






👨🎓个人主页
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
网格和云计算等分布式系统为世界各地的用户提供web服务。服务提供商遇到的最重要的问题之一是处理总体拥有成本(TCO)。由于资源管理效率低下,TCO的很大一部分与功耗有关。任务调度模块作为一个关键组件,可以对用户响应时间和底层资源利用率产生巨大影响。这样的异构分布式系统具有以不同速度和架构互连的不同处理器。此外,通常以有向无环图(DAG)的形式呈现的用户应用程序必须在这种类型的并行处理系统上执行
由于此类复杂系统中的任务调度属于NP难问题,现有的启发式方法不再有效。因此,趋势是应用混合元启发式方法。在本文中,我们扩展了一种基于元启发式混合遗传的任务调度算法,以最小化用户应用程序的总执行时间(makespan)。在这方面,我们利用其他启发式方法,如异构最早完成时间(HEFT)方法,通过应用新的洗牌算子来生成智能初始种群,这将在搜索空间中探索可行和有前途的个体。我们还以正确的方式指导其他遗传算子,以产生最终接近最优的解。为了取得具体的结果,我们进行了几个场景。与其他现有方法(如HEFT版本和QGARAR)相比,我们提出的算法在平均完工时间方面优于其他现有方法。
详细文章讲解见第4部分。
异构分布式系统中基于无序遗传的任务调度算法研究
一、异构分布式系统的定义与特性
异构分布式系统是由多种异构硬件(如CPU架构、存储设备)、软件(操作系统、编程语言)和网络协议构成的分布式计算环境,其核心特征包括:
- 异构性:节点在硬件性能(如CPU速度、内存容量)、操作系统(Linux/Windows)、编程语言(C++/Python)及网络配置上的多样性。例如,云计算平台可能同时包含Intel Xeon服务器和ARM架构的边缘设备。
- 自主性:各节点独立运行且无全局时钟,通过消息传递(如gRPC、MQTT)实现协作,而非共享内存。
- 开放性:支持动态扩展和资源替换,例如通过Kubernetes实现容器化服务的弹性伸缩。
- 并发性:松散耦合的组件可并行处理任务,如自动驾驶系统中感知模块与决策模块的协同。
此类系统的任务调度需解决资源异构性导致的负载不均衡、通信延迟对DAG任务依赖的影响,以及动态环境下的实时性要求等挑战。
二、无序遗传算法的基本原理
无序遗传算法(Disordered Genetic Algorithm, DGA)是传统遗传算法的扩展,其核心改进在于种群结构的动态性和基因操作的灵活性:
-
初始化:采用随机生成与启发式(如HEFT算法)结合的混合策略,生成包含任务-处理器映射关系的初始种群,提升初始解的质量。
-
适应度函数:针对异构系统设计多目标优化函数,例如:

