







大数据hadoop部署实验
一、数据预处理
先将要处理的CSV文件通过x-shell传到Ubuntu中
(1) 删除文件第一行字段
#查询前十行
head -10 small_user.csv

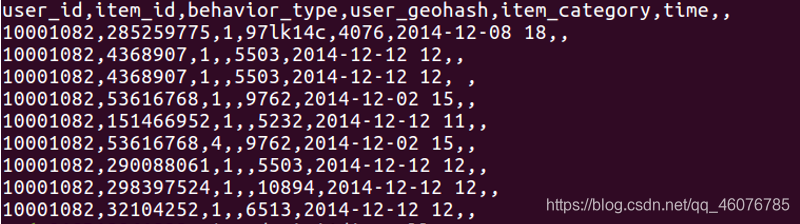
#删除第一行
sed -i '1d' small_user
#再次查询前十行
head -10 small_user.csv

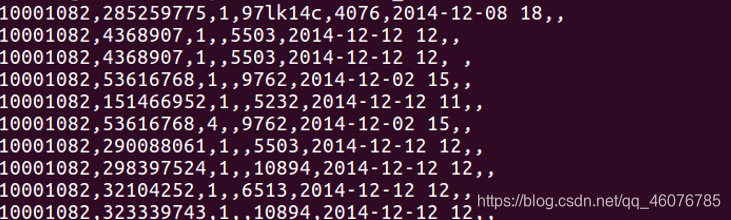
(2)删除每行读取的文件第四个字段 、保留完整的时间格式,2014-12-12,删除每行时间末尾的空格和18,推荐使用字符串截取,并读取的文件每行随机增加省份字段,省份参照省份字典。
#使用vim编辑器新建了一个pre_deal.sh脚本文件
vim pre_deal.sh
在脚本文件中插入以下内容
#!/bin/bash
#下面设置输入文件,把用户执行pre_deal.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行pre_deal.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意,最后的$infile> $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
srand();
id=0;
Province[0]="山东";Province[1]="山西";Province[2]="河南";Province[3]="河北";Province[4]="陕西";Province[5]="内蒙古";Province[6]="上海市";
Province[7]="北京市";Province[8]="重庆市";Province[9]="天津市";Province[10]="福建";Province[11]="广东";Province[12]="广西";Province[13]="云南";
Province[14]="浙江";Province[15]="贵州";Province[16]="新疆";Province[17]="西藏";Province[18]="江西";Province[19]="湖南";Province[20]="湖北";
Province[21]="黑龙江";Province[22]="吉林";Province[23]="辽宁"; Province[24]="江苏";Province[25]="甘肃";Province[26]="青海";Province[27]="四川";
Province[28]="安徽"; Province[29]="宁夏";Province[30]="海南";Province[31]="香港";Province[32]="澳门";Province[33]="台湾";
}
{
id=id+1;
value=int(rand()*34);
print id"\t"$1"\t"$2"\t"$3"\t"$5"\t"substr($6,1,10)"\t"Province[value]
}' $infile> $outfile
#执行pre_deal.sh脚本文件,对small_user.csv进行数据预处理
bash ./pre_deal.sh small_user.csv user_table.txt
#查看前十行
head -10 user_table.txt

