










 本文详细介绍了如何配置Scrapy爬虫的环境,包括Python、Scrapy、Twisted的安装,以及pip的升级。讲解了创建Scrapy项目、设置配置文件、定义items、爬取数据、使用管道处理数据的步骤,并展示了简单的XPath语法。此外,还提到了Scrapy框架的核心组件以及爬虫的运行流程。
本文详细介绍了如何配置Scrapy爬虫的环境,包括Python、Scrapy、Twisted的安装,以及pip的升级。讲解了创建Scrapy项目、设置配置文件、定义items、爬取数据、使用管道处理数据的步骤,并展示了简单的XPath语法。此外,还提到了Scrapy框架的核心组件以及爬虫的运行流程。
文章目录
安装Python环境
点击进入官网进行下载 https://www.python.org/downloads/
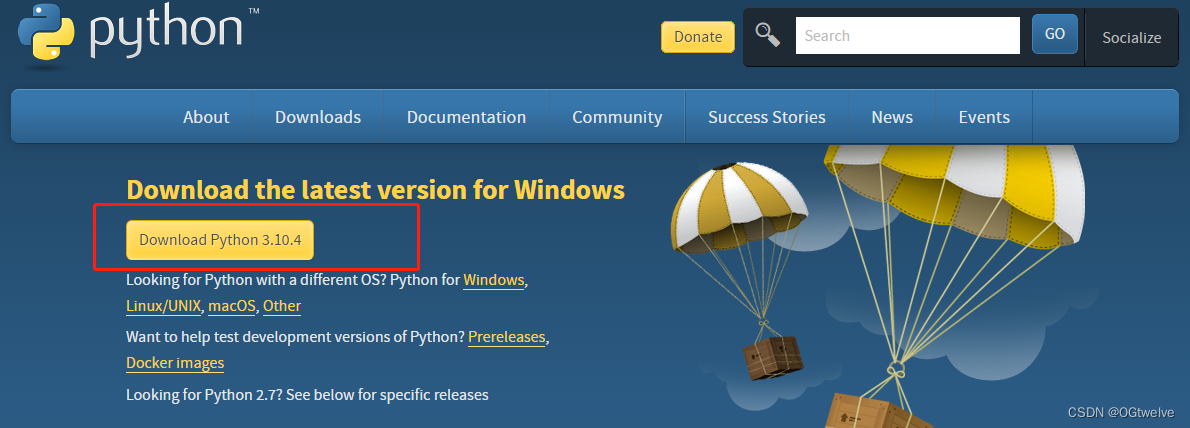
直接下载最新版即可
下载后安装, 不要着急直接点安装, 选择第二个选项客制化安装 customize的安装, 在这里因为我已经安装过了, 没办法展示安装的第一个界面了.
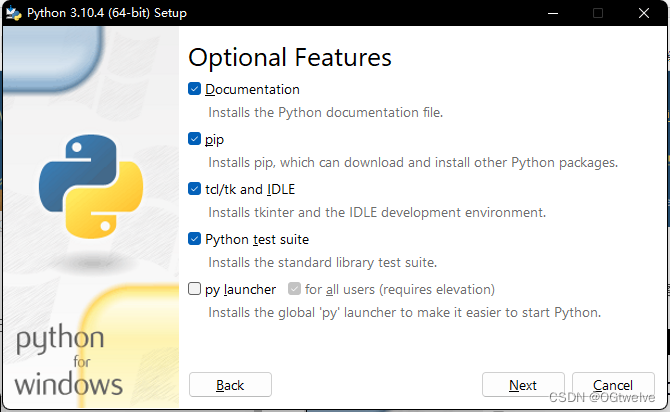
这个页面内要进行全选
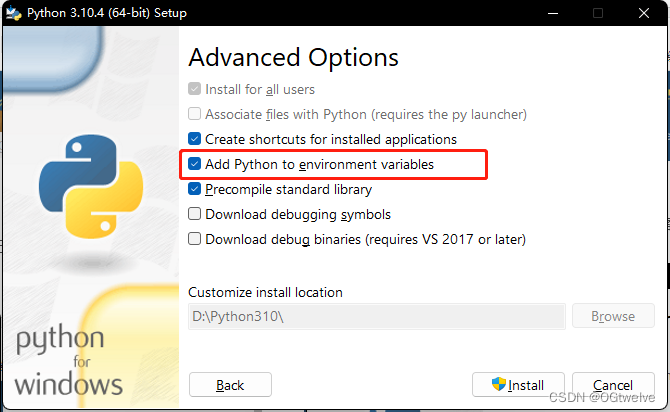
重点是在下一步的时候点击红框部分将Python环境加入环境变量中; 往后一路ok就行.
