






一、数据级高可用简介
随着信息技术的发展,企业越来越依赖于信息化管理,各业务应用的数据信息,主要存储在数据库中,企业对这些数据访问的连续性要求越来越高,为了避免因为数据的中断导致各种损失,数据库的高可用已成了企业信息化建设的重中之中。同时,对于政府、电信、金融、能源、军工等等涉及国计民生的行业或领域的关键业务对于关键数据存储都需要高可用,必须保证数据系统7×24小时全天候运行,防止数据丢失、数据损坏。
二、MHA简介
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司的youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
目前MHA主要支持一主多从的架构。要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库。因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。从代码层面看,MHA就是一套Perl脚本,那么相信以阿里系的技术实力,将MHA改成支持一主一从也并非难事。
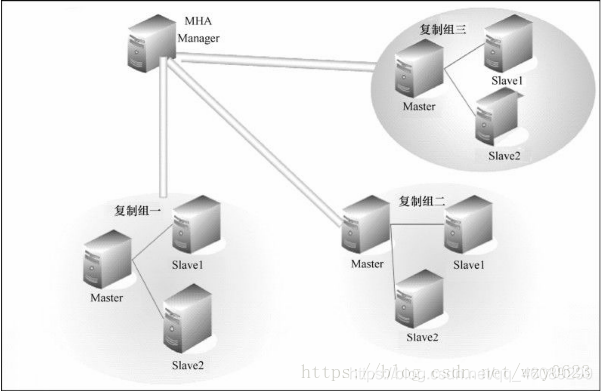
三、MHA工作原理:
1.从宕机崩溃的master保存二进制日志事件(binlog events);
2.识别含有最新更新的slave;
3.应用差异的中继日志(relay log)到其他slave;
4.应用从master保存的二进制日志事件(binlog events);
5.提升一个slave为新master;
6.使用其他的slave连接新的master进行复制。
四、搭建实验环境
server1.2.3都已安装mysql服务
主机名 IP 角色
server1 172.25.254.1 master
server2 172.25.254.2 slave(备master)
server3 172.25.254.3 slave 关闭上次实验的 [killalll mysql-proxy]
server4 172.25.254.4 MHA
五、MHA的mysql高可用架构搭建
首先实现半同步复制(一主二从)
server1上
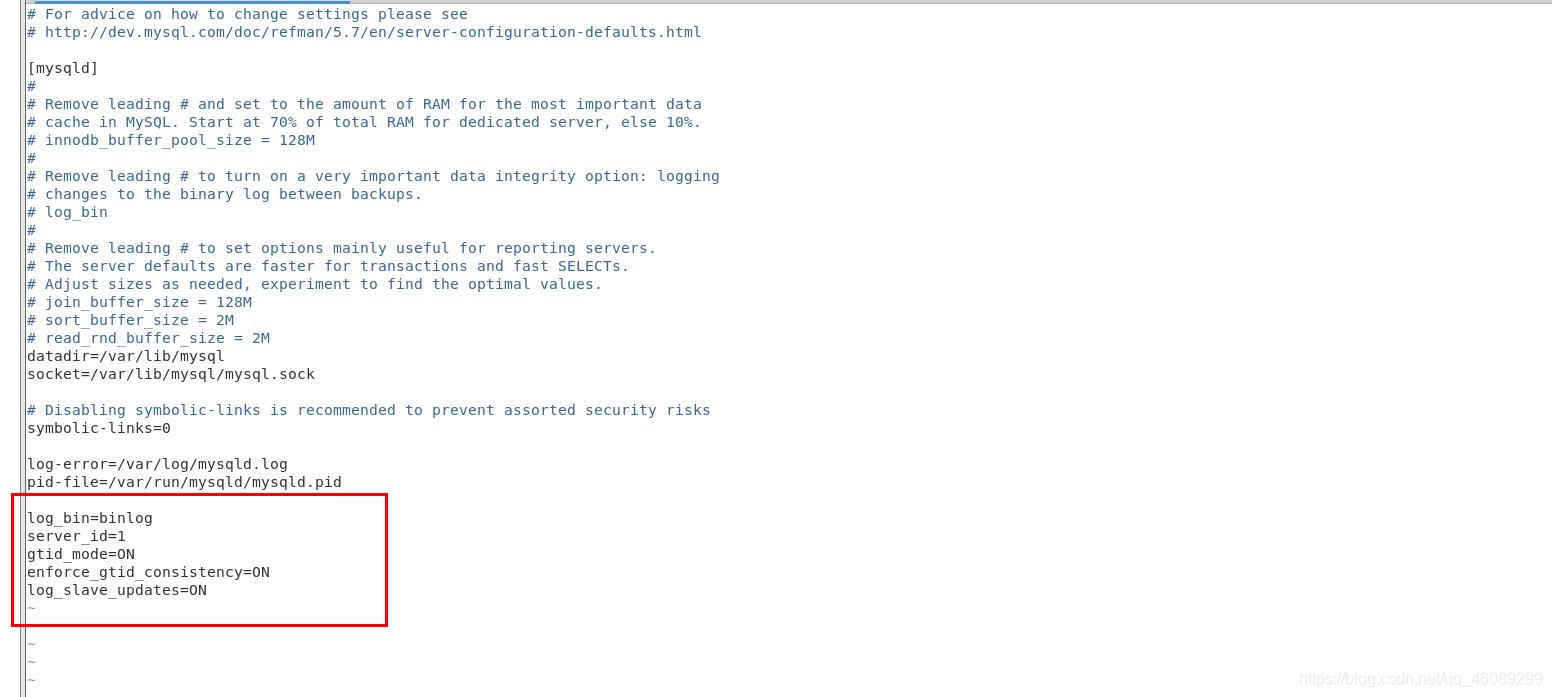
更改server1上的配置文件
[root@server1 ~]# vim /etc/my.cnf
[root@server1 ~]# systemctl stop mysqld.service
[root@server1 ~]# systemctl start mysqld.service

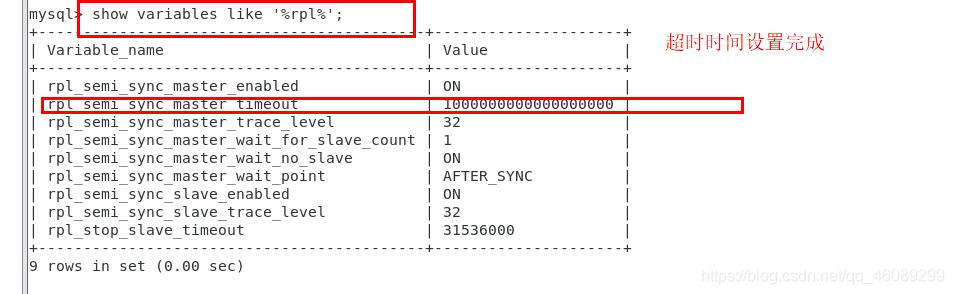
设置超时时间
mysql> SET GLOBAL rpl_semi_sync_master_timeout =1000000000000000000;
Query OK, 0 rows affected (0.00 sec)
查看超时时间
mysql> show variables like '%repl%';
server2上
注意要开启io线程
进行初始化数据库
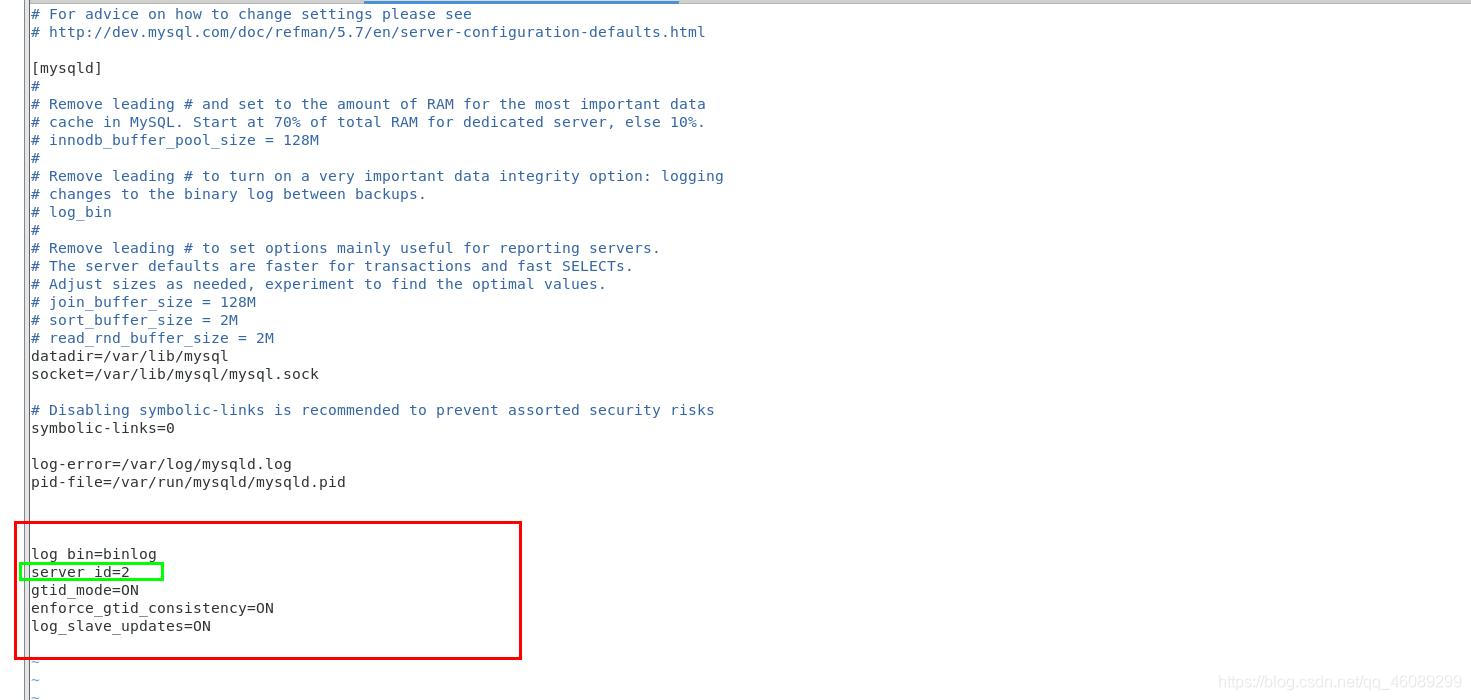
更新server2上的配置文件
[root@server2 ~]# vim /etc/my.cnf
[root@server2 ~]# systemctl stop mysqld.service
[root@server2 ~]# systemctl start mysqld.service

mysql> stop slave; 关闭
mysql> start slave; 开启
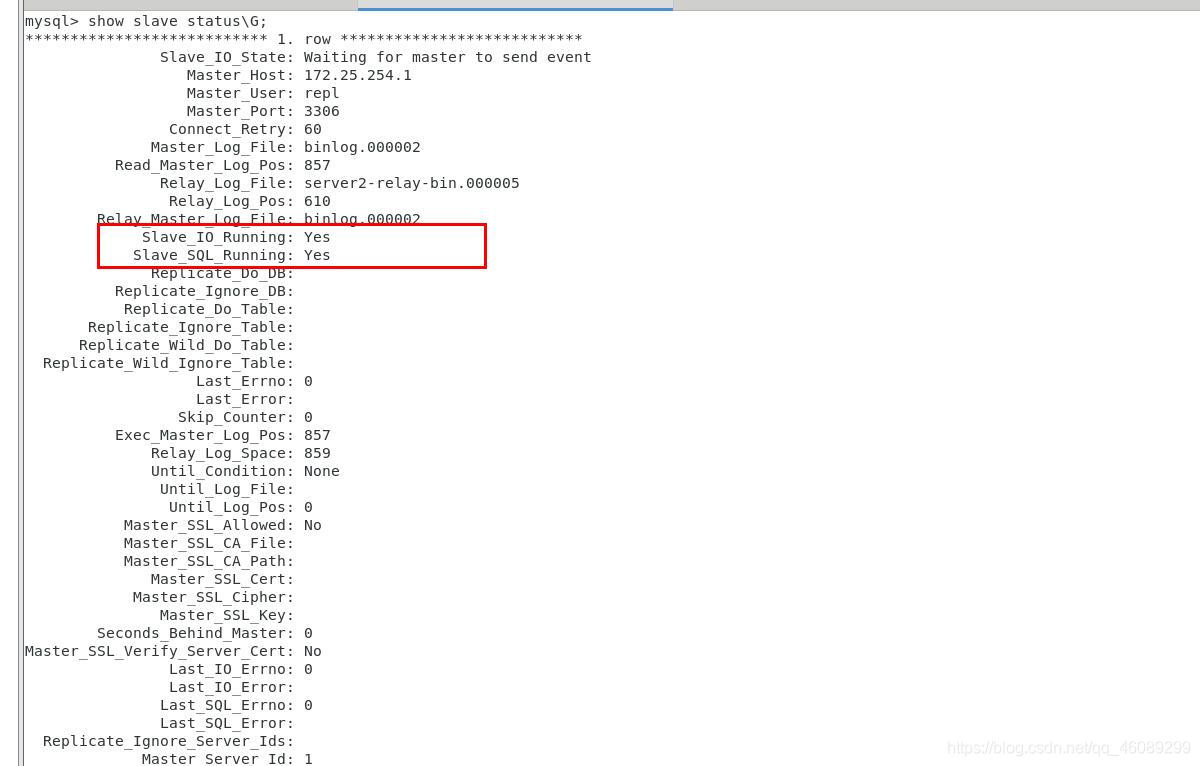
server3主机配置
更改server3上的配置文件
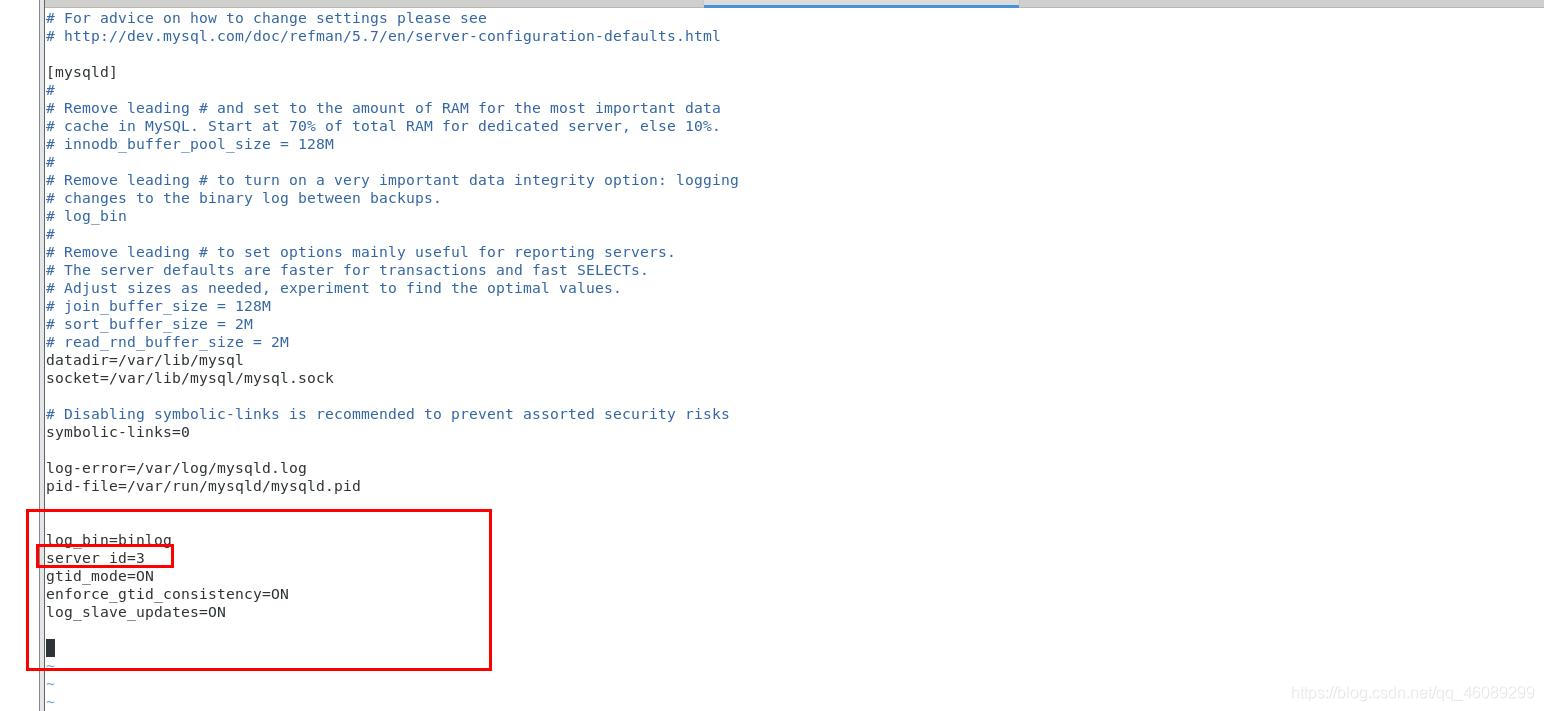
[root@server3 ~]# vim /etc/my.cnf
[root@server3 ~]# systemctl stop mysqld.service
[root@server3 ~]# systemctl start mysqld.service

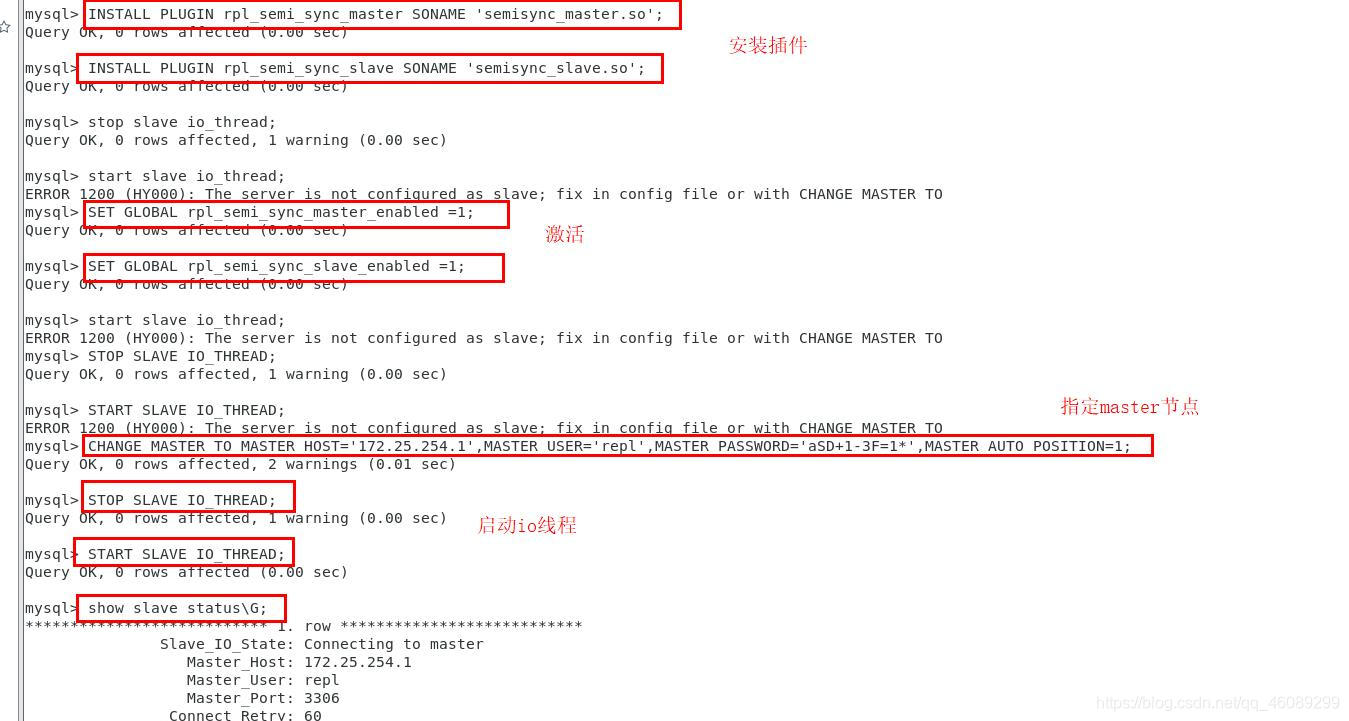
mysql> CHANGE MASTER TO MASTER_HOST='172.25.254.1',MASTER_USER='repl',MASTER_PASSWORD='aSD+1-3F=1*',MASTER_AUTO_POSITION=1;
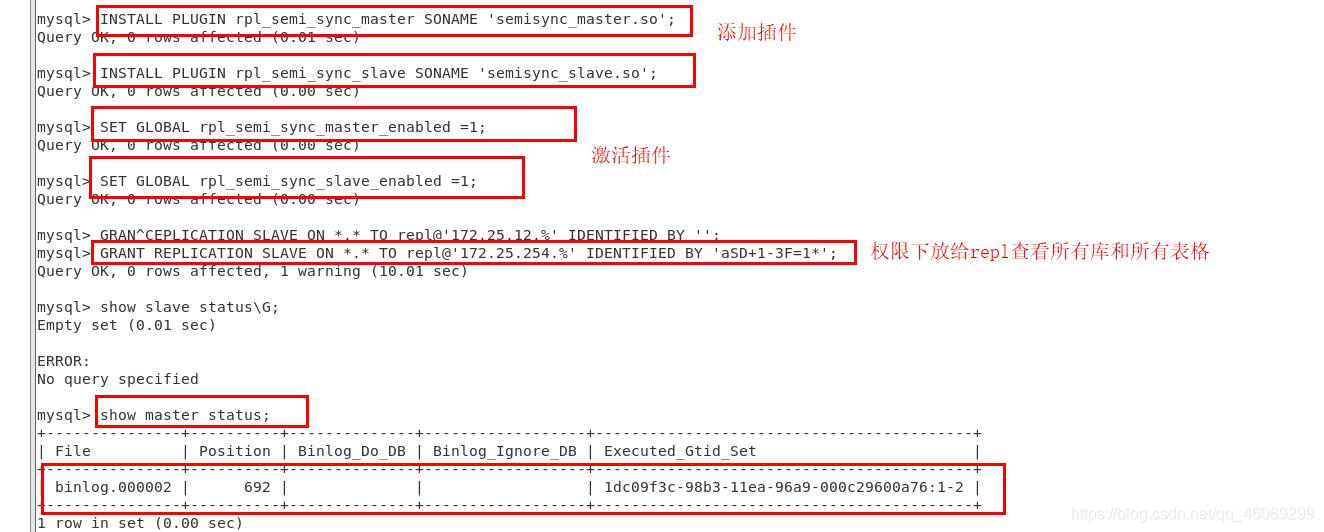
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
Query OK, 0 rows affected (0.00 sec)
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
Query OK, 0 rows affected (0.00 sec)
mysql> SET GLOBAL rpl_semi_sync_master_enabled =1;
Query OK, 0 rows affected (0.03 sec)
mysql> SET GLOBAL rpl_semi_sync_slave_enabled =1;
Query OK, 0 rows affected (0.00 sec)
mysql> STOP SLAVE IO_THREAD;
Query OK, 0 rows affected (0.00 sec)
mysql> START SLAVE IO_THREAD;
Query OK, 0 rows affected (0.00 sec)
mysql> start slave;

