







一、知识图谱简介
从实际应用的角度出发其实可以简单地把知识图谱理解成多关系图(Multi-relational Graph)
1、什么是图(Graph)
图(Graph)是由节点(Vertex)和边(Edge)来构成,多关系图一般包含多种类型的节点和多种类型的边。
通俗的来讲,知识图谱要解决这样的问题:如何能更好的描述丰富、海量和复杂的互联网数据?
1.1 数据从哪里来?
从网络上可以获取大量的非结构化数据(例如一篇文章,一条评论),面临一些问题:
* 数据很多,关系却难以提取:在海量数据中把这些关系抽出来
* 涉及大量的NLP技术:文本数据较多,如何从文本中提取有价值信息成为关键
常用技术点:命名实体识别(给词打上标签才好查)、基于实体与关系构建知识图谱网络图 (关系提取)、实体统一(代词消解)
1.2 知识图谱不只是NLP任务
- 如果可以进行特征提取,那么计算机就可以进行训练和推理任务
- embedding (如何进行编码)这件事是Ai最核心的内容,为了让计算机读懂咱们的数据
1.2.1 graph embedding
由于业务需求的不同,graph embedding方法差别很大
- 例如风控模型中对结点进行编码,有了特征编码能做的事就很多了,预测,分析等一些ML任务都能干活了,难点在于如何编码才能更准确体现这个用户的情况。
- 例如图像视频数据,如图卷积模型
特征表达尤为重要
1.3 知识融合
现有数据包括:实体数据,行为数据,文本数据,图片数据
特征进行融合,得到最终的向量,数据多就全用上
1.4 业务还是算法?
都重要,但是业务决定了算法的选择和数据需求以及模型的建立
非常数学业务才能设计出实用的知识图谱,业务和设计起决定性作用
不同应用场景业务和设计也是完全不同的,须具体分析
算法很多都是通用的(命名实体识别,graph embedding等)
二、图数据库
Neo4j:用的人多,模板好找,报错能查
neo4j的安装需要jdk10以上版本
三、「新一代知识图谱关键技术」最新2022进展综述
知识图谱以其强大的语义表达能力、存储 能力和推理能力,为互联网时代的数据知识化组织和智能应用提供了有效的解决方案,以知识图谱为基础的典型应用也逐渐走进各个行业领域,包括智能问答、推荐系统、个人助手、战场指挥系统等
本文对3方面的新一代知识图谱关键技术和理论做分析:1)非结构化多模态数据组织与理解; 2)大规模动态图谱表示学习与预训练模型; 3)神经符号结合的知识更新与推理
1. 非结构化多模态数据组织与理解
多模态数据理解旨在实现处理和理解不同模态信息之间共同表达语义的能力。整体上,和知识图谱 相关的多模态数据的理解主要分为基于本体的多模态语义理解和基于机器学习的多模态语义理解。
基于机器学习的多模态语义理解是目前多模态数据理解的主流方法,和知识图谱的联系主要是利用多模态表示学习方法实现知识补全或应用到 下游任务中.多模态表示学习是指通过利用不同多模态数据之间的互补性,剔除模态冗余性,从而将多模态数据的语义表征为实值向量,该实值向量蕴含了不同模态数据的共同语义和各自特有的特征
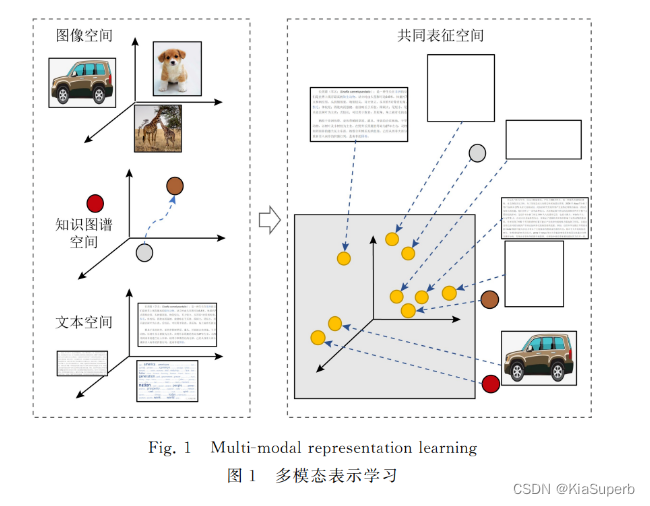
2 大规模动态图谱表示学习与预训练模型
知识图谱的本质是一种语义网络,亦是一种特 殊的图.动态知识图谱同样是一种特殊的动态图.但 是因为知识图谱的特殊性,动态知识图谱可以被分 为2类:一类是时序动态知识图谱,其中蕴含着时间 特征,知识图谱的结构、实体和关系都会随着时间的 推移发生改变;另一类是非时序动态知识图谱,这类 知识图谱中没有显式的时间特征,但是知识图谱会 发生更新,有新的实体和关系添加到原有的知识图 谱中.一般情况来说,已存在知识图谱中的实体和关 系不会发生改变.
四、QA-GNN
1.贡献
(i)相关性评分,我们使用LM来估计相对于给定QA上下文的KG节点的重要性
(ii)联合推理,我们将QA上下文和KG连接起来形成一个联合图,并通过图神经网络相互更新它们的表示
2.背景
KG可以提供额外的、结构化的、高质量的知识,提高模型泛化能力,其结构化知识可以帮助人们理解模型输出;LLM可以自动从文本数据中提取知识,从而降低KG的构建和维护成本
我们提出了QA-GNN,这是一个端到端的LM+KG问答模型,解决了上述两个挑战。我们首先使用LM对QA上下文进行编码,并根据之前的工作检索KG子图
两个关键贡献:(i)相关性评分:由于KG子图由主题实体的所有少跳邻居组成,对于给定的QA上下文,一些实体节点比其他实体节点更相关。因此,我们提出了KG节点相关性评分:我们通过将实体与QA上下文连接起来并使用预训练的LM计算可能性来对KG子图上的每个实体进行评分。这提供了一个关于KG的权重信息的一般框架。
(ii)联合推理:我们设计了QA上下文和KG的联合图表示,其中我们明确地将QA上下文视为附加节点(QA上下文节点),并将其连接到KG子图中的主题实体,如图1所示。这个联合图,我们称之为工作图,将两个模态统一成一个图。然后,我们用相关分数增强每个节点的特征,并设计了一个新的基于注意力的GNN模块用于推理。
3.QA-GNN方法
3.1 工作图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