这一步检测是否安装成功以及环境变量是否成功配置.
打开电脑的cmd窗口
可以在电脑自带搜索cmd, 也可以按 win键 + R键 打开执行窗口
在窗口中输入cmd直接回车即可;
最后在cmd窗口内输入 python -v 回车即可

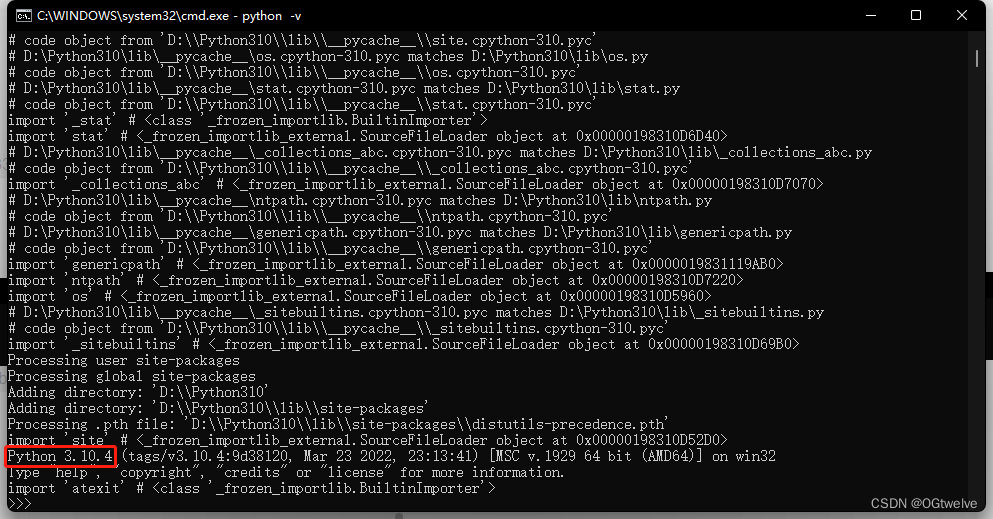
出现版本号即可关闭cmd页面;
安装Scrapy环境
进入该网页安装pywin32
https://github.com/mhammond/pywin32/releases
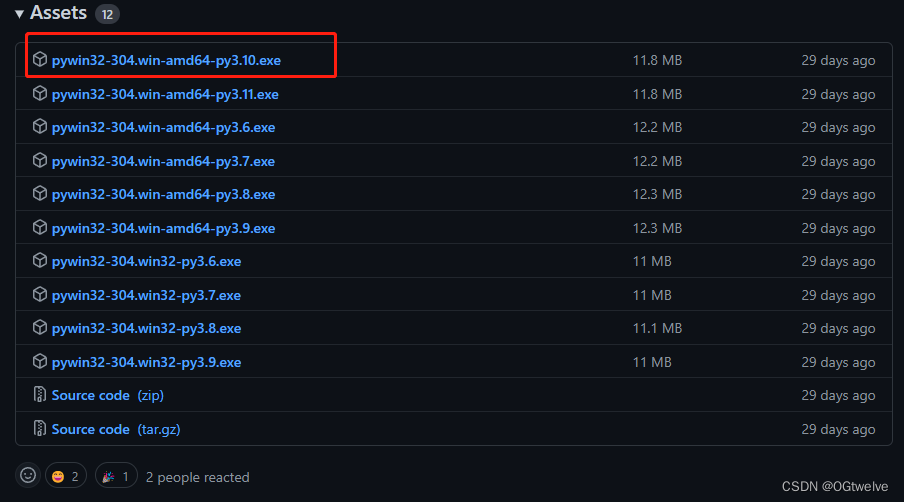
下载与python环境版本一致的即可, 我在上面安装的是3.10所以下面也选择3.10版本即可.