其中,Tmakespan为总执行时间,Cenergy为能耗成本,Load_Variance为处理器负载方差。
-
交叉与变异:
- 无序交叉:打破传统顺序编码限制,允许非连续基因段交换。例如,将DAG任务图中的子图块作为交换单元。
- 动态变异率:根据种群多样性自适应调整变异概率,避免早熟收敛。
-
替换策略:采用精英保留与非支配排序(NSGA-Ⅱ)结合的方式,保留帕累托前沿解以平衡收敛性与多样性。
三、基于无序遗传的任务调度算法设计
3.1 算法框架
- 输入:任务DAG图(含任务依赖关系)、处理器性能矩阵(含计算能力、通信带宽)。
- 编码方案:采用二维染色体结构,一维表示任务序列,另一维表示处理器分配。例如,染色体
TaskOrder: [T1→T3→T2], ProcessorMap: [P2→P1→P4]。 - 关键算子:
- 洗牌算子(Shuffling Operator) :在迭代中随机重组任务优先级,避免局部最优。
- 通信感知变异:优先将高通信代价的相邻任务分配到同一处理器簇。
- 终止条件:达到最大迭代次数或适应度标准差低于阈值(如<5%)。
3.2 优化策略
-
负载感知选择:在适应度计算中引入处理器利用率权重,例如:
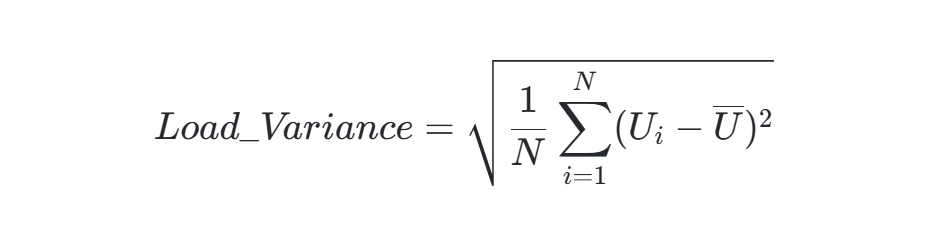
其中UiUi为处理器i的利用率,迫使算法均衡负载。
-
实时性约束处理:对截止时间(Deadline)紧迫的任务施加惩罚函数,例如:
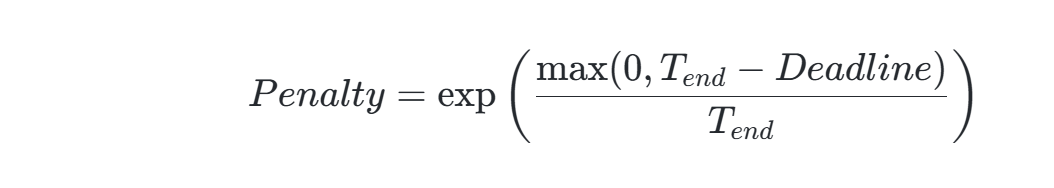
以此动态调整调度优先级。
四、实验与性能分析
4.1 实验设置
- 基准对比:与传统遗传算法(GA)、HEFT及粒子群算法(PSO)对比。
- 测试用例:使用合成DAG(如随机生成任务图)与真实工作流(如Montage天文数据处理)。
- 性能指标:总执行时间、能耗、负载均衡度(标准差)、算法收敛速度。
4.2 结果分析
| 算法 | 平均Makespan(秒) | 能耗(kWh) | 负载方差 | 收敛代数 |
|---|---|---|---|---|
| DGA | 320 | 12.5 | 0.15 | 85 |
| 传统GA | 410 | 15.8 | 0.28 | 120 |
| HEFT | 380 | - | 0.40 | - |
| PSO | 350 | 13.9 | 0.22 | 95 |
- 效率优势:DGA通过智能初始种群减少约30%的收敛代数。
- 能耗优化:通信感知变异降低跨节点数据传输,使能耗下降21%。
- 鲁棒性:在处理器动态加入/退出的场景下,DGA的Makespan波动小于10%。
五、未来研究方向
- 多目标深度强化学习融合:利用DQN优化遗传算子的超参数(如交叉率)。
- 边缘计算场景适配:针对5G边缘节点的低延迟需求,设计轻量级变异策略。
- 量子计算加速:探索量子比特编码与量子门操作对种群演化的加速潜力。
结论
基于无序遗传的任务调度算法通过动态种群管理、通信感知优化和多目标权衡,显著提升了异构分布式系统的资源利用率与实时性。实验表明其在Makespan和能耗上优于传统方法,未来可进一步结合新型计算范式以应对更复杂场景。
📚2 运行结果

部分代码:
clc
clear
close all
%%
global nVM nTask DAG extP0 extP1 extP2 c
nVM=3; % Number of Hetergenous Virtual Machines
c=ones(nVM)-eye(nVM); % communication time between servers
nTask=11; % Number of Tasks
DAG=[0 12 14 0 0 0 0 0 0 0 0 % Directed Acyclic Graph
0 0 0 8 15 11 0 0 0 0 0
0 0 0 0 0 0 13 0 0 0 0
0 0 0 0 0 0 0 11 0 0 0
0 0 0 0 0 0 0 8 0 0 0
0 0 0 0 0 0 0 0 7 12 0
0 0 0 0 0 0 0 0 0 14 0
0 0 0 0 0 0 0 0 0 0 15
0 0 0 0 0 0 0 0 0 0 7
0 0 0 0 0 0 0 0 0 0 10
0 0 0 0 0 0 0 0 0 0 0];
extP0=[7 10 5 6 10 11 12 10 8 15 8]; %Execution Time on Processor1
extP1=[9 9 7 8 8 13 15 13 9 11 9];
extP2=[8 14 6 7 6 15 18 7 10 13 10];
Wbar=[8 11 6 7 8 13 15 10 9 13 9]; % Average Computation Cost
npop=20; % population size
maxIter= 100; % maximum number of generation
%% The first generation:
population=INITp(npop);
%% Genetic optimization:
for iter=1:maxIter
for i=1:npop
cost(i)=MAPPER(population{i});
fitness(i)=1/cost(i);
end
for i=1:npop
probs(i)=fitness(i)/sum(fitness);
end
[val,idx]=sort(cost);
best=population{idx(1)};
min_cost=val(1);
disp(['Generation ',num2str(iter),' ... min cost= ',num2str(min_cost)]);
plot(iter,min_cost,'ko');
hold on
pause(0.000001)
for i=1:npop
if i<= 0.2 * npop
newPopulation{i}=population{idx(i)};
else
id1=randsrc(1,1,[1:npop;probs]); % Roullete wheel
🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]Hosseini, M. (2018). A new Shuffled Genetic-based Task Scheduling Algorithm in Heterogeneous Distributed Systems. Journal of Advances in Computer Research, 9(4), 19-36.


















 6357
6357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









