







一、redis的基础知识
redis默认会在/usr/local/bin下创建文件,需要把解压包里面的redis.conf文件拷贝到/usr/local/bin/redis-start/此目录下(目录是新建的==之后启动就指定此文件)
切记一定要把redis.conf 文件中的第136行更改: daemonize yes允许后台启动
 启动redis如下所示:
启动redis如下所示:
 连接redis测试!单机版直接使用-p参数指定端口,若是多台要使用-h 指定连接主机的ip
连接redis测试!单机版直接使用-p参数指定端口,若是多台要使用-h 指定连接主机的ip
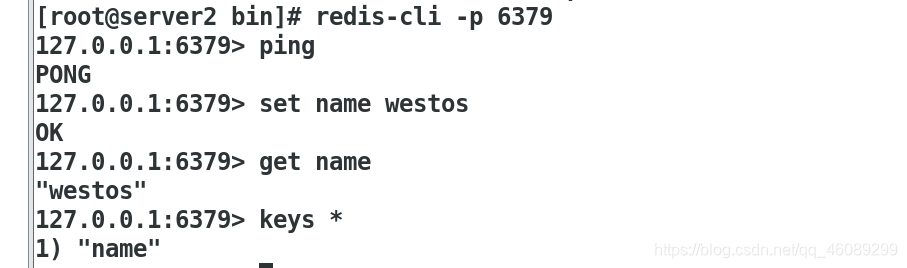 redis性能测试
redis性能测试
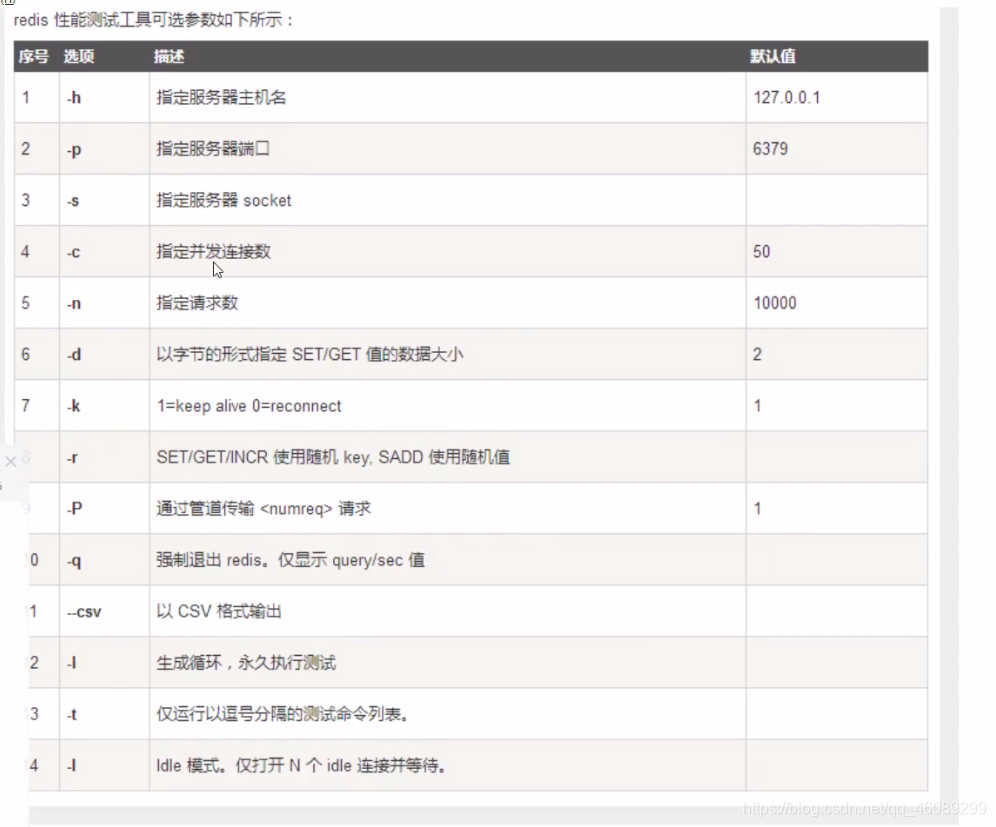 如下:100个并发连接,每个并发十万个请求
如下:100个并发连接,每个并发十万个请求
[root@server2 bin]# redis-benchmark -p 6379 -c 100 -n 100000 -c指定并发数 -n指定每个并发的请求数量
====== SET ======
100000 requests completed in 1.68 seconds 写入十万个请求进行测试
100 parallel clients 100 个并发
3 bytes payload 每次写入三个字符
keep alive: 1 一个服务器
83.01% <= 1 milliseconds
97.35% <= 2 milliseconds
99.35% <= 3 milliseconds
99.74% <= 4 milliseconds
99.79% <= 5 milliseconds
99.89% <= 6 milliseconds
99.93% <= 7 milliseconds
99.97% <= 8 milliseconds
100.00% <= 8 milliseconds 所有请求在9毫秒内完成
59382.42 requests per second 每毫秒的请求数量59382.42
redis默认16个数据库(0-15),默认使用第一个
[root@server2 bin]# redis-cli -p 6379 登录
127.0.0.1:6379> config get databases
1) "databases"
2) "16"
127.0.0.1:6379> select 4 切换到第四个数据库
OK
127 .0.0.1:6379[4]> set name rhel7 插入键值对
OK
127.0.0.1:6379[4]> get name 获取数据
"rhel7"
127.0.0.1:6379[4]> dbsize 获取数据库大小
(integer) 1
127.0.0.1:6379[4]> select 6 切换到第六个数据库
OK
127.0.0.1:6379[6]> get name 获取失败
(nil)
127.0.0.1:6379[4]> flushdb 清空当前数据库,flushall清空所有库
OK
redis为什么是单线程?????
因为redis的性能瓶颈不是cpu限制的,而是和内存、带宽有关系,既然单线程就能实现redis的高性能,那就没必要在去使用多线程了。
 大多数情况下多线程是比单线程块,但是高性能的服务器不一定是多线程,多线程会进行CPU上下文切换,redis是把数据放在内存里面,所以说单线程是做好的解决方案。(对于多次读写都在一个cpu上,并且数据在内存当中,就不会发生上下文切换,)
大多数情况下多线程是比单线程块,但是高性能的服务器不一定是多线程,多线程会进行CPU上下文切换,redis是把数据放在内存里面,所以说单线程是做好的解决方案。(对于多次读写都在一个cpu上,并且数据在内存当中,就不会发生上下文切换,)
redis的命令
exists 判断key是否存在
127.0.0.1:6379> exists name
(integer) 1 存在返回1
127.0.0.1:6379> exists namewww
(integer) 0 不存在返回0
设置key 的过期时间
127.0.0.1:6379> set name luhan
OK
127.0.0.1:6379> get name
"luhan"
127.0.0.1:6379> keys *
1) "name"
2) "key:__rand_int__"
127.0.0.1:6379> expire name 5 设置key的过期时间5s
(integer) 1
(0.96s)
127.0.0.1:6379> ttl name 查看剩余时间,-2表示时间已经结束
(integer) -2
127.0.0.1:6379> keys * 查看key是否存在,显示不存在
1) "key:__rand_int__"
127.0.0.1:6379> get name 获取不到name
(nil)
查看key的类型
127.0.0.1:6379> type name
string
知识点补充:1. del是删除key,move是移动














 376
376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