安装一路下一步就可以.
检查pywin32是否安装成功:
- 找到自己安装python的路径, 打开文件夹, 找到python.exe的文件双击打开
- 输入 import win32api 没有报错就是成功的

- 如果在这报错的话 问题应该出在了PYTHONPATH环境变量没有配置, 配置PYTHONPATH环境变量,将python安装目录下lib目录中的site-packages路径添加到PYTHONPATH环境变量,再次检验安装结果; 如何配置环境变量就不在这多做赘述.
安装Twisted
安装Twisted,进入https://www.lfd.uci.edu/~gohlke/pythonlibs/下载对应twisted和lxml
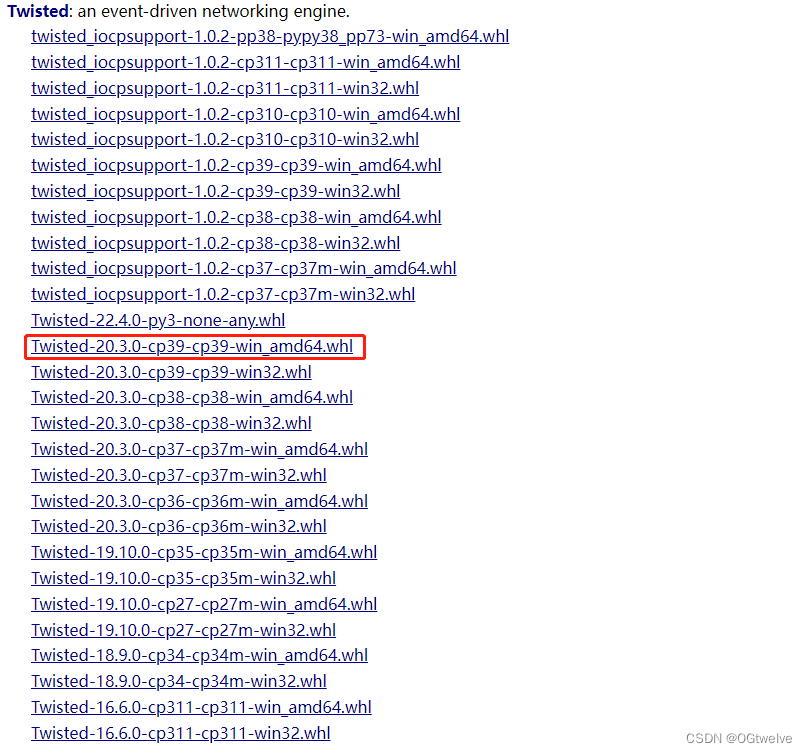
非amd处理器的安装红框下的即可
下一步,在cmd中将上方下载的东西载入即可
pip install 后面跟上文件路径即可
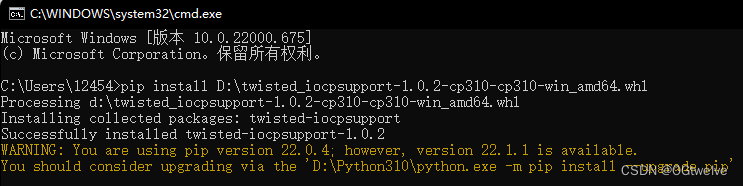
警告不用在意, 这个是说明pip的版本是22.0.4,建议更换到22.1.1, 这个看使用者心情 升级一下只用 upgrade即可
输入pip --version检查是否安装成功

pip的安装
如果在上一步 pip没有安装的同学, 可以按照我以下操作进行安装;
在cmd中 输入py -m ensurepip --upgrade 或者 python -m ensurepip --upgrade 安装即可