【知识点补充:测试半同步复制碰到的问题】
server1

解决方案
杀死sever1上mysql进程

再去server2上查看
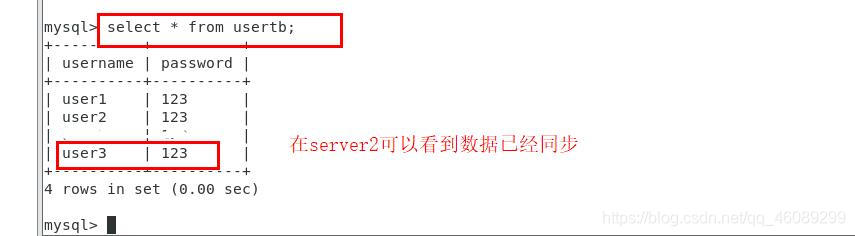
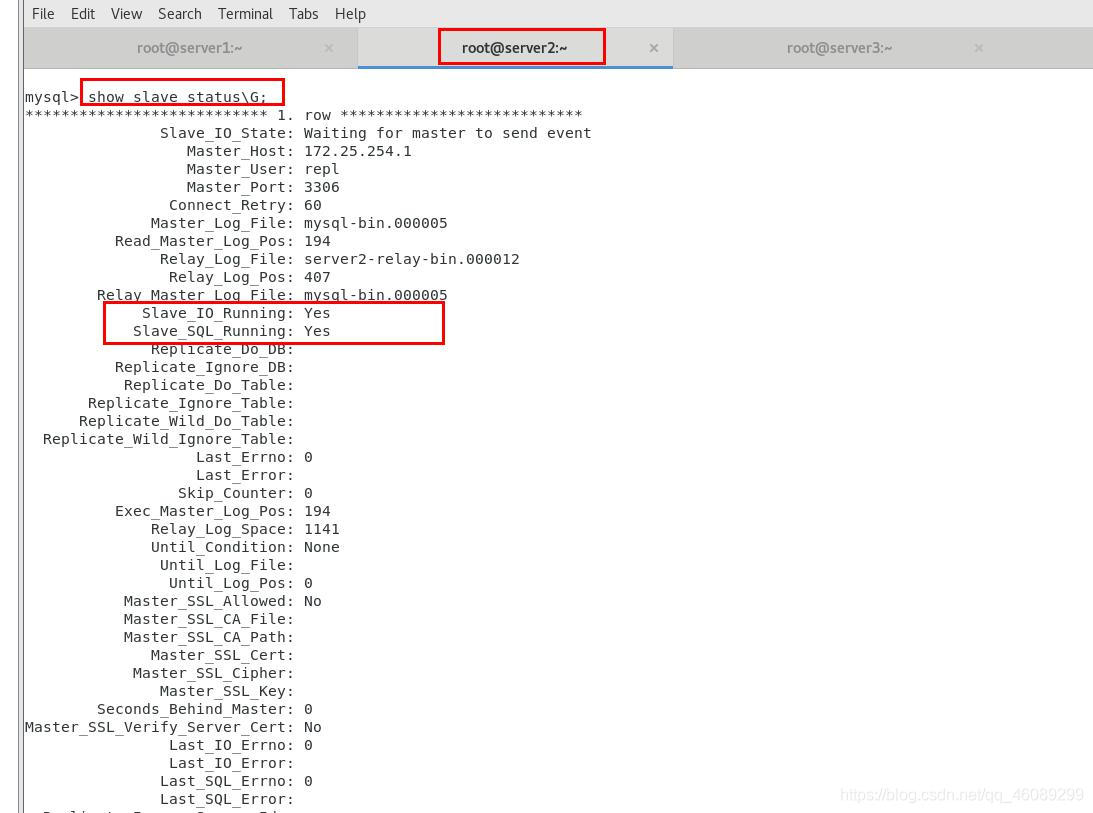
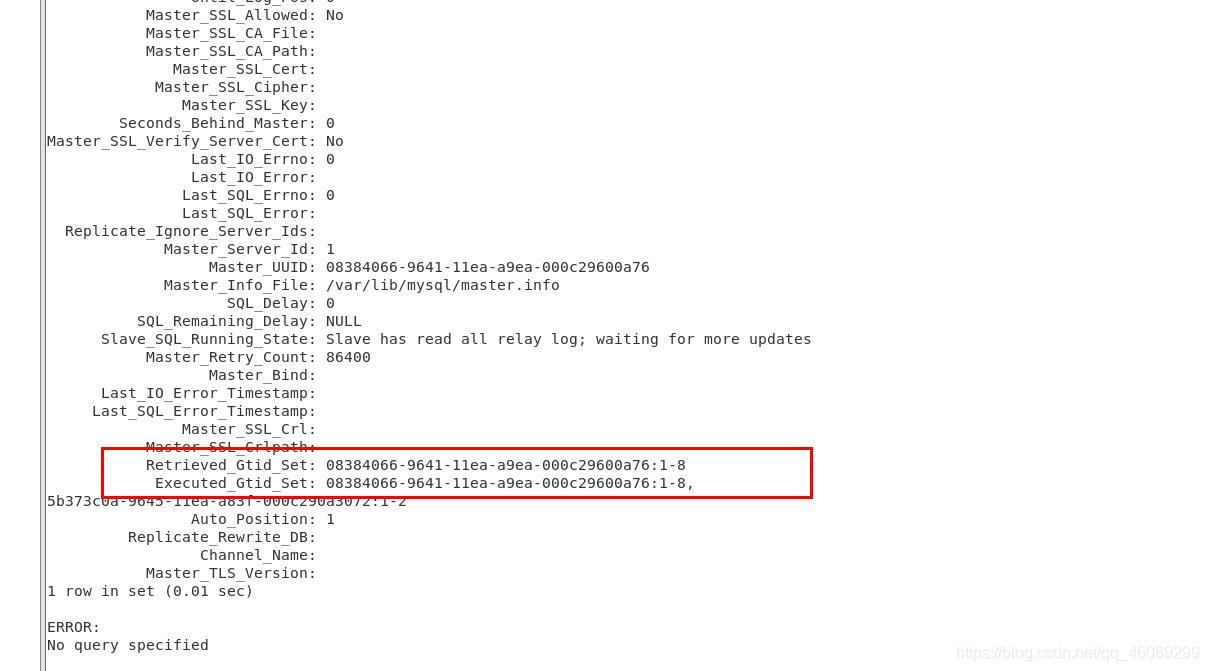
【当master节点的数据库已经存有数据如何同步到新建立的slave节点上的主机】
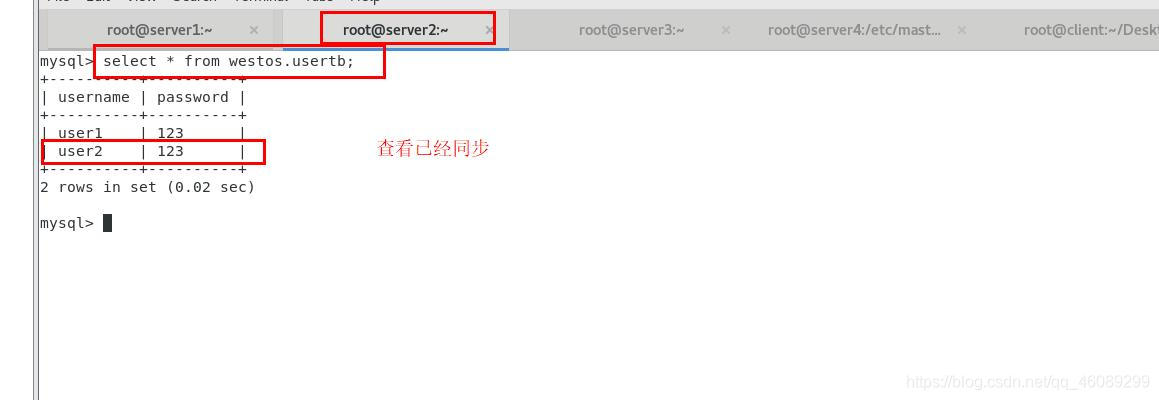
server3上查看数据是否同步
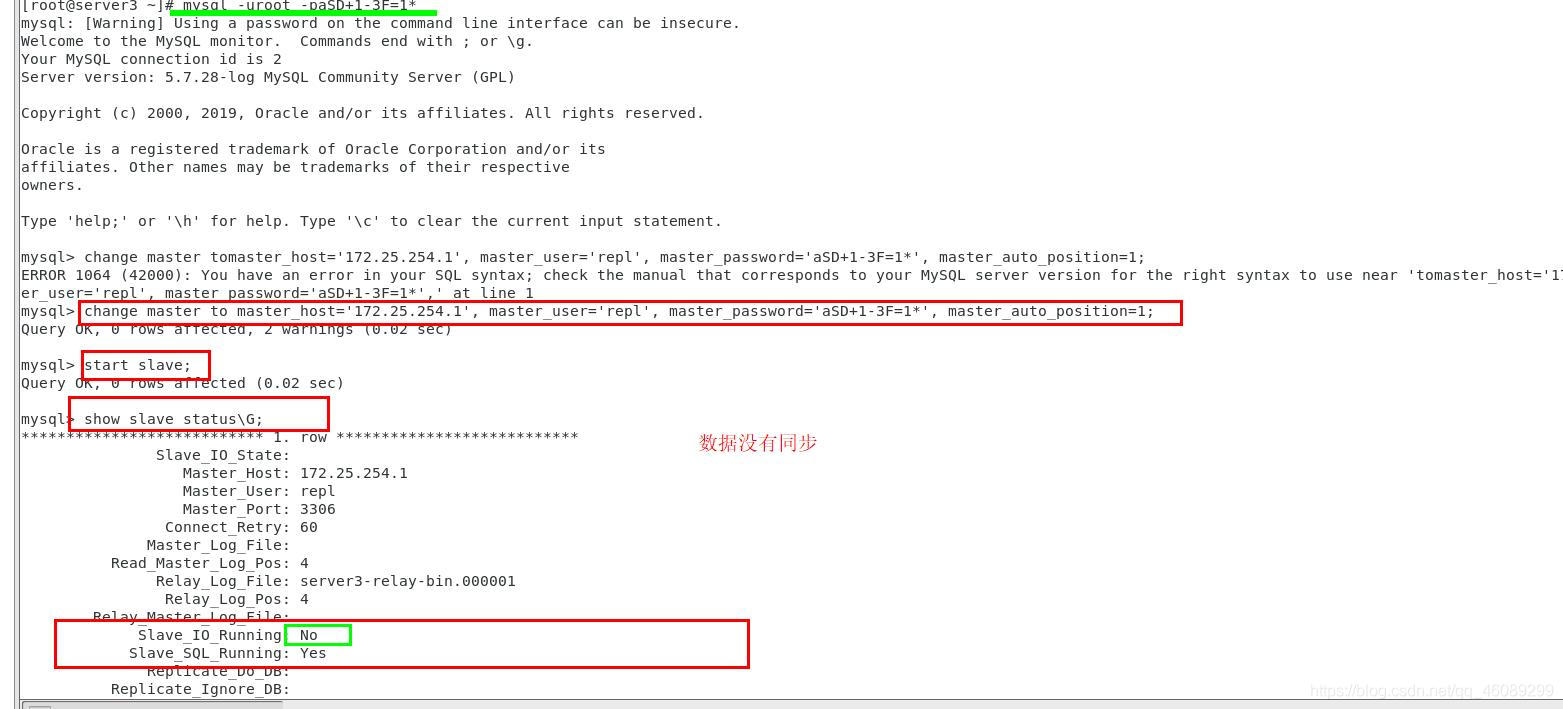
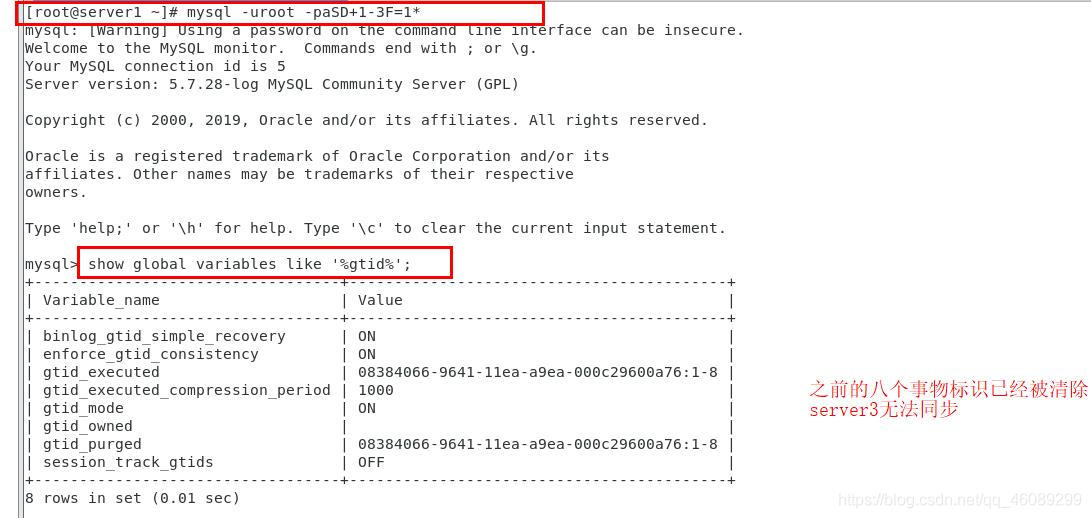
需要手动备份server1数据,同步到server3
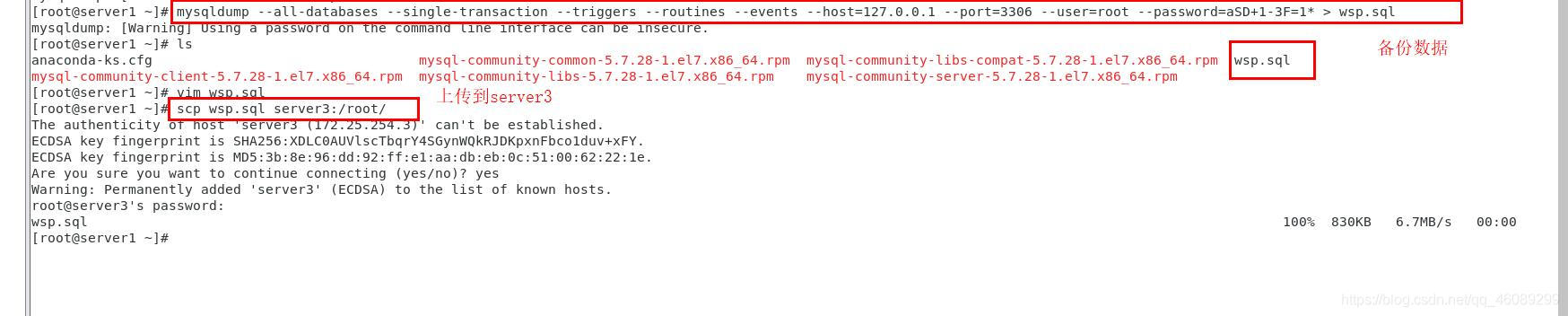
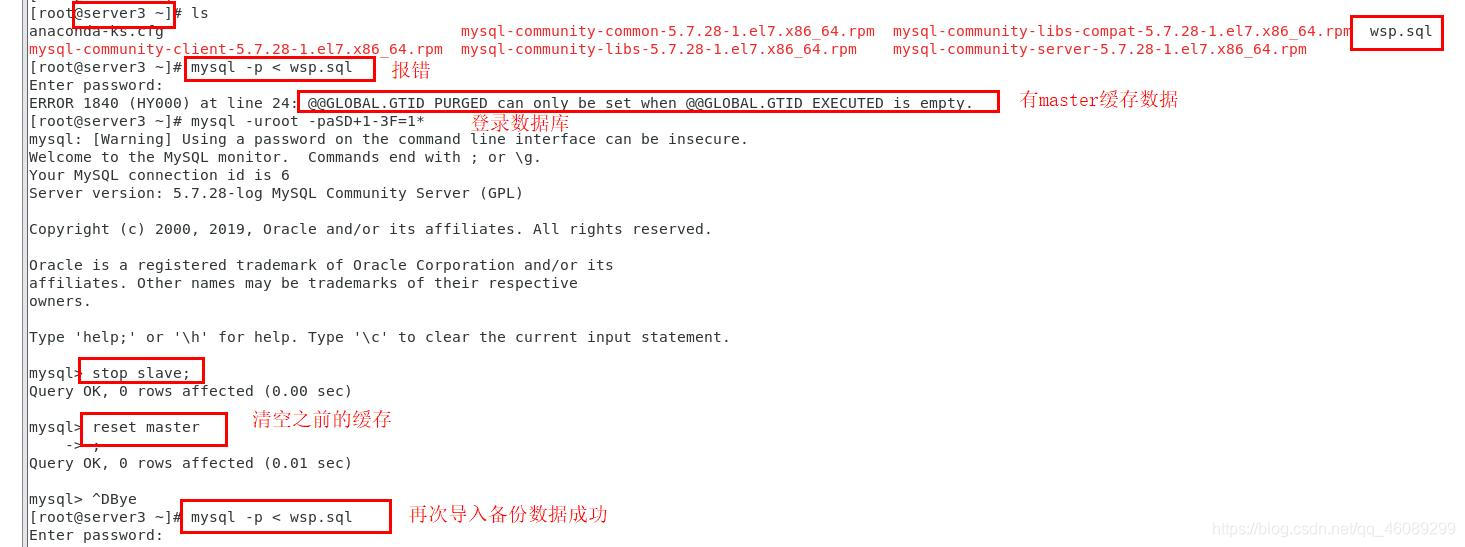
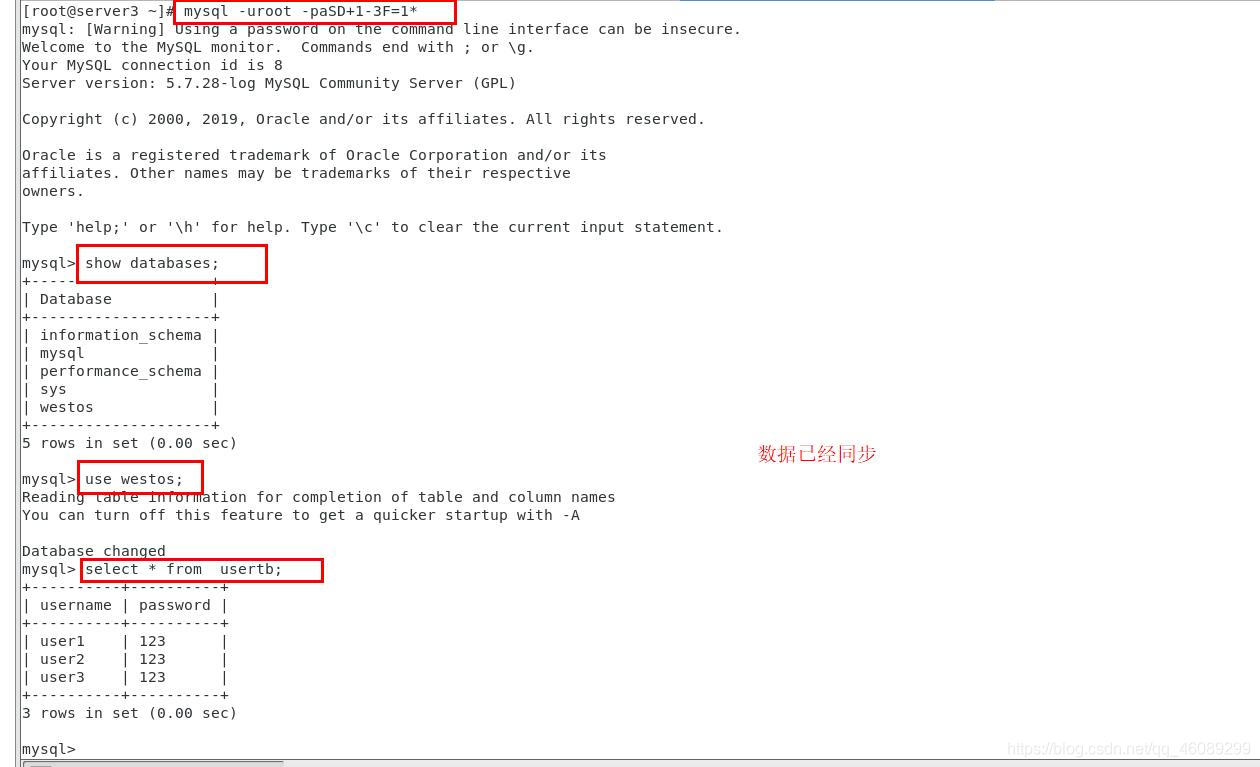
方便操作server1.2.3进行以下配置
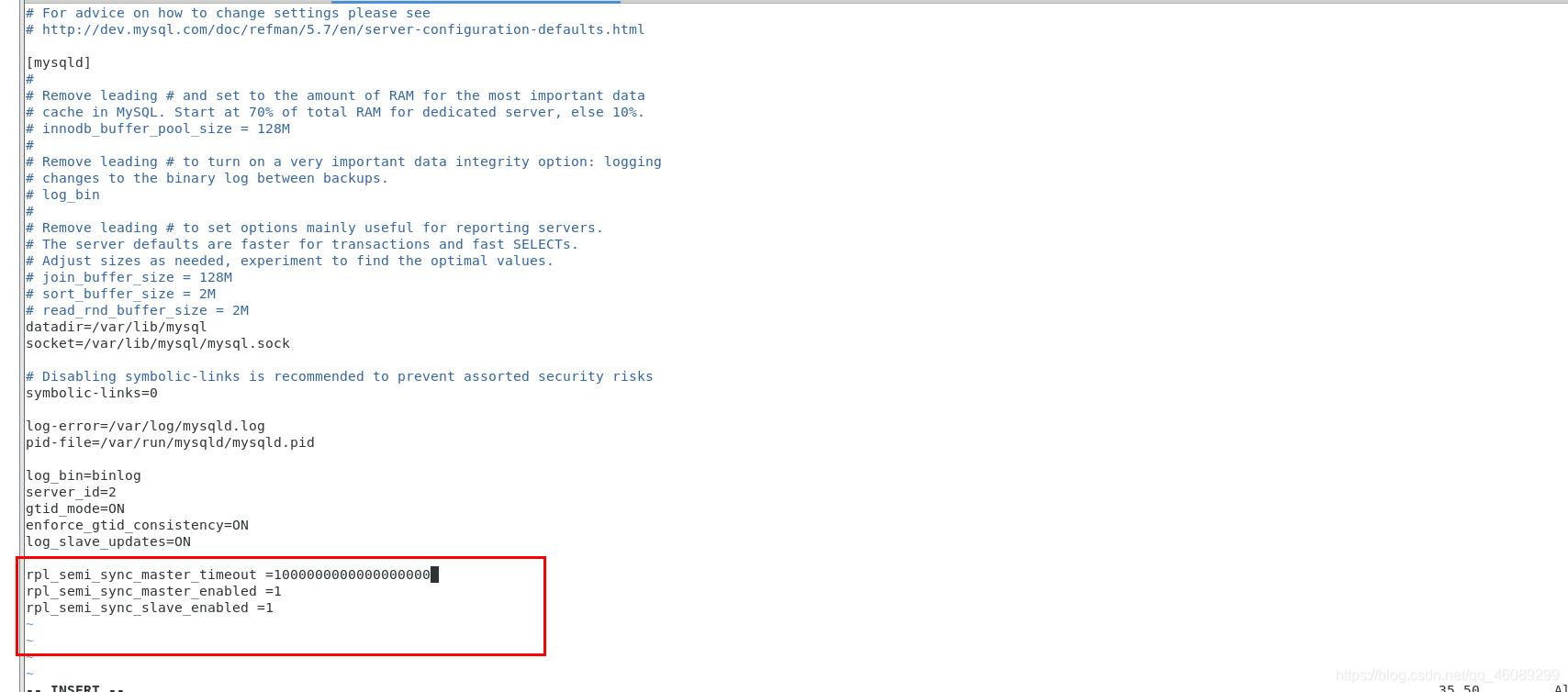
/etc/my.cnf
rpl_semi_sync_master_timeout =1000000000000000000 不要添加超时间会影响数据同步
rpl_semi_sync_master_enabled =1
rpl_semi_sync_slave_enabled =1
#更改完后要重启服务
systemctl stop mysqld.service
systemctl start mysqld.service
server4配置高可用
高可用都是奇数节点没有偶数节点,当其中一个master节点挂掉,奇数可以投票选择出新的master,偶数的话会出现相同的票数,所以不能使用偶数节点
先测试数据同步是否正常,此时已经取消了超时时间设置


