,动态调整奖励函数。
-
社会机器人交互
- 人类偏好建模:通过逆强化学习(IRL)从人类示范中提取奖励函数,优化服务机器人行为。
- 伦理约束:在MDP中引入安全约束(如“不与人类发生碰撞”),通过约束优化生成合规策略。
六、结论
值迭代算法为机器人策略提供了一种高效且理论严谨的求解方法,尤其在离散状态和动作空间场景中表现突出。然而,面对复杂动态环境时,需结合深度学习、分层规划和实时优化技术突破传统MDP的局限性。未来,随着具身智能(Embodied AI)和边缘计算的发展,基于值迭代的MDP框架将在自主导航、协作制造等领域展现更大潜力。
📚2 运行结果



部分代码:
% DRAW THE WORLD, REWARD, ANIMATE VALUE ITERATION, DISPLAY POLICY
subplot(2,2,1)
imagesc(~World);
set(gca,'Xtick',[], 'Ytick',[])
axis equal
axis tight
text(25,-1,'World','HorizontalAlignment','center','FontSize',18)
drawnow
if pauseOn; pause(); end %#ok<*UNRCH>
subplot(2,2,2)
imagesc(R);
axis equal
axis tight
set(gca, 'Xtick',[], 'Ytick',[])
text(25,-1,'Reward function','HorizontalAlignment','center','FontSize',18)
drawnow
if pauseOn; pause(); end
V_hat = MDP_discrete_value_iteration(R,World,false);
if pauseOn; pause(); end
DrawPolicy(V_hat,World,false);
if pauseOn; pause(); end
figure(f1)
V_hat_prob = MDP_discrete_value_iteration(R,World,true);
if pauseOn; pause(); end
DrawPolicy(V_hat_prob,World,true);
if pauseOn; pause(); end
🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction. MIT Press.
[2]Chapter 14 in 'Probabilistic Robotics', ISBN-13: 978-0262201629,


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