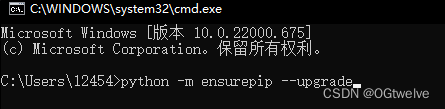
好的那么到这一步都跟下来的同学, 就可以开始安装scrapy了;
scrapy安装
直接在cmd窗口 pip install scrapy即可 (下载这一步不要开vpn, 亲测会失败)
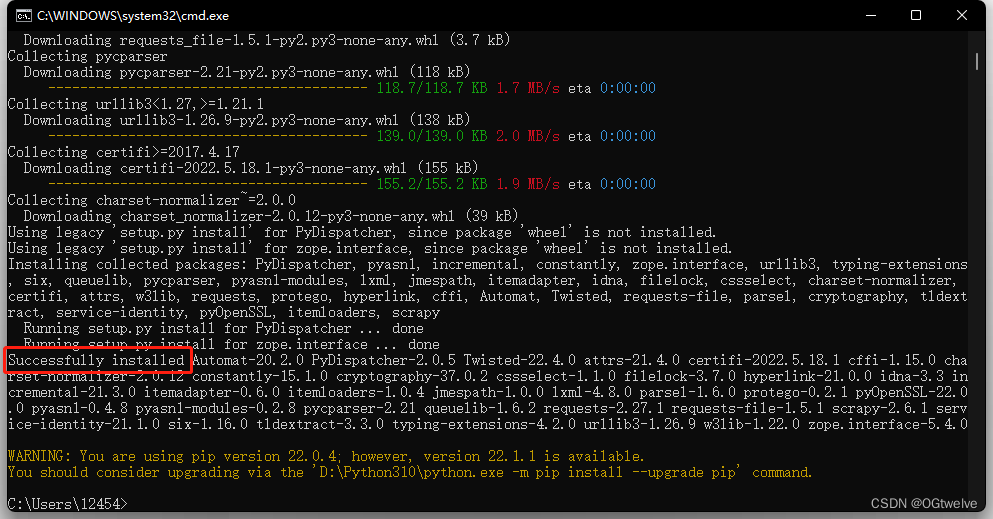
漫长的等待后看到红框即为安装成功;
创建项目
那么以上就是scrapy爬虫前期需要的全部环境内容了, 下面开始使用scrapy框架进入主题吧 !
scrapy startproject 项目名
scrapy genspider 爬虫名 域名
scrapy crawl 爬虫名
这三个是最方便的语句要牢记;
在cmd中输入
scrapy startproject myFirstScrapy
cd myFirstScrapy
scrapy genspider baidu www.baidu.com
然后打开IDE进行后续的修改, 在这我用的是社区版的PyCharm;
打开刚才创建的项目;
这个是整个项目的默认结构;

整体的结构是这样的;
那么说到项目的结构, 下面就引入scrapy的组成
由部分组件组成:
1、引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务(框架核心)。