server4上进行配置
获取软件包
[root@client Desktop]# ls
MHA-7
[root@client Desktop]# scp -r MHA-7/ server4:
root@server4's password:
mha4mysql-manager-0.58-0.el7.centos.noarch.rpm 100% 79KB 4.1MB/s 00:00
mha4mysql-manager-0.58.tar.gz 100% 91KB 38.7MB/s 00:00
mha4mysql-node-0.58-0.el7.centos.noarch.rpm 100% 35KB 24.4MB/s 00:00
perl-Config-Tiny-2.14-7.el7.noarch.rpm 100% 25KB 19.4MB/s 00:00
perl-Email-Date-Format-1.002-15.el7.noarch.rpm 100% 17KB 578.1KB/s 00:00
perl-Log-Dispatch-2.41-1.el7.1.noarch.rpm 100% 82KB 18.0MB/s 00:00
perl-Mail-Sender-0.8.23-1.el7.noarch.rpm 100% 59KB 3.3MB/s 00:00
perl-Mail-Sendmail-0.79-21.el7.noarch.rpm 100% 29KB 13.8MB/s 00:00
perl-MIME-Lite-3.030-1.el7.noarch.rpm 100% 96KB 31.8MB/s 00:00
perl-MIME-Types-1.38-2.el7.noarch.rpm 100% 38KB 8.8MB/s 00:00
perl-Parallel-ForkManager-1.18-2.el7.noarch.rpm 100% 28KB 10.1MB/s 00:00
[root@client Desktop]#
软件包全部安装在server4既是:manager管理者需要配置免密登录, 也是node节点
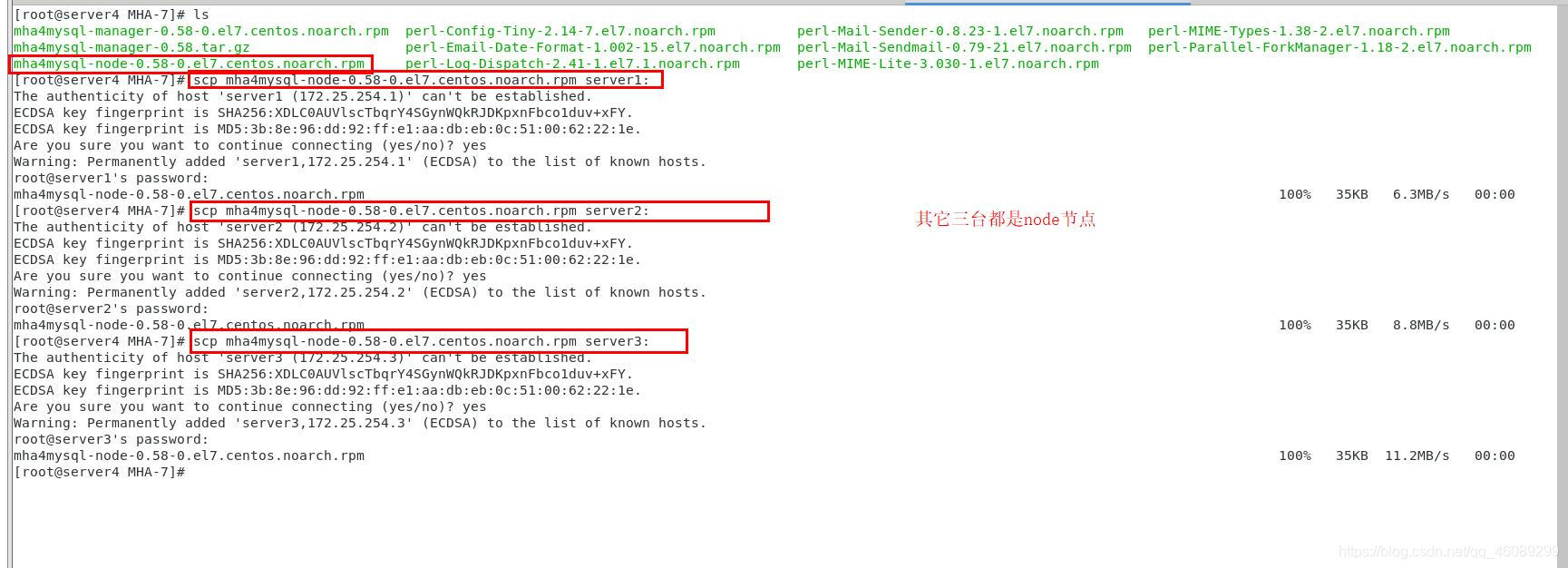
server1.2.3安装软件包

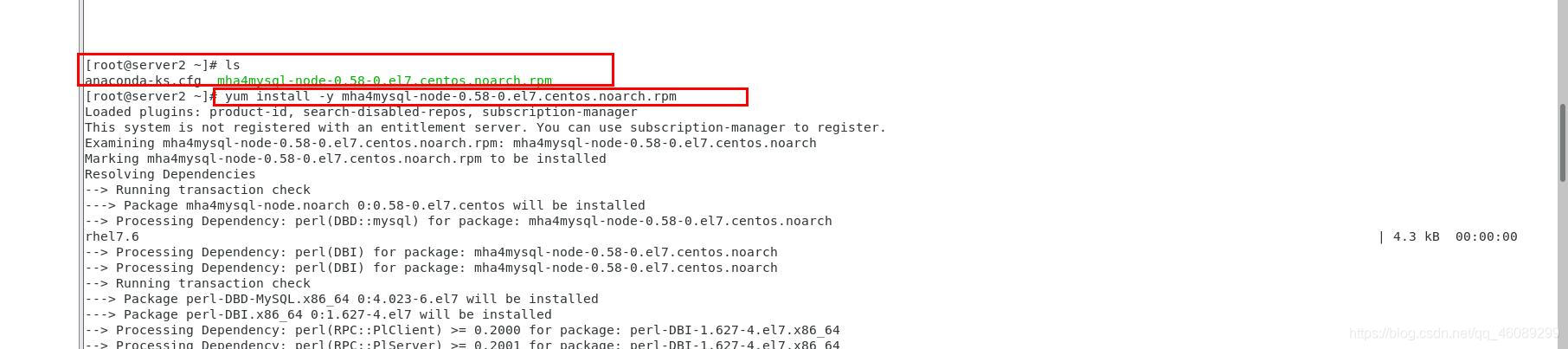
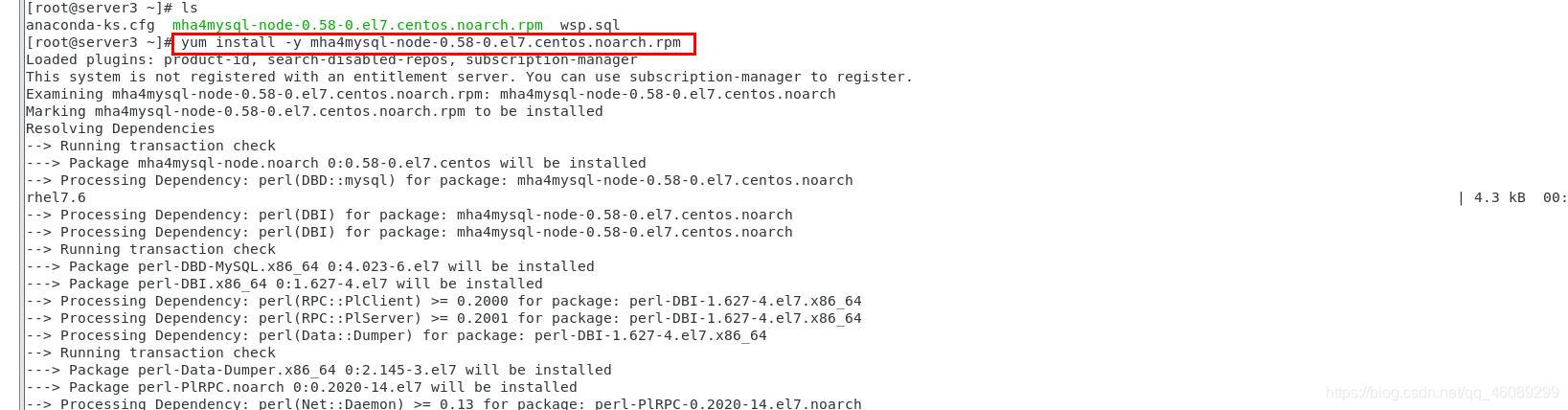
在server4上
管理节点创建一个目录,编辑配置文件
[root@server4 ~]# mkdir /etc/masterha
[root@server4 ~]# cd /etc/masterha/
[root@server4 masterha]# vim masterha.cnf
[root@server4 ~]# mkdir /etc/masterha
[root@server4 ~]# cd /etc/masterha/
[root@server4 masterha]# vim masterha.cnf
[server default]
manager_workdir=/etc/masterha 工作目录地址
manager_log=/var/log/masterha.log 日志存放地址
master_binlog_dir=/etc/masterha binlongd地址
password=aSD+1-3F=1* 密码
user=root 用户
ping_interval=1 间隔1s
remote_workdir=/tmp 数据存放目录
repl_password=aSD+1-3F=1* 用户密码
repl_user=repl 用户repl用户复制数据的
ssh_user=root ssh登录用户
以下是指定工作主机
[server1] 指定变量名称。这里不代表主机,可以随意设置
hostname=172.25.254.1 指定第一台主机ip
port=3306 端口号
[server2]
hostname=172.25.254.2
port=3306
candidate_master=1 指定此台主机可以成为master一员
check_repl_delay=0 MHA忽略复制延迟选择一个新master
[server3]
hostname=172.25.254.3
port=3306
no_master=1 不能成为master节点
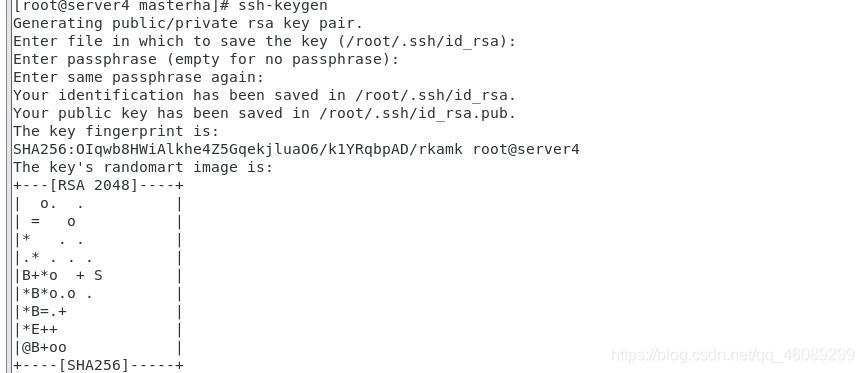
接下来做免密登录使四台虚拟机都能相互免密登录
生成秘钥
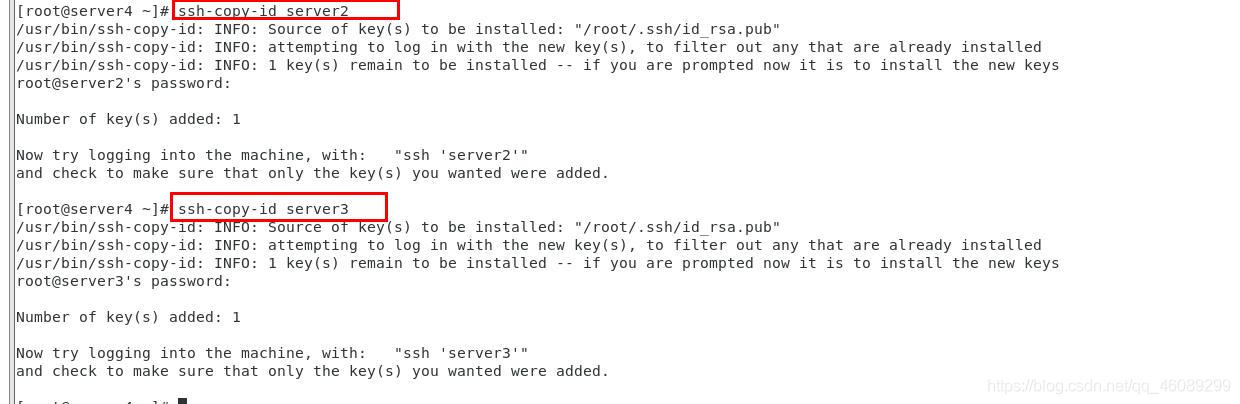
上传公钥