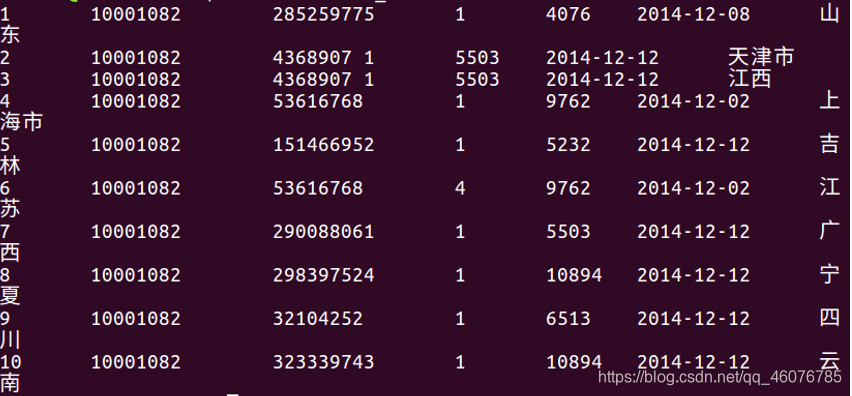
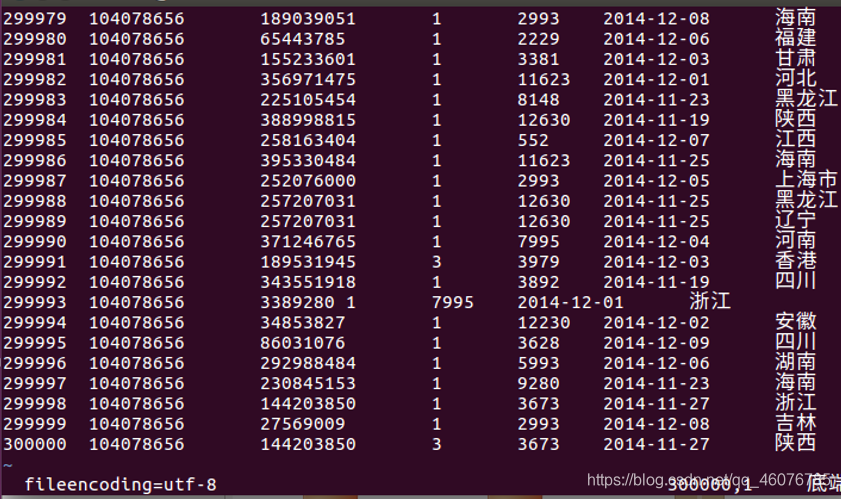
(3)查看文件user_table.txt编码并转换导出文件编码
#先进入csv文件
vi user_table.txt
#将编码变成utf-8
:set fileencoding
二、 将处理完成的数据上传至HDFS保存
先将hadoop启动
start-all.sh

#查看启动成功没有
jps


在hdfs上创建目录big,并将user_table.txt上传到hdfs的big目录下
hdfs dfs -mkdir /big
hdfs dfs -put user_table.txt /big

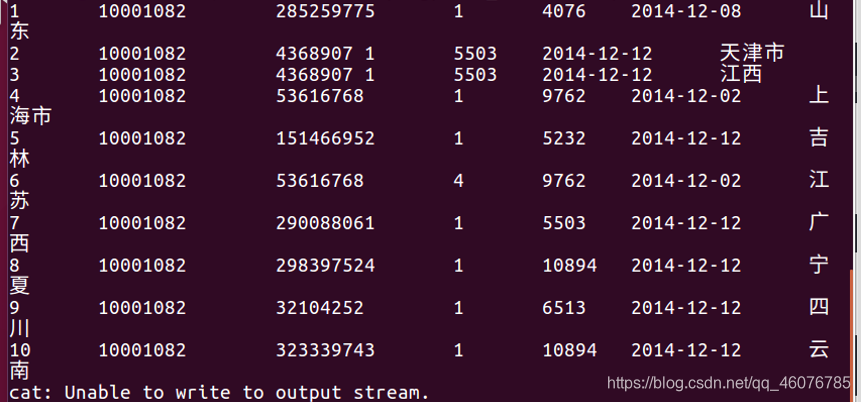
查看前十行
hdfs dfs -cat /big/user_table.txt | head -10

三、 根据上传至HDFS的文件构建数据仓库Hive
(1)创建数据库dblab
create database dblab;

(2)查看数据库
show databases;

(3)使用数据库
use dblab;