2、调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址。
3、下载器(Downloader): 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)。
4、爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
5、项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
6、下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
7、爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
8、调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
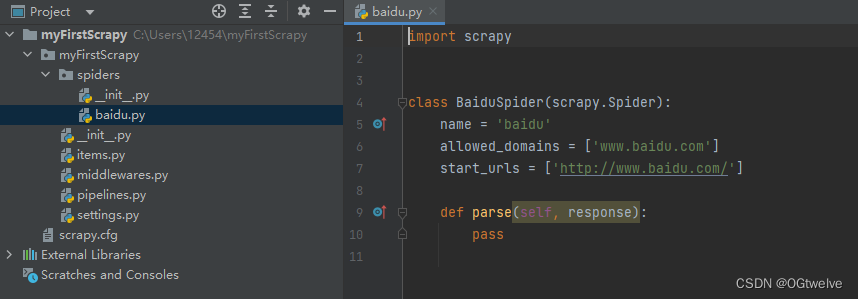
这个baidu的py文件是scrapy自动为我们生成的;
打开 setting文件
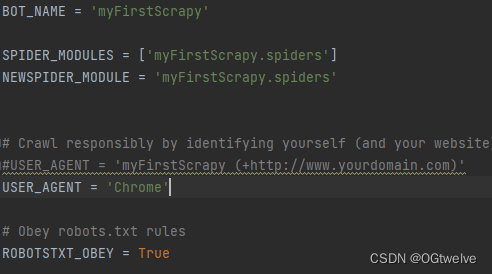
BOT_NAME:项目名
USER_AGENT:默认是注释的,这个东西非常重要,如果不写很容易被判断为电脑,简单点洗一个Mozilla/5.0即可
ROBOTSTXT_OBEY:是否遵循机器人协议,默认是true,需要改为false,否则很多东西爬不了