测试免密登陆
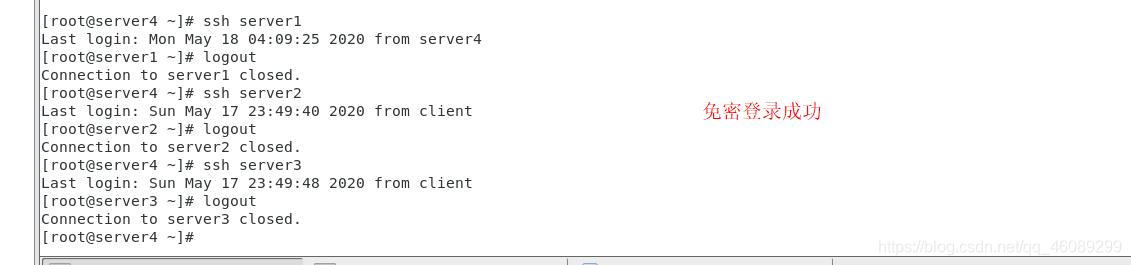
公钥私钥全部上传到其他主机

测试免密登陆
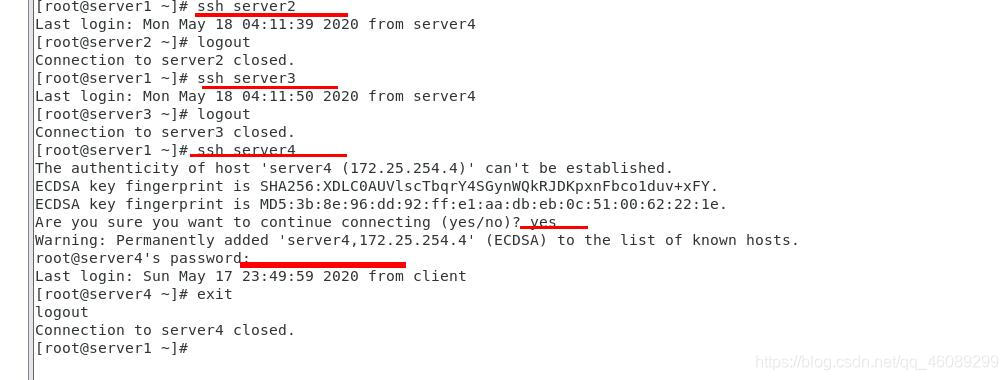
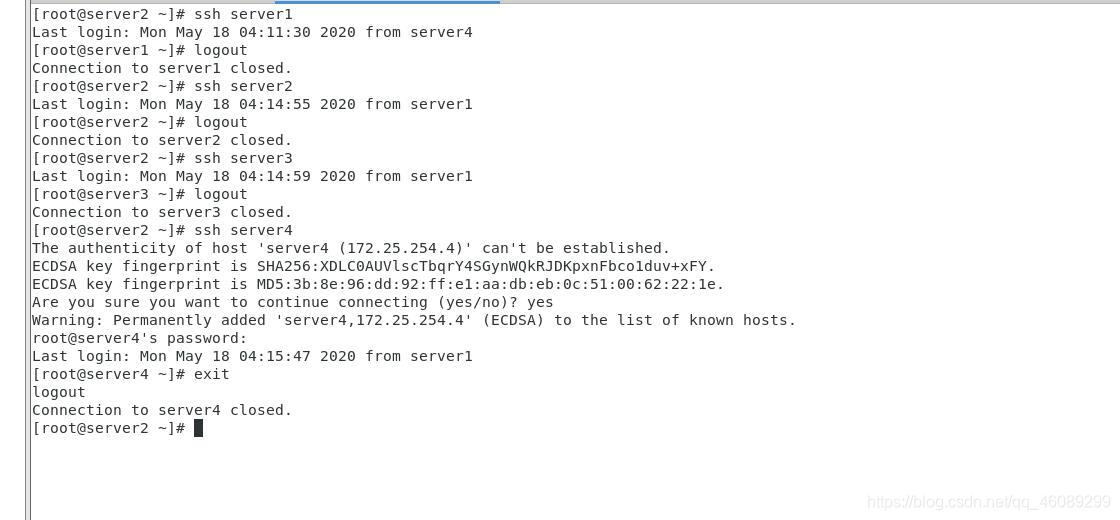
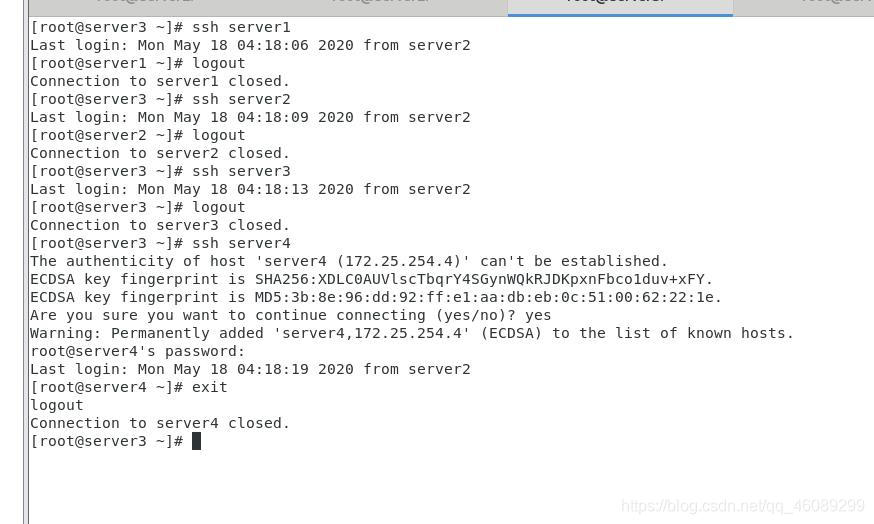
在server4检测ssh连接
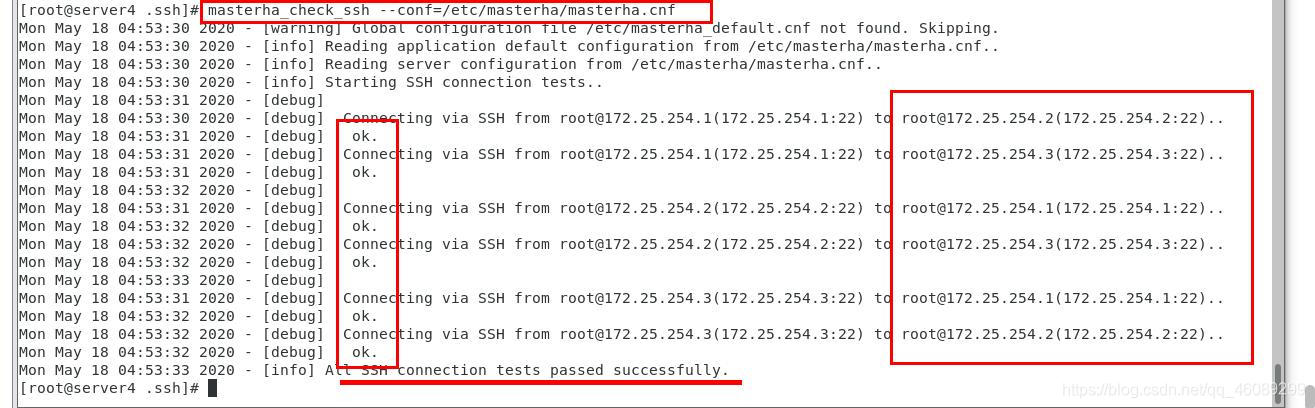
在server4检测数据同步
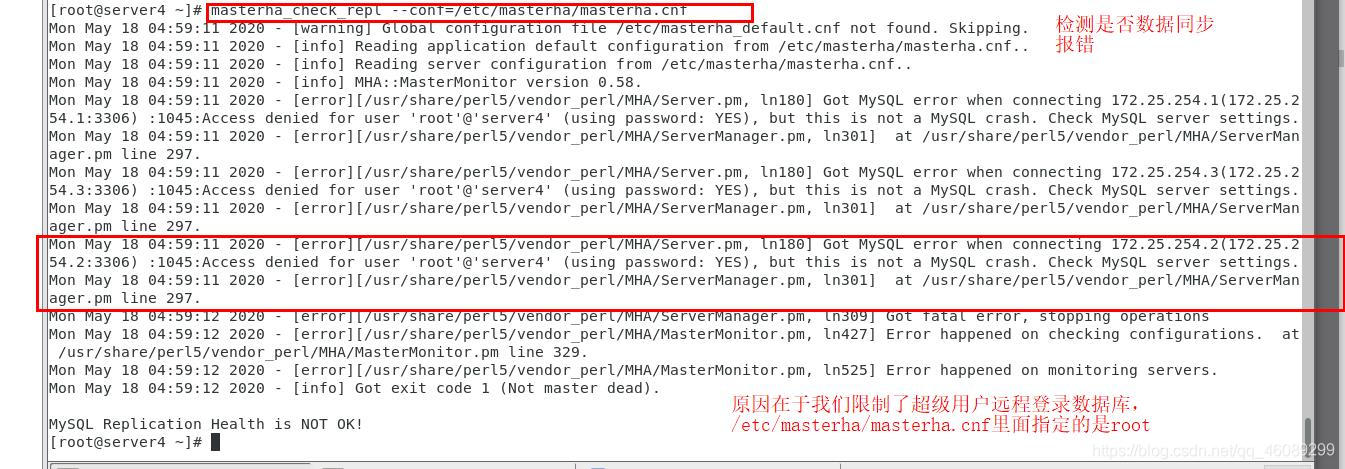
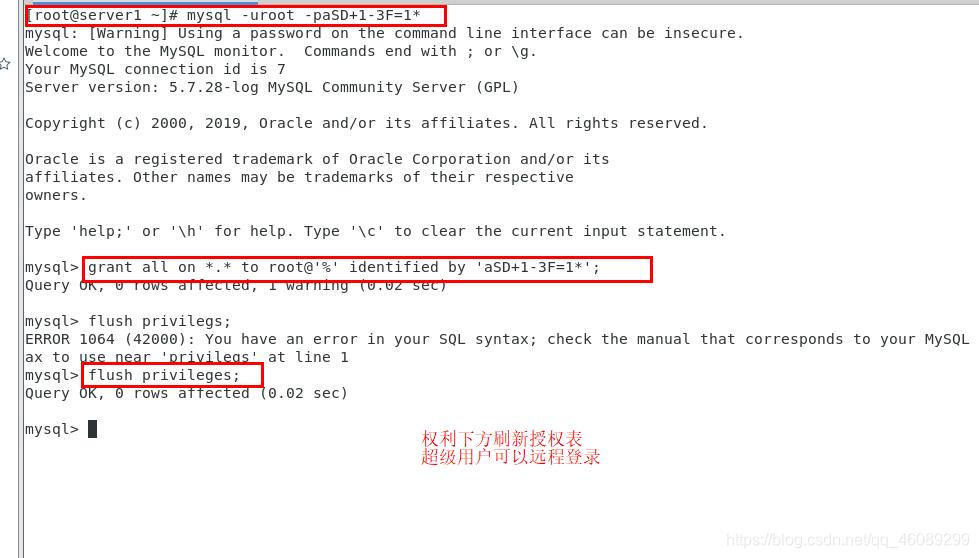
解决报错
在server1
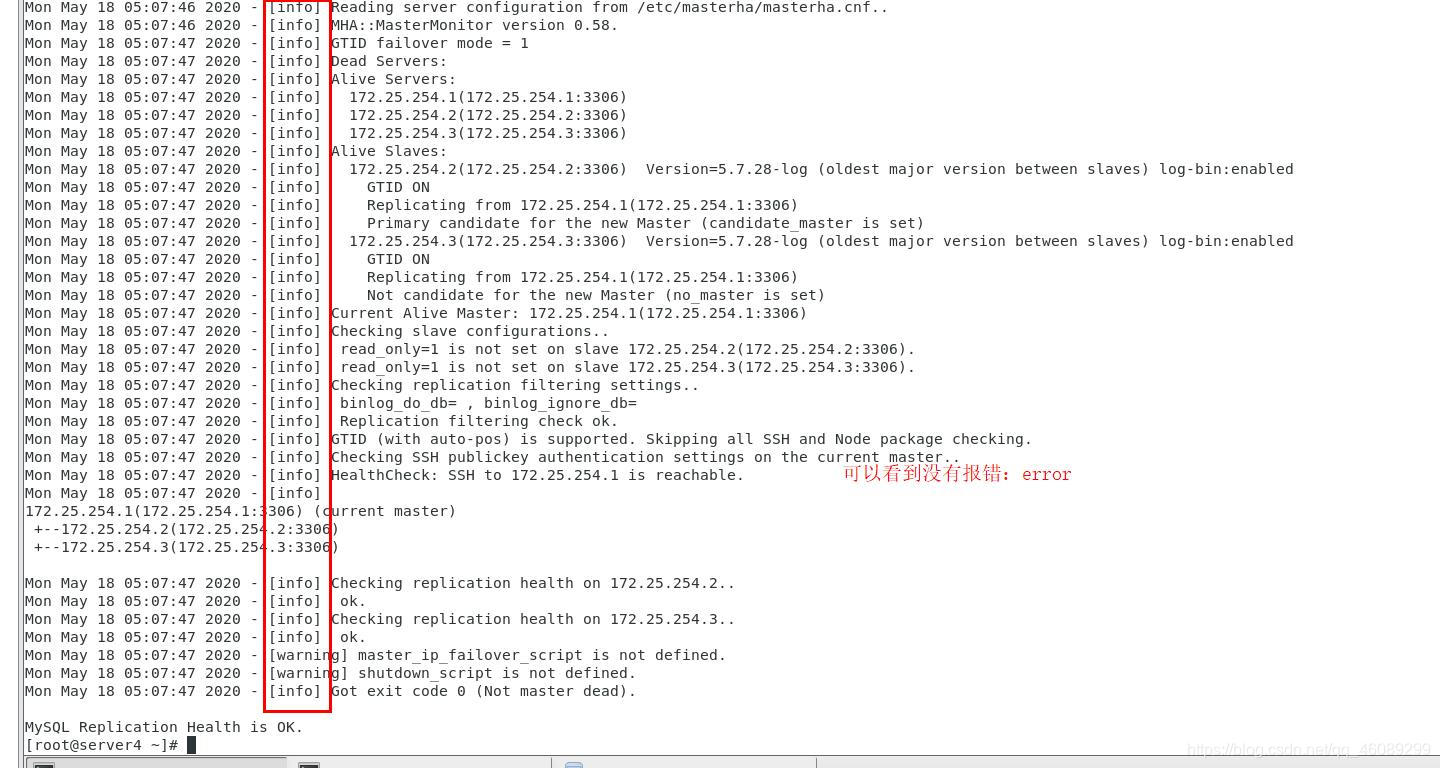
在server4上再次测试检测
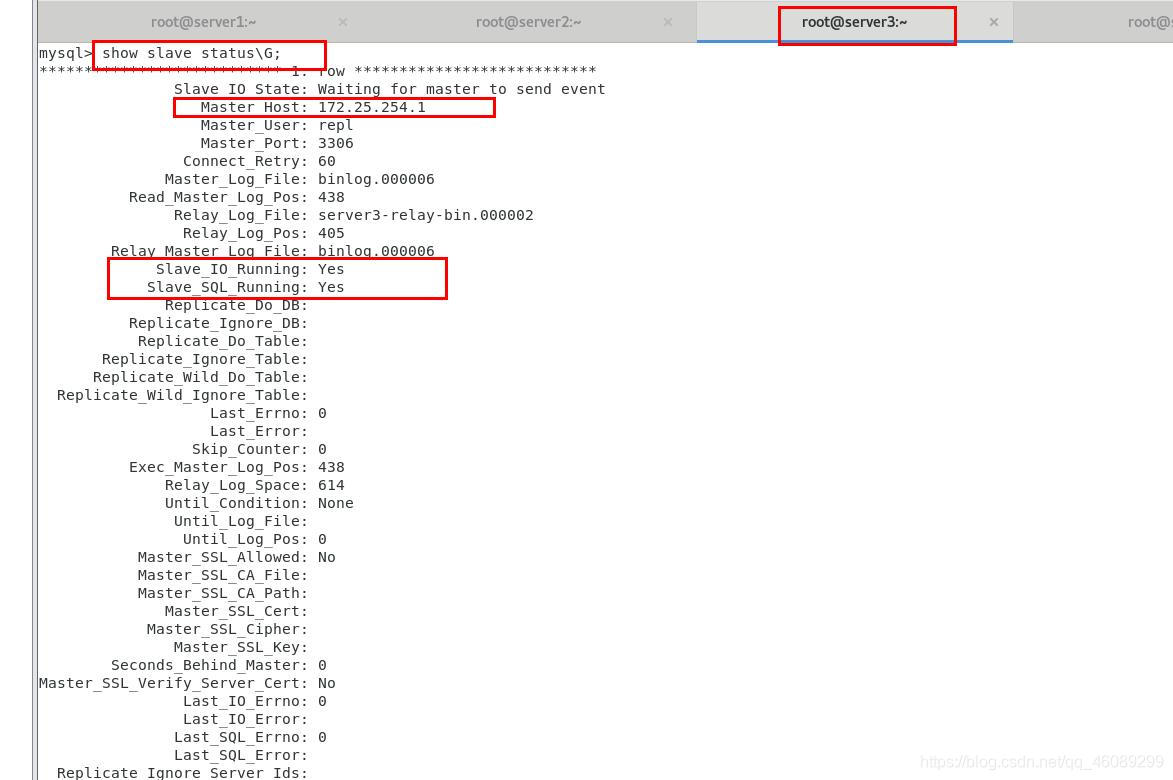
[root@server4 ~]# masterha_check_repl --conf=/etc/masterha/masterha.cnf
手动操作当其中一个master坏了选举出新的master
挂掉server1应该选择server2当选新的master,因为配置文件写的是只能是server2,server3不能当选master
[root@server4 masterha]# pwd
/etc/masterha
[root@server4 masterha]# vim masterha.cnf
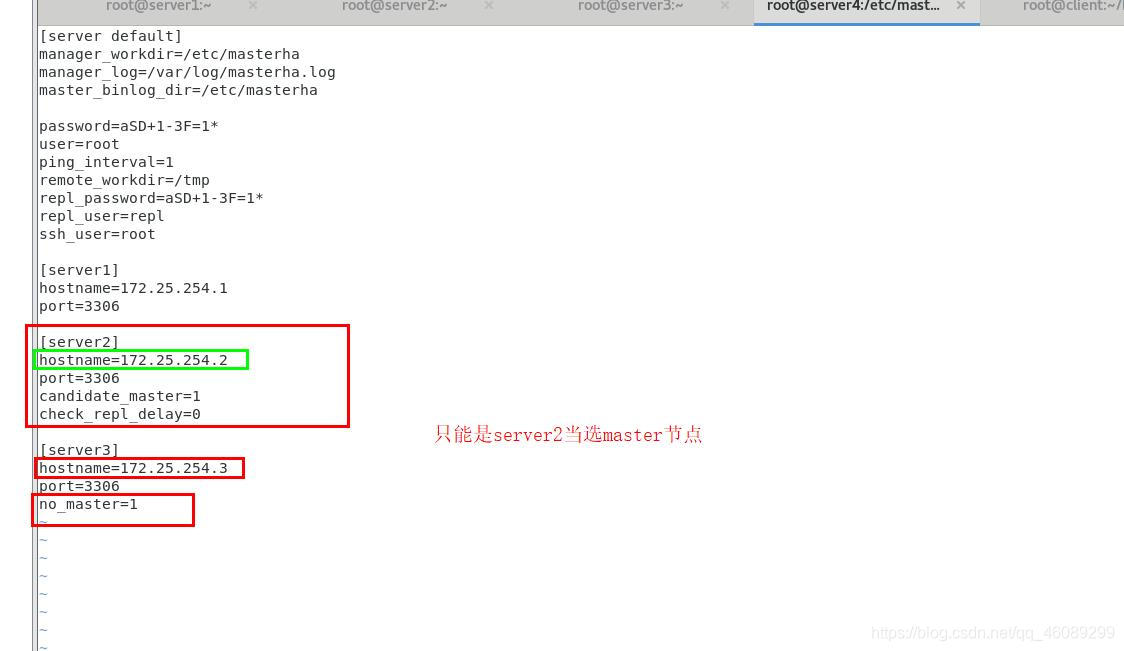
挂掉一台测试
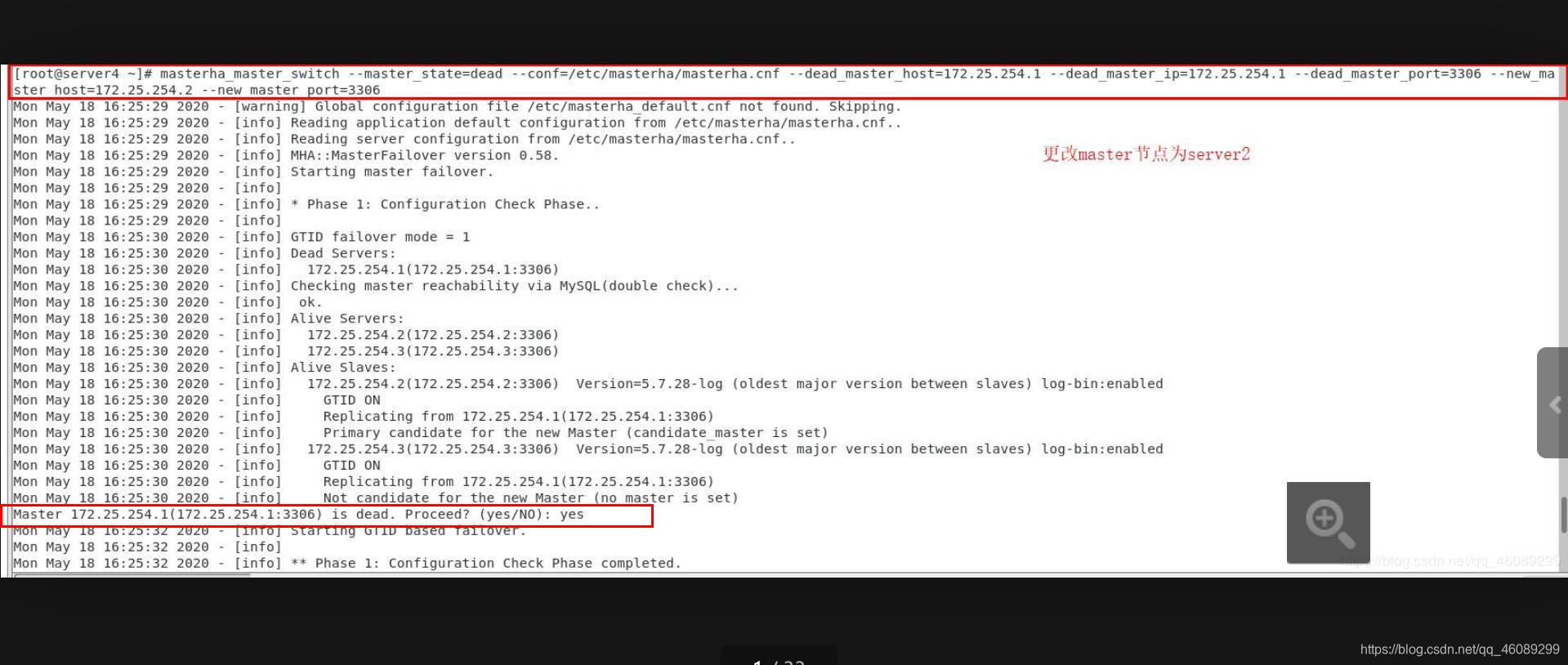
[root@server4 ~]# masterha_master_switch
--master_state=dead
--conf=/etc/masterha/masterha.cnf
--dead_master_host=172.25.254.1
--dead_master_ip=172.25.254.1
--dead_master_port=3306
--new_master_host=172.25.254.2
--new_master_port=3306