(4)创建外部表
CREATE EXTERNAL TABLE dblab.big(id INT,uid STRING,item_id STRING,behavior_type INT,item_category STRING,visit_date DATE,province STRING) COMMENT 'Welcome to xmudblab!' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '/big';
#这里的'/big'是hdfs上的目录

(5)查看表
show tables;

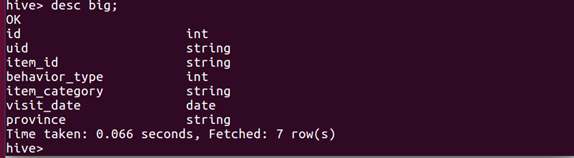
(6)查看表的结构
desc big;
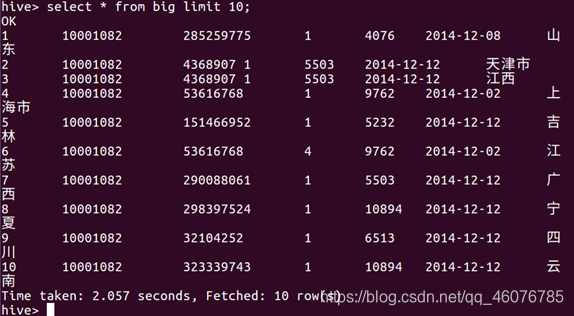
(7)查看文件前十行
select * from big limit 10;
(8)查看相关数据
select behavior_type from big linit 10;

四、 Hive数据分析阶段
(1)根据user_id查询不重复的数据有多少行。
select count(distinct uid) from big;


(2)查询不重复的数据有多少行。
select count(*) from (select uid,item_id,behavior_type,item_category,visit_date,province from big group by uid,item_id,behavior_type,item_category,visit_date,province having count(*)=1)a;


(3)统计时间在2014-12-11和2014-12-12这两天商品售出总和。
select count(*) from big where behavior_type='4' and visit_date >= '2014-12-11' and visit_date <= '2014-12-12';


(4)以月的第n天为统计单位,依次显示第n天网站卖出去的商品的个数。
select day(visit_date), count(distinct uid) from big where behavior_type='4' group by day (visit_date);

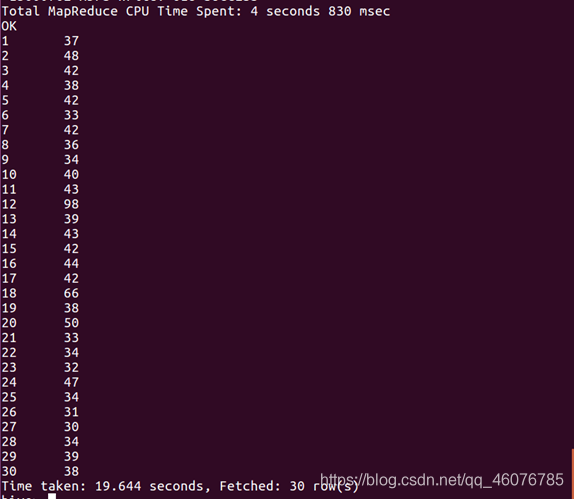
(5)取给定时间和给定地点,我们可以求当天发出到该地点的货物的数量。
如查看2014-12-12发货到江西的数量。
select count(*) from big where province = '江西省' and visit_date = '2014-12-12' and behavior_type='4';


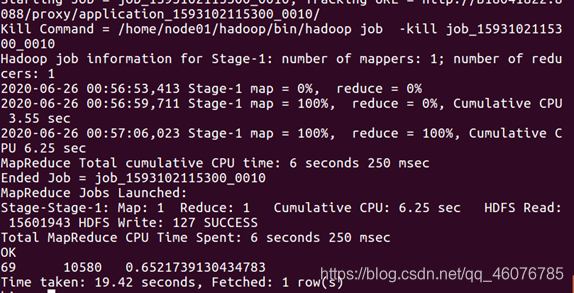
(6)统计出2014-12-11的购买数、浏览数,分析购买率
SELECT count(if(behavior_type='4',1,NULL)),COUNT(if(behavior_type<>'4',1,null)), count(if(behavior_type='4',1,NULL))/COUNT(if(behavior_type<>'4',1,null))*100 from bigdata_user where visit_date ='2014-12-11';