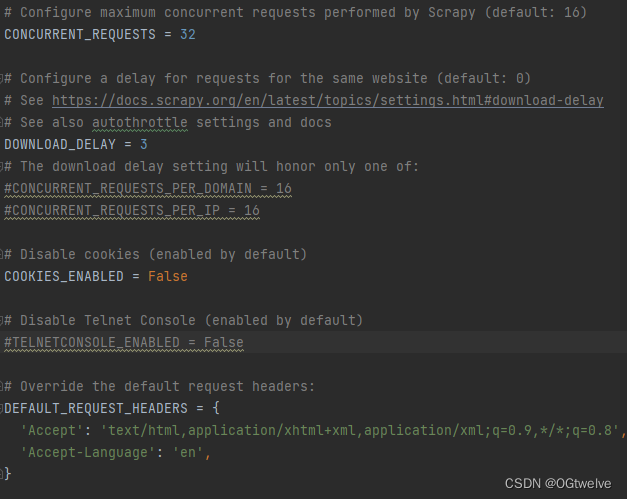
CONCURRENT_REQUESTS:最大并发数,很好理解,就是同时允许开启多少个爬虫线程
DOWNLOAD_DELAY:下载延迟时间,单位是秒,控制爬虫爬取的频率,根据你的项目调整,不要太快也不要太慢,默认是3秒,即爬一个停3秒,设置为1秒性价比较高,如果要爬取的文件较多,写零点几秒也行
COOKIES_ENABLED:是否保存COOKIES,默认关闭,开机可以记录爬取过程中的COKIE,非常好用的一个参数
DEFAULT_REQUEST_HEADERS:默认请求头,上面写了一个USER_AGENT,其实这个东西就是放在请求头里面的,这个东西可以根据你爬取的内容做相应设置。
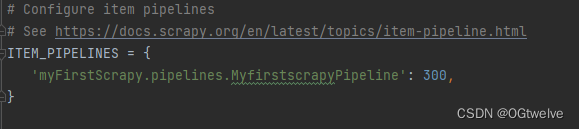
ITEM_PIPELINES:项目管道,300为优先级,越低越爬取的优先度越高

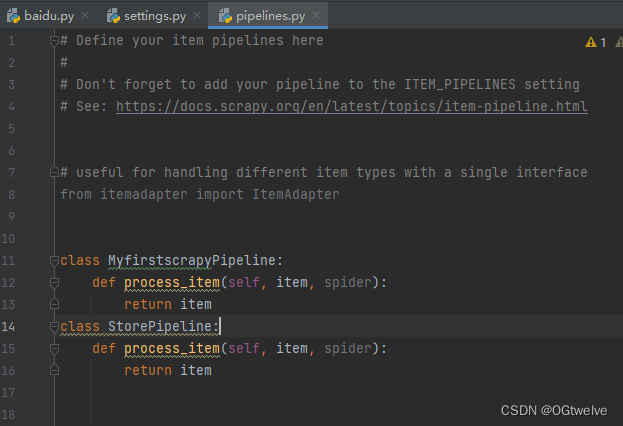
比如我的pipelines.py里面写了两个管道,一个爬取网页的管道,一个存数据库的管道,我调整了他们的优先级,如果有爬虫数据,优先执行存库操作。
爬虫操作, 可以直接跳这一步看效果;
直接使用上面创建的项目, 爬取4399首页的游戏名称
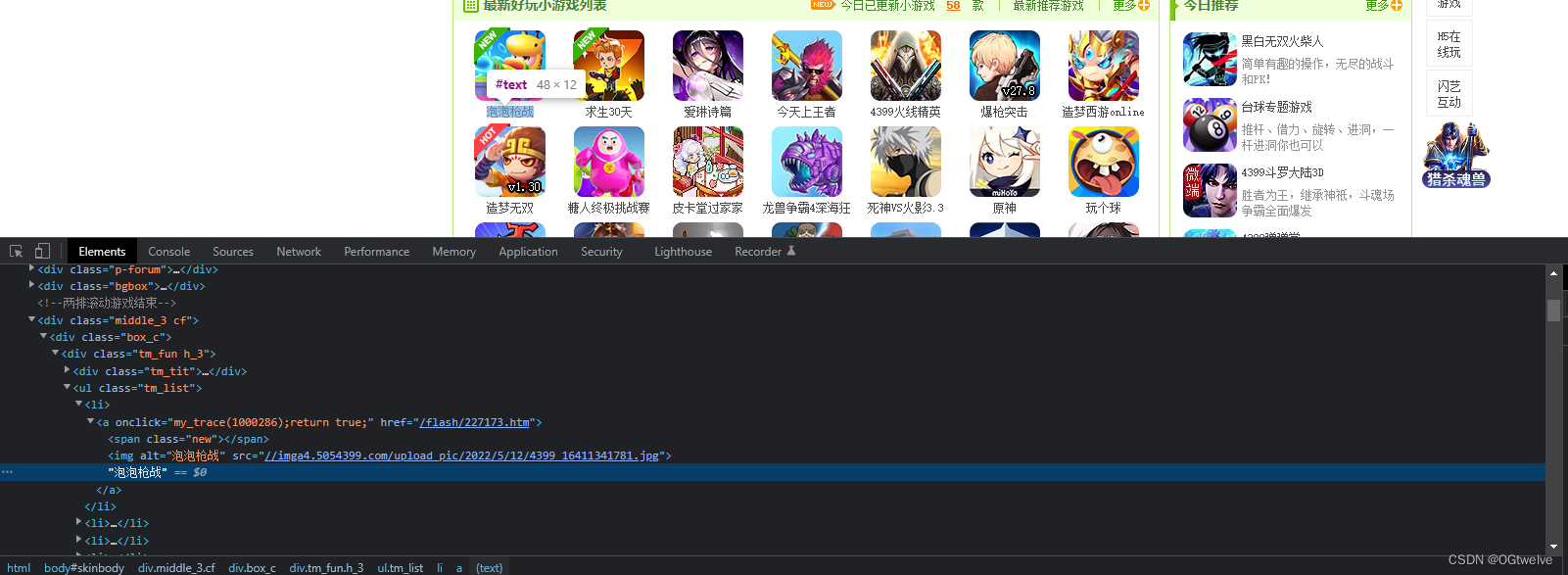