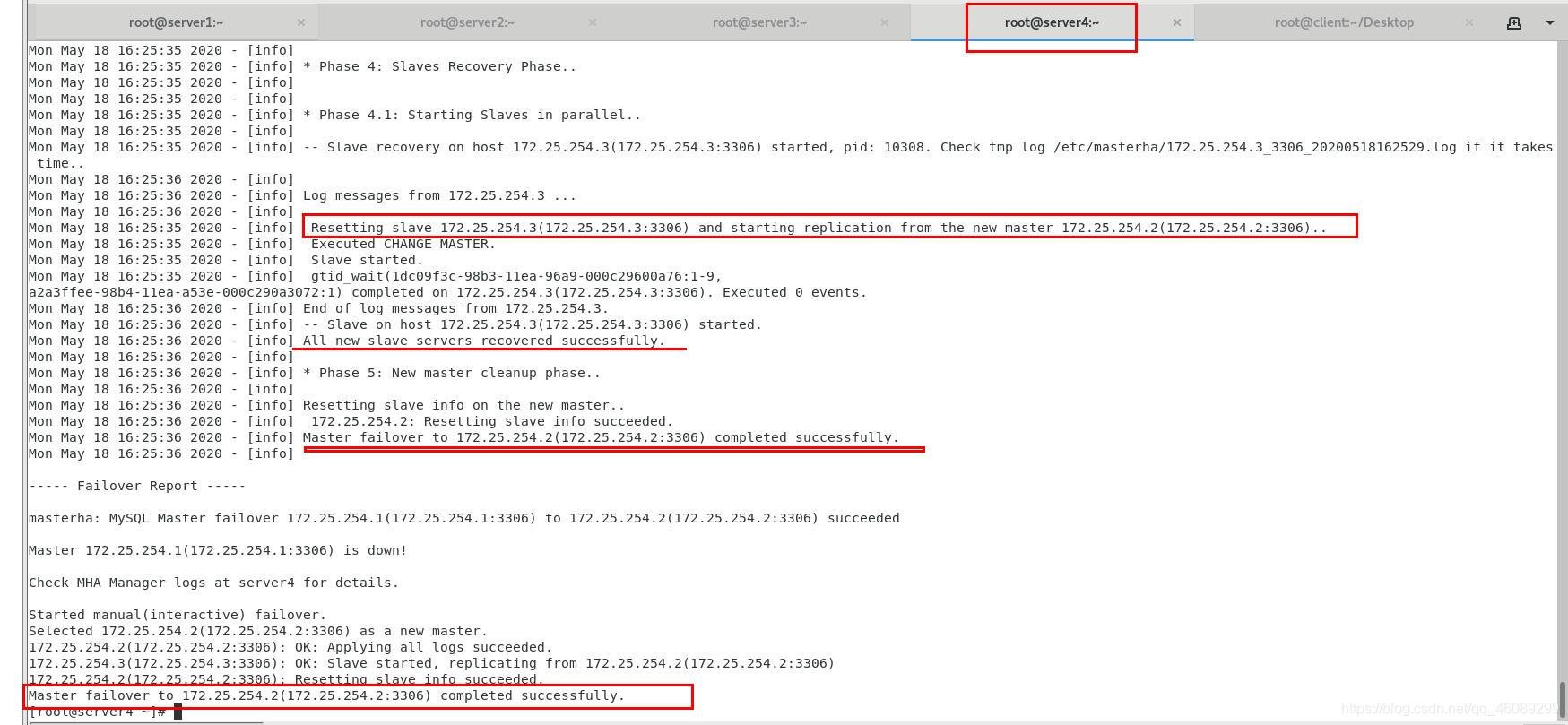 检查新更改的master节点状态
检查新更改的master节点状态
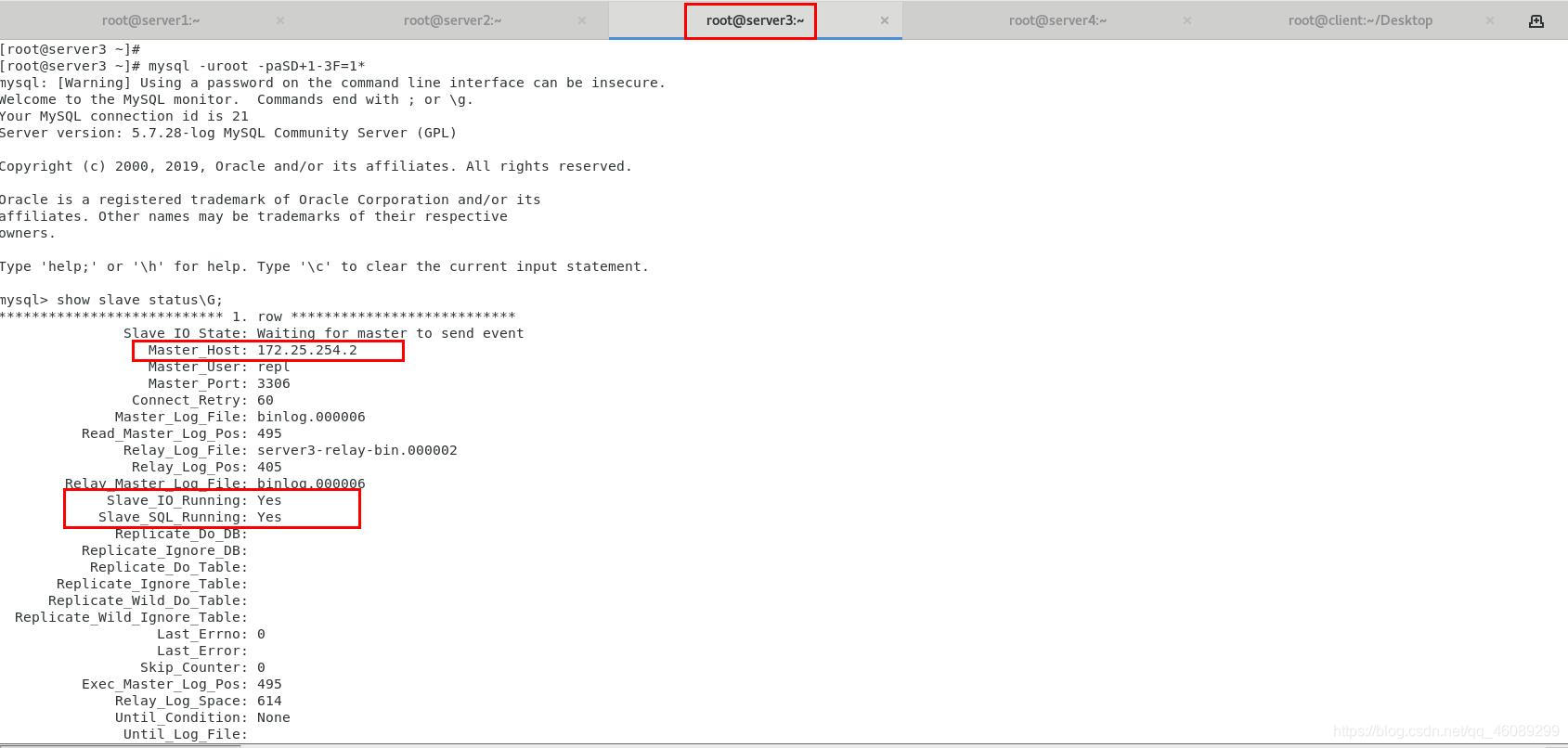
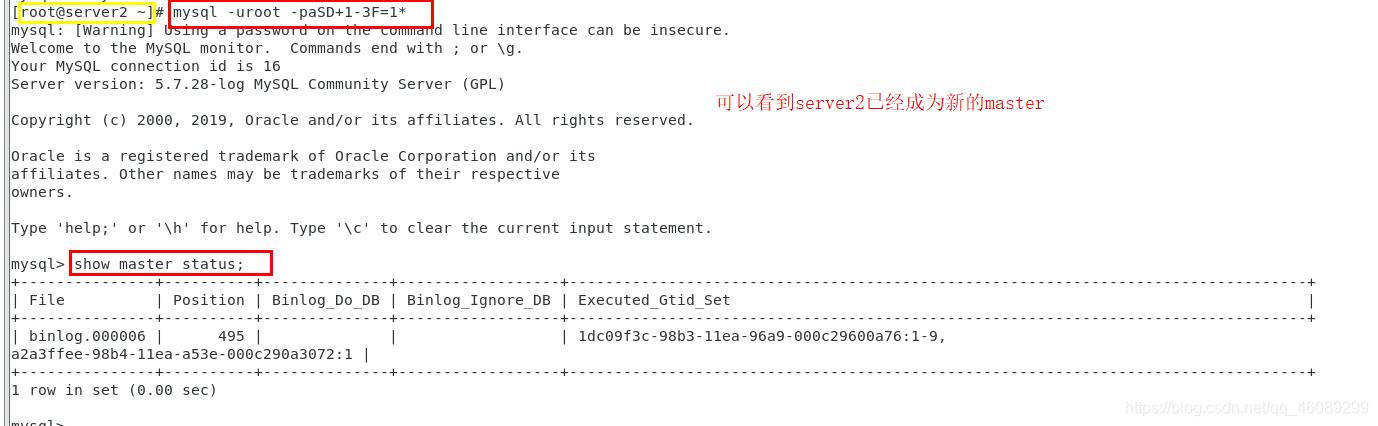
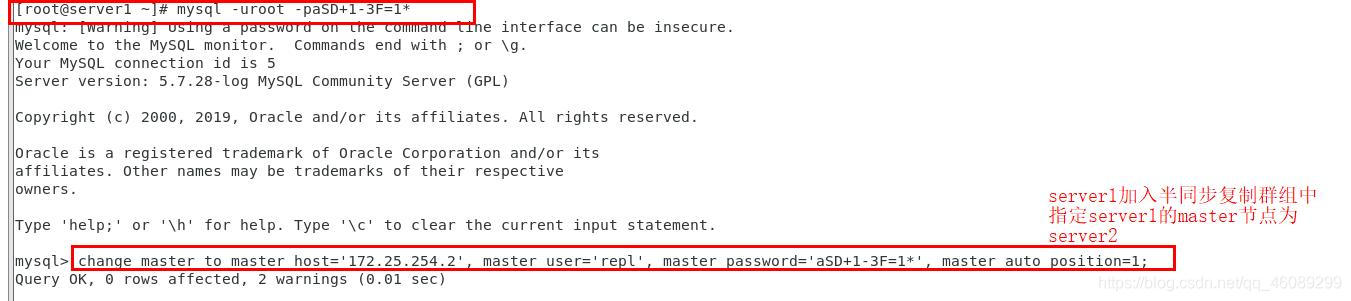
以上为手动关闭数据库进行master节点切换,接着配置在线切换master节点(不关闭master节点的数据库)

[root@server4 ~]# ll /etc/masterha/
total 4
-rw-r--r-- 1 root root 415 May 18 04:53 masterha.cnf
-rw-r--r-- 1 root root 0 May 18 16:25 masterha.failover.complete
[root@server4 ~]# rm -rf /etc/masterha/masterha.failover.complete 删除此文件
[root@server4 ~]# ll /etc/masterha/
total 4
-rw-r--r-- 1 root root 415 May 18 04:53 masterha.cnf
[root@server4 ~]# masterha_master_switch
--conf=/etc/masterha/masterha.cnf
--master_state=alive
--new_master_host=172.25.254.1
--new_master_port=3306
--orig_master_is_new_slave
--running_updates_limit=10000
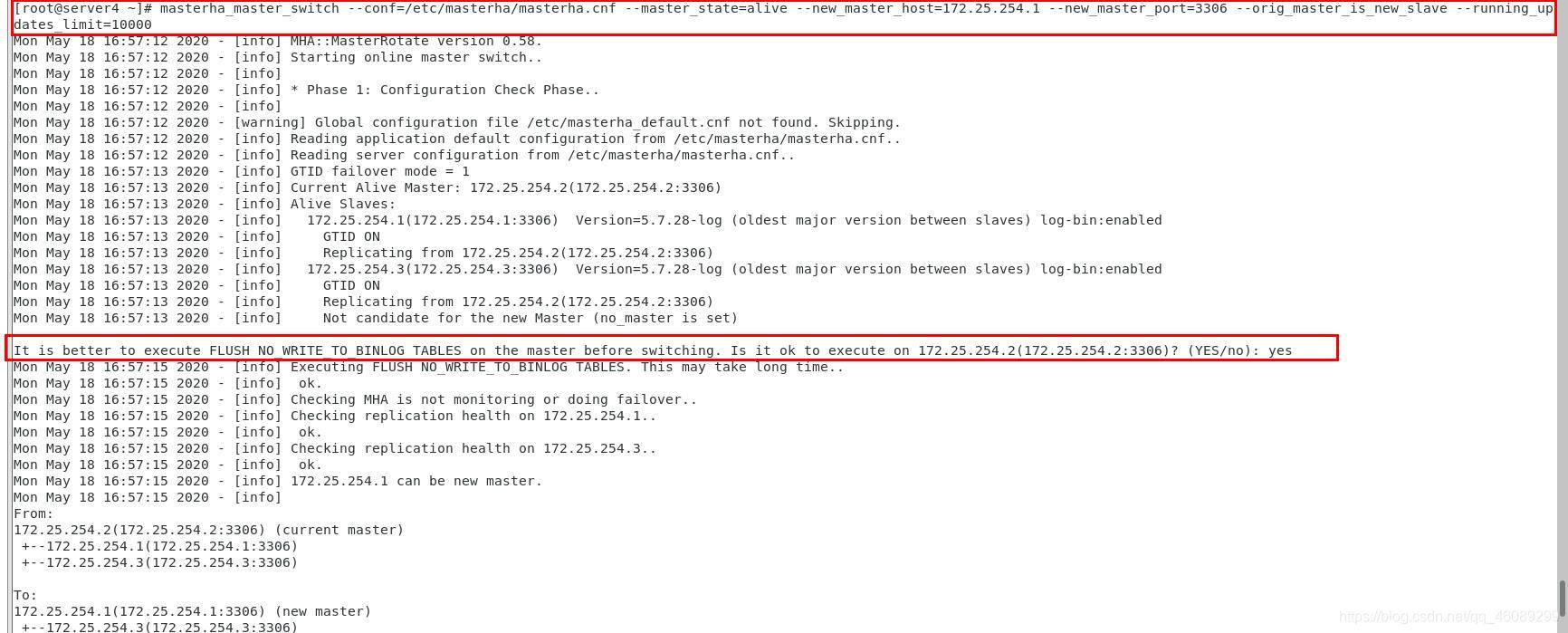
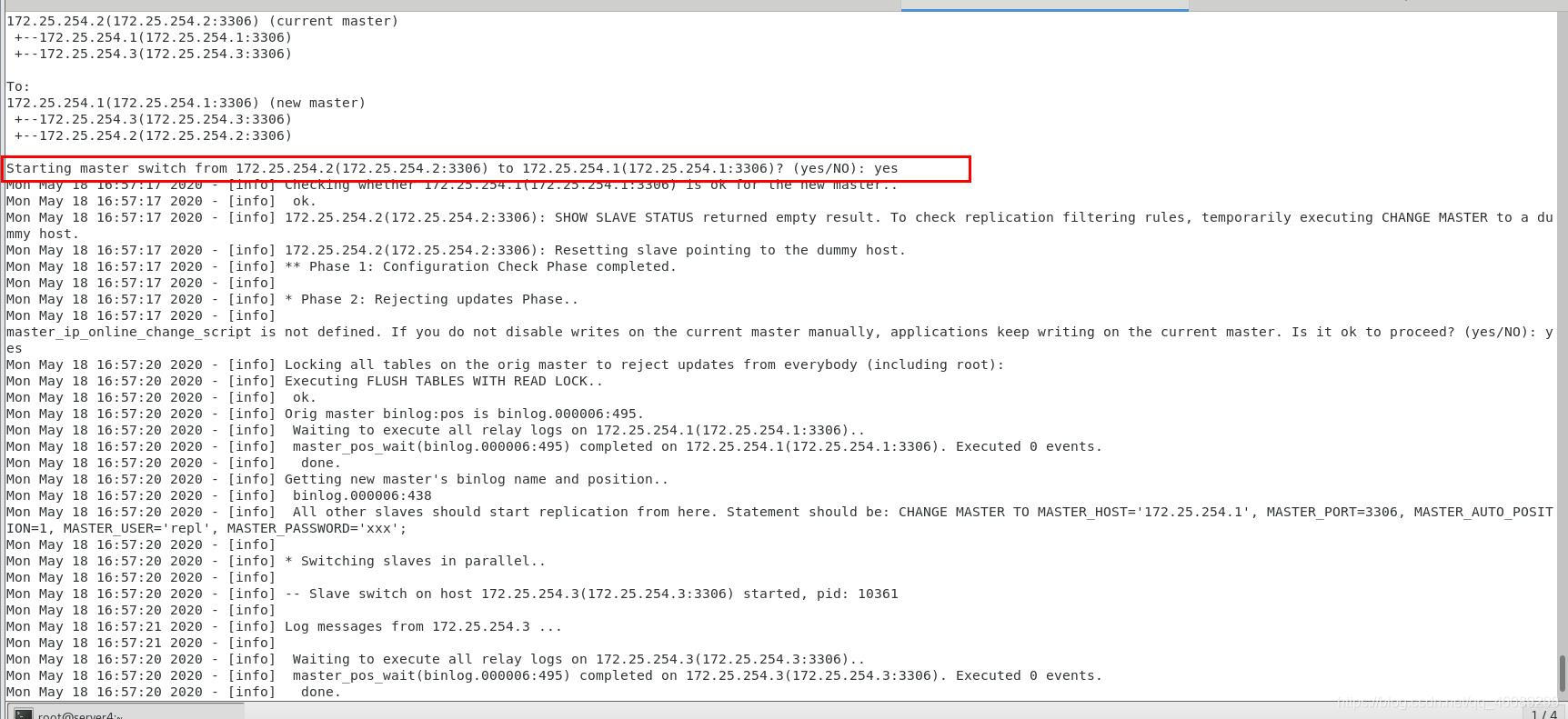
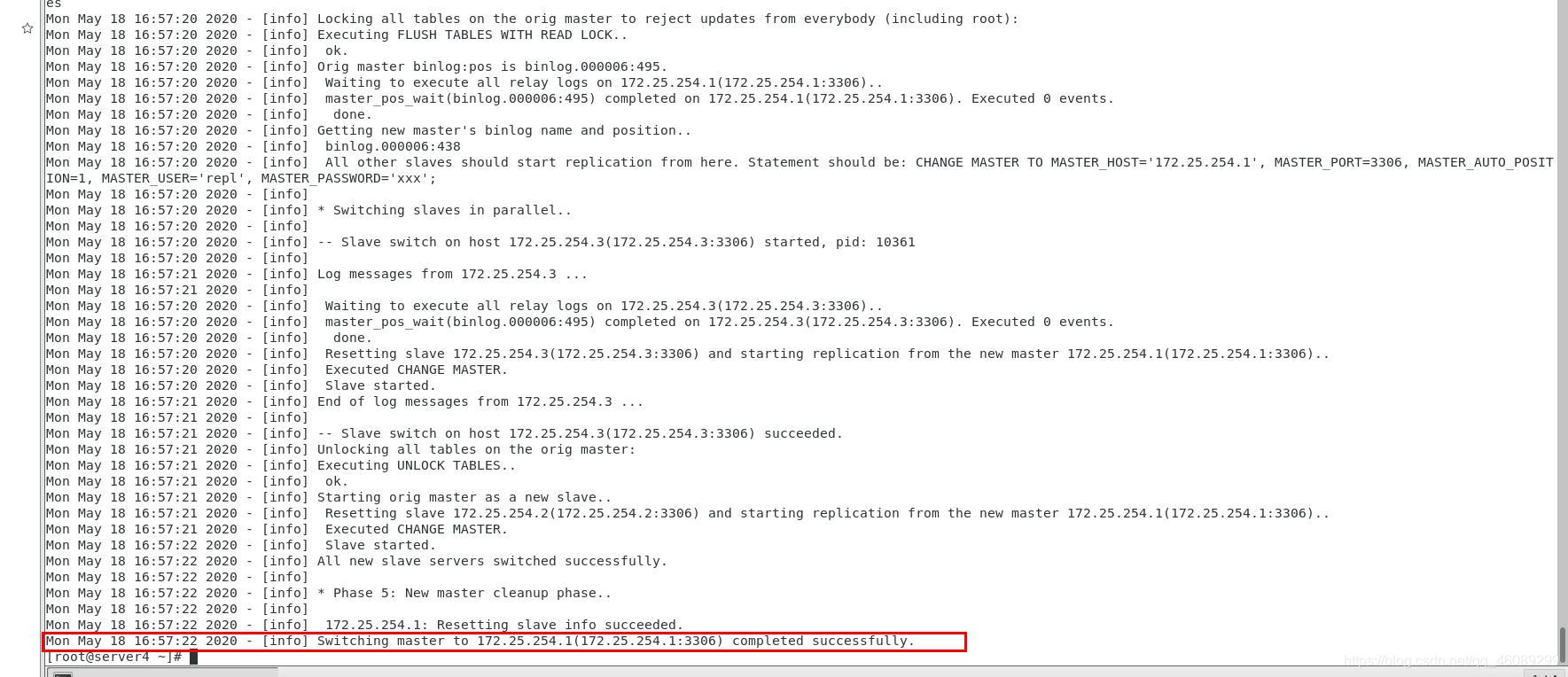
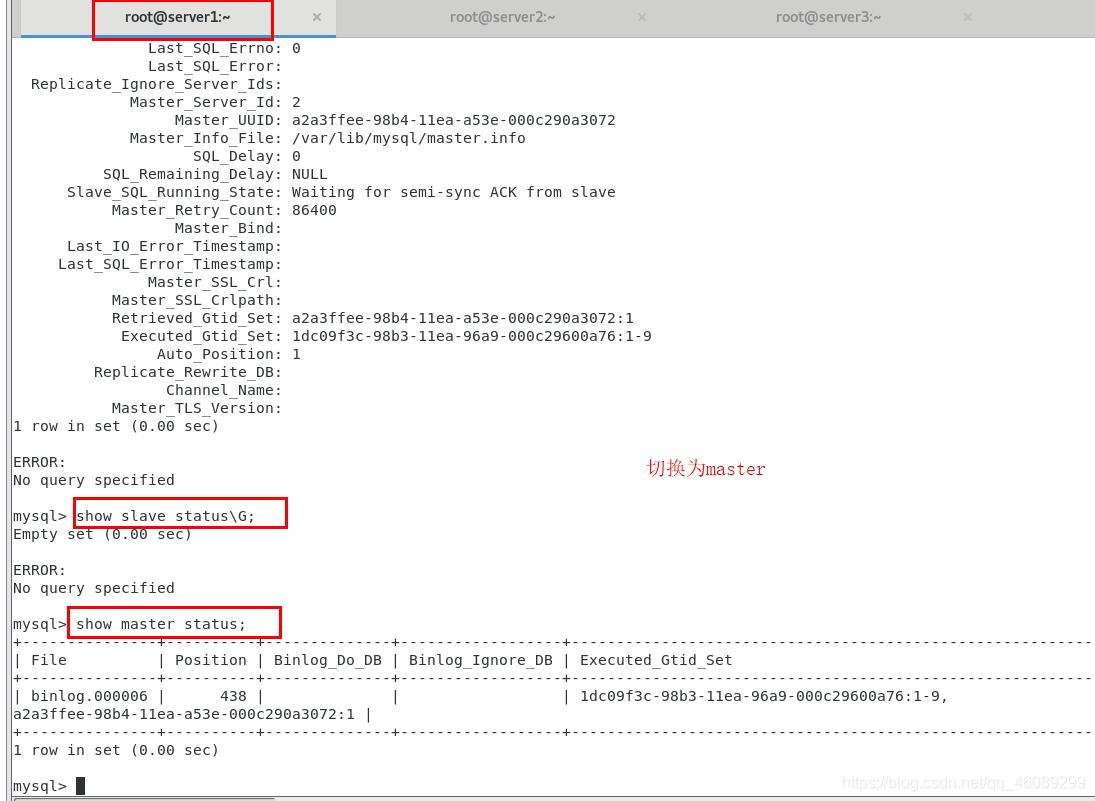
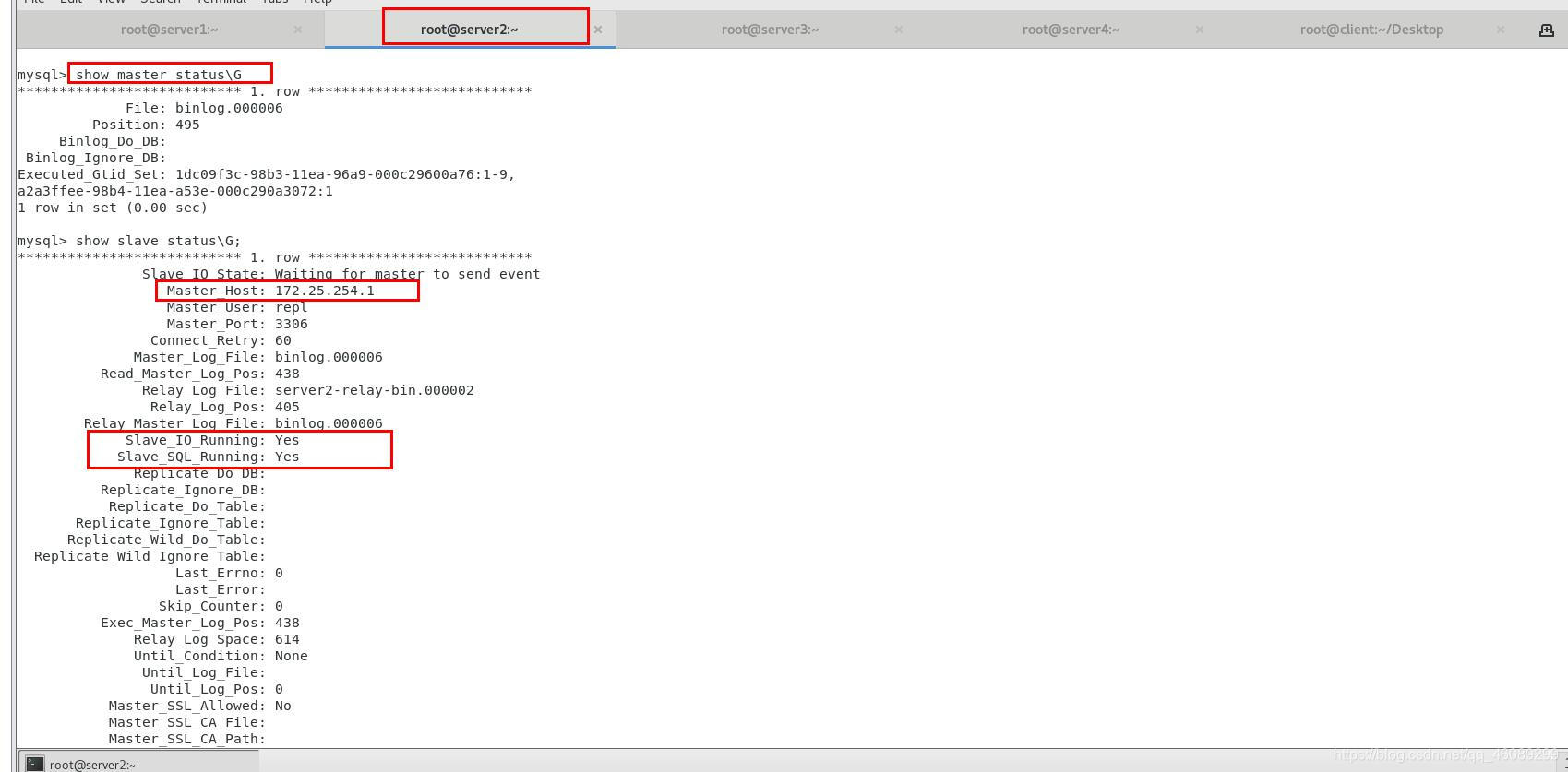
实现自动切换master节点
root@server4 ~]# ll /etc/masterha/ 没有故障文件
-rw-r--r-- 1 root root 415 May 18 04:53 masterha.cnf
[root@server4 ~]# nohup masterha_manager --conf=/etc/masterha/masterha.cnf &> /dev/null &
[1] 10403
[root@server4 ~]# ps ax