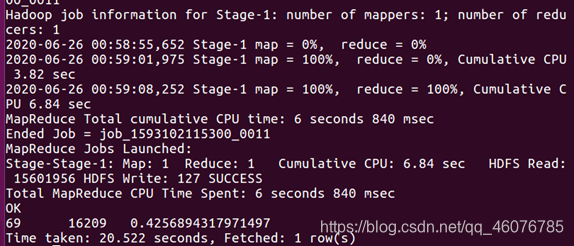
(7)在2014-12-12这天,用户10001082的所有点击行为数、所有用户的点击行为数、并获取用户10001082的所有点击行为数占所有用户的点击行为数的比例
SELECT COUNT(if(uid='10001082',1,NULL)),COUNT(uid),COUNT(if(uid='10001082',1,NULL))/COUNT(uid)*100 FROM bigdata_user WHERE behavior_type='1' and visit_date ='2014-12-12';

(8)查询取时间为2014-12-12每个地区当天的浏览数。
select province, count(behavior_type) from big where behavior_type='1' and visit_date ='2014-12-12' group by province;


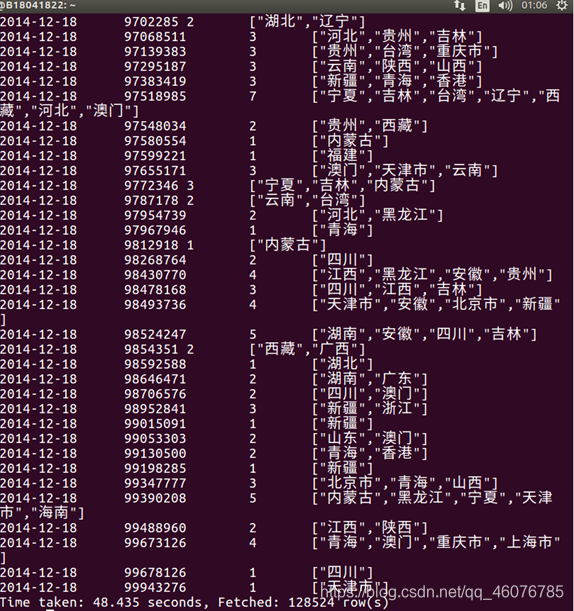
(9)从时间维度统计商品售出明细。
SELECT visit_date,item_id,count(province),collect_set(province) FROM big GROUP BY visit_date,item_id order by visit_date;

(10)查询2014-12-12当天购买数超过5的id及购买商品数量,并以购买的商品数降序排列查询结果。
SELECT uid , COUNT(if(behavior_type='4',1,null)) as num from big where visit_date ='2014-12-12' GROUP BY uid having num>5 ORDER BY num DESC limit 10;