F12检索该数据
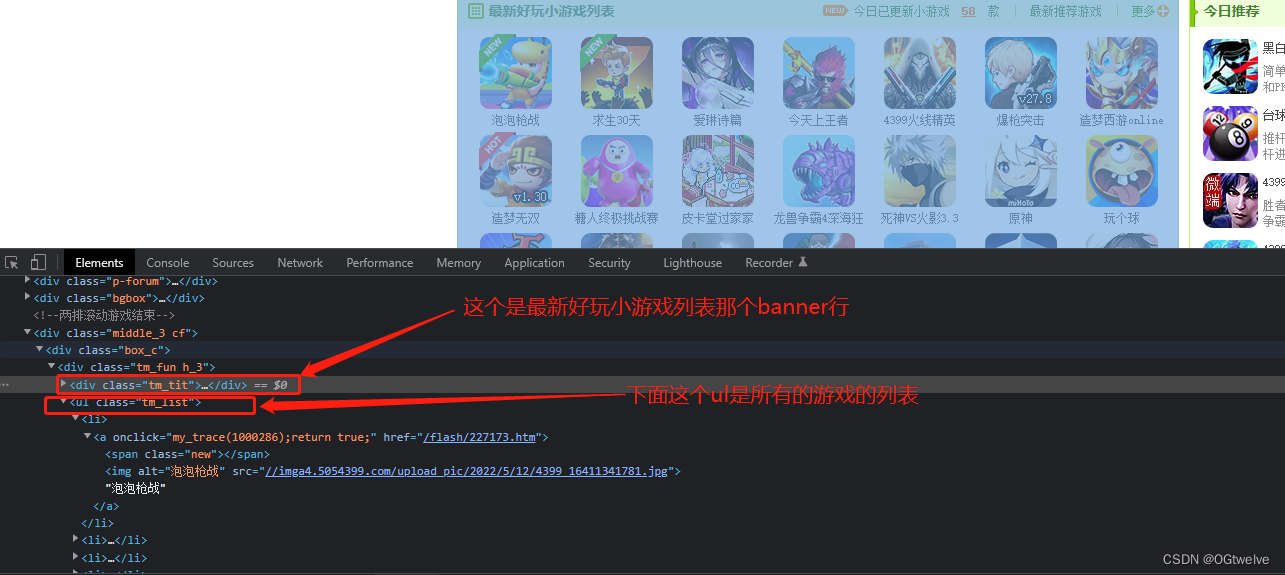
对要抓取数据的html逻辑进行了解, 第一个div是banner行, 第二个ul是所有游戏循环的输出, ul下有li, li下有a标签, a标签内有文本, 所以整体上是 [div class=tm_fun h_3] < [ul class=tm_list] < li < a < text
只需要加个循环就可以搞定
第一步对setting文件进行配置
直接全粘了, 给之前setting文件中内容ctrl+a直接全改即可
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 '
'Safari/537.36 '
}
ITEM_PIPELINES = {
'myFirstScrapy.pipelines.MyfirstscrapyPipeline': 300,
}
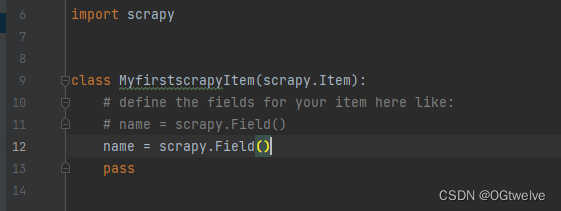
第二步在items中创建需要获取的属性名称
第三步进行爬取
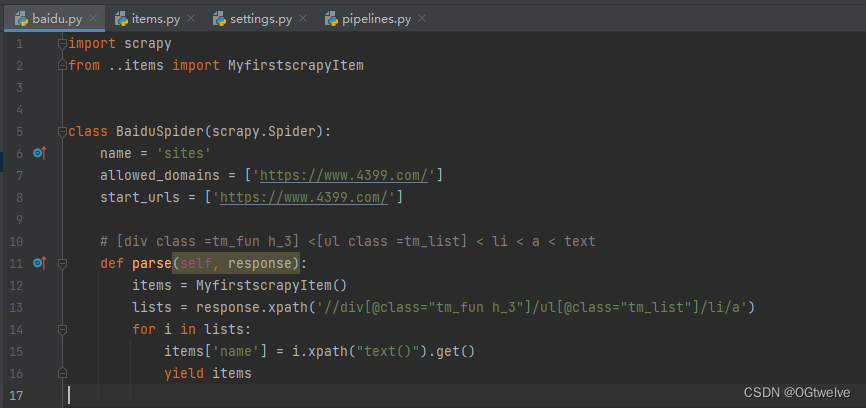
因为有许多的li 所以将li作为条件即可
第四步交给管道输出
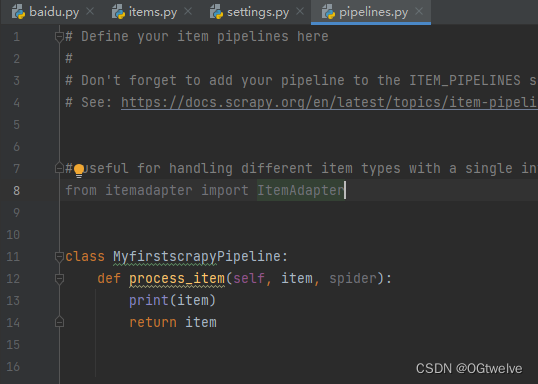
第五步在控制台输入输出
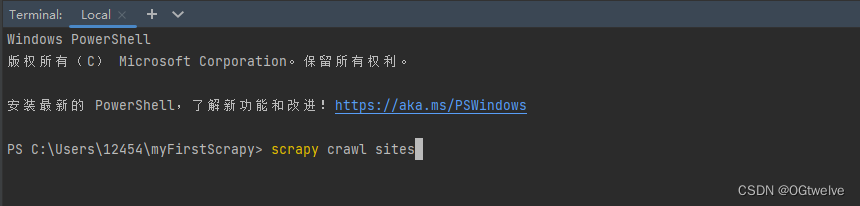