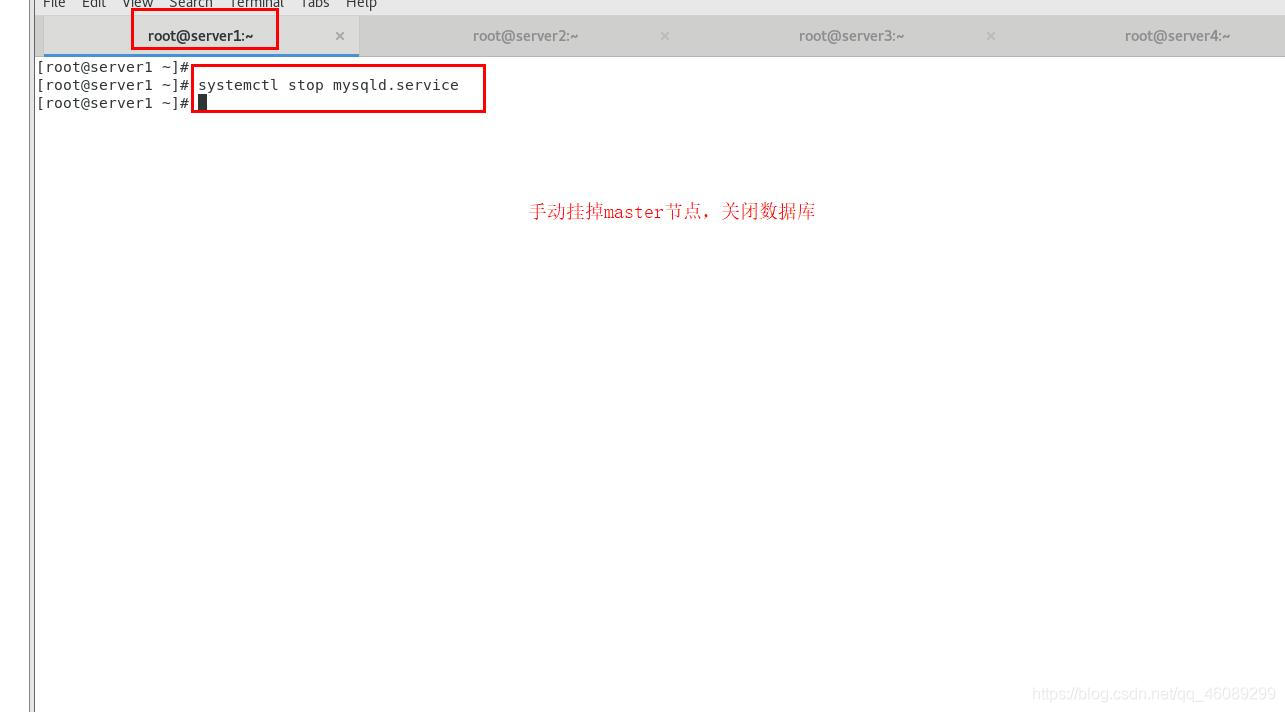
停止当前server1的master节点
[root@server1 ~]# systemctl stop mysqld.service
server4的管理节点自动切换master节点
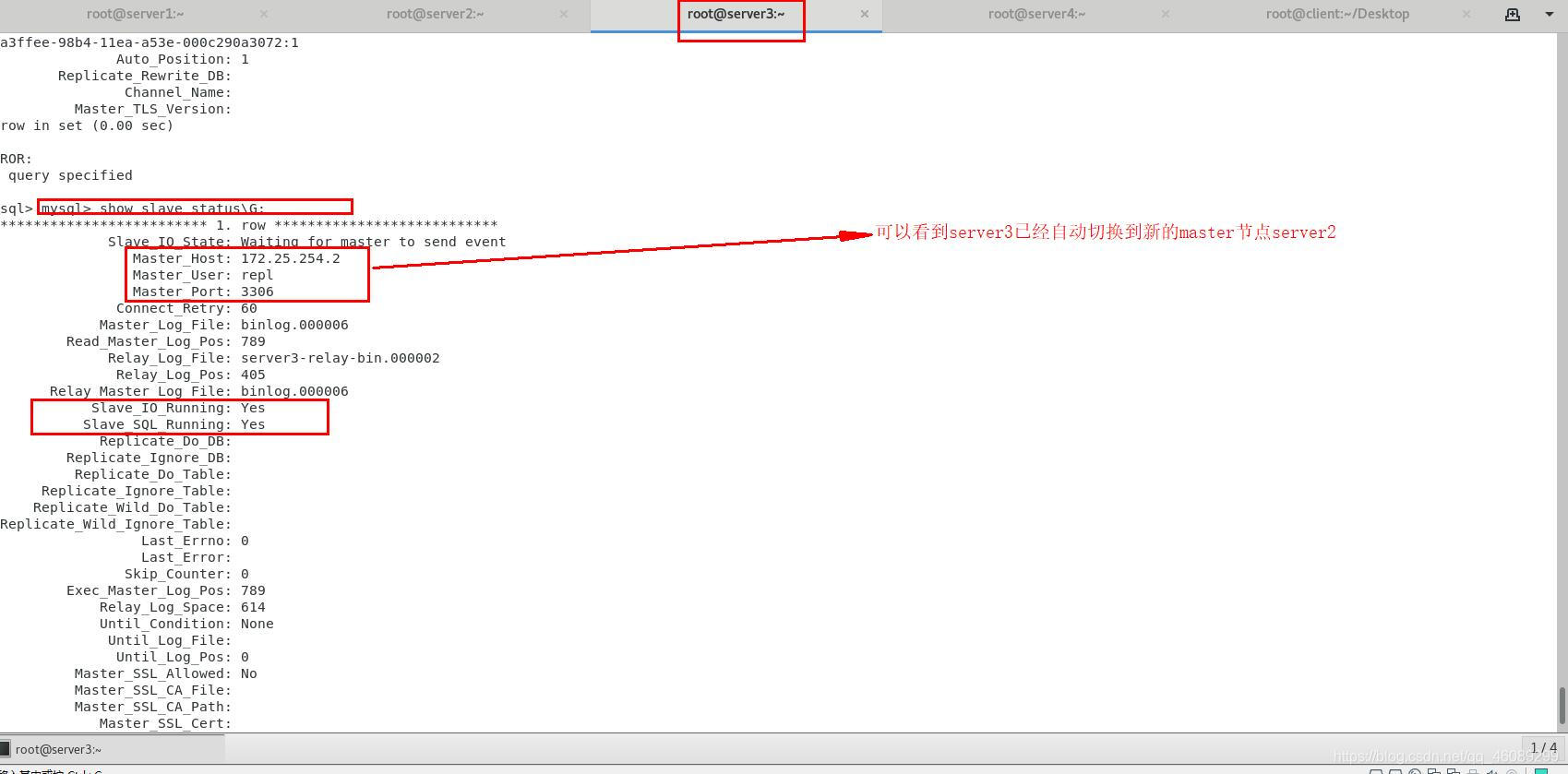
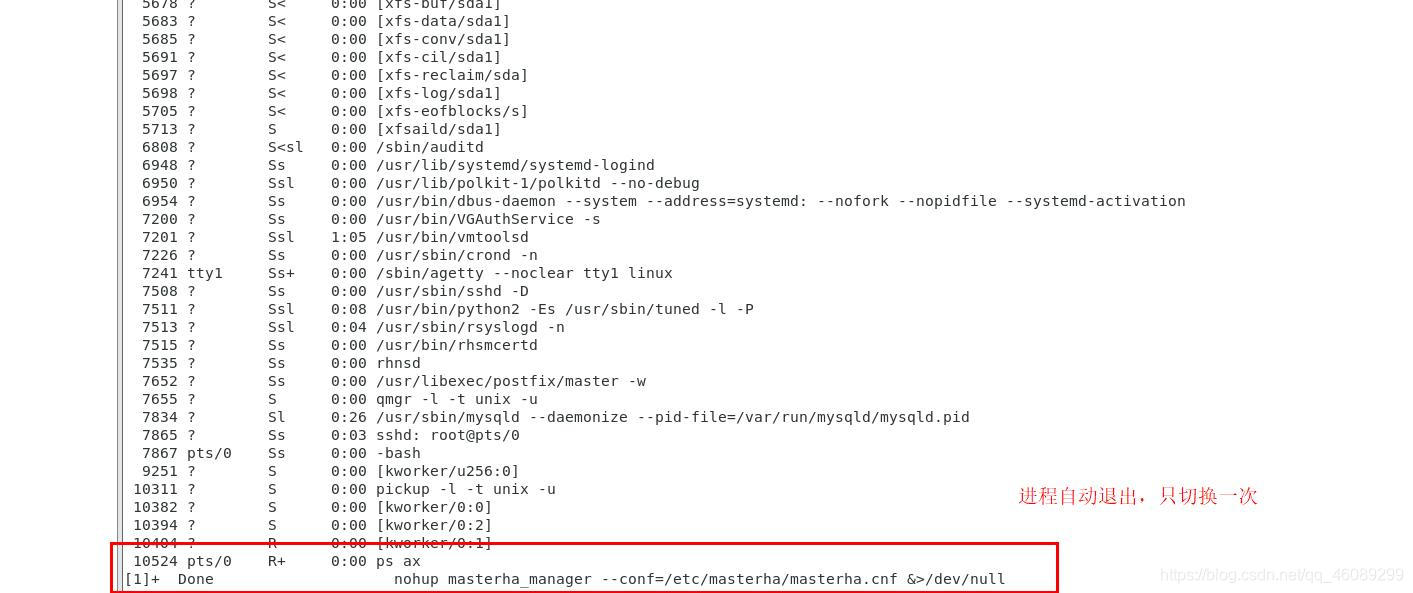
每一次切换都会生成一个master.failover.complete文件(简称故障文件),要将这个文件删除,否则会出错
创建一个监控master的进程(此进程拥有守护进程),这个进程会实时监控master节点的状态,一旦master节点出现故障(宕机)
server4(管理节点)就会自动执行/etc/masterha/masterha.cnf脚本,在正常运行的节点中选择一个最新的来作为新的master节点
同时当前的进程更会挂掉,因为他监控的master已经不再当前集群
复位将server1加入到半同步复制群组中
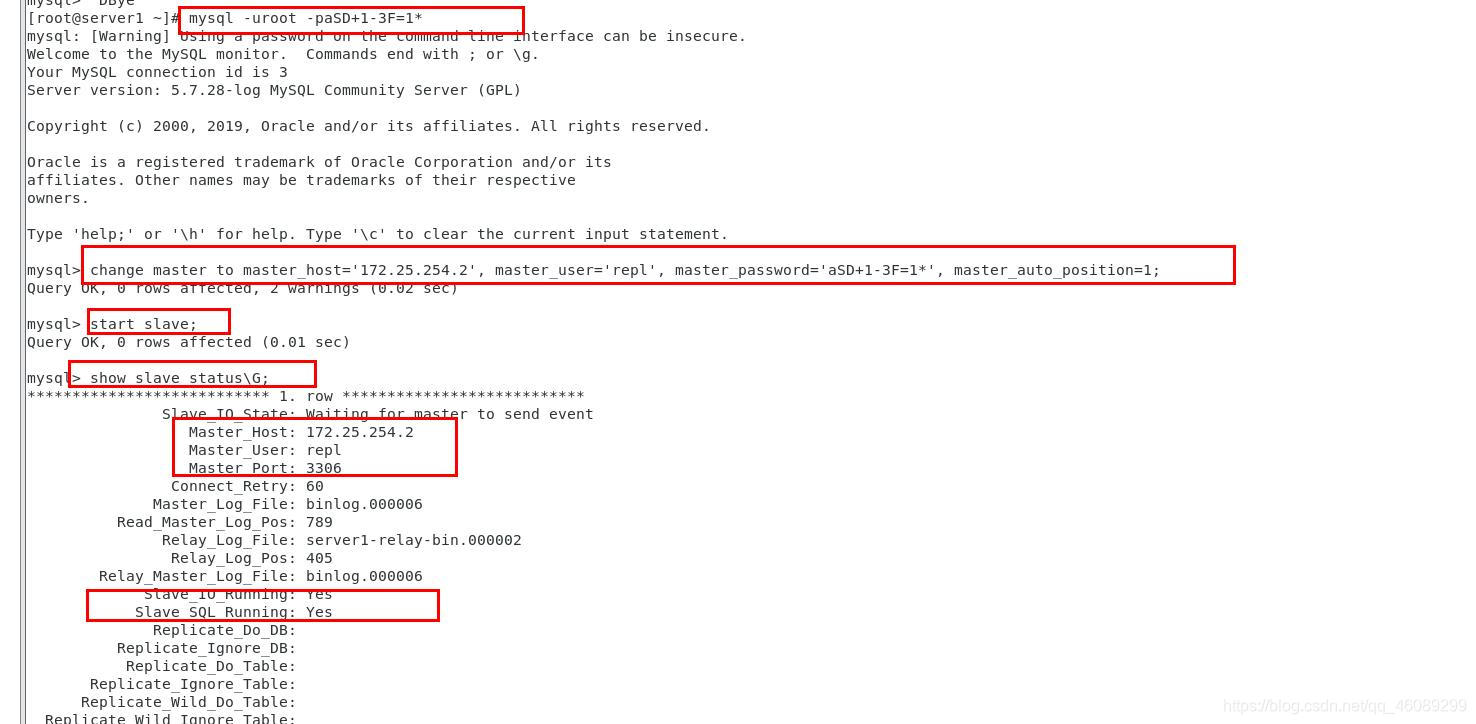
通过脚本实现vip的自动漂移
获取自动脚本

