







 本文详细介绍了如何下载和安装LIBSVM,一个强大的SVM工具包,包括设置编译环境、使用Matlab接口进行模型训练和预测,并提供了svmtrain和svmpredict函数的示例以及关键参数说明。
本文详细介绍了如何下载和安装LIBSVM,一个强大的SVM工具包,包括设置编译环境、使用Matlab接口进行模型训练和预测,并提供了svmtrain和svmpredict函数的示例以及关键参数说明。
LIBSVM是一个由台湾大学林智仁(Lin Chih-Jen)教授等开发的SVM模式识别与回归的软件包,使用简单,功能强大。是一个广泛应用的SVM工具箱,它提供了一组函数和工具,用于训练和测试支持向量机模型。 Libsvm支持多种SVM模型,包括C-SVM、ν-SVM、One-Class SVM等。
下载链接:https://www.csie.ntu.edu.tw/~cjlin/libsvm/#download
需要提前下一个编辑器,将c++语言转换为matlab可识别的语言。
下载链接:TDM-GCC 10.3.0 release | tdm-gcc
下载不了提供百度网盘链接:https://pan.baidu.com/s/19E3TeY3cFwIaEvrzmAlGuw?pwd=4z69
提取码:4z69
编译器
然后在下载的libsvm的matlab路径下,运行以下代码
setenv('MW_MINGW64_LOC','C:\TDM-GCC-64')%设置编译器的系统变量
mex -setup
%下面是会出现的提示
%{
MEX 配置为使用 'MinGW64 Compiler (C)' 以进行 C 语言编译。
警告: MATLAB C 和 Fortran API 已更改,现可支持
包含 2^32-1 个以上元素的 MATLAB 变量。您需要
更新代码以利用新的 API。
您可以在以下网址找到更多的相关信息:
https://www.mathworks.com/help/matlab/matlab_external/upgrading-mex-files-to-use-64-bit-api.html。
要选择不同的语言,请从以下选项中选择一种命令:
mex -setup C++
mex -setup FORTRAN
%}选择C++就可以,编译成功后。运行
make就成功安装好了libsvm工具箱了,最后将该工具箱添加到路径中,
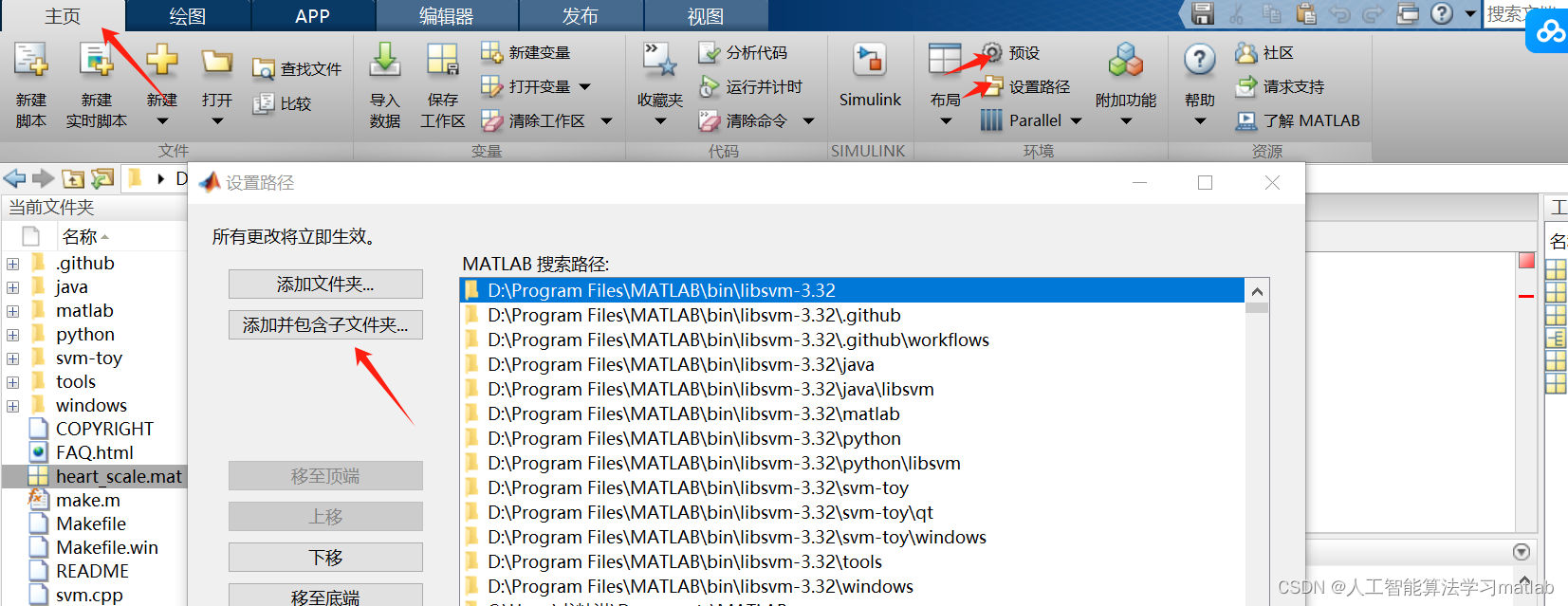
添加后在预设的常规中更新一下。
测试
代码
load heart_scale;
model=svmtrain(heart_scale_label,heart_scale_inst,'-c 1 -g 0.07');
[predict_label,accuracy,dec_value]=svmpredict(heart_scale_label,heart_scale_inst,model);
%输出为2的时候不返回值,所以要设三个。
%官方的工具箱中heart_scale数据有问题,要下最新数据或者为.mat形式结果为Accuracy = 86.6667% (234/270) (classification),则安装成功。
svmtrain函数格式
model= svmtrain(train_label, train_data, ['libsvm_options']);
两个步骤:训练建模——>模型预测
分类 model = svmtrain(train_label, train_data, '-s 0 -t 2 -c 1.2 -g 2.8');