在第三步中, 我将爬虫的name改成了sites, 所以执行语句直接写scrapy crawl sites即可
以下就是获取到的结果, 其实还可以获取一堆的属性, 然后进行json格式的排版直接存入json文件以供微信云开发的数据库导入, 这个是之前小程序开发的时候学的 应该都大差不差, 这些都只是基础;
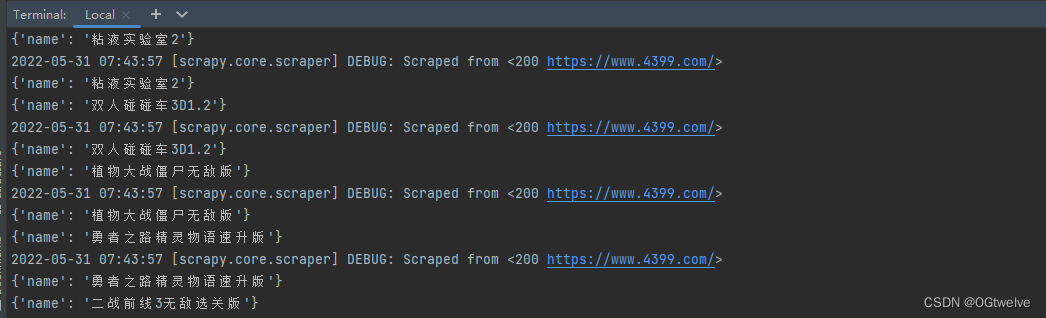
那么以上就是获取到的信息内容, 并没有将开头截出来 感觉不是很有必要 反正就是只要对html的基本结构有了解, 就可以随意获取数据, 当然哈, 这个爬虫, 仅供学习使用, 尝试偷公司数据卖钱的我只能祝你好运了.
xpath语法(scrapy能实现的核心)
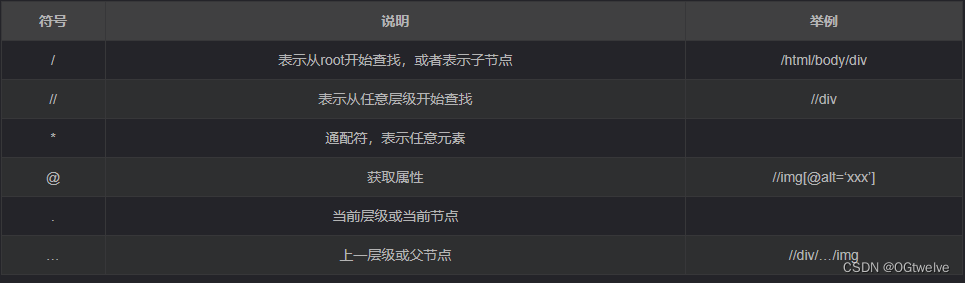
这个是scrapy中符号的说明, 比如在某页面中, 你想查证你是否获取的是正确的路径, 在f12中可以ctrl+f直接进行搜索, 这个搜索框是可以使用xpath的语法, 试一试就好啦;
结尾
以上的操作都仅限于单次展示完全的页面, 如果是淘宝那种往下拉才能刷新出数据的, 需要用到selenium的自动化框架, 这个就等我有时间再进行科普吧;


















 3964
3964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