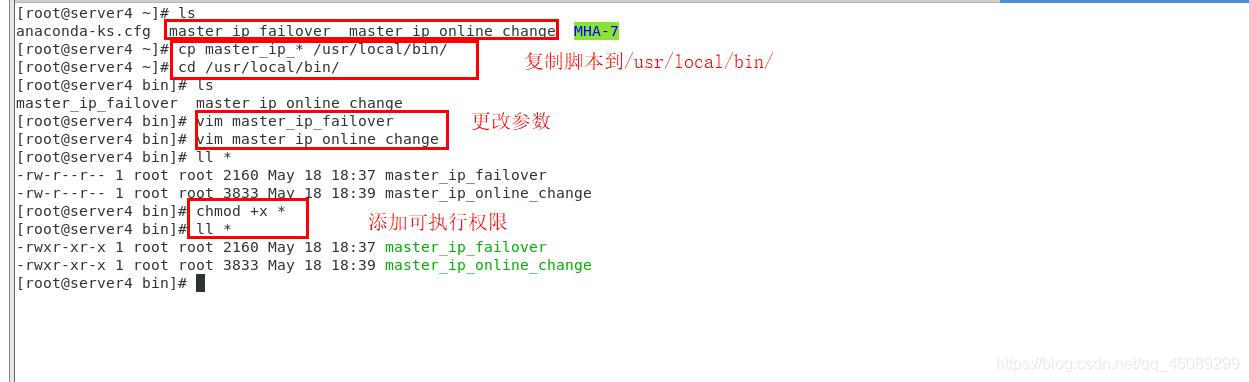
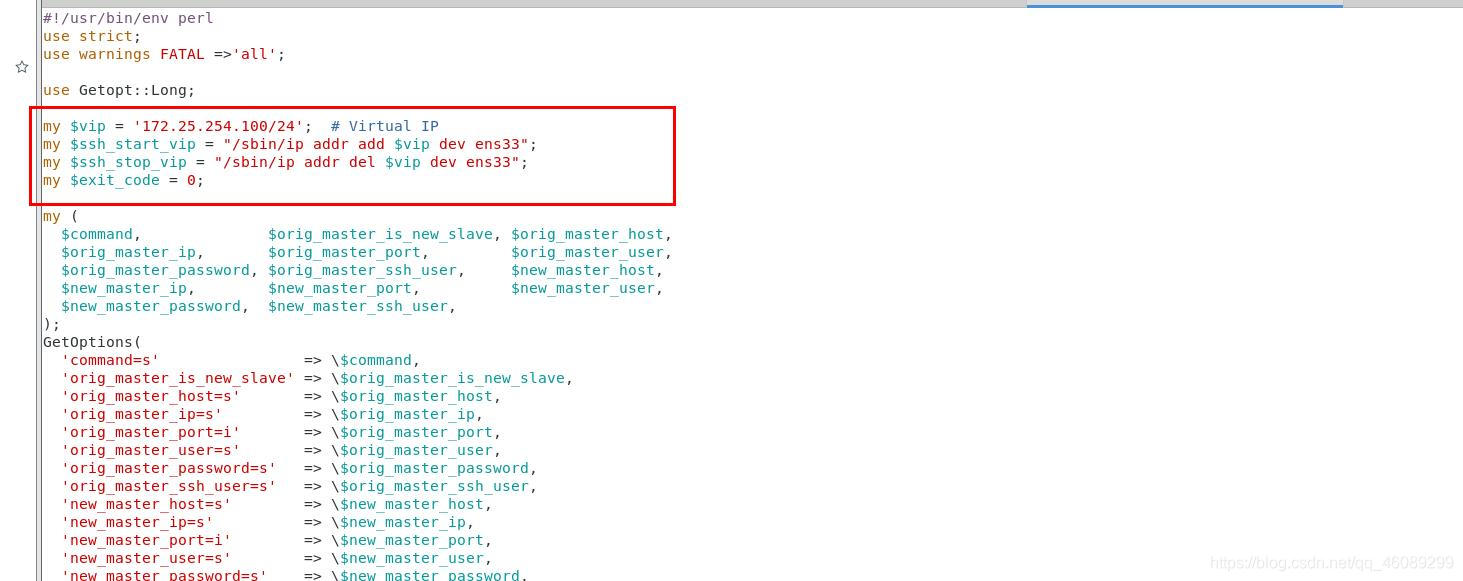
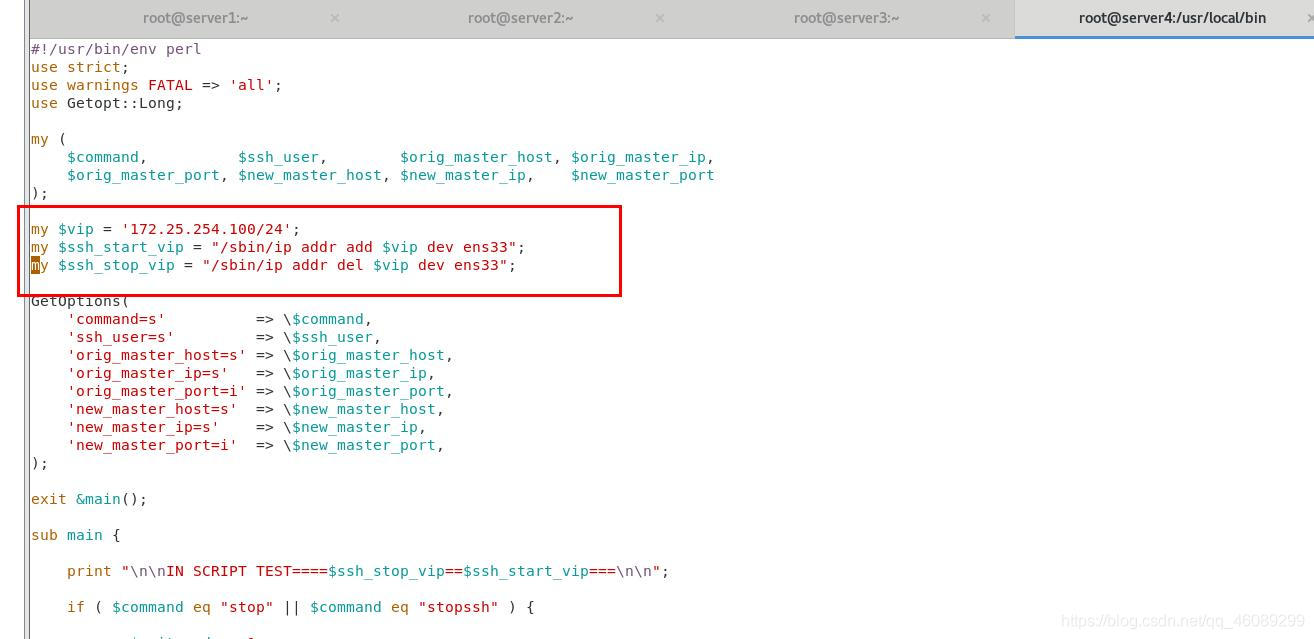
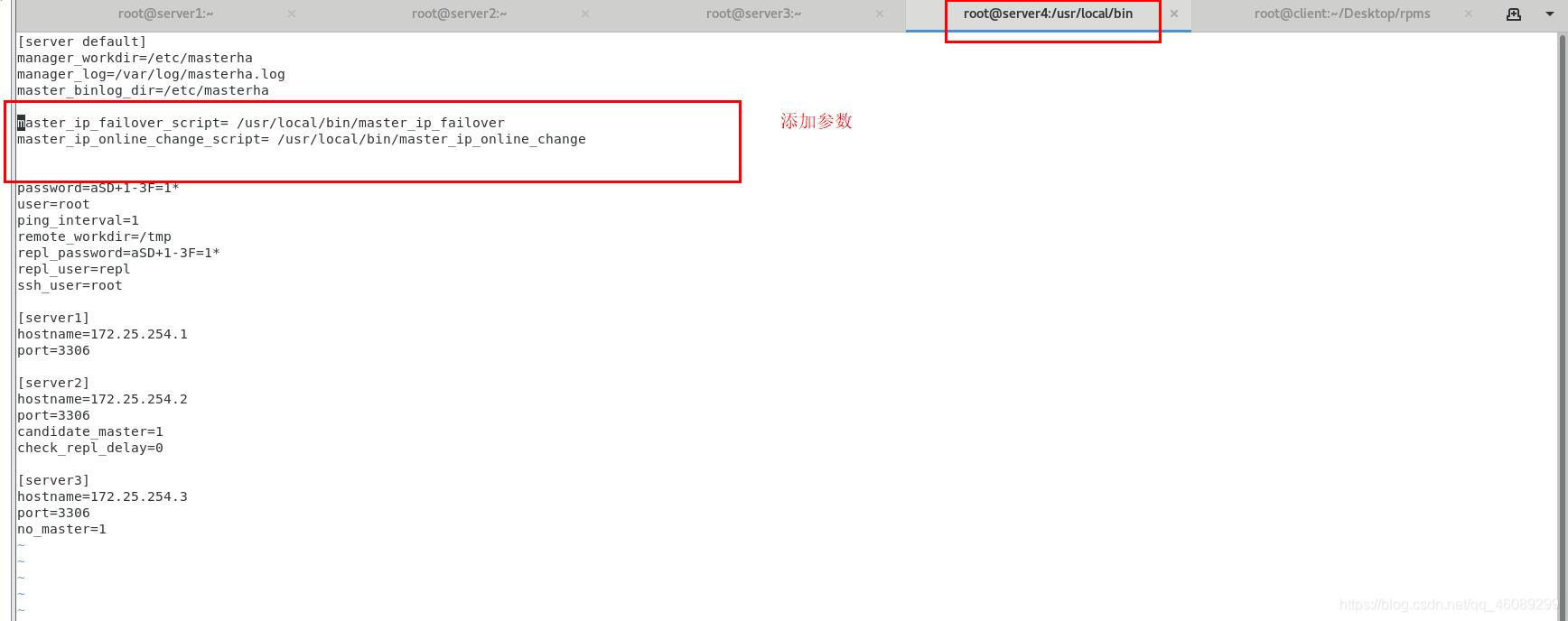
[root@server4 bin]# vim /etc/masterha/masterha.cnf
在server2(master)节点上添加一个VIP
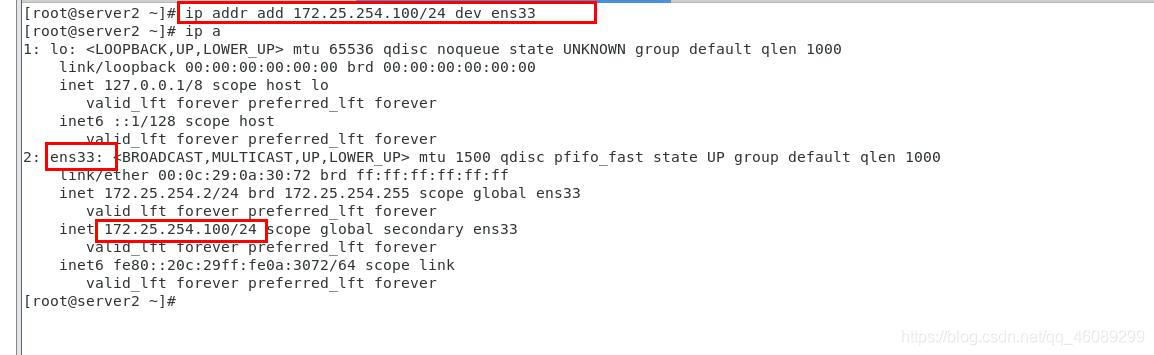
在server4上进行手动切换master节点到server1上
删除故障脚本
[root@server4 masterha]# rm -rf masterha.failover.complete
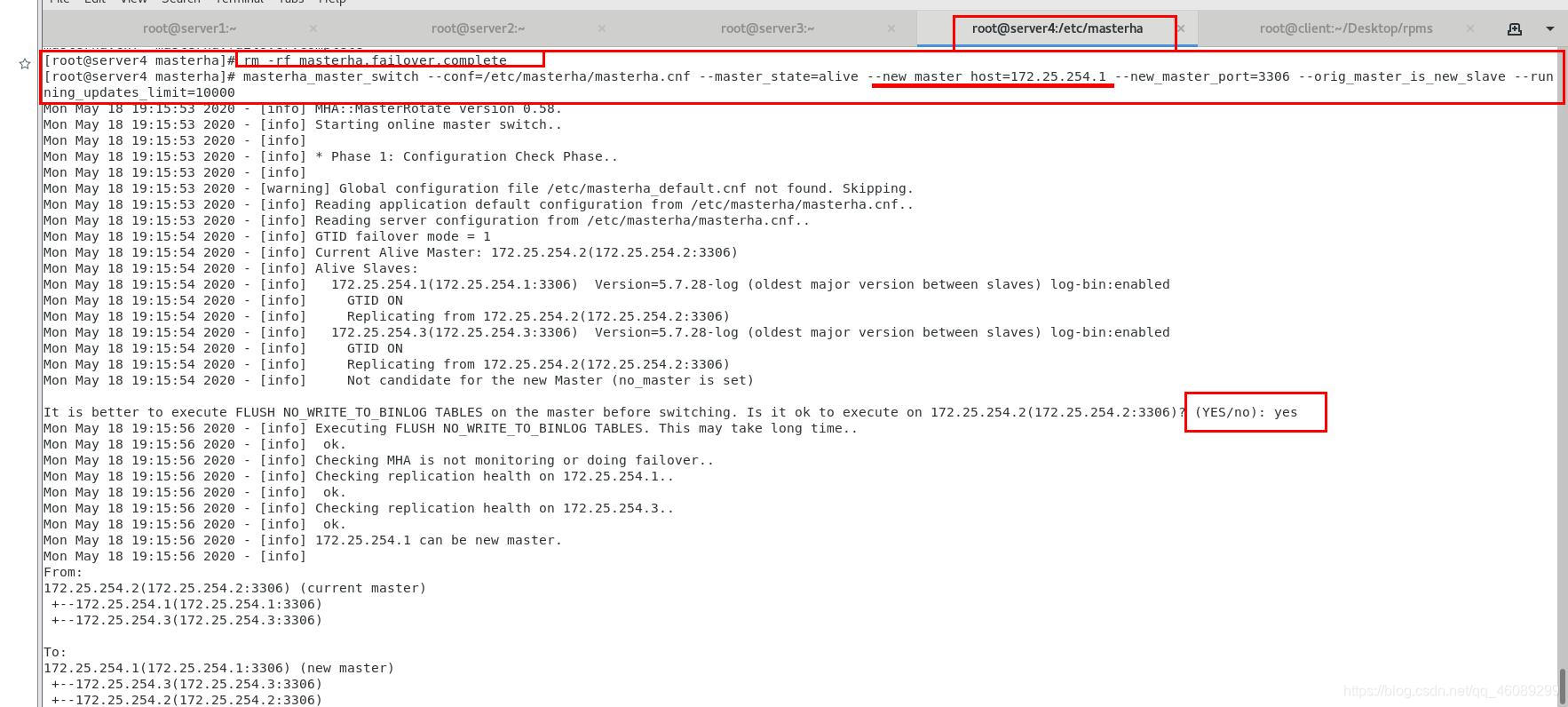
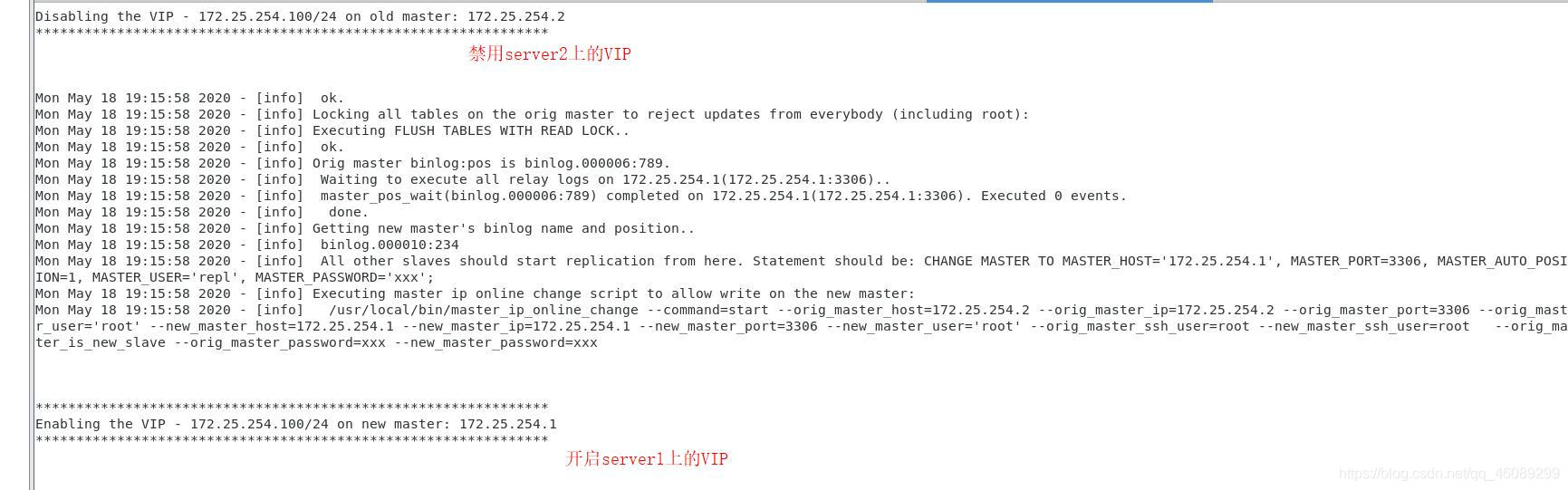
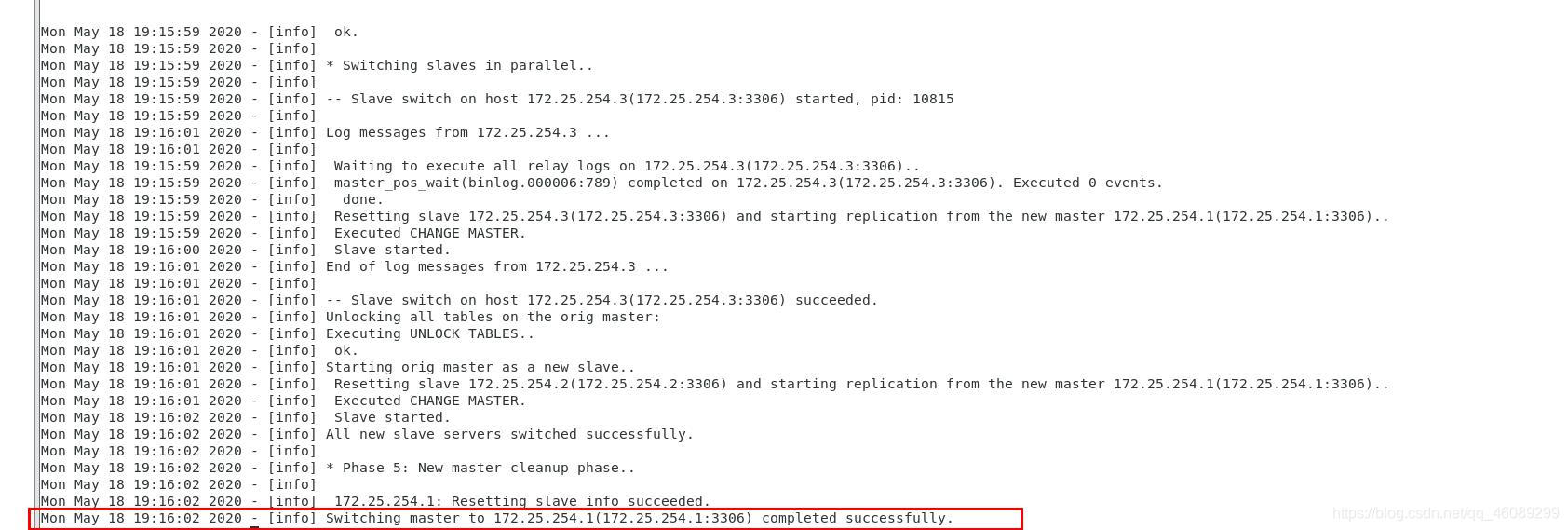
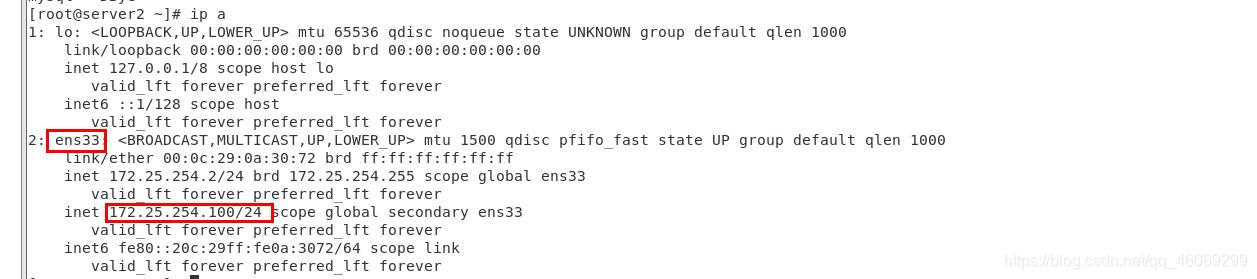
在server1上查看VIP已经成功漂移
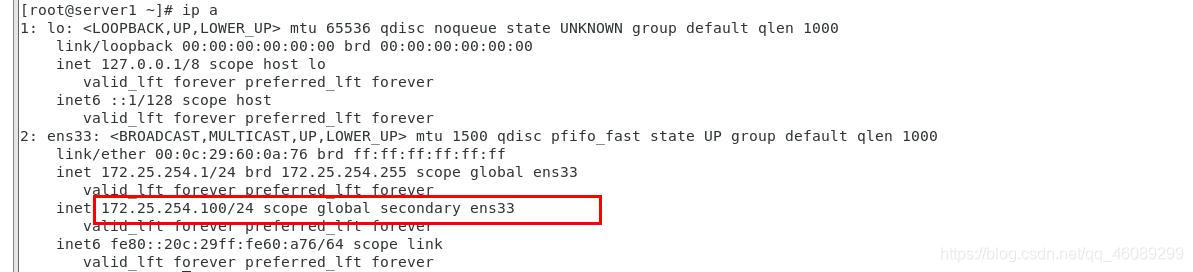
在server上2查看VIP状态和节点状态
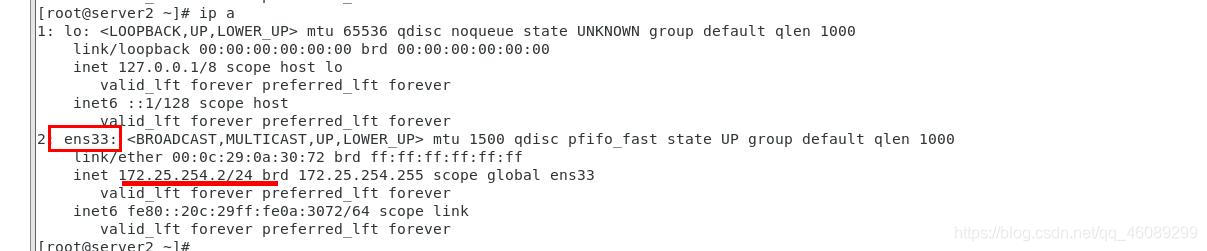
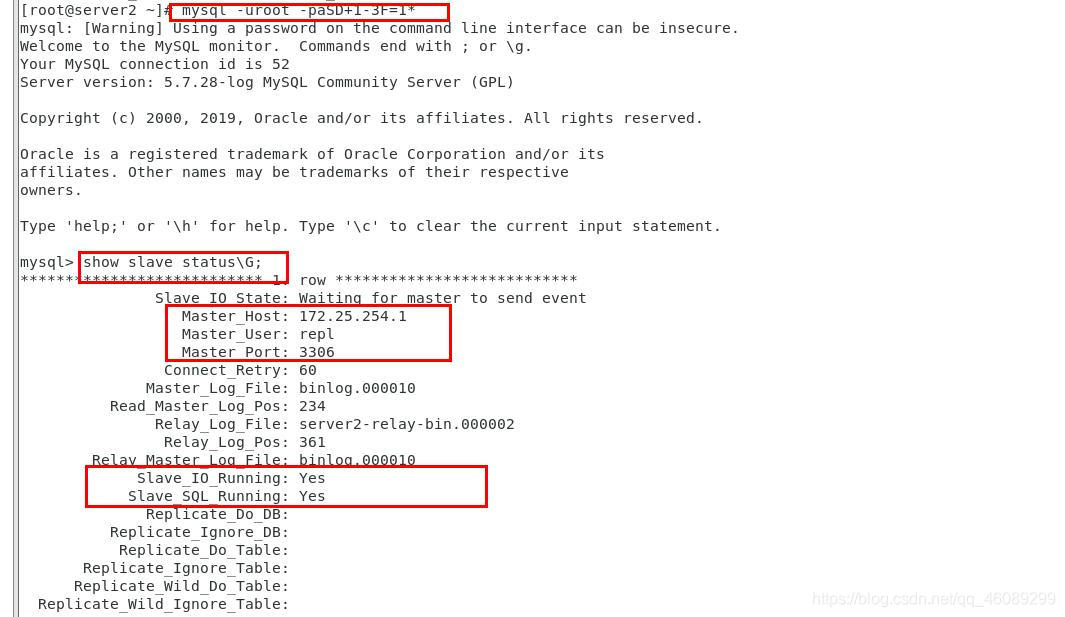
在server3查看master节点
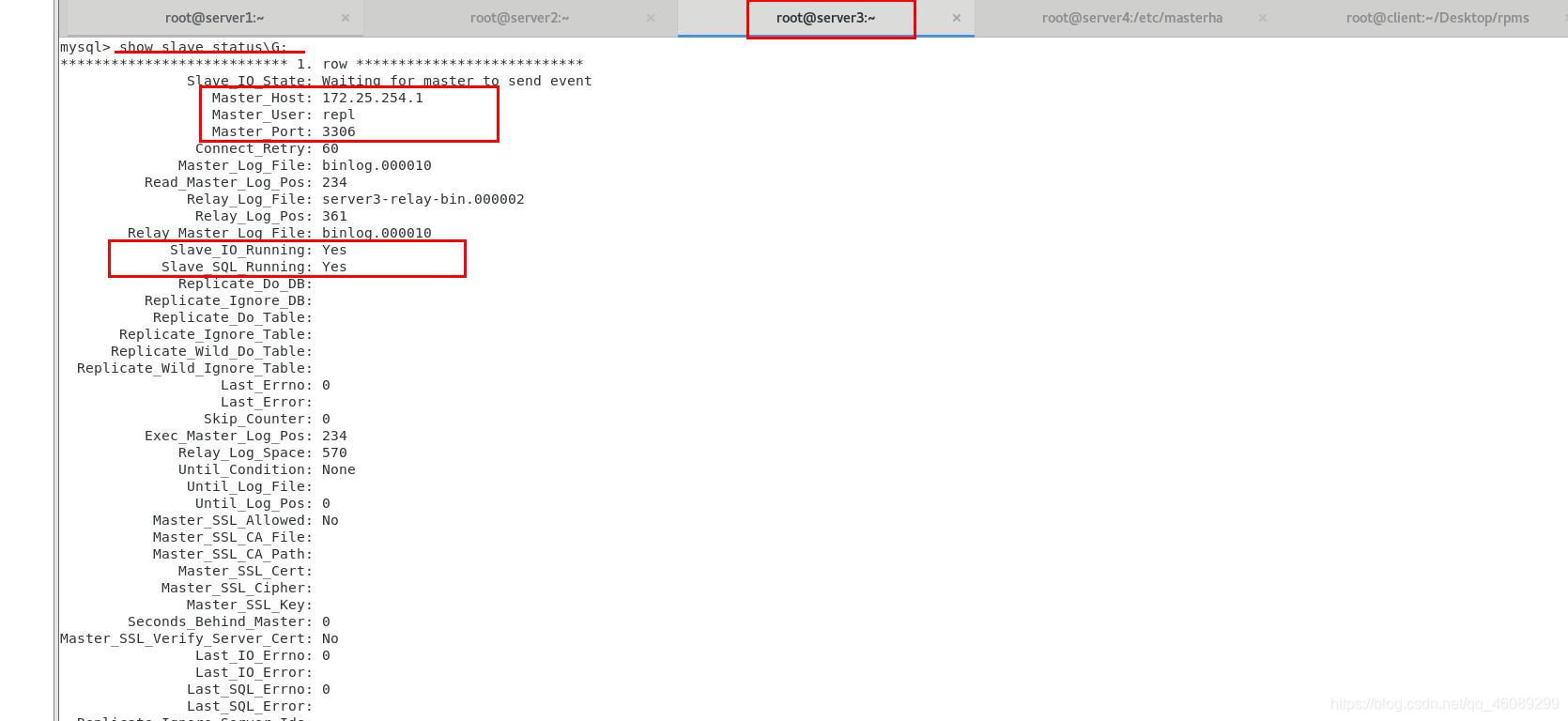
测试一下全自动切换master节点
管理节点server4上开启masterha_manager进程
[root@server4 ~]# nohup masterha_manager --conf=/etc/masterha/masterha.cnf &> /dev/null &
[1] 10823
server1上关闭数据库服务
[root@server1 ~]# systemctl stop mysqld.service
查看server2成为新的master节点