回归 model = svmtrain(train_label, train_data, '-s 3 -t 2 -c 2.2 -g 2.8 -p 0.01');
其中:
train_label表示训练集的标签。
train_matrix表示训练集的数据。
libsvm_options是需要设置的一系列参数,如果用回归的话,其中的-s参数值应为3。
参数说明:
-s svm类型:SVM设置类型(默认0)
0 -- C-SVC
1 --v-SVC
2 – 一类SVM
3 -- e -SVR
4 -- v-SVR
-t 核函数类型:核函数设置类型(默认2)
0 – 线性:u'v
1 – 多项式:(r*u'v + coef0)^degree
2 – RBF函数:exp(-r|u-v|^2)
3 –sigmoid:tanh(r*u'v + coef0)
-d degree:核函数中的 degree 设置(针对多项式核函数)(默认 3)
-g r(gama):核函数中的 gamma 函数设置(针对多项式/rbf/sigmoid 核函数)(默认 1/ k)
-r coef0:核函数中的 coef0 设置(针对多项式/sigmoid 核函数)((默认 0)
-c cost:设置 C-SVC,e -SVR 和 v-SVR 的参数(损失函数)(默认 1)
-n nu:设置 v-SVC,一类 SVM 和 v- SVR 的参数(默认 0.5)
-p p:设置 e -SVR 中损失函数 p 的值(默认 0.1)
-m cachesize:设置 cache 内存大小,以 MB 为单位(默认 40)
-e eps:设置允许的终止判据(默认 0.001)
-h shrinking:是否使用启发式,0 或 1(默认 1)
-wi weight:设置第几类的参数 C 为 weight*C(C-SVC 中的 C)(默认 1)
-v n: n-fold 交互检验模式,n 为 fold 的个数,必须大于等于 2
其中-g 选项中的 k 是指输入数据中的属性数。option -v 随机地将数据剖分为 n 部分并计算交互检验准确度和均方根误差。以上这些参数设置可以按照 SVM 的类型和核函数所支持的参数进行任意组合,如果设置的参数在函数或SVM 类型中没有也不会产生影响,程序不会接受该参数;如果应有的参数设置不正确,参数将采用默认值。
输出
分类参数
iter:迭代次数
nu: 与前面的操作参数-n nu 相同
obj:为SVM问题转换为的二次规划求解得到的最小值
rho:表示决策函数中的常数项的相反数(-b)
nSV:标准支持向量个数,就是在分类的边界上,松弛变量等于0,朗格朗日系数 0=<ai<C
nBSV:边界的支持向量个数,不在分类的边界上,松弛变量大于0,拉格郎日系数 ai = C
Accuracy:预测结果的准确率, 为3*1的向量,第一维就是准确率,显示为百分比,如95,精度就是95%
回归参数
iter:迭代次数
nu: 与前面的操作参数-n nu 相同
obj:为SVM问题转换为的二次规划求解得到的最小值
rho:表示决策函数中的常数项的相反数(-b)
nSV:标准支持向量个数,就是在分类的边界上,松弛变量等于0,拉格朗日系数 0=<ai<C
nBSV:边界的支持向量个数,不在分类的边界上,松弛变量大于0,拉格郎日系数 ai = C
Mean squared error:均方误差
Squared correlation coefficient:平方相关系数















 1520
1520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