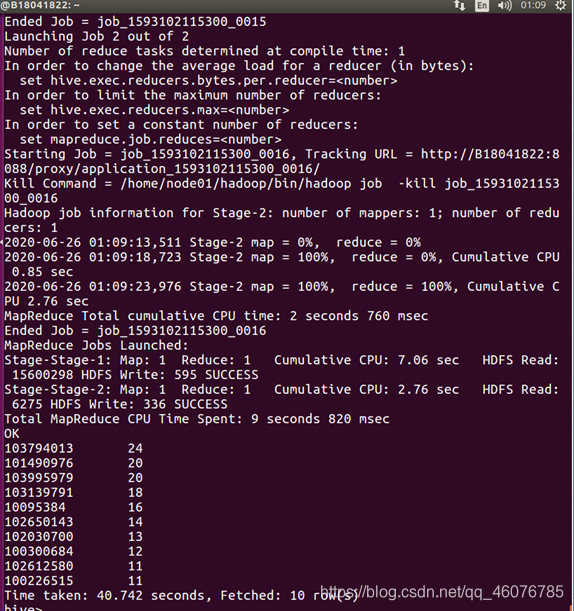
(11)以月的第n天为统计单位,依次显示第n天网站的购买数、浏览数,分析购买率
Select visit_date,count(if(behavior_type<>"4",1,NULL)) ,count(if(behavior_type='4',1,NULL)),count(if(behavior_type='4',1,NULL))/count(if(behavior_type<>"4",1,NULL)) from bigdata_user GROUP BY visit_date;

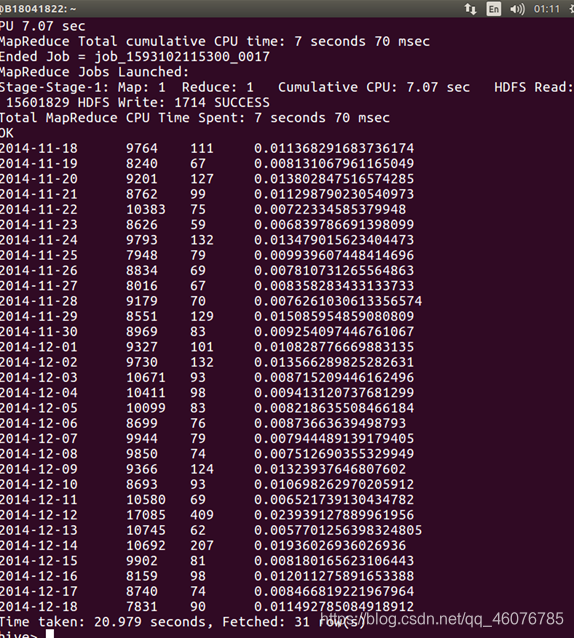
(12)取时间为2014-12-12求当天各地区的购买货物的数量
select province , count(behavior_type) from big where visit_date='2014-12-12' and behavior_type='4' group by province;

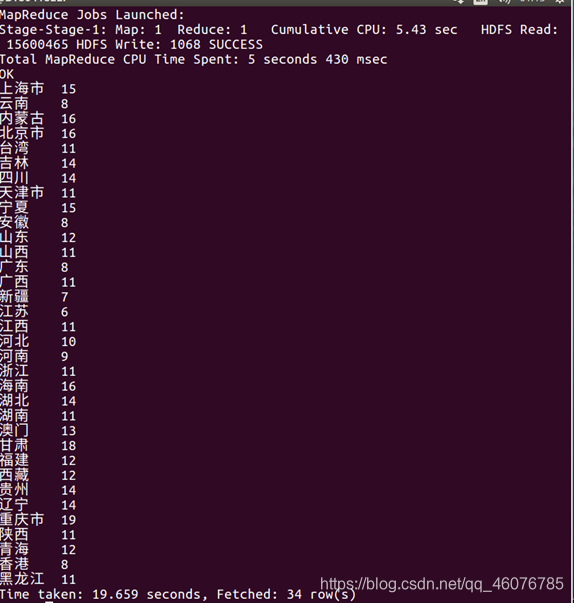
五、 Hive、MySql数据互导
从以上指标中选取几个指标结果导入到Mysql中,要求满足以下几点可视化需求:
在Hive建一个dblab数据库,在建一个user_action表,将处理完得数据文档传上去
在数据库建表grace
CREATE TABLE `grace`(`id` int(50),`uid` varchar(50),`item_id`varchar(50),`behavior_type` int(50),`item_category` varchar(50),`visit_date` DATE,`province` varchar(50)) ENGINE=InnoDB DEFAULT CHARSET=utf8;