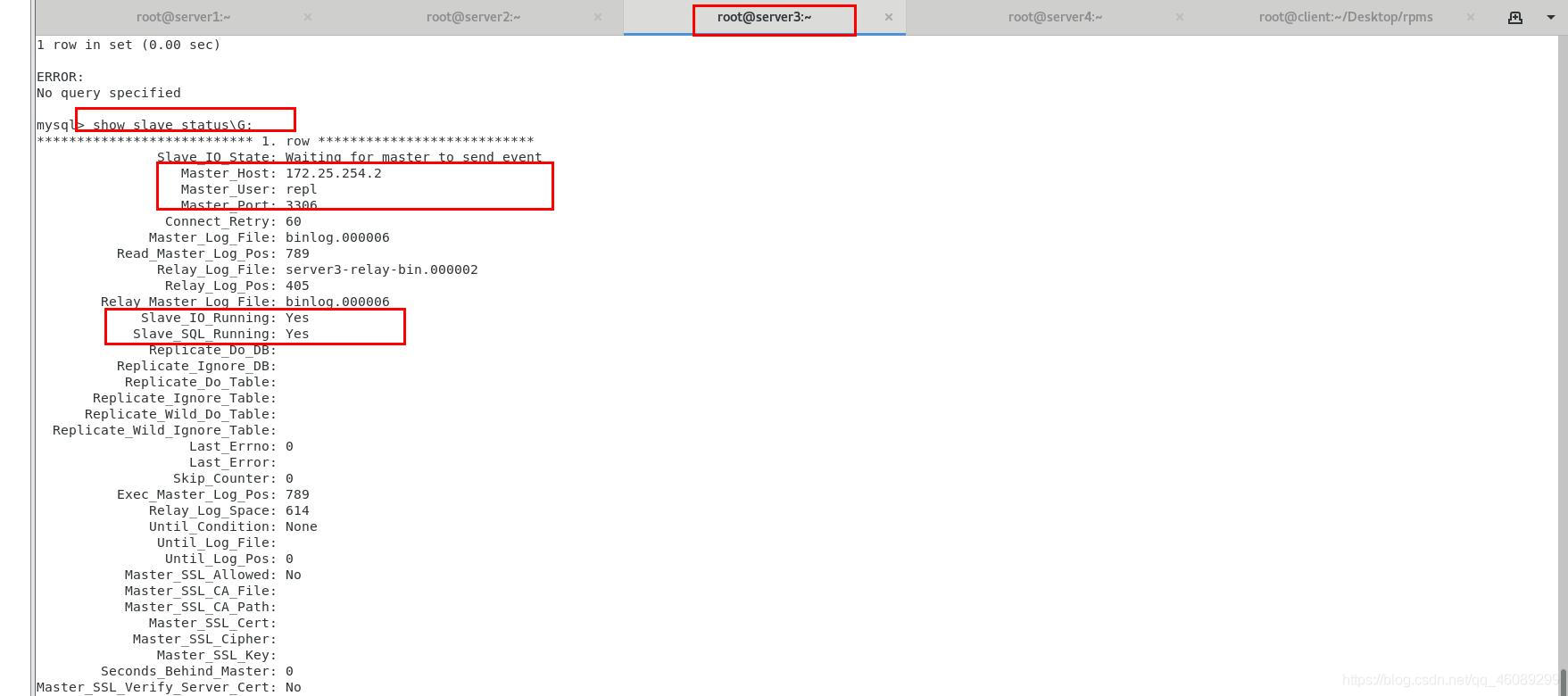
server3查看新的master节点为server2
用户在访问时直接访问172.25.254.100就可以正常访问,不会受到master节点更改主机而受到影响
数据库mysql知识点补充
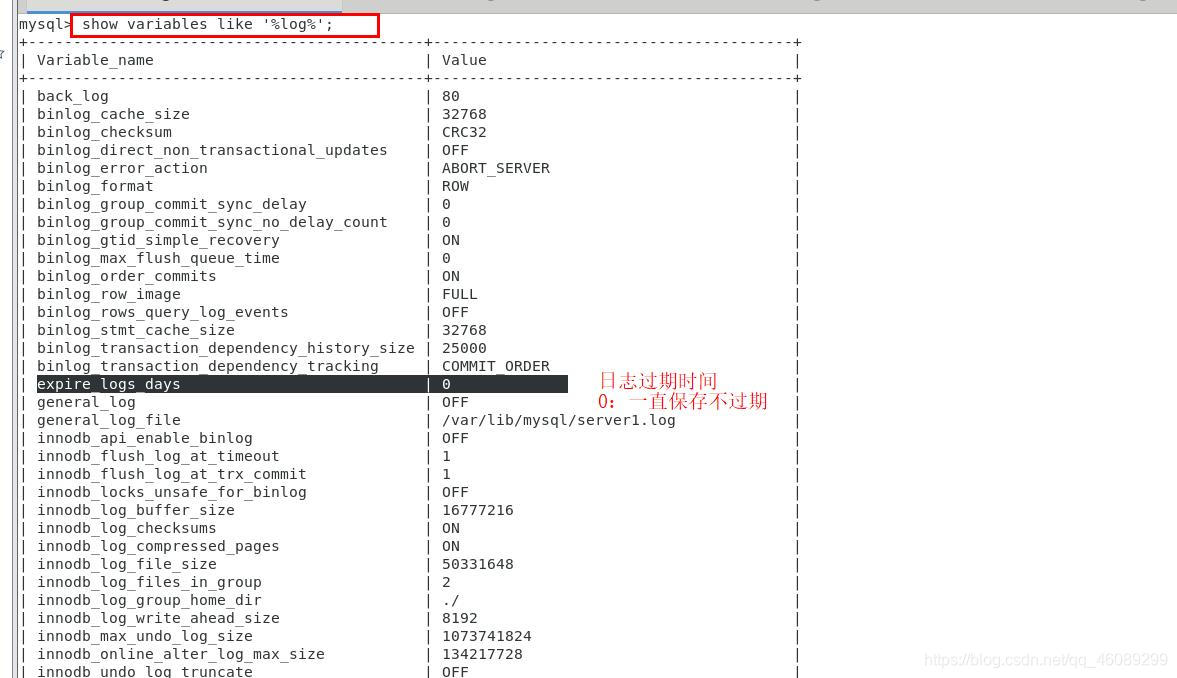
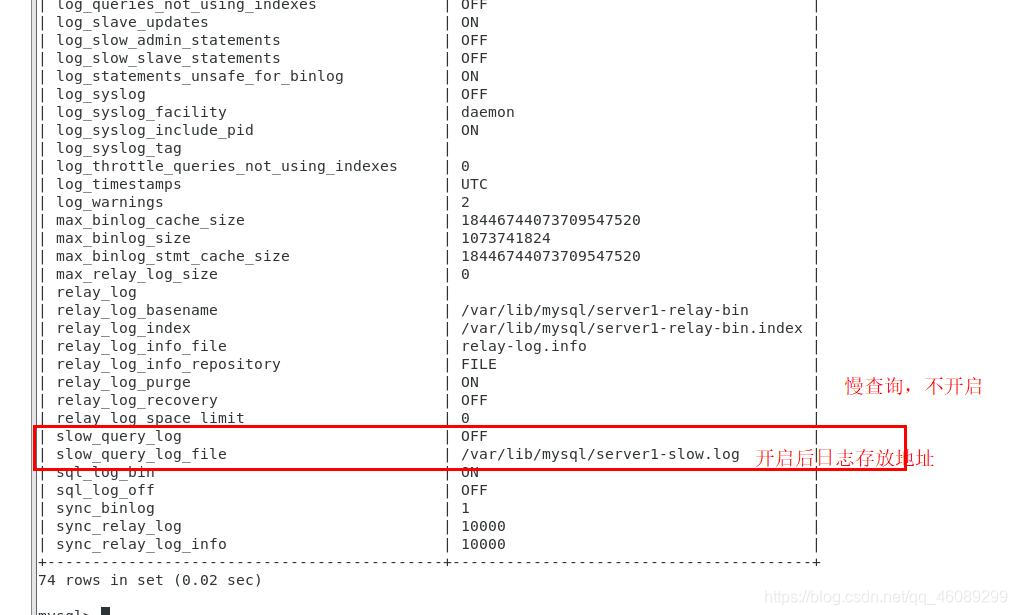
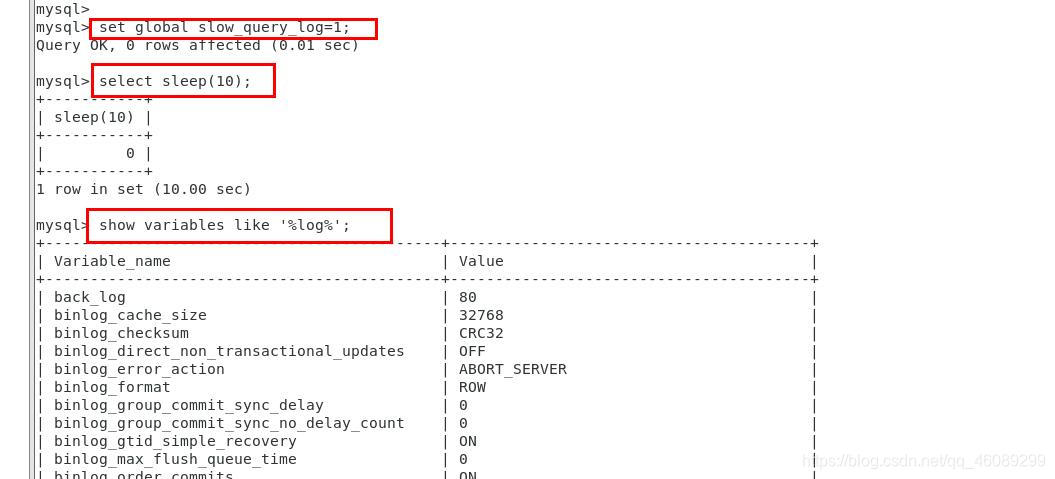
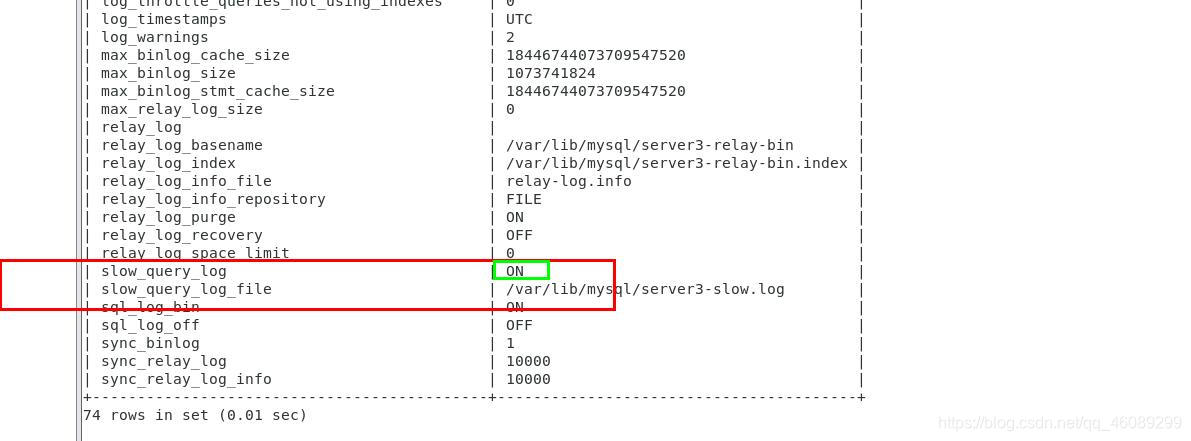
开启慢查询日志,可以让MySQL记录下查询超过指定时间的语句,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能。
slow_query_log 慢查询开启状态
slow_query_log_file 慢查询日志存放的位置(这个目录需要MySQL的运行帐号的可写权限,一般设置为MySQL的数据存放目录)
long_query_time 查询超过多少秒才记录
mysql> set global slow_query_log=1 开启慢查询















 171
171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