使用sqoop语句导入到Mysql数据库上
sqoop export --connect jdbc:mysql://127.0.0.1:3306/grace?useUnicode=true&characterEncoding=utf-8' --username root --password ubuntu--table grace --export-dir '/ hive/warehouse/dblab.db/user_action' --fields-terminated-by '\t';
然后进入mysql数据库查询是否导入成功
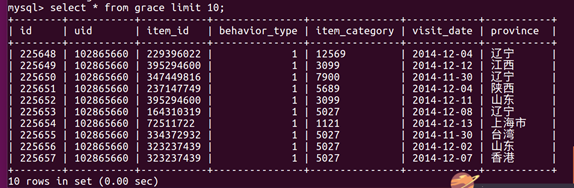
select * from grace limit 10;
可以看到查询成功,说明导入成功
在查询的时候出现一个问题,中文是乱码,关于这个问题,是由于数据库的编码不是utf-8,可以使用下面的语句进行查询
mysql>show variables like'character%';
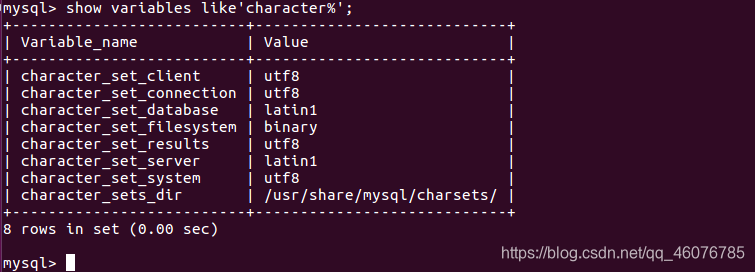
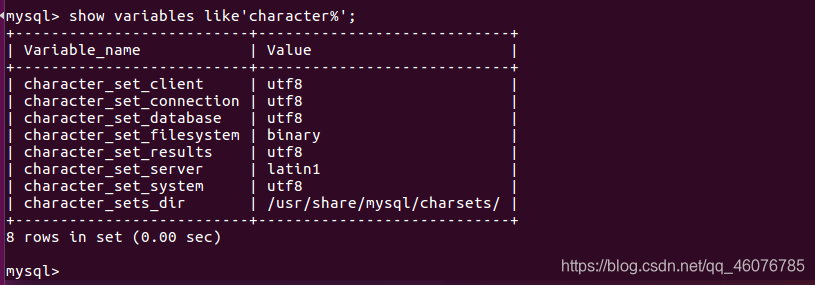
这里可以看到数据库的编码是Latin1,我们只需要用下面的语句修改成utf-8就OK了
set character_set_database=utf8;

再次查询显示已经更改
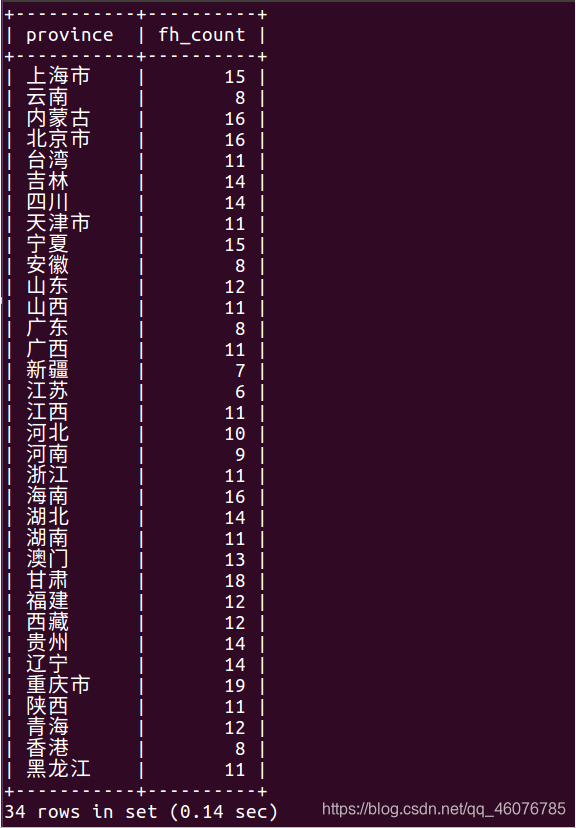
(1) 双十二当天的各个省的发货量。
select province,count(behavior_type)as fh_count from grace where behavior_type=4 and visit_date='2014-12-12' GROUP BY province;
(2) 每天的点击量和购买量。
SELECT visit_date,count(if(behavior_type='1',1,null))as ll_count,count(if(behavior_type='4',1,null))as gm_count from grace group by visit_date;

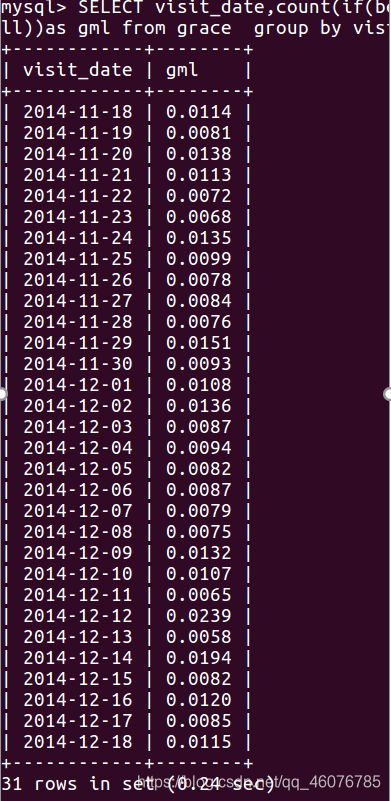
(3) 每天的购买率。
SELECT visit_date,count(if(behavior_type='4',1,null))/count(if(behavior_type<>'4',1,null))as gml from grace group by visit_date;
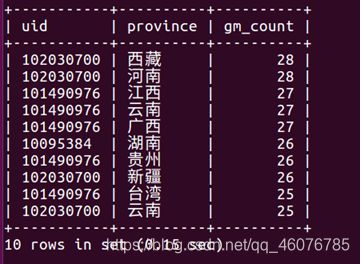
(4)双十二当天top10的用户信息(包括:user_id,购买数量,省份)
select uid,province,count(behavior_type='4') as gm_count from grace where visit_date='2014-12-12' group by uid,province order by gm_count desc limit 10;
六、 利用Django或JavaWeb+Echarts进行数据可视化展示
展示业务量:
1.先导出csv文件便于分析数据
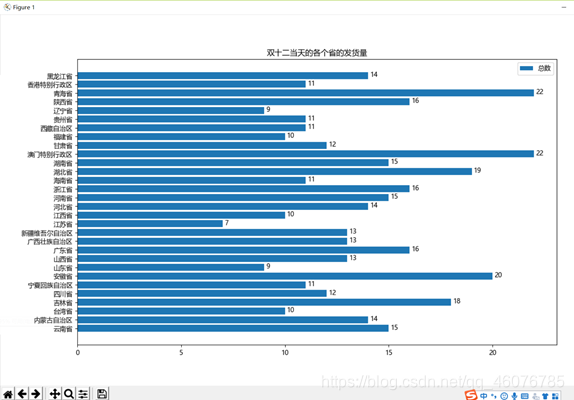
(1)双十二当天的各个省的发货量。
insert overwrite local directory '/home/node01/Documents/a' row format delimited fields terminated by ',' select province, count(behavior_type) from big where behavior_type='4' and visit_date='2014-12-12' group by province;


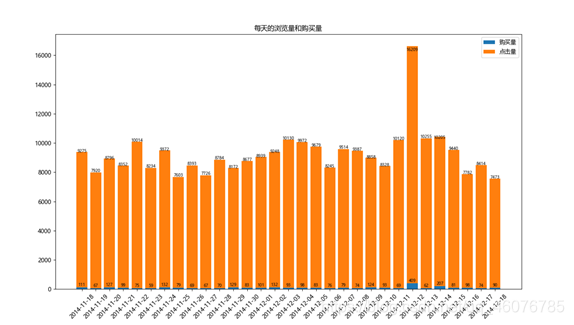
(2)每天的浏览量和购买量。
insert overwrite local directory '/home/node01/Documents/b' row format delimited fields terminated by ',' select * from big;


(3)每天的购买率。
insert overwrite local directory '/home/node01/Documents/c' row format delimited fields terminated by ',' select * from big;


(4) 双十二当天top10的用户信息(包括:useid,购买数量)
insert overwrite local directory '/home/node01/Documents/d' row format delimited fields terminated by ',' select * from big;


2.进行python编程
(1)双十二当天的各个省的发货量。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif']='Microsoft YaHei'
name = "D:/Users/MAIBENBEN/Desktop/a.csv"
df = pd.read_csv(name,encoding='utf8')
#pandas读取
num1 = df['province']
num2 = df['sum']
#定义变量
X1 = np.array(num1)
Y1 = np.array(num2)
#设置位置
plt.xticks(rotation=0)
plt.barh(X1,Y1,label='总数')
#增加数据标签
for y, x in enumerate(num2):
plt.text(x+0.1, y-0.15, "%s" %x)
#列出图例
plt.legend()
#标题
plt.title('双十二当天的各个省的发货量')
plt.show()
(2)每天的浏览量和购买量。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif']='Microsoft YaHei'
name = "D:/Users/MAIBENBEN/Desktop/b.csv"
df = pd.read_csv(name,encoding='utf8')
#pandas读取
num1 = df['time']
num2 = df['dian']
num3= df['gou']
#定义变量
X1 = np.array(num1)
Y1 = np.array(num3)
Y2 = np.array(num2)
#设置位置
plt.xticks(rotation=45)
plt.bar(X1,Y1,label='购买量')
plt.bar(X1,Y2,bottom=Y1,label='点击量')
#增加数据标签
for a,b in zip(X1,Y1):
plt.text(a, b, '%.0f' % b, ha='center', va= 'bottom',fontsize=7)
for a,b in zip(X1,Y2):
plt.text(a, b, '%.0f' % b, ha='center', va= 'bottom',fontsize=7)
#列出图例
plt.legend()
#标题
plt.title('每天的浏览量和购买量')
plt.show()
(3)每天的购买率。

import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif']='Microsoft YaHei'
name = "/Users/MAIBENBEN/Desktop/c.csv"
df = pd.read_csv(name,encoding='utf8')
#pandas读取
num1 = df['time']
num2 = df['lv']
#定义变量
X1 = np.array(num1)
Y1 = np.array(num2)
#设置位置
plt.xticks(rotation=0)
plt.barh(X1,Y1,label='购买率')
#增加数据标签
for y, x in enumerate(num2):
plt.text(x, y, '%.5f' %x)
#列出图例
plt.legend()
#标题
plt.title('每天的购买率')
plt.show()
(4)双十二当天top10的用户信息(包括:useid,购买数量)

import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif']='Microsoft YaHei'
name = "D:/Users/MAIBENBEN/Desktop/d.csv"
df = pd.read_csv(name,encoding='utf8')
#pandas读取
num1 = '用户'+ df['id'].map(str) +'('+ df['province'] +','+ df['sum'].map(str)+'件)'
num2 = df['sum']
plt.pie(num2,labels=num1,autopct='%.0f%%')
plt.title("双十二当天top10的用户信息")
plt.show()
ok,到这里就没了,其实遇到的问题远不止一两个,内事问百度,外事问谷歌,就这样!















 4327
4327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









